Apache Ranger安装部署
1.概述
Apache Ranger提供了一个集中式的安全管理框架,用户可以通过操作Ranger Admin页面来配置各种策略,从而实现对Hadoop生成组件,比如HDFS、YARN、Hive、HBase、Kafka等进行细粒度的数据访问控制。本篇博客,笔者将为大家介绍如何Apache Ranger的安装部署、以及使用。
2.内容
Apache Ranger提供以下核心功能,它们分别是:
- 通过统一的中心化管理界面或者REST接口来管理所有安全任务,从而实现集中化的安全管理;
- 通过统一的中心化管理界面,对Hadoop生态圈组件或者工具的操作进行更加细粒度级别的控制;
- 提供了统一的、标准化的授权方式;
- 支持基于角色的访问控制,基于属性的访问控制等多种访问控制手段;
- 支持对用户访问和管理操作的集中审计。
2.1 架构
Ranger的主要由以下几个核心模块组成,它们分别是:
- Ranger Admin:该模块是Ranger的核心,它内置了一个Web管理界面,用户可以通过这个Web管理界面或者REST接口来制定安全策略;
- Agent Plugin:该模块是嵌入到Hadoop生态圈组件的插件,它定期从Ranger Admin拉取策略并执行,同时记录操作以供审计使用;
- User Sync:该模块是将操作系统用户/组的权限数据同步到Ranger数据库中。
它们之间的流程关系,如下图所示:
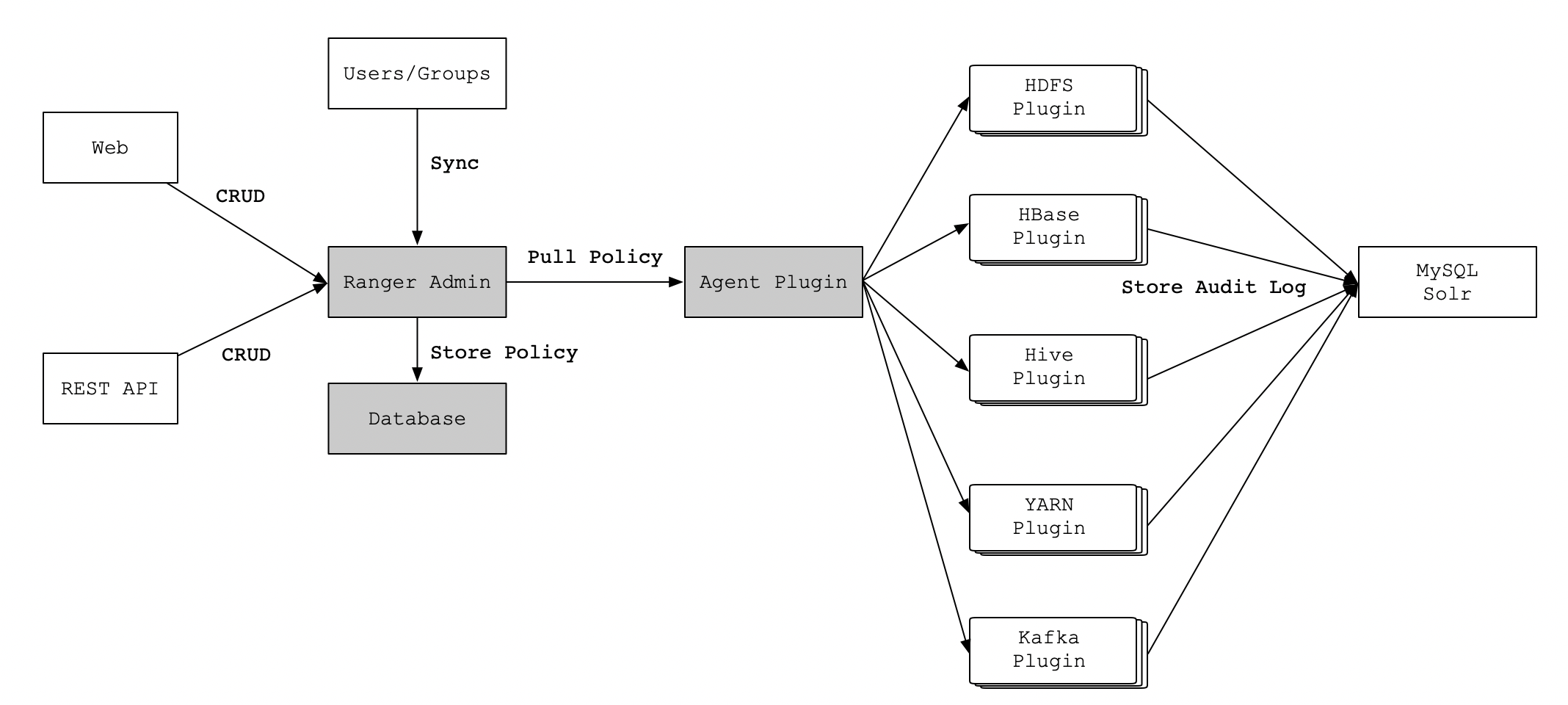
2.2 工作流程
Ranger Admin是Apache Ranger和用户交互的主要界面,用户登录Ranger Admin时,可以针对不同的Hadoop组件定制不同的安全策略,当策略制定并保存后,Agent Plugin会定期从Ranger Admin拉取该组件配置的所有策略,并缓存到本地。
