[排序算法] 堆排序 (C++)
堆排序解释
什么是堆
堆 heap 是一种近似完全二叉树的数据结构,其满足一下两个性质
1. 堆中某个结点的值总是不大于(或不小于)其父结点的值;
2. 堆总是一棵完全二叉树
将根结点最大的堆叫做大根堆(大项堆),根结点最小的堆叫做小根堆(小项堆)。
堆排序原理
我们一般用大根堆对数组进行正向排序喔
首先将当前的无序数组构成一个无序堆,对于每个元素在堆中对应的下标,由二叉树数组表示法可得
若一个节点的下标为 i,那么其左孩子节点下标为 2 * i + 1,右孩子节点下标为 2 * i + 2。
然后我们再将当前的无序堆进行不断调整,直到最后构造成 大根堆。
之后交换首尾元素,即将当前堆顶的最大元素交换到末尾,这时此元素就完成了归位。
交换完首尾元素后,此时的堆再次变成一个无序堆,需要再次堆对剩余元素进行调整,使其重新变成 大根堆。
重复上述的操作,直至堆的大小为 1,最后所有的元素都交换结束,即完成了堆排序。
堆排序动态演示
我们以 [4,7,3,1,6,2,5] 为例进行动态演示
构成无序堆
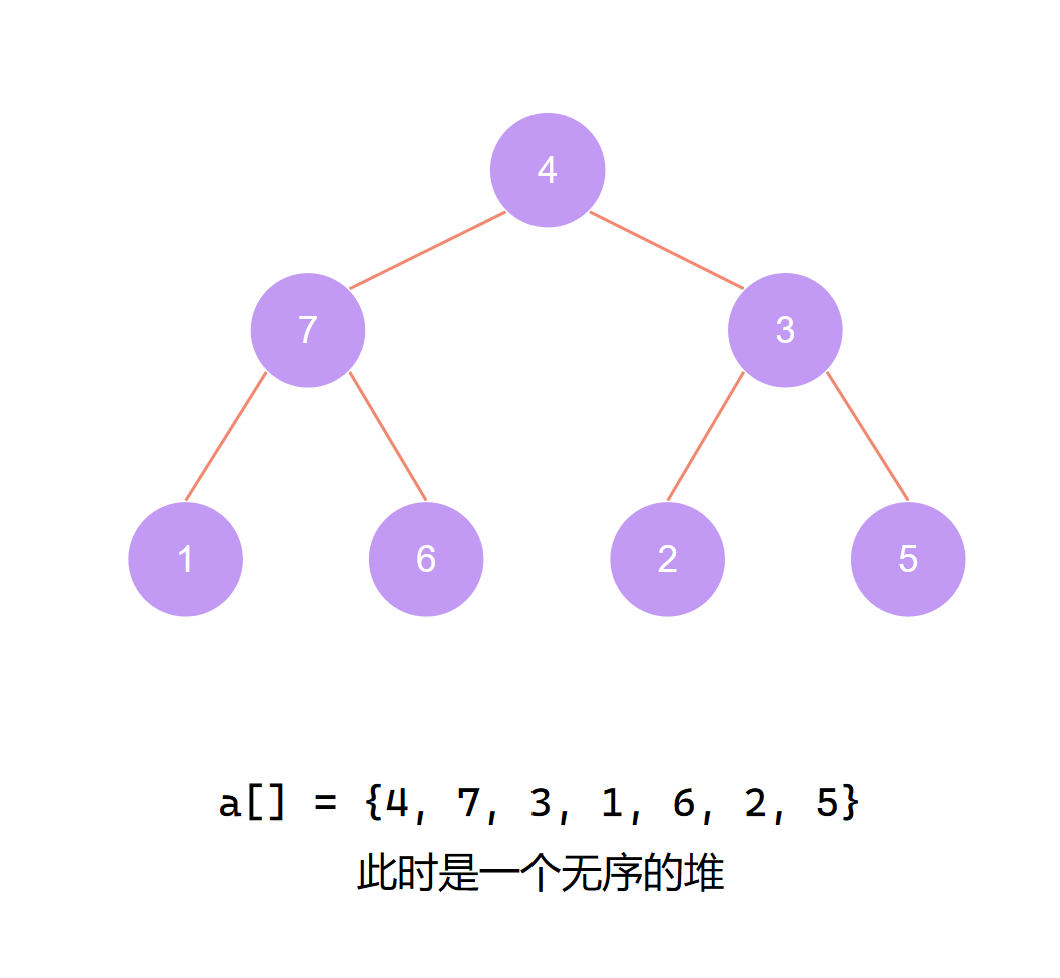
从最后一个非叶子节点开始 调整堆
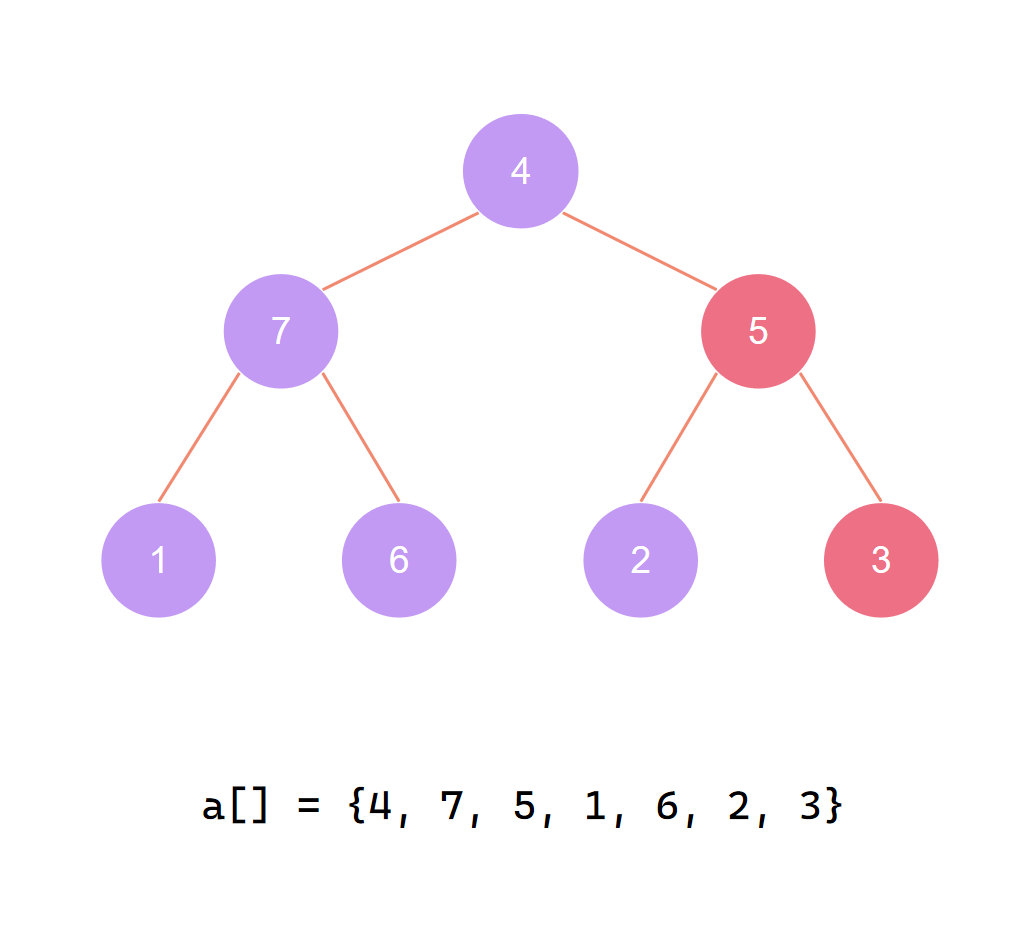
对倒数第二个非叶子节点 调整堆 此时我们发现无需调整
对最后一个非叶子节点 调整堆
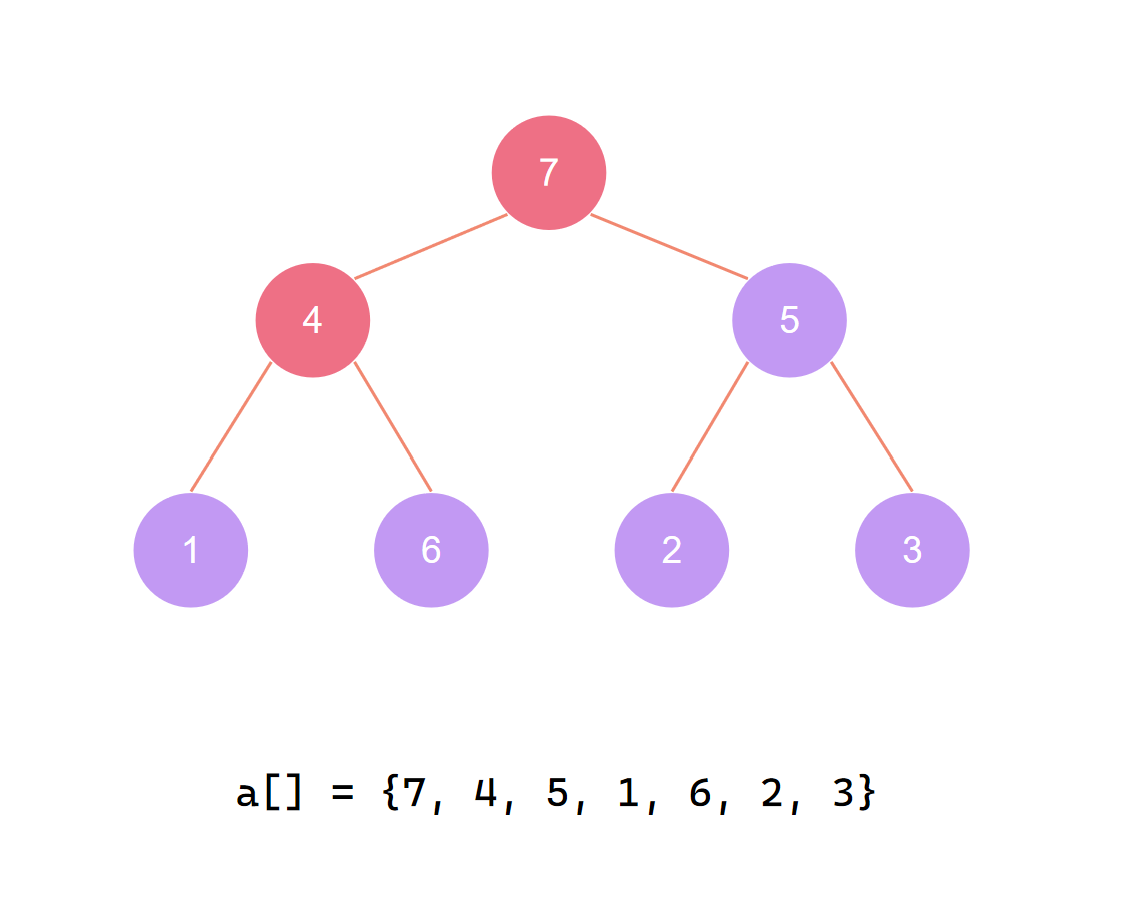
这时当前根节点的左节点由于调整不满足大根堆性质 需递归调整
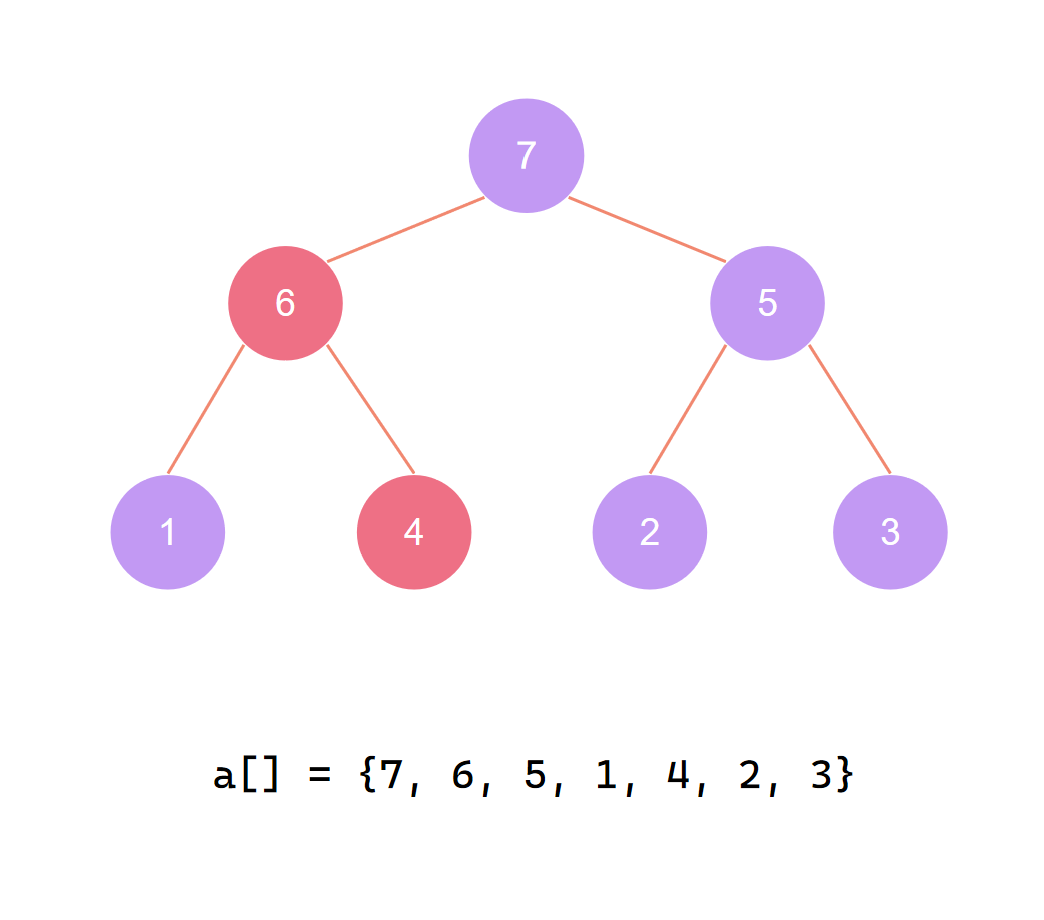
大根堆构建完成
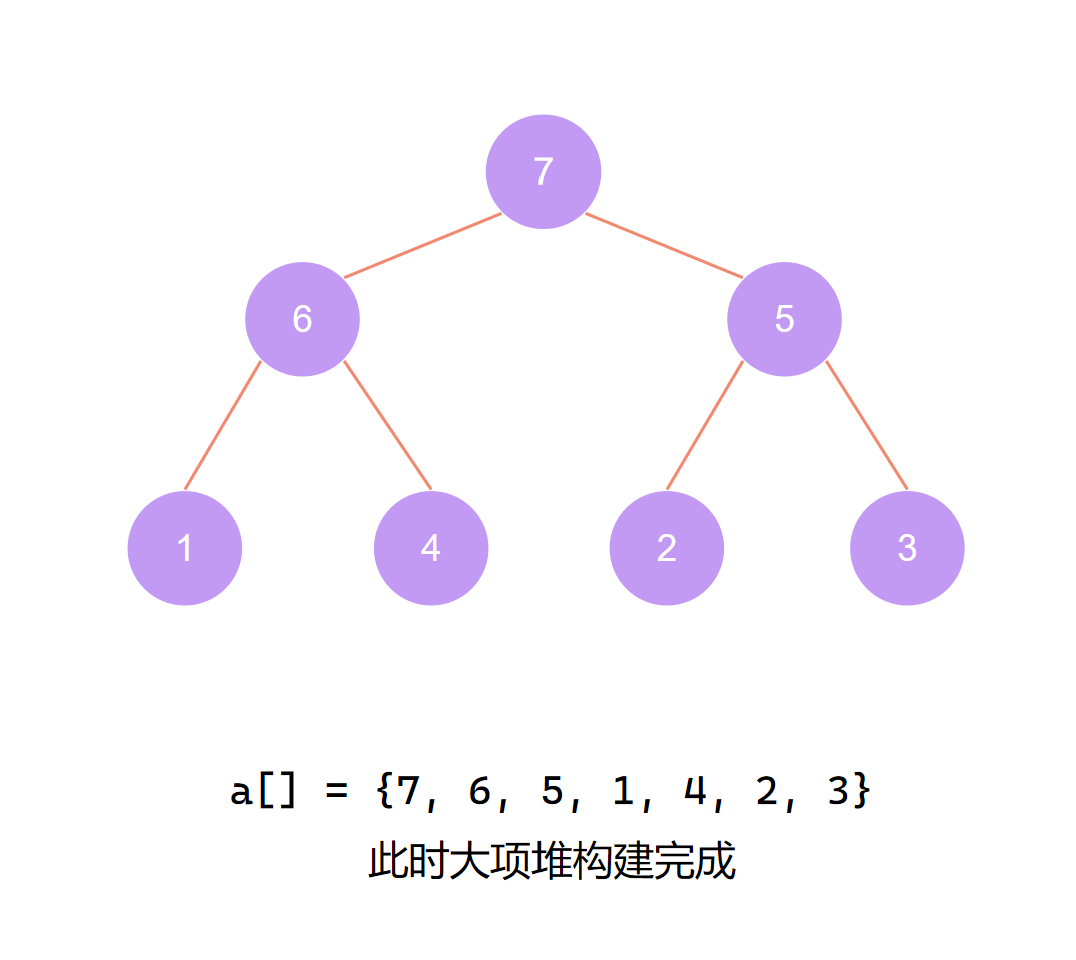
