利用Kafka的Assign模式实现超大群组(10万+)消息推送
引言
问题背景

问题分解
1)长连接网关要支持10万+用户在线
2)群ID到成员列表的转换
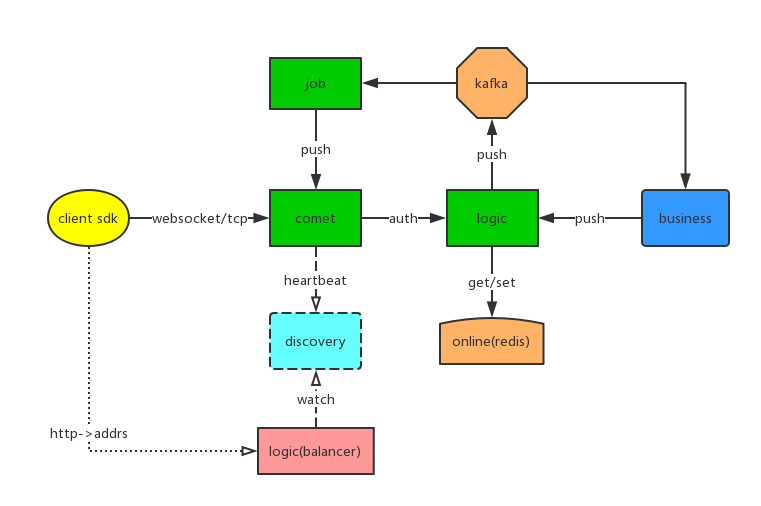
3)长连接网关之间的路由通信问题
解决方案
1)连接池
2)kafka实现
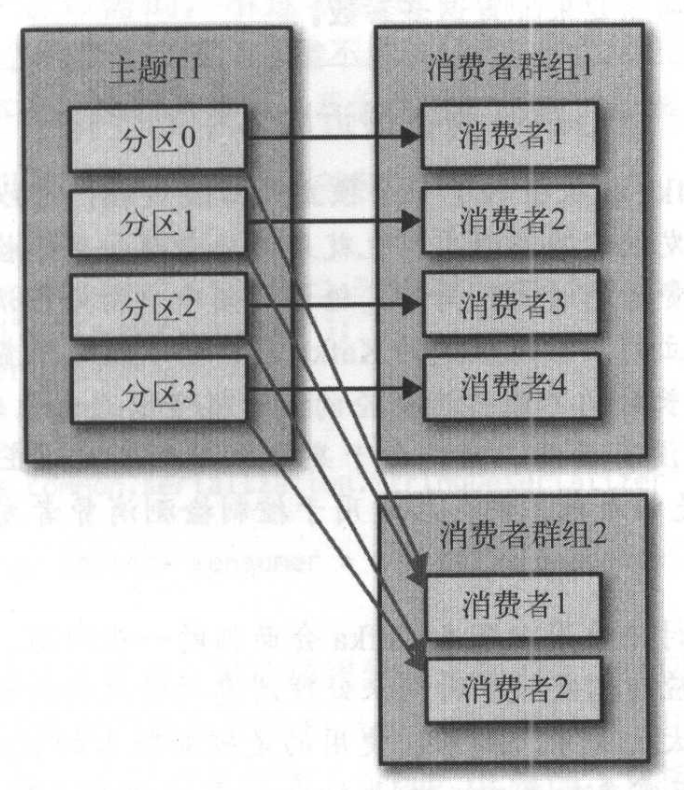
方式一:使用consumer group
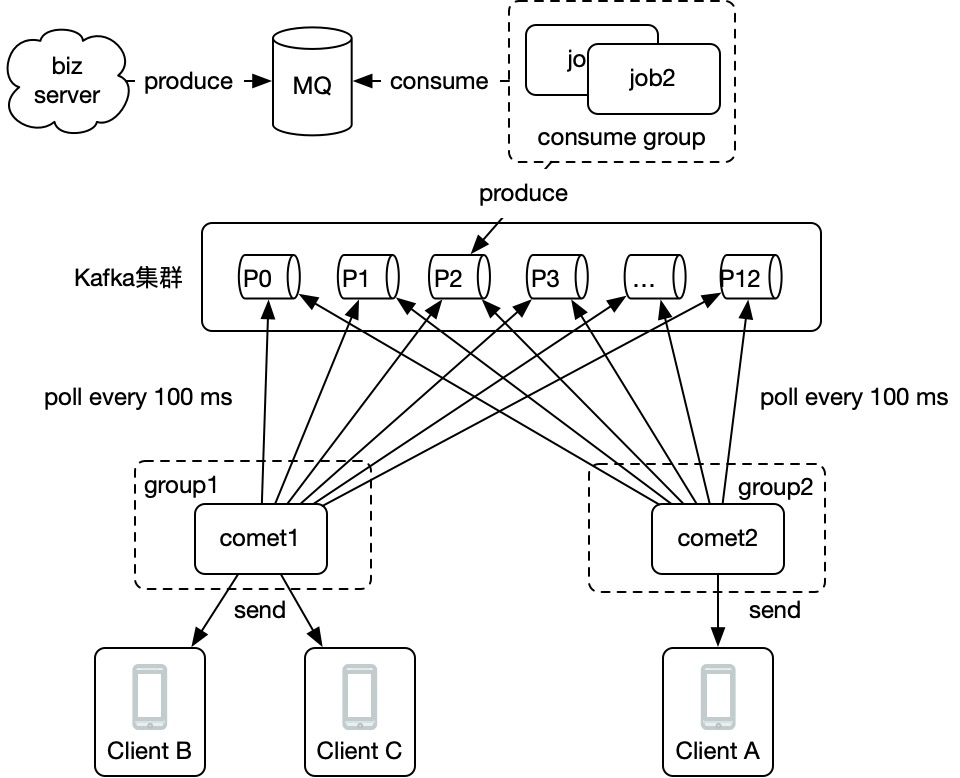

方式二:使用assign,手动订阅所有分区,不使用consumer group
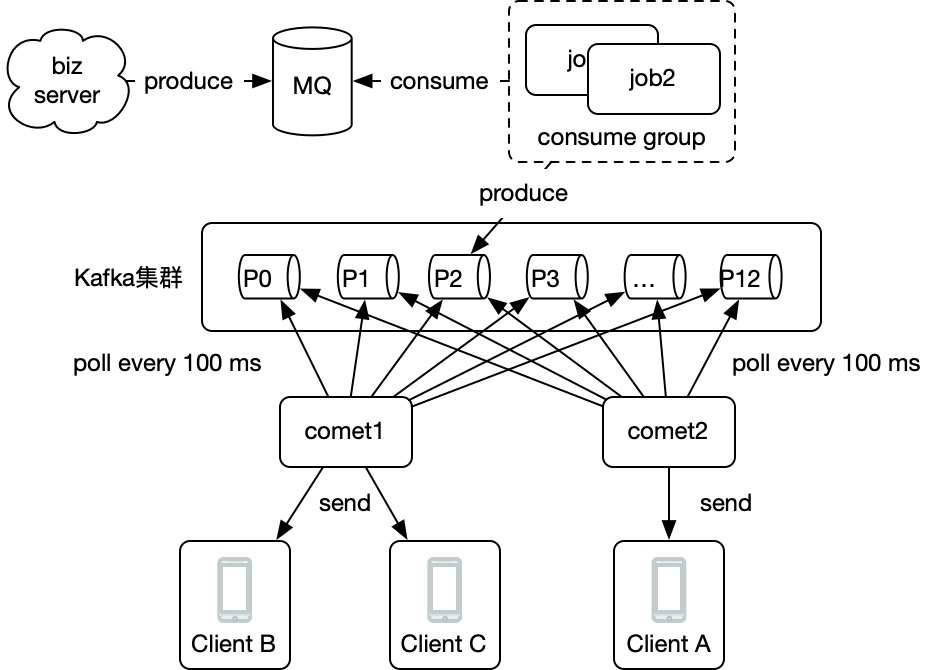
consumer group vs assign模式