这样,当有用户来请求Hadoop组件的数据服务时,Agent Plugin就提供鉴权服务,并将鉴权结果反馈给相应的组件,从而实现了数据服务的权限控制功能。当用户在Ranger Admin中修改了配置策略后,Agent Plugin会拉取新策略并更新,如果用户在Ranger Admin中删除了配置策略,那么Agent Plugin的鉴权服务也无法继续使用。
以Hive为例子,具体流程如下所示:
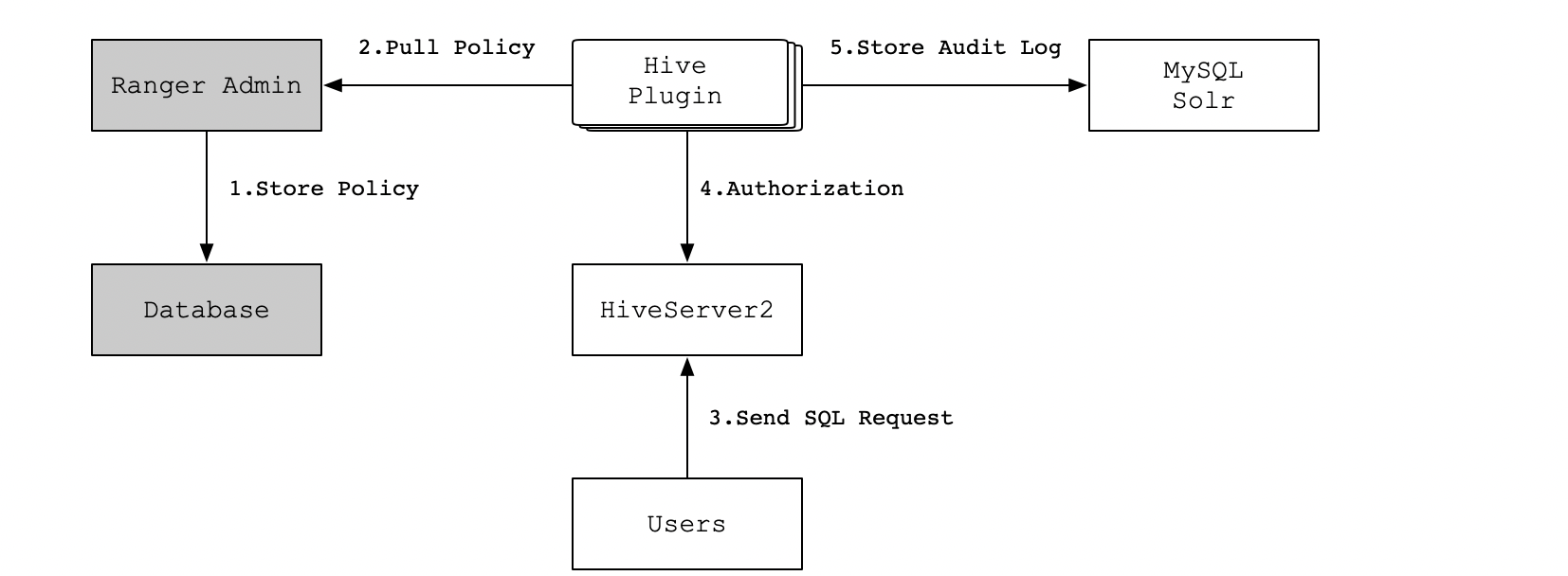
3.安装部署
3.1 基础环境准备
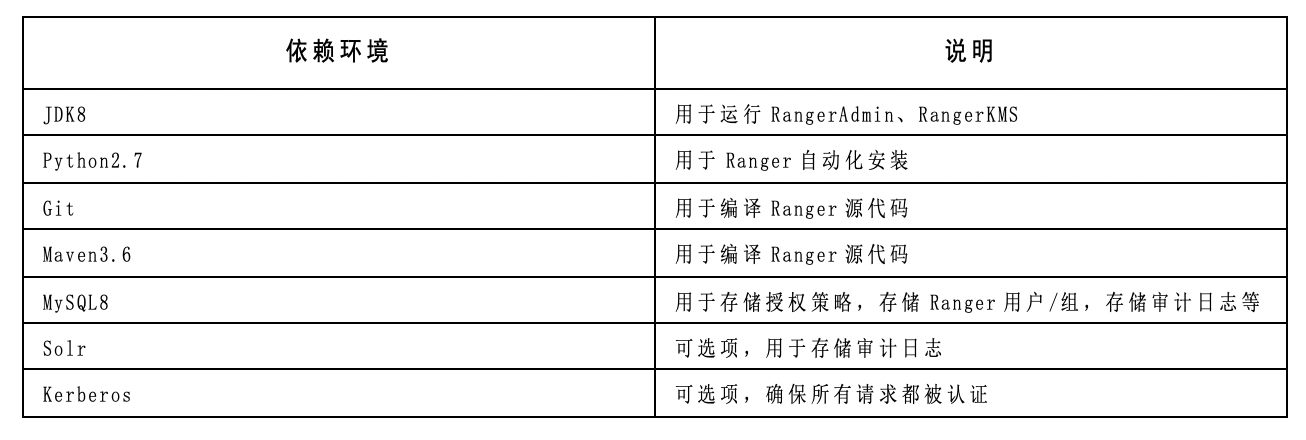
3.2 下载源代码
下载源代码地址渠道,如下所示:
- 官网:https://ranger.apache.org/download.html
- Github:https://github.com/apache/ranger
3.3 编译源代码
Apache Ranger源代码使用Java语言开发,编译时需要使用Java环境,这里我们使用Maven命令来进行编译。Apache Ranger存储数据库支持MySQL数据库,我们直接使用MySQL数据库来作为Apache Ranger系统的存储数据库即可。
# 使用Maven命令编译
mvn -DskipTests=true clean package
编译成功后,会出现如下所示的截图:
3.4 安装Ranger Admin
编辑install.properties文件,具体内容如下所示:
# 指明使用数据库类型
DB_FLAVOR=MYSQL