交换首尾 第一个元素归位
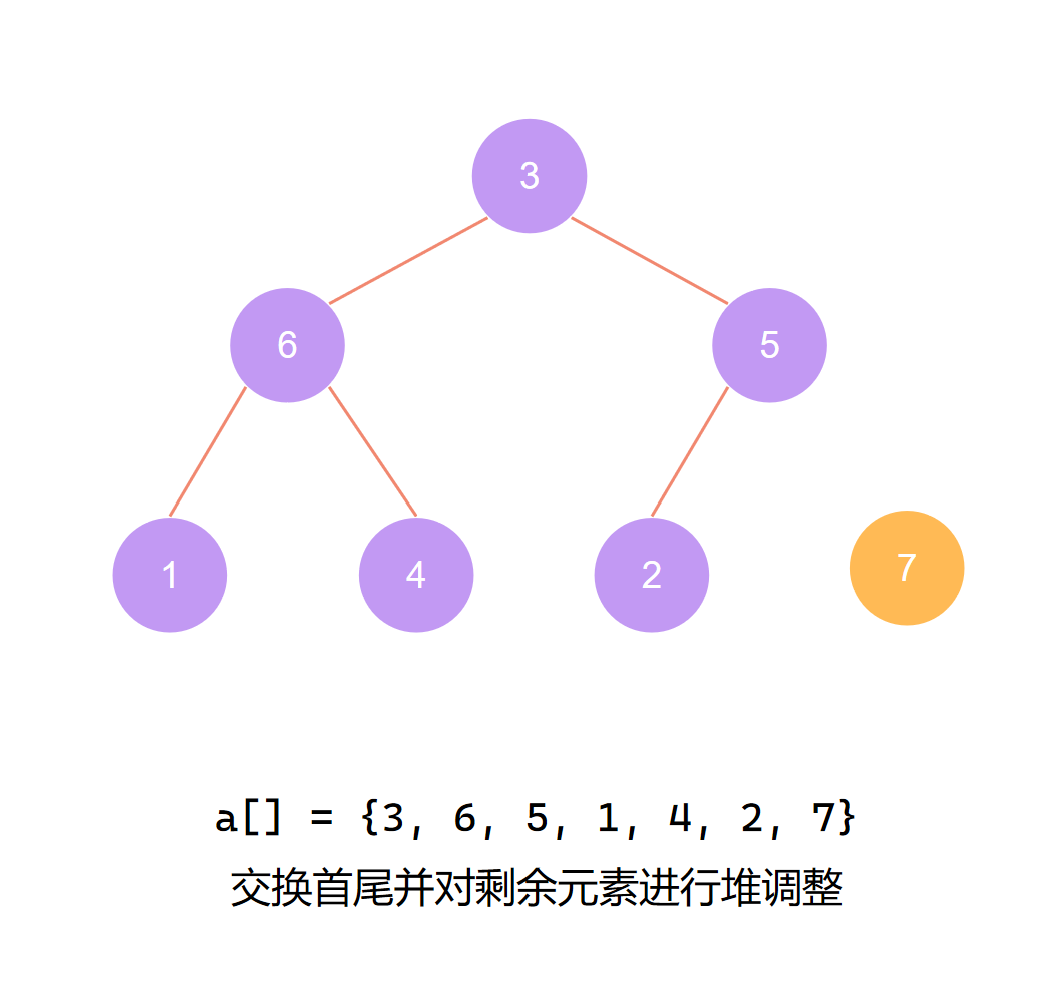
第一个元素归位后 再度调整(1)
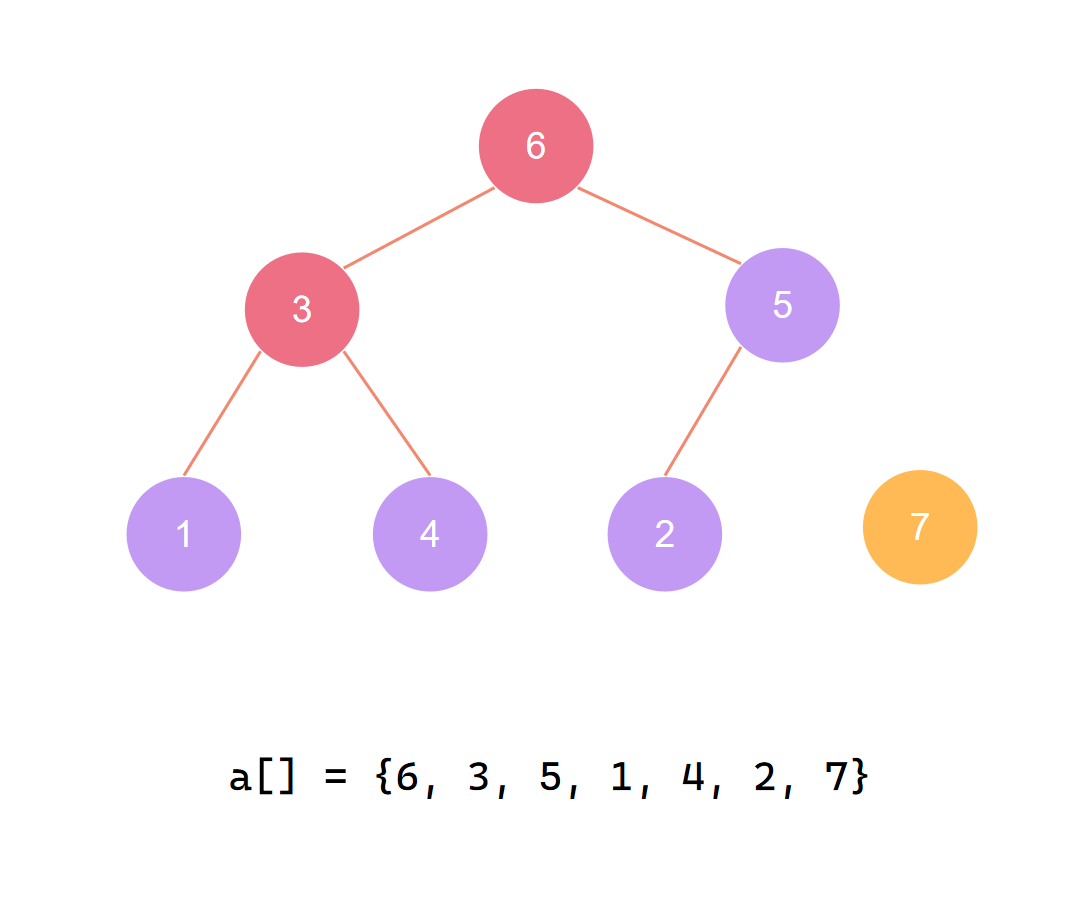
第一个元素归位后 再度调整(2)
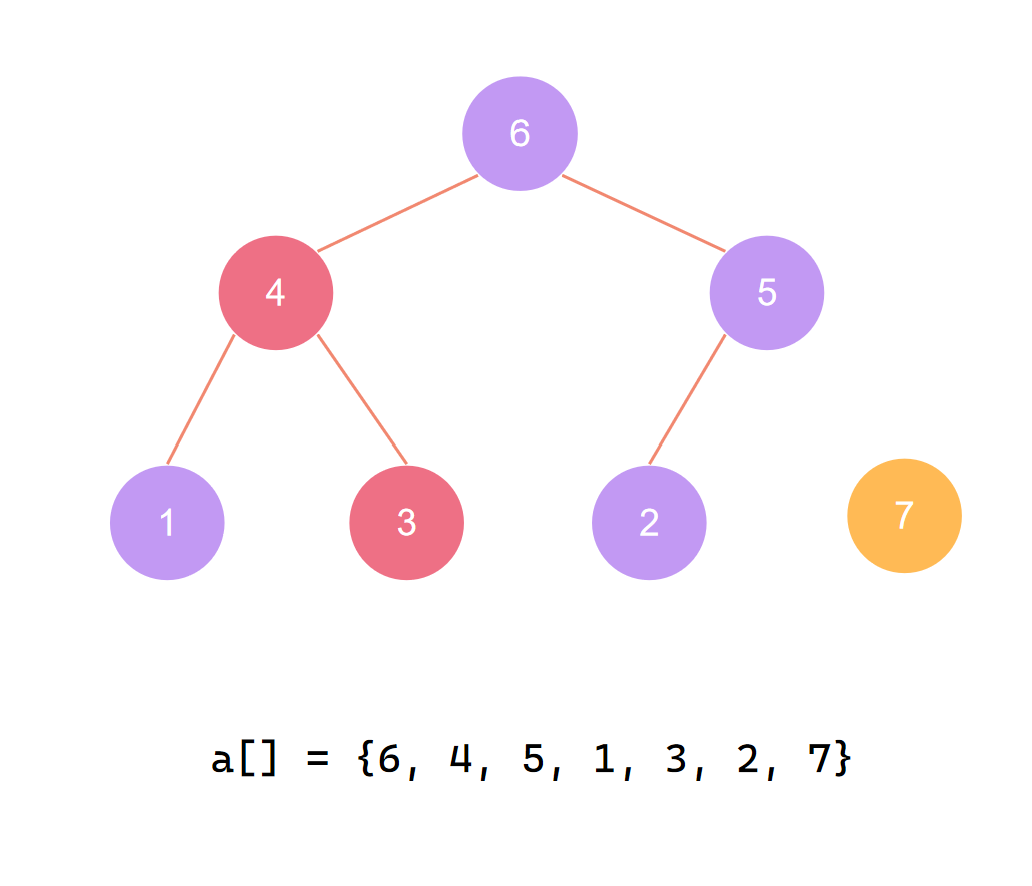
交换首尾 第二个元素归位
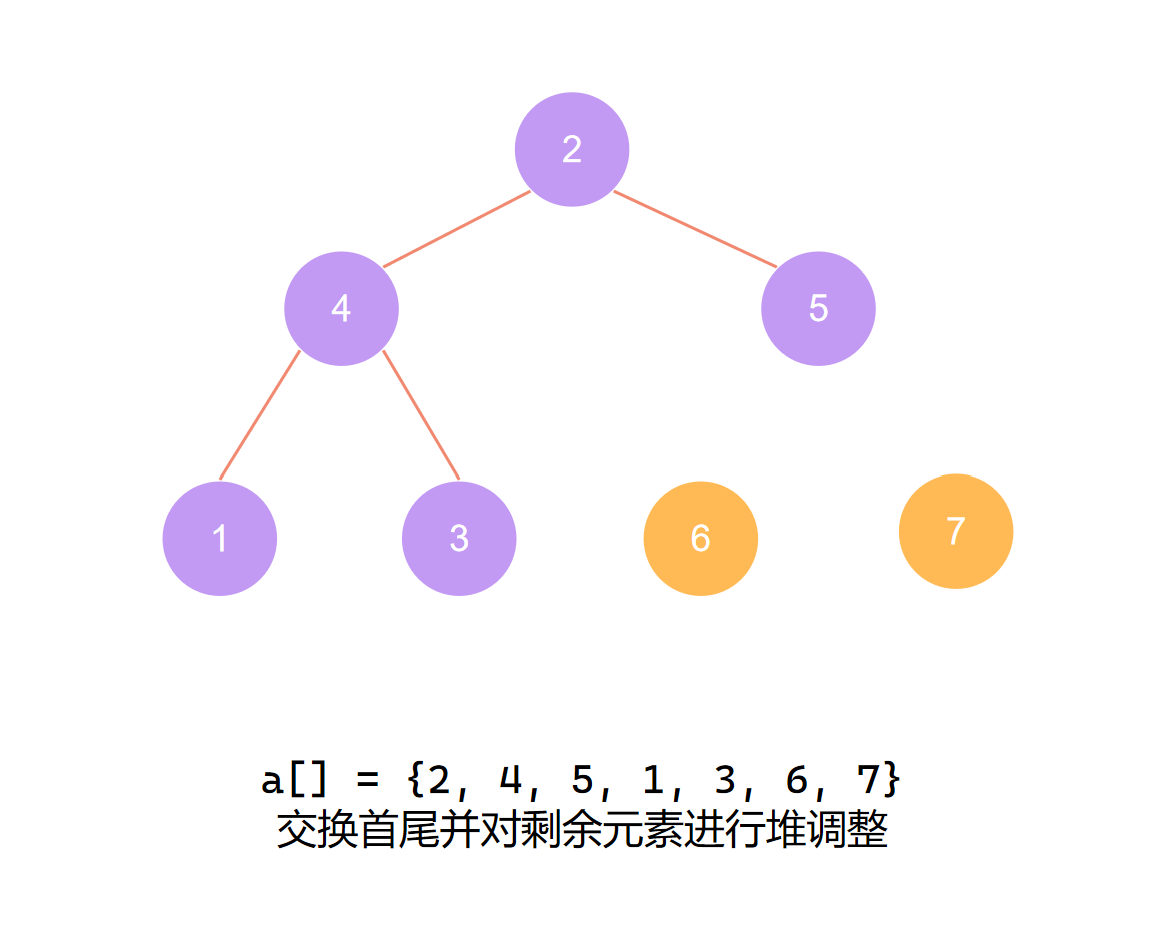
第二个元素归位后 再度调整
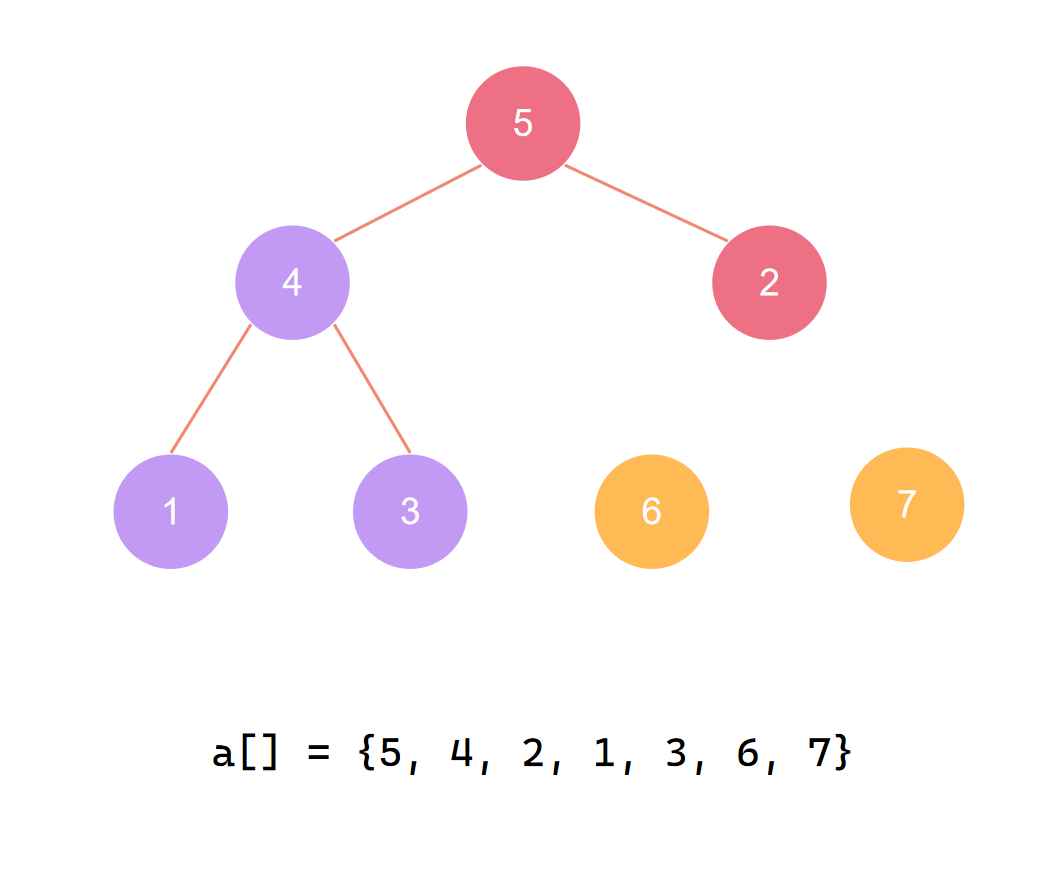
交换首尾 第三个元素归位
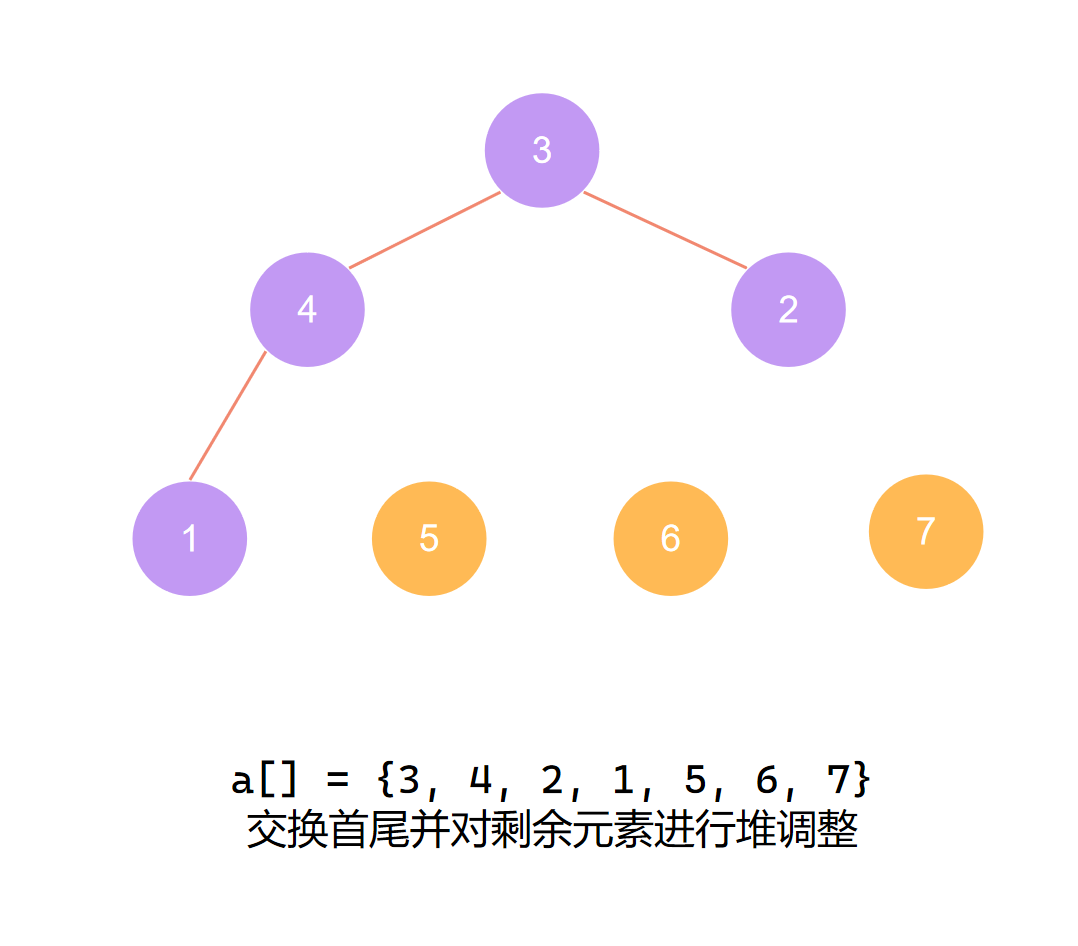
第三个元素归位后 再度调整
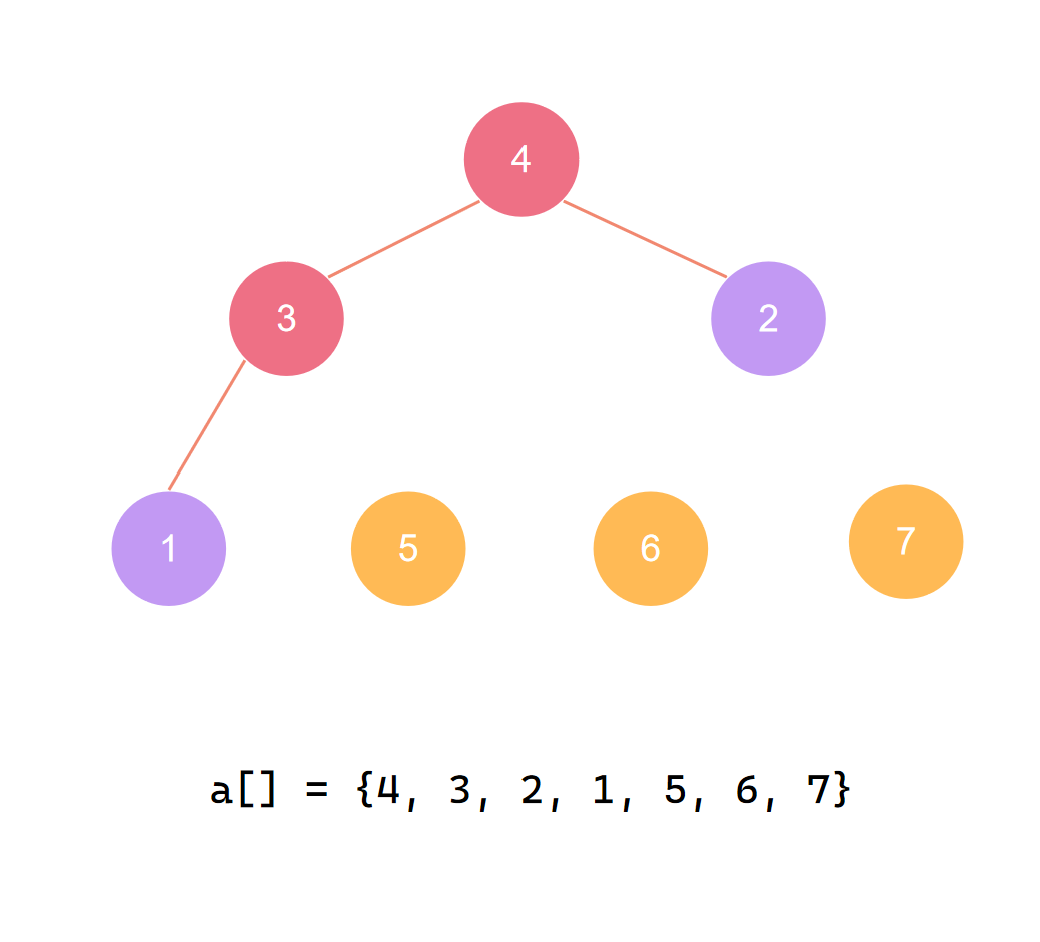
交换首尾 第四个元素归位
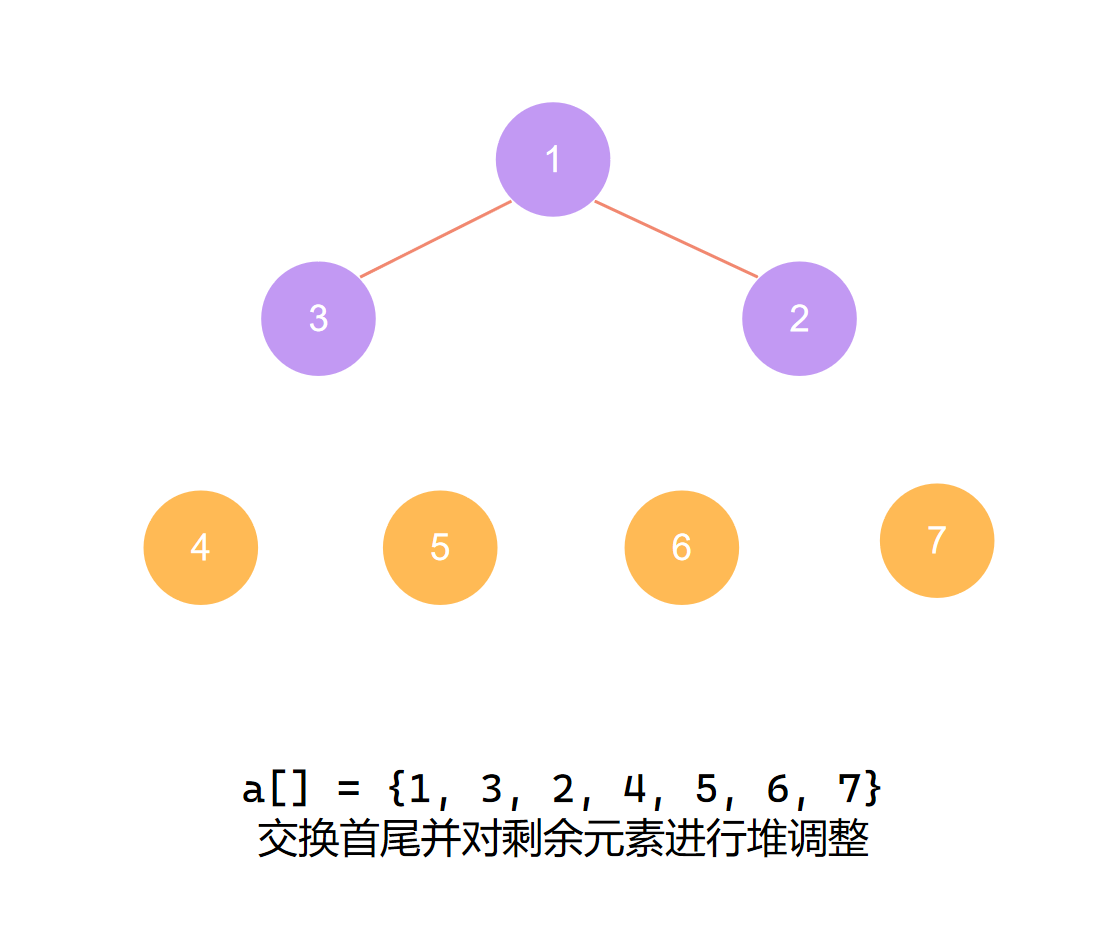
第四个元素归位后 再度调整
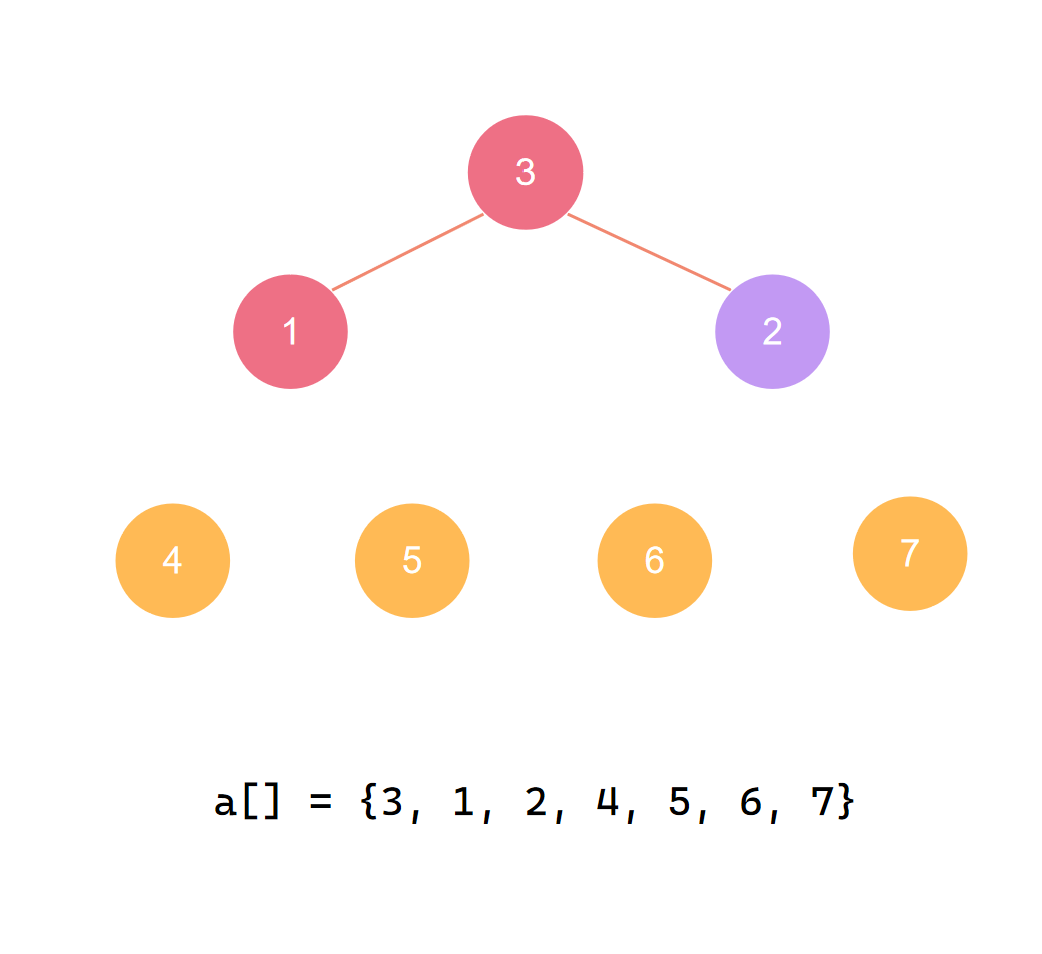
交换首尾 第五个元素归位
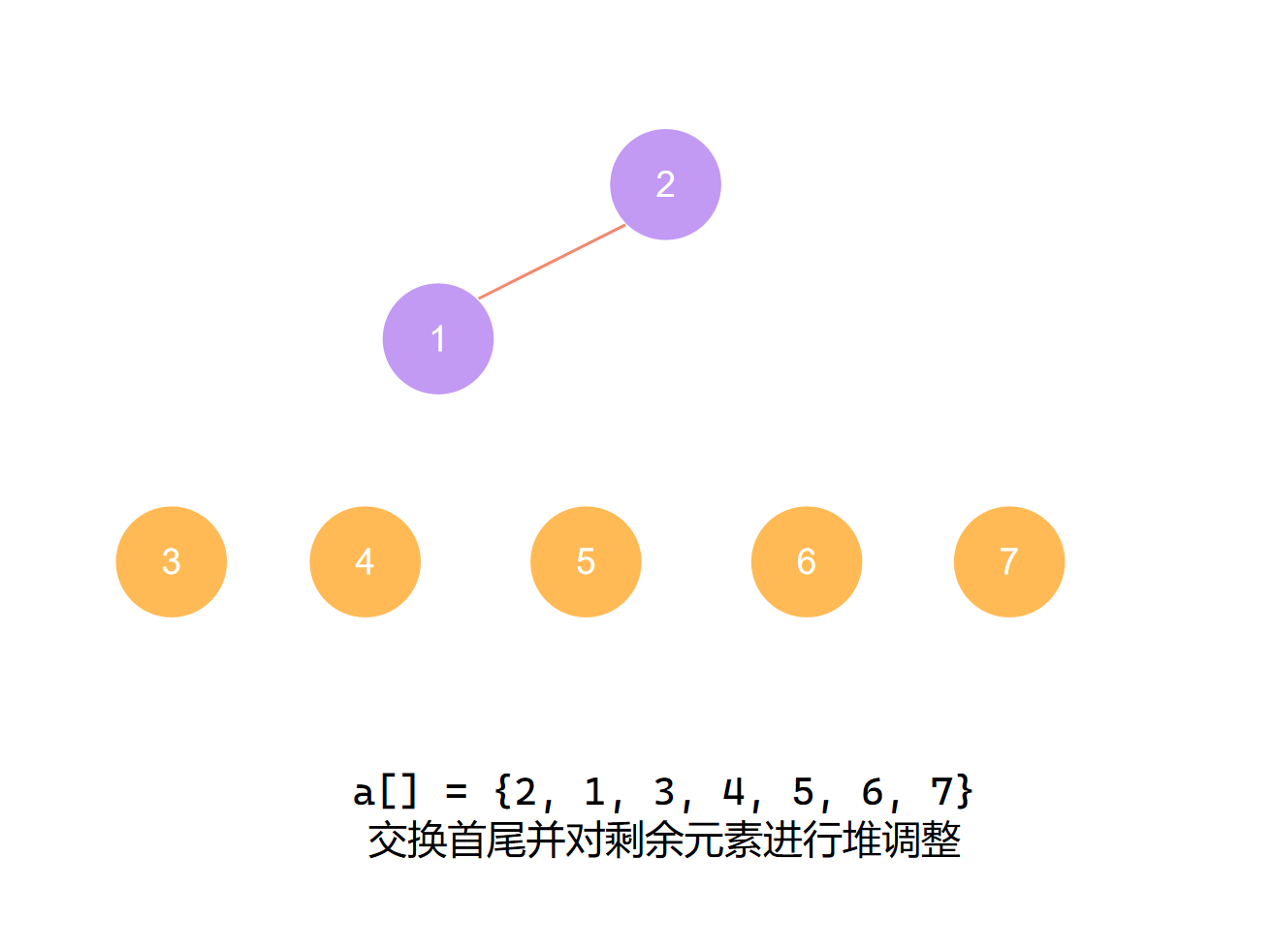
交换首尾 第六个元素归位
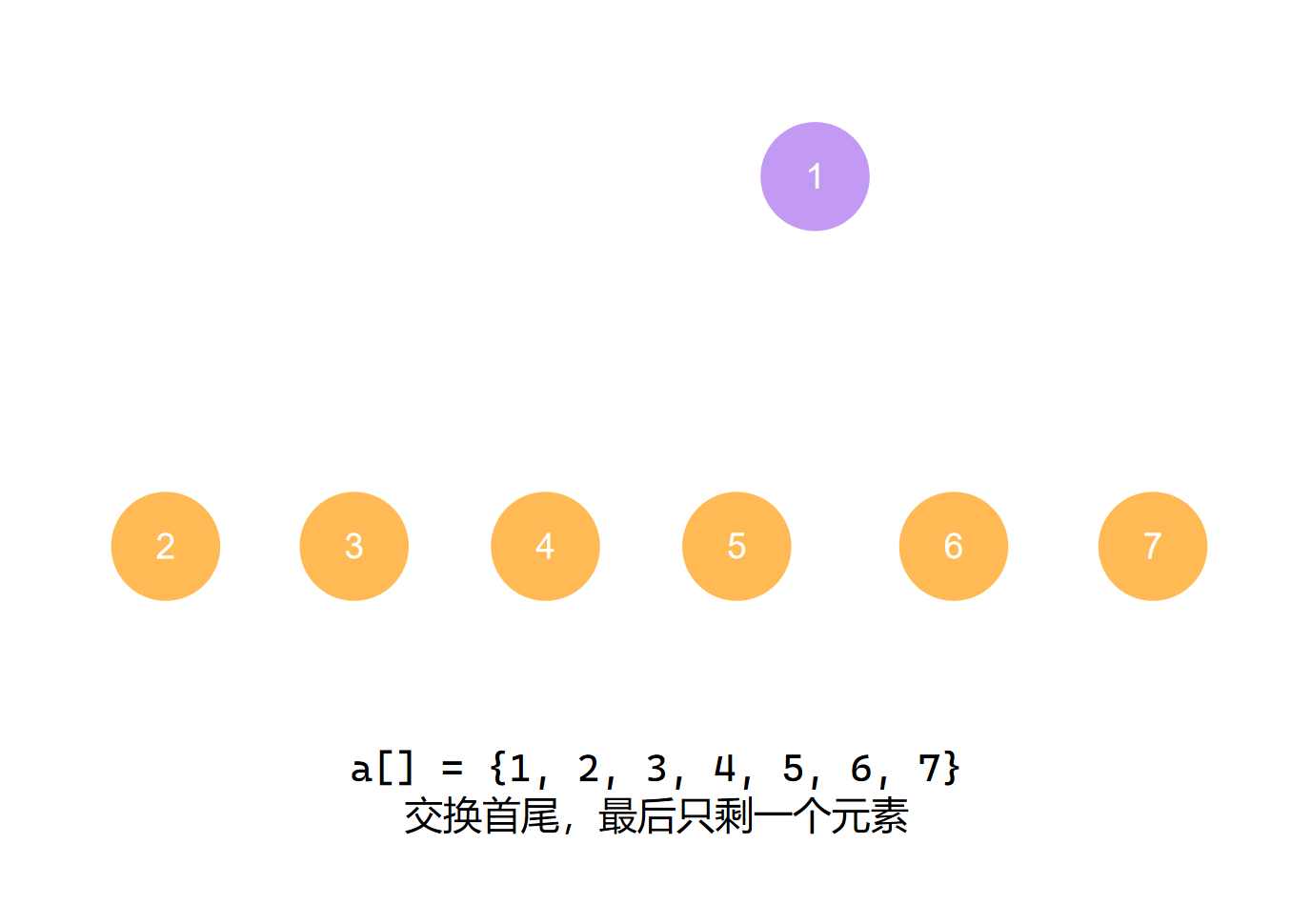
最后堆大小为1,排序完成
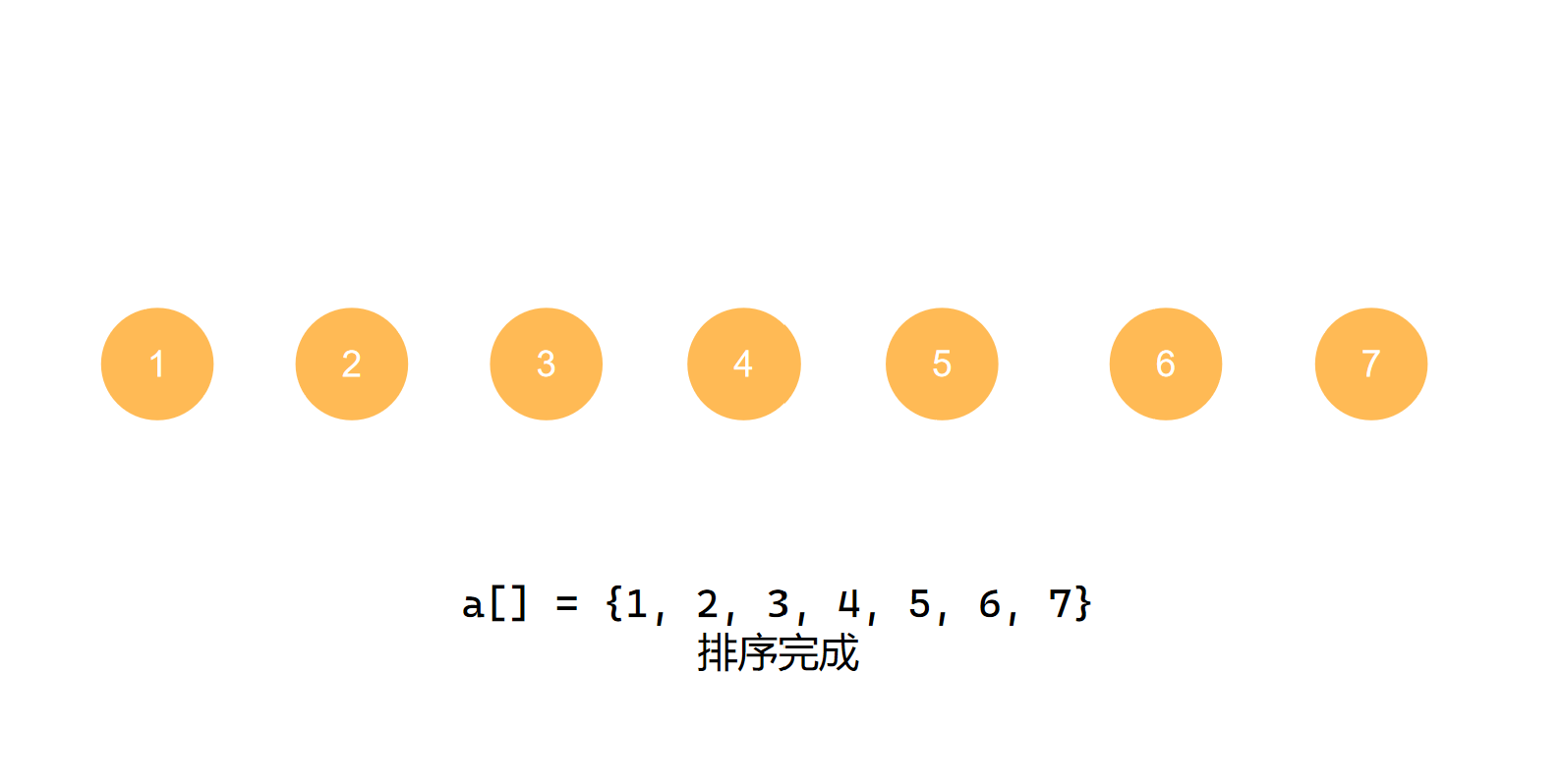
堆排序时间复杂度
构建初始的大根堆时间复杂度为O(n),
交换及重建大顶堆的过程中,需要交换n-1次,重建大顶堆的过程根据完全二叉树,log2(n-1),log2(n-2)...1 近似为nlogn。
