[排序算法] 堆排序 (C++)
堆排序解释
什么是堆
堆 heap 是一种近似完全二叉树的数据结构,其满足一下两个性质
1. 堆中某个结点的值总是不大于(或不小于)其父结点的值;
2. 堆总是一棵完全二叉树
将根结点最大的堆叫做大根堆(大项堆),根结点最小的堆叫做小根堆(小项堆)。
堆排序原理
我们一般用大根堆对数组进行正向排序喔
首先将当前的无序数组构成一个无序堆,对于每个元素在堆中对应的下标,由二叉树数组表示法可得
若一个节点的下标为 i,那么其左孩子节点下标为 2 * i + 1,右孩子节点下标为 2 * i + 2。
然后我们再将当前的无序堆进行不断调整,直到最后构造成 大根堆。
之后交换首尾元素,即将当前堆顶的最大元素交换到末尾,这时此元素就完成了归位。
交换完首尾元素后,此时的堆再次变成一个无序堆,需要再次堆对剩余元素进行调整,使其重新变成 大根堆。
重复上述的操作,直至堆的大小为 1,最后所有的元素都交换结束,即完成了堆排序。
堆排序动态演示
我们以 [4,7,3,1,6,2,5] 为例进行动态演示
构成无序堆
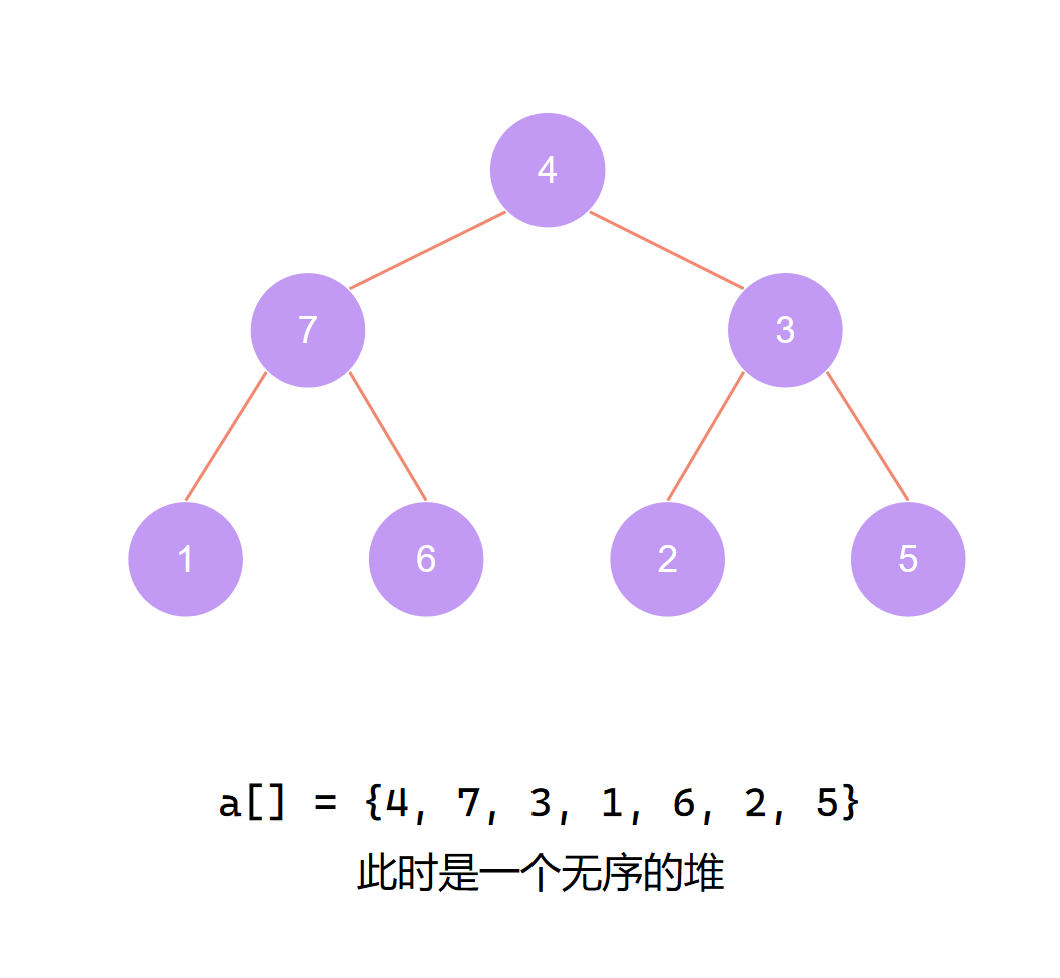
从最后一个非叶子节点开始 调整堆
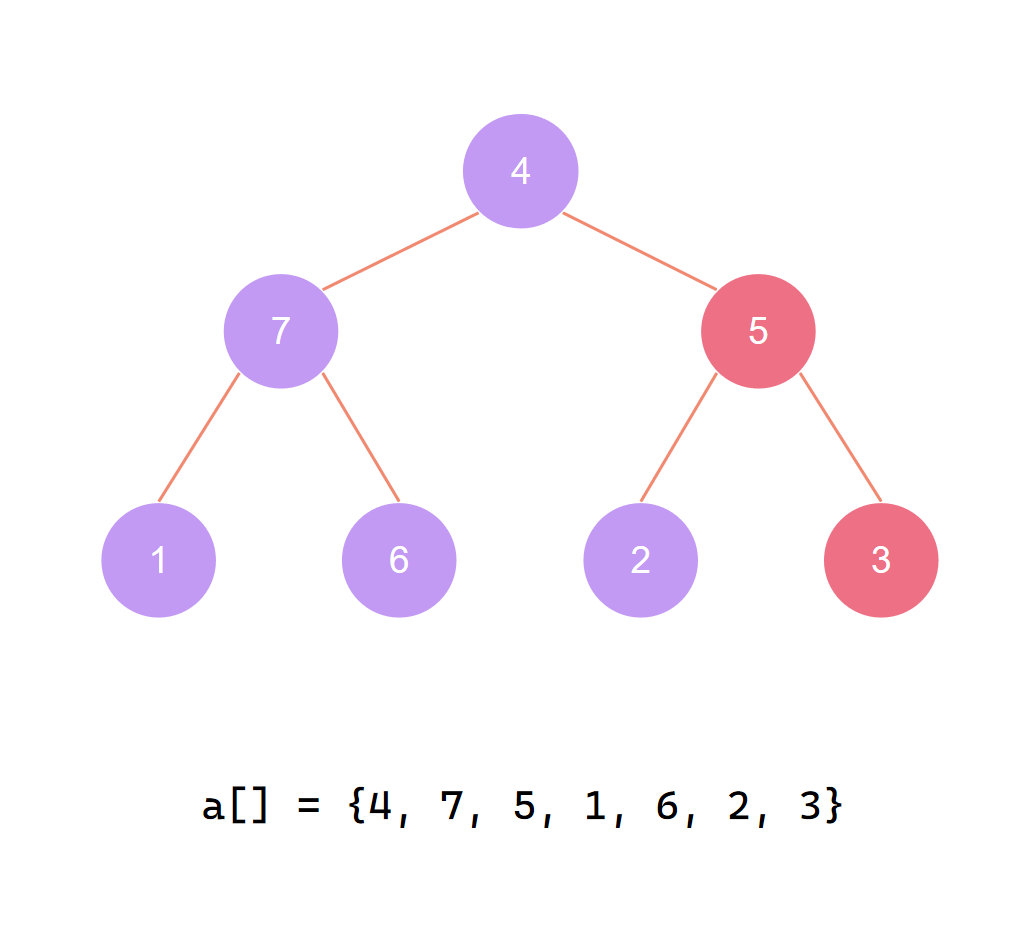
对倒数第二个非叶子节点 调整堆 此时我们发现无需调整