# 数据库连接驱动
SQL_CONNECTOR_JAR=/appcom/jars/mysql-connector-java-5.1.32-bin.jar
# 数据库root用户名
db_root_user=root
# 数据库密码
db_root_password=Hive123@
# 数据库主机
db_host=nns:3306 # 以下三个属性是用于设置ranger数据库的
#数据库名
db_name=ranger
# 管理该数据库用户
db_user=root
# 管理该数据库密码
db_password=Hive123@ # 不需要保存,为空,否则生成的数据库密码为'_'
cred_keystore_filename= # 审计日志,如果没有安装solr,对应的属性值为空即可
audit_store= audit_solr_urls=
audit_solr_user=
audit_solr_password=
audit_solr_zookeepers= # 策略管理配置,配置ip和端口,默认即可
policymgr_external_url=http://nna:6080 # 配置hadoop集群的core-site.xml文件,把core-site.xml文件拷贝到该目录
hadoop_conf=/data/soft/new/hadoop-conf # rangerAdmin、rangerTagSync、rangerUsersync、keyadmin密码配置。
# 默认为空,可以不配,对应的内部组件该属性也要为空
rangerAdmin_password=ranger123
rangerTagsync_password=ranger123
rangerUsersync_password=ranger123
keyadmin_password=ranger123
执行setup.sh脚本命令后,如果成功,会出现如图所示的结果:
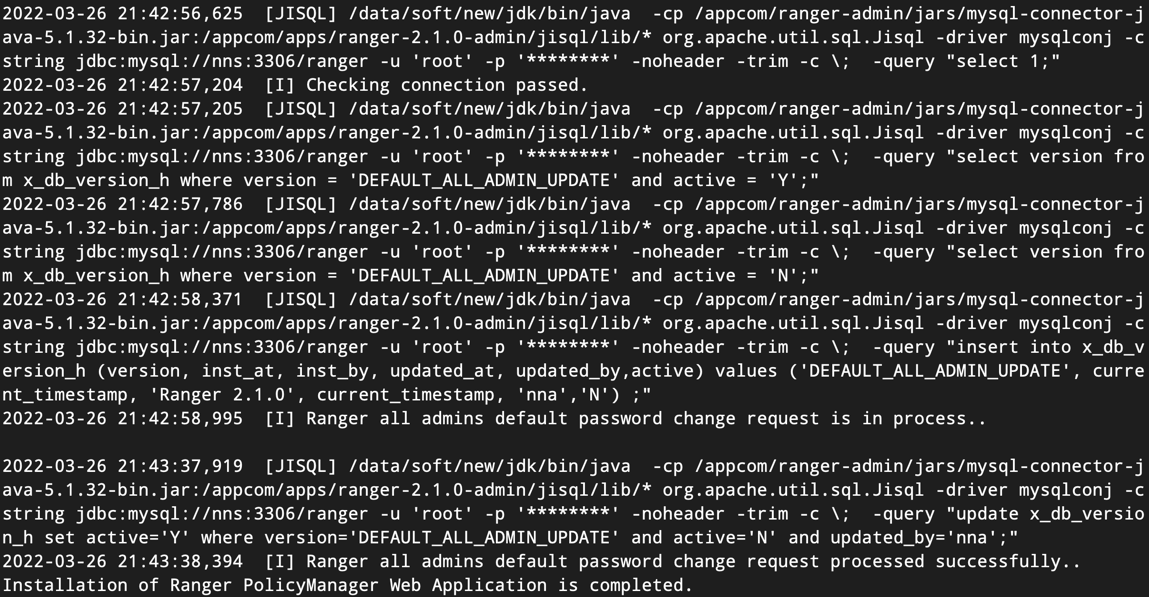
然后,执行set_globals.sh脚本命令,会出现如下所示的结果。
[root@nna ranger-admin]# ./set_globals.sh
usermod: no changes
[2022/03/26 21:45:26]: [I] Soft linking /etc/ranger/admin/conf
to ews/webapp/WEB-INF/classes/conf
[root@nna ranger-admin]#
然后,在登录界面输入“admin/ranger123”,成功进入主界面,如下图所示:
3.5 安装ranger-usersync
编辑install.properties文件,具体内容如下所示:
# 配置ranger admin的地址
POLICY_MGR_URL = http://nna:6080 # 同步源系统类型
SYNC_SOURCE = unix # 同步间隔时间,1分钟
SYNC_INTERVAL = 1 # usersync程序运行的用户和用户组
unix_user=ranger
unix_group=ranger # 修改rangerusersync用户的密码。注意,此密码应与ranger-admin中
# install.properties的rangerusersync_password相同。
# 此处可以为空,同样ranger-admin的也要为空
rangerUsersync_password=ranger123 # 配置hadoop的core-site.xml路径