堆排序核心代码
//调整堆
void Heapify(vector<int> &v, int i, int len){
int left = 2 * i + 1, right = 2 * i + 2; //二叉树当前节点的左右节点的索引
int maxindex = i; //先默认i为最大值索引 即当前非叶子节点
if(left < len && v[left] > v[maxindex]) //如果有左节点且左节点值更大
maxindex = left;
if(right < len && v[right] > v[maxindex]) //如果有右节点且右节点值更大
maxindex = right;
if(maxindex != i){
//发现最大值并非当前非叶子节点,则需调整 即交换最大值到非叶子节点处
swap(v[i], v[maxindex]);
//互换之后,子节点值发生变化,子节点若也有其子节点,则需继续调整其子结构
Heapify(v, maxindex, len); //递归 调整堆
}
}
//无序数组 构建大根堆
void BuildMaxHeap(vector<int> &v, int len){
//从最后一个非叶子节点开始遍历,调整每个子结构,构建形成大根堆
for(int i = len / 2 - 1; i >= 0; i--)
Heapify(v, i, len);
}
//堆排序
void HeapSort(vector<int> &v){
int len = v.size();
BuildMaxHeap(v, len); //构建大根堆
while(len > 1){
swap(v[0], v[len - 1]); //交换首尾数据 尾部最大 且出现在合适位置