- 优点:分区的管理通过group自动实现,不用考虑新分区创建、新消费者加入等等情况。在kafka中还能很方便的看到每一个消费者的消费情况。
- 缺点:受限于云产品的group数量限制,再加上k8s动态启动容器,故需要开发额外的group name分配服务来动态分配提前创建好的group name。
- 优点:不需要创建consumer group,简单方便。
- 缺点:由于是程序自己管理分区,故 kafka tools 等工具上看不到消费情况,消息堆积情况等等。另外如果新增分区,要么重启程序,要么程序中定时拉取,kafka需要预先就估算创建好分区数量,有一定难度。
Assign模式代码实现
assign模式由来
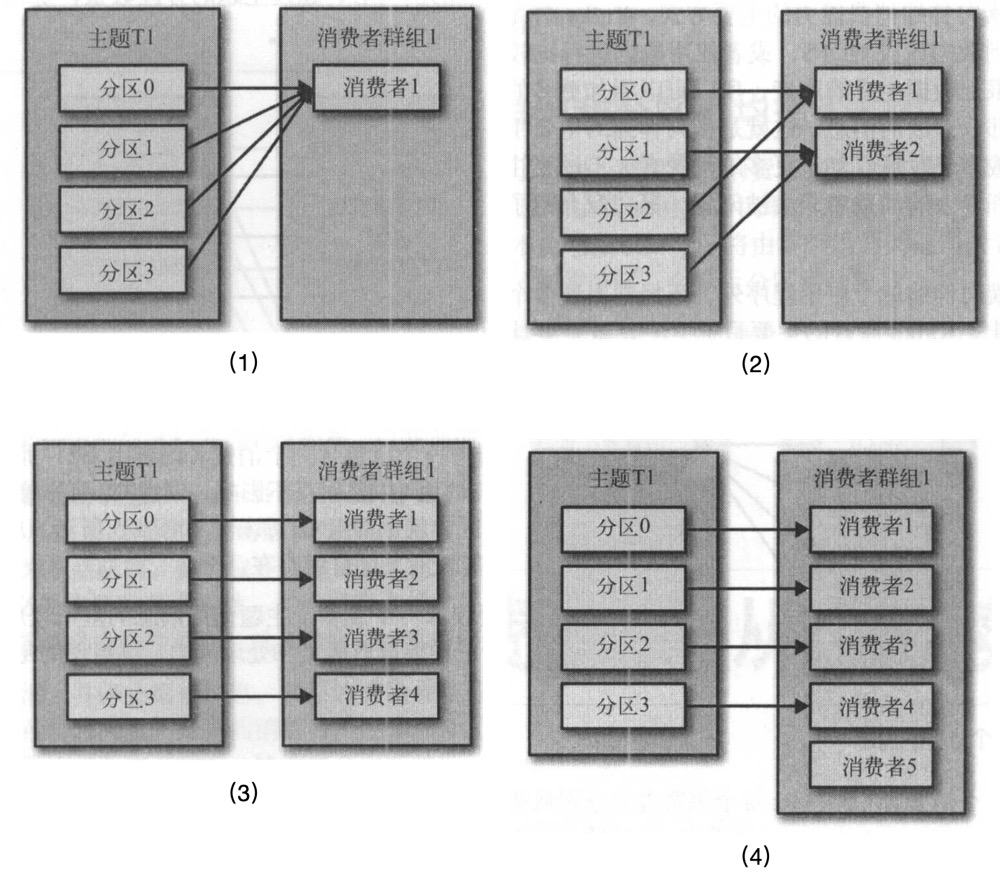
- subscribe:为consumer自动分配partition,有内部算法保证topic-partition以最优的方式均匀分配给同group下的不同consumer
// Subscribe to the given list of topics to get dynamically assigned partitions.
void subscribe(Collection<String> topics, ConsumerRebalanceListener listener)
- assign:为consumer手动、显示的指定需要消费的topic-partitions,不受group.id限制,相当于指定的group无效(this method does not use the consumer's group management)
// Manually assign a list of partitions to this consumer.