hadoop_conf=/data/soft/new/hadoop-config # 配置usersync的log路径
logdir=logs
执行setup.sh脚本命令后,如果成功,会出现如图所示的结果:
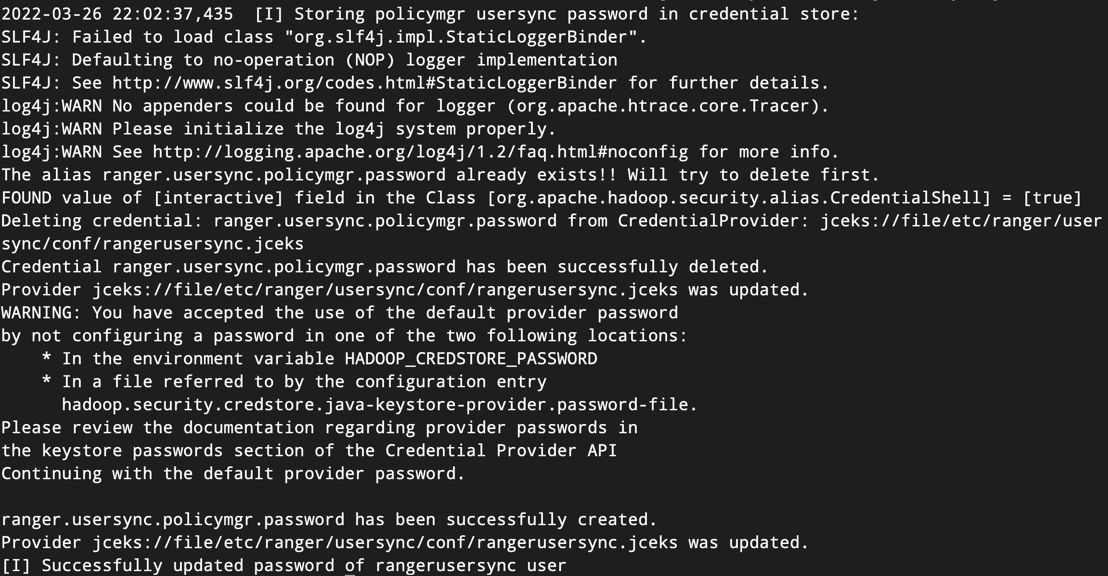
在Ranger Admin管理界面,出现如下所示的截图,表名安装成功。

4.配置Hive插件
4.1 启动插件
编辑install.properties文件,具体内容如下所示:
# 配置ranger admin的地址
POLICY_MGR_URL = http://nna:6080 # 配置hive的仓库名
REPOSITORY_NAME=hive-ranger # 配置hive组件的HIVE_HOME
COMPONENT_INSTALL_DIR_NAME=/data/soft/new/hive # 配置ranger-hive-plugin的所属用户、用户组
CUSTOM_USER=hadoop
CUSTOM_GROUP=hadoop
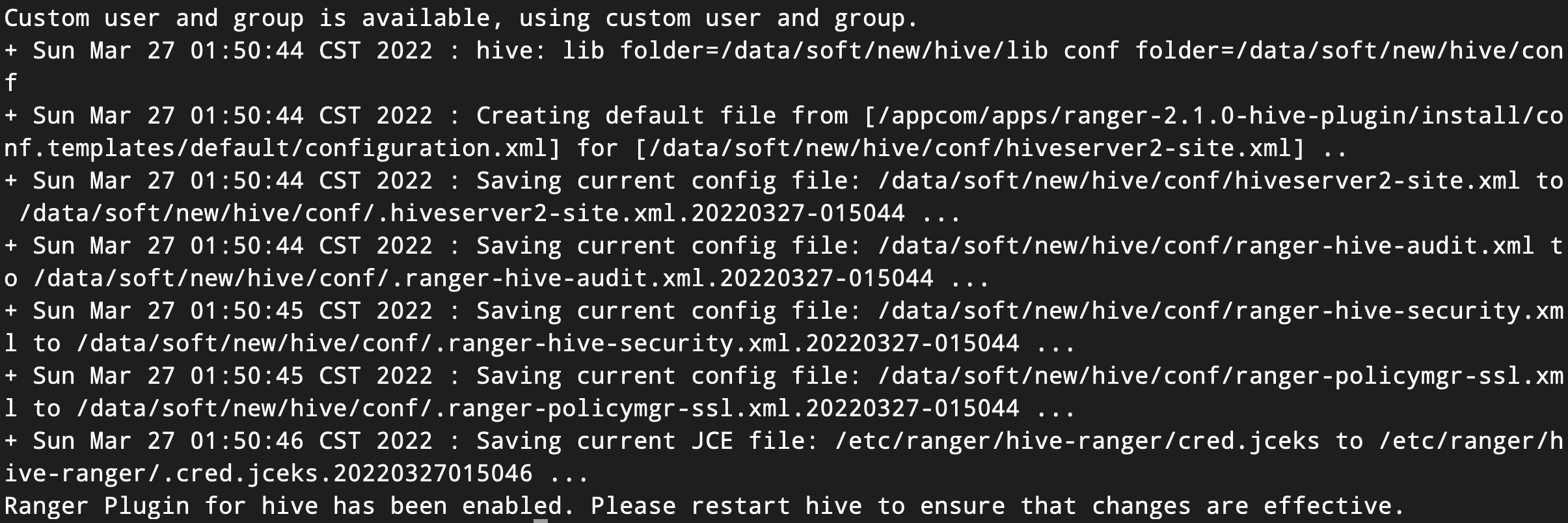
执行enable-hive-plugin.sh脚本命令,使HDFS插件生效。结果如下图所示:
4.2 创建新用户
在一台Hadoop的Client节点上创建一个新用户(hduser1024),具体操作命令如下所示:
# 新增一个用户
[hadoop@nna ~]$ adduser hduser1024
# 将新增的用户添加到已有的hadoop组中
[hadoop@nna ~]$ usermod -a -G hadoop hduser1024