Heapify(v, 0, --len); //重置大根堆
}
}
完整程序源代码
#include<iostream>
#include<vector>
#include<ctime>
using namespace std;
//调整堆
void Heapify(vector<int> &v, int i, int len){
int left = 2 * i + 1, right = 2 * i + 2; //二叉树当前节点的左右节点的索引
int maxindex = i; //先默认i为最大值索引 即当前非叶子节点
if(left < len && v[left] > v[maxindex]) //如果有左节点且左节点值更大
maxindex = left;
if(right < len && v[right] > v[maxindex]) //如果有右节点且右节点值更大
maxindex = right;
if(maxindex != i){
//发现最大值并非当前非叶子节点,则需调整 即交换最大值到非叶子节点处
swap(v[i], v[maxindex]);
//互换之后,子节点值发生变化,子节点若也有其子节点,则需继续调整其子结构
Heapify(v, maxindex, len); //递归 调整堆
}
}
//无序数组 构建大根堆
void BuildMaxHeap(vector<int> &v, int len){
//从最后一个非叶子节点开始遍历,调整每个子结构,构建形成大根堆
for(int i = len / 2 - 1; i >= 0; i--)
Heapify(v, i, len);
}
//堆排序
void HeapSort(vector<int> &v){
int len = v.size();
BuildMaxHeap(v, len); //构建大根堆
while(len > 1){
swap(v[0], v[len - 1]); //交换首尾数据 尾部最大 且出现在合适位置
Heapify(v, 0, --len); //重置大根堆
}
}
//打印数据
void show(vector<int> &v){
for(auto &x : v)
cout<<x<<" ";
cout<<endl;
}
main(){
vector<int> v;
srand((int)time(0));
int n = 50;
while(n--)
v.push_back(rand() % 100 + 1);
show(v);
HeapSort(v);
cout<<endl<<endl;
show(v);
}
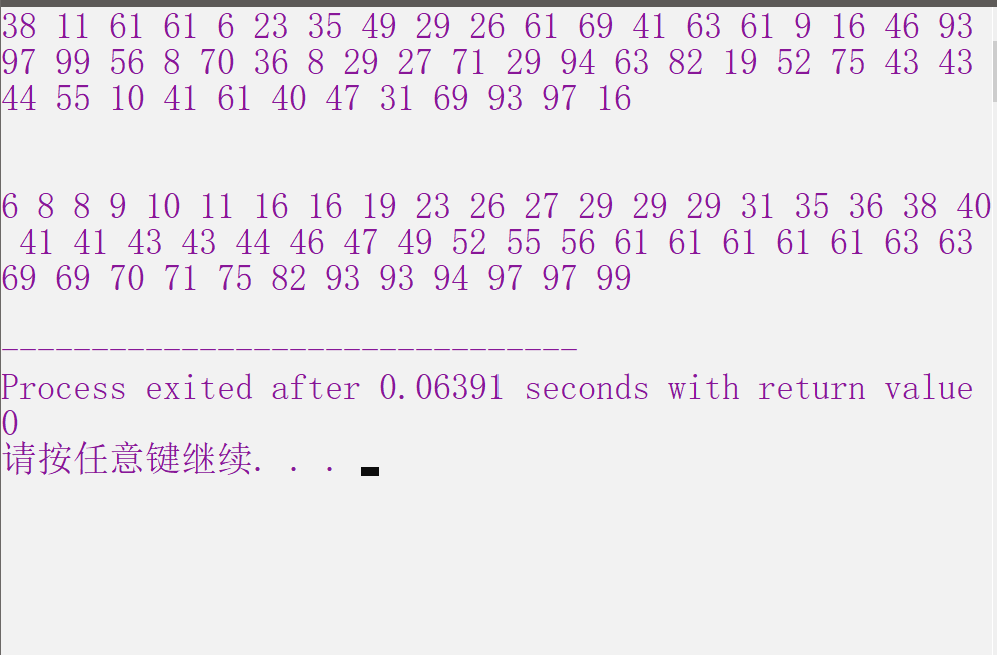
程序运行结果图
[排序算法] 堆排序 (C++)的更多相关文章
- 使用 js 实现十大排序算法: 堆排序
使用 js 实现十大排序算法: 堆排序 堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法. 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列: 小顶堆:每个 ...
- 八大排序算法——堆排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演示 二.思路分析 先来了解下堆的相关概念:堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆:或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆.如 ...