void assign(Collection<TopicPartition> partitions)
go中代码实现
package main import (
"context"
"sync"
"time" "github.com/Shopify/sarama"
) type ConsumerHandler func(partition int32, partitionConsumer sarama.PartitionConsumer, message *sarama.ConsumerMessage) func NewConsumer(addrs []string, config *sarama.Config) (sarama.Consumer, error) {
if config == nil {
config = sarama.NewConfig()
// Aliyun kafka version 2.2.0
config.Version = sarama.V2_0_0_0
}
return sarama.NewConsumer(addrs, config)
} // Consume start consume, will block until exit, call in `goroutine`
// note: `handle` called in `goroutine`
func Consume(ctx context.Context, consumer sarama.Consumer, topic string, handle ConsumerHandler) error {
defer consumer.Close() // 获取所有分区
partitions, err := consumer.Partitions(topic)
if err != nil {
return err
} // 消费所有分区
waitGroup := sync.WaitGroup{}
for k, part := range partitions {
p, err := consumer.ConsumePartition(topic, part, sarama.OffsetNewest)
if err != nil {
return err
} waitGroup.Add(1)
go func(partition int32, partitionConsumer sarama.PartitionConsumer) {
defer waitGroup.Done()
defer partitionConsumer.AsyncClose() for {
select {
case <-ctx.Done():
return
case m := <-partitionConsumer.Messages():
handle(partition, partitionConsumer, m)
default:
time.Sleep(time.Millisecond)
}
}
}(int32(k), p)
}
waitGroup.Wait()
return nil
}
main.go中使用:
func main() {
// create and start consumer
consumer, err := NewConsumer(kafkaAddr, nil)
if err != nil {
panic(err)
}
for {
log.Println("consumer is running...")
// will block
err := Consume(context.Background(), consumer, topic, func(partition int32, partitionConsumer sarama.PartitionConsumer, message *sarama.ConsumerMessage) {