# 复制hadoop用户下的环境变量
[hadoop@nna ~]$ cp /home/hadoop/.bash_profile /home/hduser1024/
进入Ranger Admin管理界面添加新用户,如下图所示:
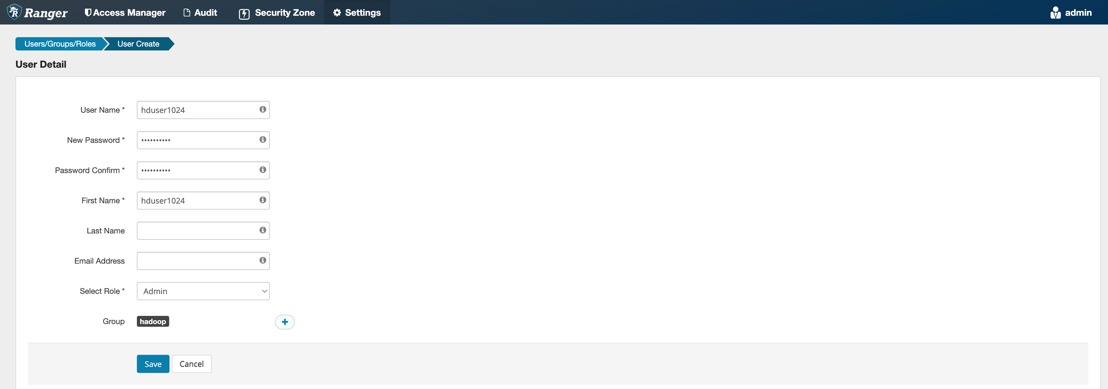
4.3 配置Hive策略
在Ranger Admin中选择Hive策略模块,配置内容如下图所示:
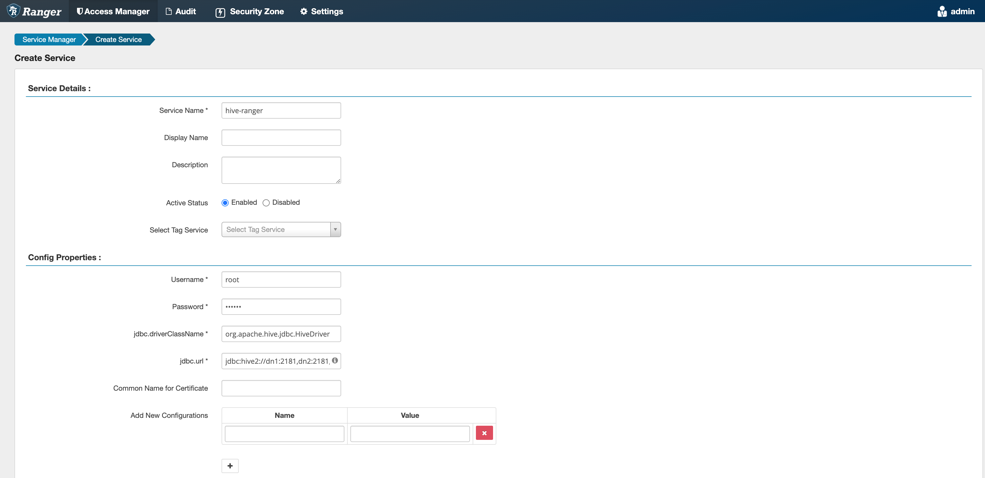
这里策略名称、用户名和密码可以任意填写,JDBC驱动类和URL地址填写内容如下所示:
# 驱动类
org.apache.hive.jdbc.HiveDriver # URL地址,使用Zookeeper模式连接方式
jdbc:hive2://dn1:2181,dn2:2181,dn3:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
接着,进入到具体的数据库、表以及列的权限设置页面,如下图所示:
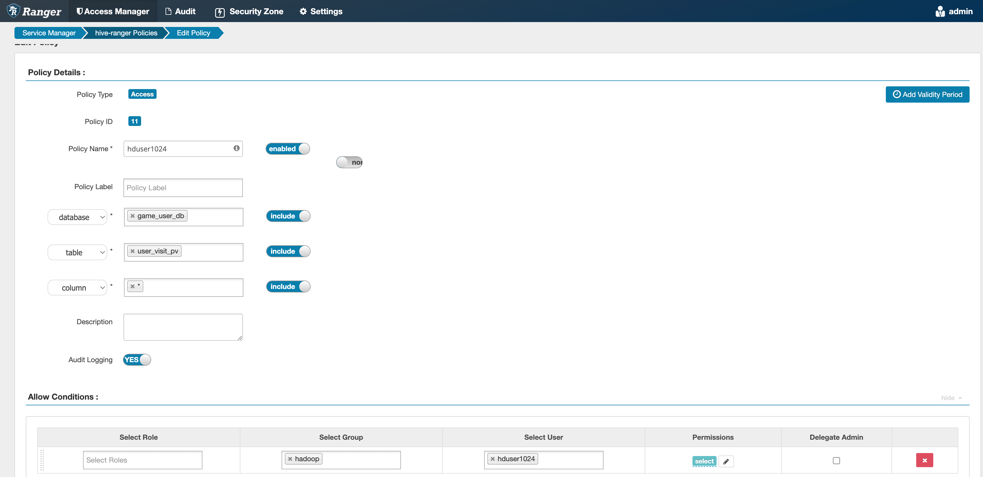
4.4 Hive表权限验证
设置数据库game_user_db,选择表user_visit_pv,然后指定该表下的所有列(使用*号)授予hduser1024用户拥有查询权限(select)。接着,我们可以在Hive的客户端中执行查询语句验证权限:
# 进入到Hive客户端,并切换到指定数据库
hive> use game_user_db;
# 查询表内容
hive> select * from user_visit_pv limit 2;
结果如下所示:

然后,我们进入到Hive策略中,修改只授予hduser1024用户读取uid字段的权限:
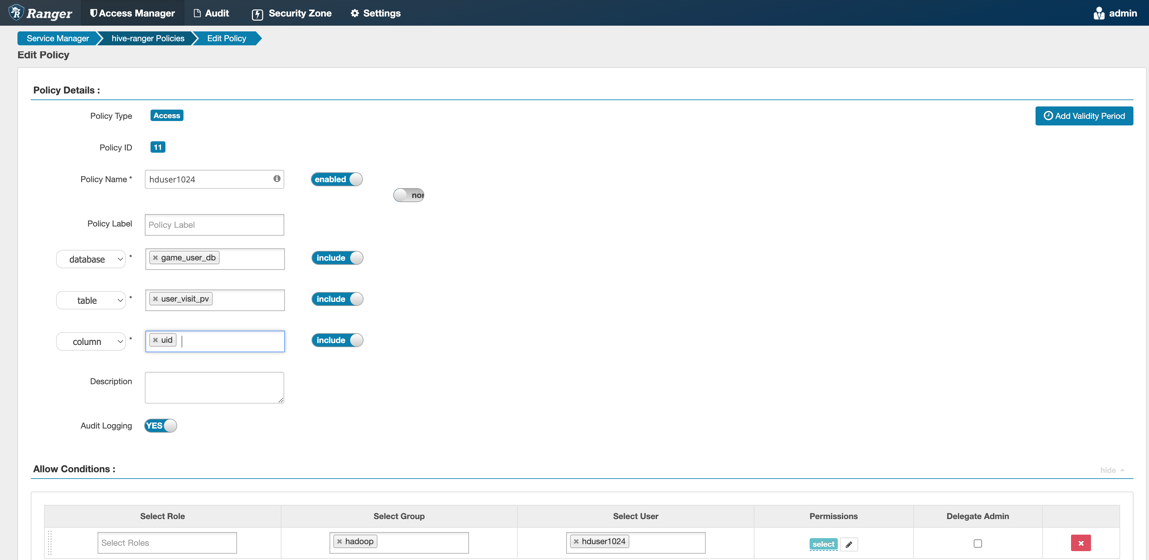
接着,我们可以在Hive的客户端中执行查询语句验证权限:
# 进入到Hive客户端,并切换到指定数据库
hive> use game_user_db;
# 查询表内容
hive> select uid from user_visit_pv limit 2;
hive> select uid,pv from user_visit_pv limit 2;
结果如下图所示:
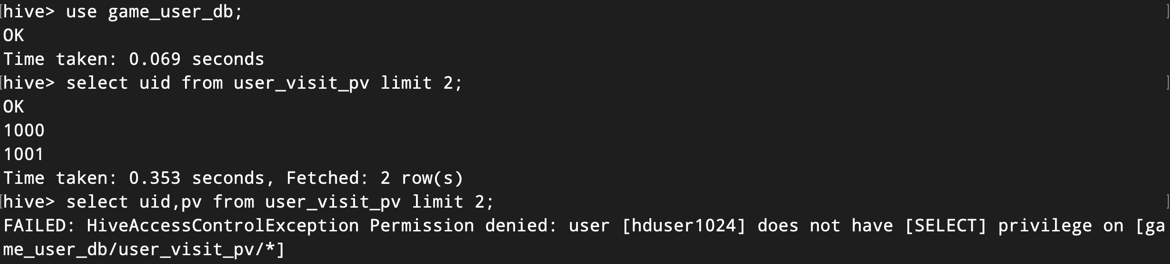
可以看到hduser1024用户只拥有读取uid字段的权限,读取pv字段则会抛出权限异常的错误。
5.总结
综合考虑,Apache Ranger能够很好的和现有系统集成,比如:
- 支持多组件,比如HDFS、Hive、Kafka等,基本能覆盖现有大数据组件;
- 支持日志审计,便于问题排查;
- 用于自己的用户管理体系,方便和其他系统集成。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
Apache Ranger安装部署的更多相关文章
- Ranger安装部署 - solr安装
1. 概述 Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库: Solr是以Lucene为基础实现的文本检索应用服务.Solr部署方式有单机方式.多机Master-Slaver方法. ...
- Ranger安装部署
1. 概述 Apache Ranger是大数据领域的一个集中式安全管理框架,目的是通过制定策略(policies)实现对Hadoop组件的集中式安全管理.用户可以通过Ranger实现对集群中数据的安全 ...