- 排序算法-堆排序(Java)
package com.rao.linkList; import java.util.Arrays; /** * @author Srao * @className HeapSort * @date ...
- JavaScript排序算法——堆排序
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Java排序算法——堆排序
堆排序 package sort; public class Heap_Sort { public static void main(String[] args) { // TODO 自动生成的方法存 ...
- 七种常见经典排序算法总结(C++实现)
排序算法是非常常见也非常基础的算法,以至于大部分情况下它们都被集成到了语言的辅助库中.排序算法虽然已经可以很方便的使用,但是理解排序算法可以帮助我们找到解题的方向. 1. 冒泡排序 (Bubble S ...
- Java常见排序算法之堆排序
在学习算法的过程中,我们难免会接触很多和排序相关的算法.总而言之,对于任何编程人员来说,基本的排序算法是必须要掌握的. 从今天开始,我们将要进行基本的排序算法的讲解.Are you ready?Let ...
- 排序算法c语言描述---堆排序
排序算法系列学习,主要描述冒泡排序,选择排序,直接插入排序,希尔排序,堆排序,归并排序,快速排序等排序进行分析. 文章规划: 一.通过自己对排序算法本身的理解,对每个方法写个小测试程序.具体思路分析不 ...
- 七内部排序算法汇总(插入排序、Shell排序、冒泡排序、请选择类别、、高速分拣合并排序、堆排序)
写在前面: 排序是计算机程序设计中的一种重要操作,它的功能是将一个数据元素的随意序列,又一次排列成一个按keyword有序的序列.因此排序掌握各种排序算法很重要. 对以下介绍的各个排序,我们假定全部排 ...
- Java排序算法之堆排序
堆的概念: 堆是一种完全二叉树,非叶子结点 i 要满足key[i]>key[i+1]&&key[i]>key[i+2](最大堆) 或者 key[i]<key[i+1] ...
随机推荐
- Nginx_Mac安装时使用
Mac 上安装和使用Nginx 1. 安装Nginx brew install nginx 2. 启动Nginx nginx 其他命令 重启Nginx nginx -s reload 关闭(停止)Ng ...
- 华南理工大学 Python第3章课后小测-1
1.(单选)给出如下代码 s = 'Hello scut' print(s[::-1]) 上述代码的输出结果是(本题分数:4)A) HelloB) Hello scutC) olleH tucsD) ...
- SpringBoot 配置文件使用详解
一.创建一个SpringBoot项目 创建 SprintBoot 项目的 2 种方式: 在 https://start.spring.io/ 上创建一个 SpringBoot 项目,然后导入到 IDE ...
- 2、String类
String类 String 对象用于保存字符串,也就是一组字符序列 字符串常量对象是用双引号括起来的字符序列,例如:"你好"."12.07"."bo ...
- VLAN的配置