log.Println("consumer new mq, paritition=", partition, ",topic:", message.Topic, ",offset:", message.Offset)
})
if err != nil {
log.Println(err)
} else {
log.Println("consume exit")
}
time.Sleep(time.Second * 3)
}
}
producer代码:
func startProducer(addrs []string, topic string) {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewRandomPartitioner
config.Producer.Return.Successes = true
producer, err := sarama.NewSyncProducer(addrs, config)
if err != nil {
panic(err)
}
for i := 0; i < 1000; i++ {
p, offset, err := producer.SendMessage(&sarama.ProducerMessage{
Key: sarama.StringEncoder(strconv.Itoa(i)),
Value: sarama.StringEncoder("hello" + strconv.Itoa(i)),
Topic: topic,
})
if err != nil {
log.Println(err)
} else {
log.Println("produce success, partition:", p, ",offset:", offset)
}
time.Sleep(time.Second)
}
log.Println("exit producer.")
}
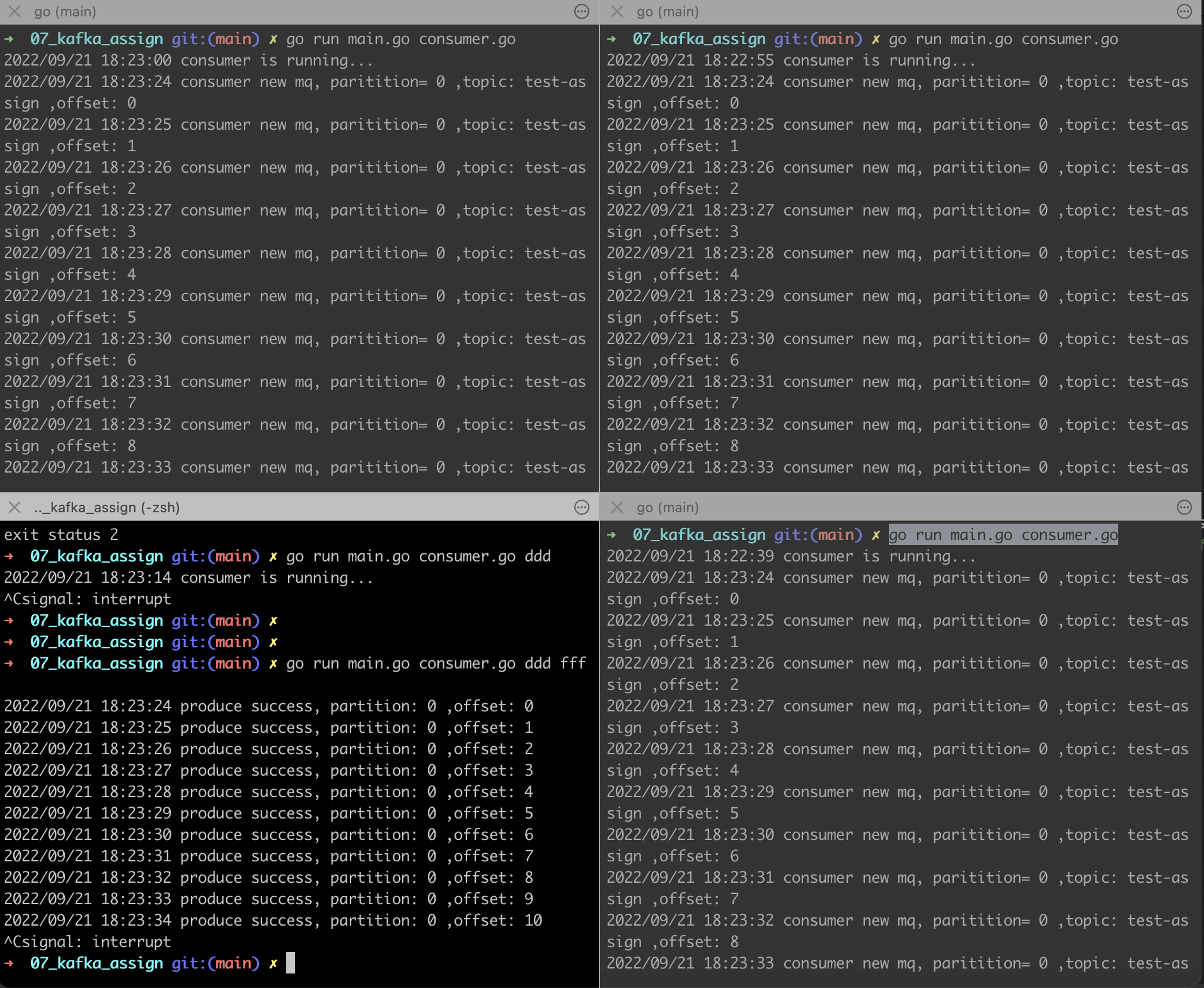
效果如下:
加餐:epoll和连接池的应用以及其局限
1)单体性能
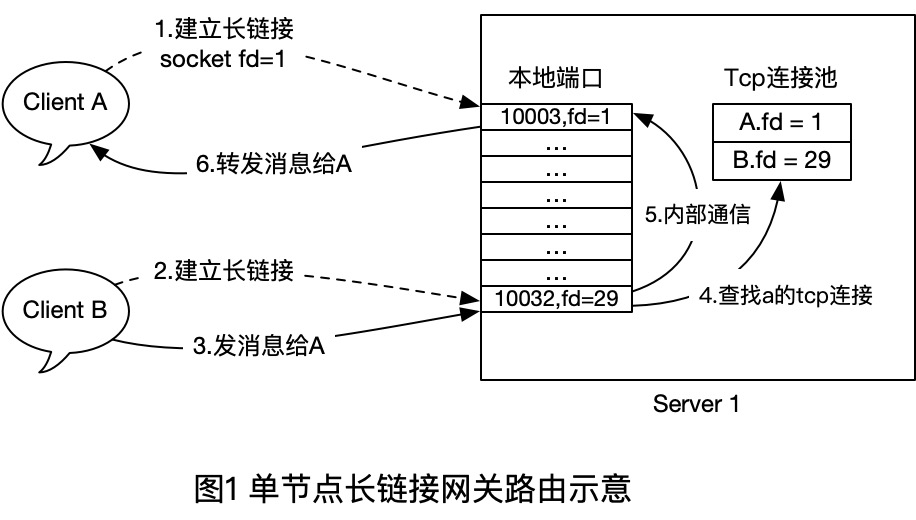
- 首先客户端A和B都和Server1建立TCP长连接,建立时,Server1在内存中插入一条 `User - TcpConn` 的关系,断开时,移除一个对应的关系。
- 当B 给 A发消息时,服务端直接使用本地维护的路由表(连接池)来查找对方的soket句柄,然后Send()到对方的Tcp连接即可。
map[int64]tcp.Conn
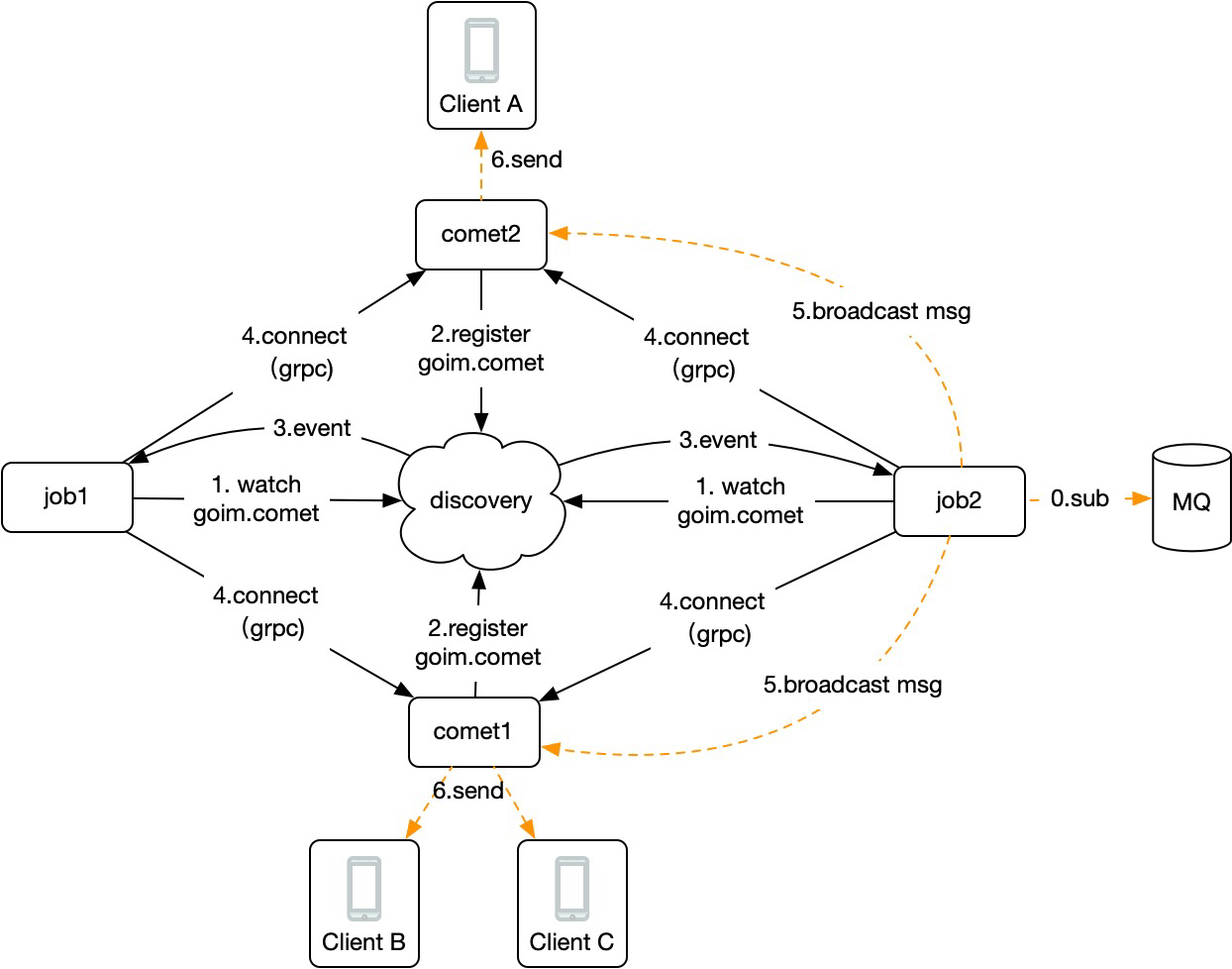
2)水平扩展和信息孤岛
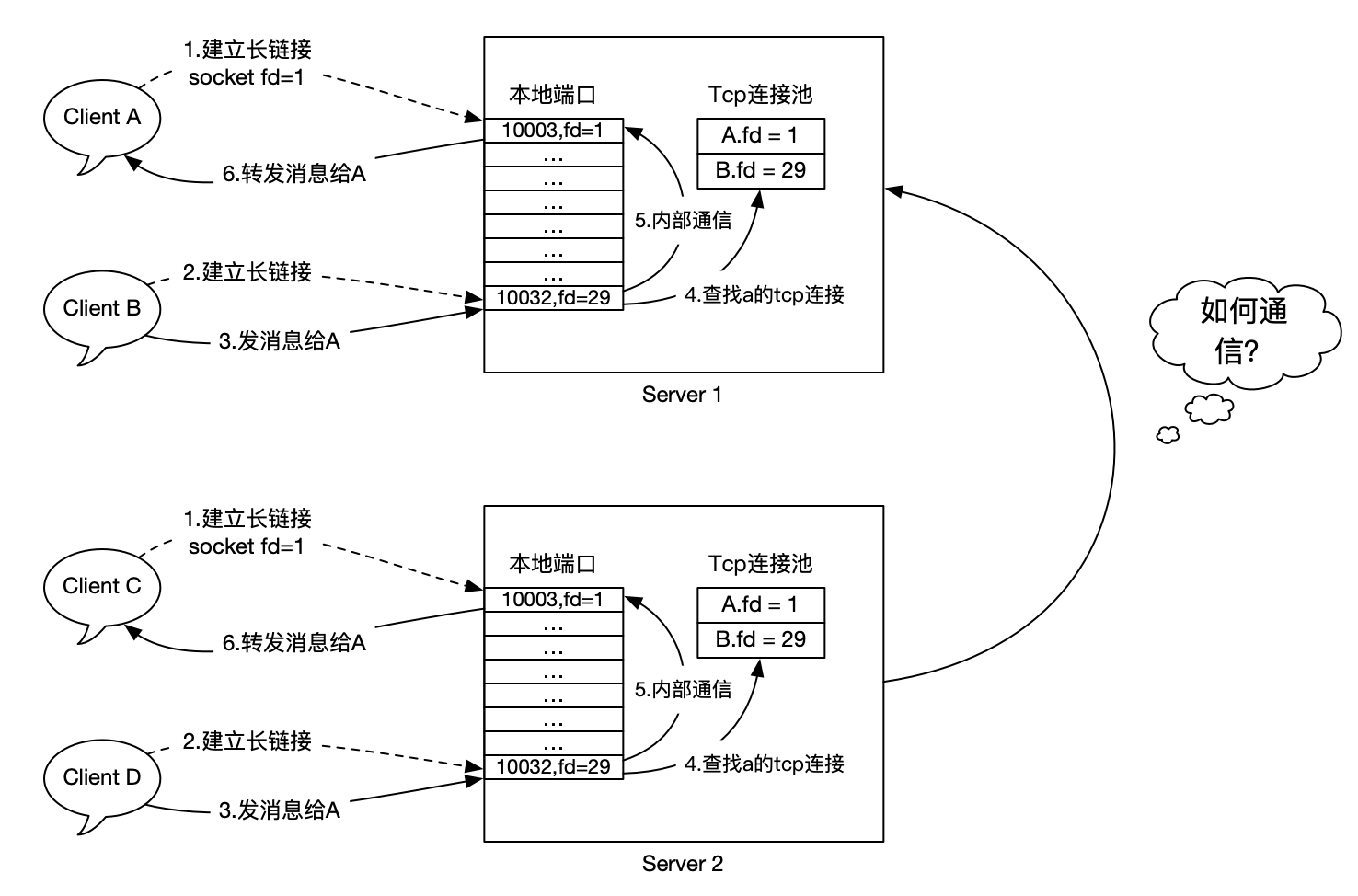
- 分布式路由表。在某个地方统一存放用户登录的节点,推送的时候倒查即可。
- 服务广播。给所有服务器广播消息,那么在该服务器上的用户自然也能收到。
总结
利用Kafka的Assign模式实现超大群组(10万+)消息推送的更多相关文章
- spring websocket 和socketjs实现单聊群聊,广播的消息推送详解
spring websocket 和socketjs实现单聊群聊,广播的消息推送详解 WebSocket简单介绍 随着互联网的发展,传统的HTTP协议已经很难满足Web应用日益复杂的需求了.近年来,随 ...
- Knative 实战:基于 Kafka 实现消息推送
作者 | 元毅 阿里云智能事业群高级开发工程师 导读:当前在 Knative 中已经提供了对 Kafka 事件源的支持,那么如何基于 Kafka 实现消息推送呢?本文作者将以阿里云 Kafka 产品为 ...
- MPush开源消息推送系统:简洁、安全、支持集群
引言由于之前自己团队需要一个消息推送系统来替换JPUSH,一直找了很久基本没有真正可用的开源系统所有就直接造了个轮子,造轮子的时候就奔着开源做打算的,只是后来创业项目失败一直没时间整理这一套代码,最近 ...