- Apache Kylin安装部署
0x01 Kylin安装环境 Kylin依赖于hadoop大数据平台,安装部署之前确认,大数据平台已经安装Hadoop, HBase, Hive. 1.1 了解kylin的两种二进制包 预打包的二进制 ...
- Apache Hama安装部署
安装Hama之前,应该首先确保系统中已经安装了hadoop,本集群使用的版本为hadoop-2.3.0 一.下载及解压Hama文件 下载地址:http://www.apache.org/dyn/clo ...
- Apache的安装部署 2(加密认证 ,网页重写 ,搭建论坛)
一.http和https的基本理论知识1. 关于https: HTTPS(全称:Hypertext Transfer Protocol Secure,超文本传输安全协议),是以安全为目标的HTTP通道 ...
- Apache Ranger 编译安装部署
1. 概述 Apache Ranger是大数据领域的一个集中式安全管理框架,目的是通过制定策略(policies)实现对Hadoop组件的集中式安全管理.用户可以通过Ranger实现对集群中数据的安全 ...
- Apache Solr 初级教程(介绍、安装部署、Java接口、中文分词)
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- 安装部署Apache Hadoop (本地模式和伪分布式)
本节内容: Hadoop版本 安装部署Hadoop 一.Hadoop版本 1. Hadoop版本种类 目前Hadoop发行版非常多,有华为发行版.Intel发行版.Cloudera发行版(CDH)等, ...
- Apache入门篇(一)之安装部署apache
一.HTTPD特性 (1)高度模块化:core(核心) + modules(模块) = apache(2)动态模块加载DSO机制: Dynamic Shared Object(动态共享对象)(3)MP ...
随机推荐
- 通过Dapr实现一个简单的基于.net的微服务电商系统(二十)——Saga框架实现思路分享
今天这篇博文的主要目的是分享一下我设计Saga的实现思路来抛砖引玉,其实Saga本身非常的类似于一个简单的工作流体系,相比工作流不一样的部分在于它没有工作流的复杂逻辑处理机制(比如会签),没有条件分支 ...
- 掌握这20个JS技巧,做一个不加班的前端人
摘要:JavaScript 真的是一门很棒的语言,值得学习和使用.对于给定的问题,可以有不止一种方法来达到相同的解决方案.在本文中,我们将只讨论最快的. 本文分享自华为云社区<提高代码效率的 2 ...
- 使用Java的GUI技术实现 “ 贪吃蛇 ” 游戏
详细教程: 使用Java的GUI技术实现 " 贪吃蛇 " 游戏_IT打工酱的博客-CSDN博客
- .Net Core AOP之AuthorizeAttribute
一.简介 在.net core 中Filter分为以下六大类: 1.AuthorizeAttribute(权限验证) 2.IResourceFilter(资源缓存) 3.IActionFilter(执 ...
- OpenGL ES 3D空间中自定义显示空间
在Android中,我们所熟知的是在ES管线中,其在图元装配时,会进行图元组装与图元分配,这样就回剪裁出来视景体中的物体.但是如果我想在3D场景中规定一个区域,凡是在这个区域中的物体就能显示出来,非这 ...
- RENIX 软件如何进行IP地址管理——网络测试仪实操
本文主要介绍了BIGTAO网络测试仪如何通过RENIX软件进行IP地址管理.文章分为五部分内容,第一部分介绍了如何通过机框显示屏查看IP地址,之后几部分分别介绍了机框按钮修改.机框接显示器/键盘修改. ...
- Linux性能优化实战CPU篇之软中断(三)
一.软中断 1,中断的定义 a>定义 举例:你点了一份外卖,在无法获知外卖进度的情况下,配送员送外卖是不等人的,到了发现没人取会直接走,所以你只能苦苦等着,时不时去门口看送到没有,无法干别的事情 ...
- 【C#操作符】typeof 和 is 运算符执行的类型检查之间的差异
typeof 运算符也能用于公开的泛型类型.具有不止一个类型参数的类型的规范中必须有适当数量的逗号.不能重载 typeof 运算符. is 可以检测和父类是否兼容,typeof责不能 public c ...
- netty系列之:EventExecutor,EventExecutorGroup和netty中的实现
目录 简介 EventExecutorGroup EventExecutor EventExecutorGroup在netty中的基本实现 EventExecutor在netty中的基本实现 总结 简 ...
- Oracle数据库对象(表空间/同义词/序列/视图/索引)
数据库对象 Oracle数据库对象: 数据库对象是数据库的组成部分,常常用 CREATE 命令进行创建,可以使用 ALTER 命令修改,用 DROP 执行删除操作. 种类: (1)表空间:所有的数据对 ...