1 vlan的概念和作用 虚拟局域网(VLAN)是一组逻辑上的设备和用户,这些设备和用户并不受物理位置的限制,可以根据功能.部门等因素将它们组织起来.相互之间的通信就好像它们在同一个网段中一样. 虚拟 ...
- 延申三大问题中的第二个问题处理---收集查看k8s中pod的控制台日志
1.不使用logstash 2.步骤: 2.1 先获取一个文件的日志 2.2 再获取多个文件的日志 2.3 批量获取文件日志 pod日志文件路径 [root@worker hkd-eureka]# p ...
- Docker搭建自己的Gitlab CI Runner
转载自:https://cloud.tencent.com/developer/article/1010595 1.Gitlab CI介绍 CI:持续集成,我们通常使用CI来做一些自动化工作,比如程序 ...
- 阿里云服务器部署Web环境
一.配置阿里云服务器 进入阿里云官方网站(https://www.aliyun.com/). 初次使用的话使用支付宝快速注册账户,并进行个人实名认证. 点击试用中心. 选择第二个,云服务器2核4G. ...
- Go_Goroutine详解
Goroutine详解 goroutine的概念类似于线程,但 goroutine是由Go的运行时(runtime)调度和管理的.Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU ...
- 运行eeui项目不出现 WiFI真机同步 IP地址
从git上 clone项目之后,安装依赖 npm install eeui环境配置 npm install eeui-cli -g 问题:npm run dev 后项目一直不出现 WiFI真 ...