- dwr消息推送和tomcat集群
网友的提问: 项目中用到了dwr消息推送.而服务端是通过一个http请求后 触发dwr中的推送方法.而单个tomcat中.服务器发送的http请求和用户都在一个tomcat服务器中.这样就能精准推送到 ...
- Java Socket聊天室编程(一)之利用socket实现聊天之消息推送
这篇文章主要介绍了Java Socket聊天室编程(一)之利用socket实现聊天之消息推送的相关资料,非常不错,具有参考借鉴价值,需要的朋友可以参考下 网上已经有很多利用socket实现聊天的例子了 ...
- JBoss 系列十九:使用JGroups构建块RspFilter对群组通信返回消息进行过滤
内容概述 本部分说明JGroups构建块接口RspFilter,具体提供一个简单示例来说明如何使用JGroups构建块RspFilter对群组通信返回消息进行过滤. 示例描述 我们知道构建块基于通道之 ...
- (七)RabbitMQ消息队列-通过fanout模式将消息推送到多个Queue中
原文:(七)RabbitMQ消息队列-通过fanout模式将消息推送到多个Queue中 前面第六章我们使用的是direct直连模式来进行消息投递和分发.本章将介绍如何使用fanout模式将消息推送到多 ...
- SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=》提升)
SignalR快速入门 ~ 仿QQ即时聊天,消息推送,单聊,群聊,多群公聊(基础=>提升,5个Demo贯彻全篇,感兴趣的玩才是真的学) 官方demo:http://www.asp.net/si ...
- APNS IOS 消息推送沙盒模式和发布模式
在做.NET向IOS设备的App进行消息推送时候,采用的是PushSharp开源类库进行消息的推送,而在开发过程中,采用的是测试版本的app,使用的是测试的p12证书采用的是ApnsConfigura ...
随机推荐
- Future源码一观-JUC系列
背景介绍 在程序中,主线程启动一个子线程进行异步计算,主线程是不阻塞继续执行的,这点看起来是非常自然的,都已经选择启动子线程去异步执行了,主线程如果是阻塞的话,那还不如主线程自己去执行不就好了.那会不 ...
- CVPR 2017:See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks for Video-based Person Re-identification
[1] Z. Zhou, Y. Huang, W. Wang, L. Wang, T. Tan, Ieee, See the Forest for the Trees: Joint Spatial a ...
- Thread和Runnable的区别和匿名内部类方式实现线程的创建
如果一个类继承Thread,则不适合资源共享.但是如果实现了Runable接口的话,则很容易的实现资源共享. 总结:实现Runnable接口比继承Thread类所具有的优势: 1.适合多个相同的程序代 ...
- Tomcat深入浅出——Filter与Listener(五)
一.Filter过滤器 1.1 Filter过滤器的使用 这是过滤器接口的方法 public interface Filter { default void init(FilterConfig fil ...
- 禁用Chrome自动更新
删除下Update目录 C:\Program Files (x86)\Google\Chrome\
- VMware 无法为处于开启或挂起状态的去你及或快照创建克隆
VMware 要克隆的时候出现 无法为处于开启或挂起状态的去你及或快照创建克隆 因为属于挂起或者运行中的不能克隆,因为会发生数据的变化
- 聊聊 Redis 是如何进行请求处理
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com/archives/674 本文使用的Redis 5.0源码 感觉这部分的代码还是挺有意思 ...
- 什么是双网口以太网IO模块
MXXXE系列远程IO模块工业级设计,适用于工业物联网和自动化控制系统,MxxxE工业以太网远程 I/O 配备 2 个mac层数据交换芯片的以太网端口,允许数据通过可扩展的菊花链以太网远程 I/O 阵 ...
- 在win10系统环境下,安装配置sublime 3,构建python和vue.js开发环境(插件)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_131 疫情当下,最近一直在用mac下的虚拟机运行win10系统,由于在线人数过多,直播授课的时候使用vscode的时候内存暴涨,于 ...
- Ubuntu14.04或16.04下普通用户的root权限获得
Ubuntu系统默认不允许使用root登录,因此初始root帐户是不能使用的,需要在普通账户下利用sudo权限修改root密码.然后以root帐户进行相关操作. 具体操作: 1.打开系统,用普通帐户登 ...