对最后一个非叶子节点 调整堆
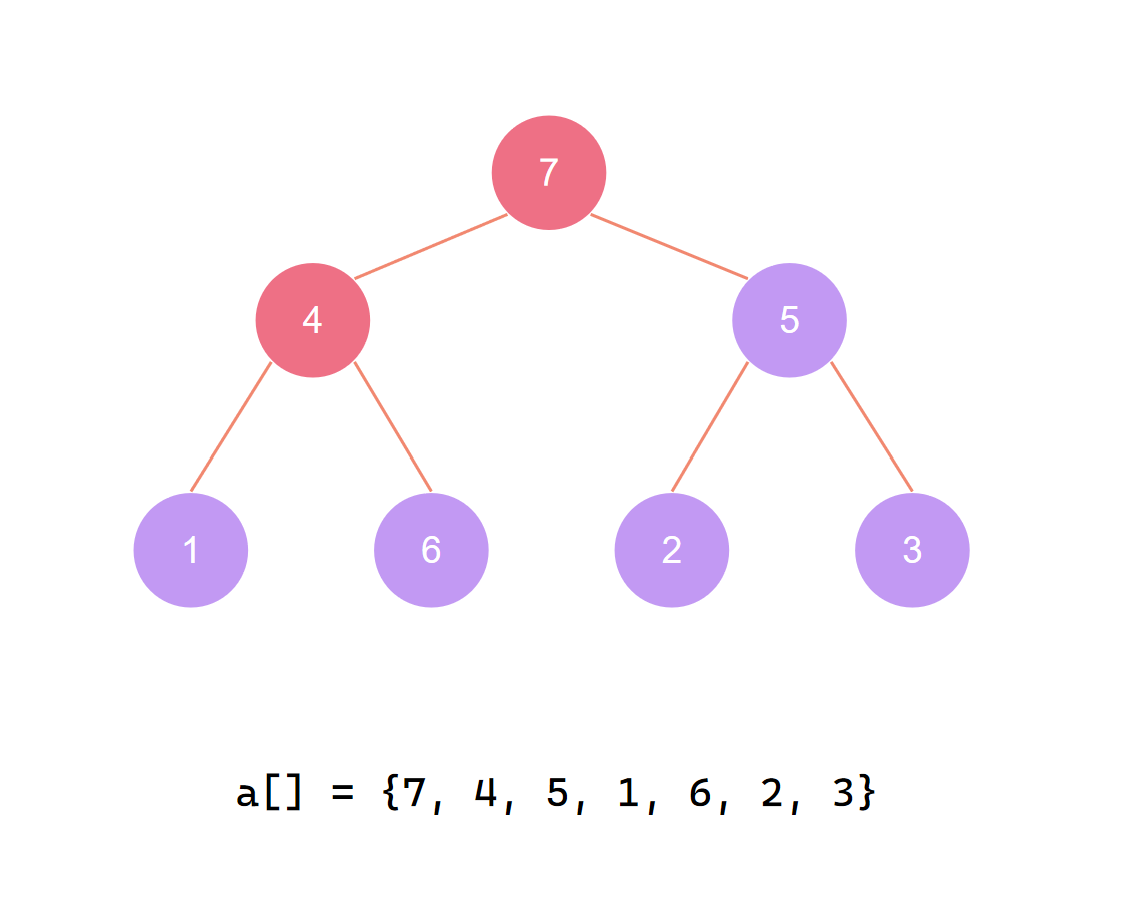
这时当前根节点的左节点由于调整不满足大根堆性质 需递归调整
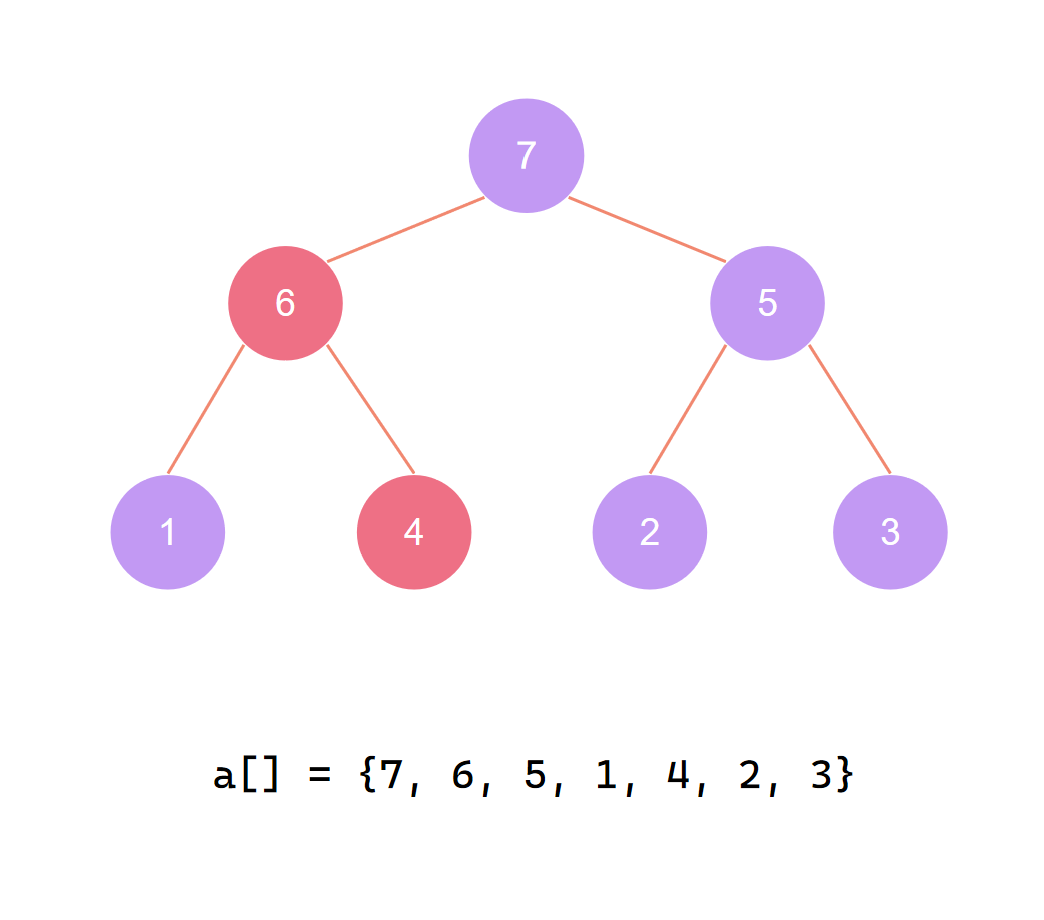
大根堆构建完成
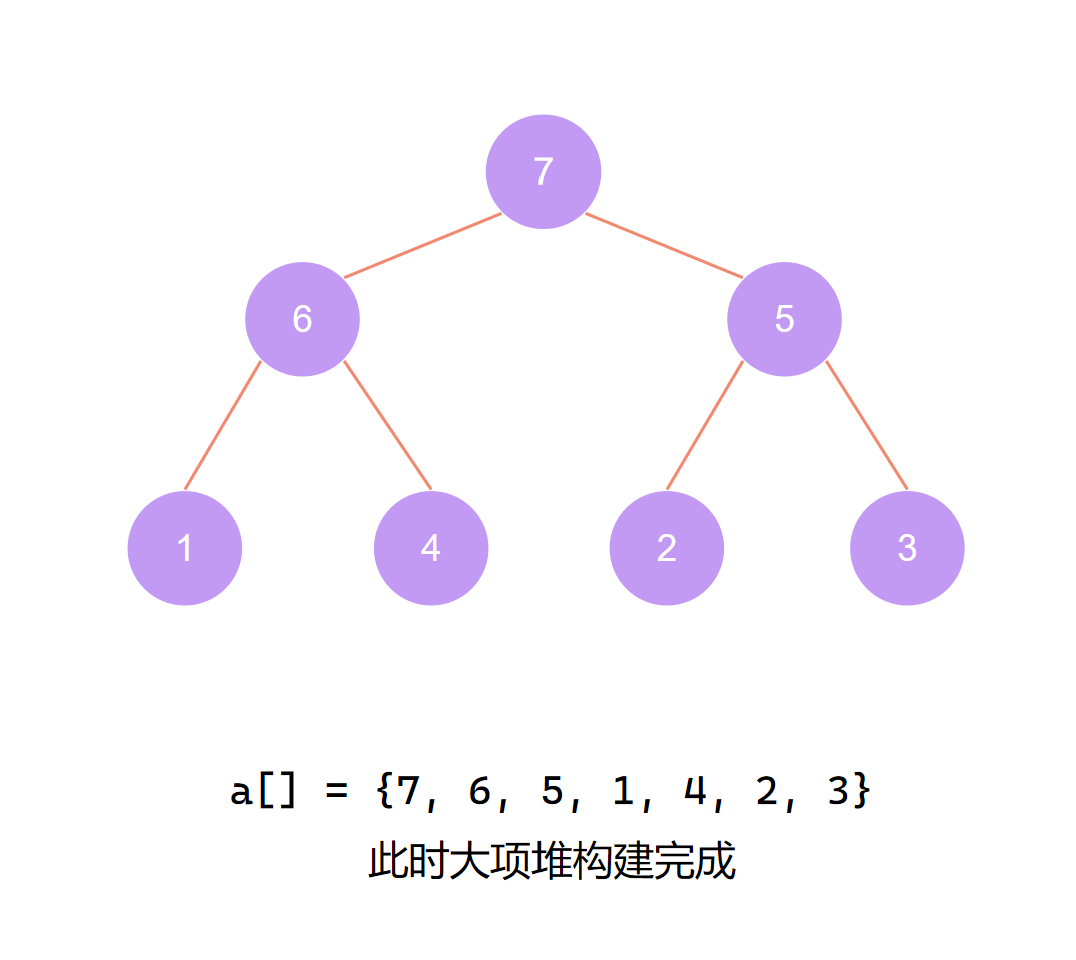
交换首尾 第一个元素归位
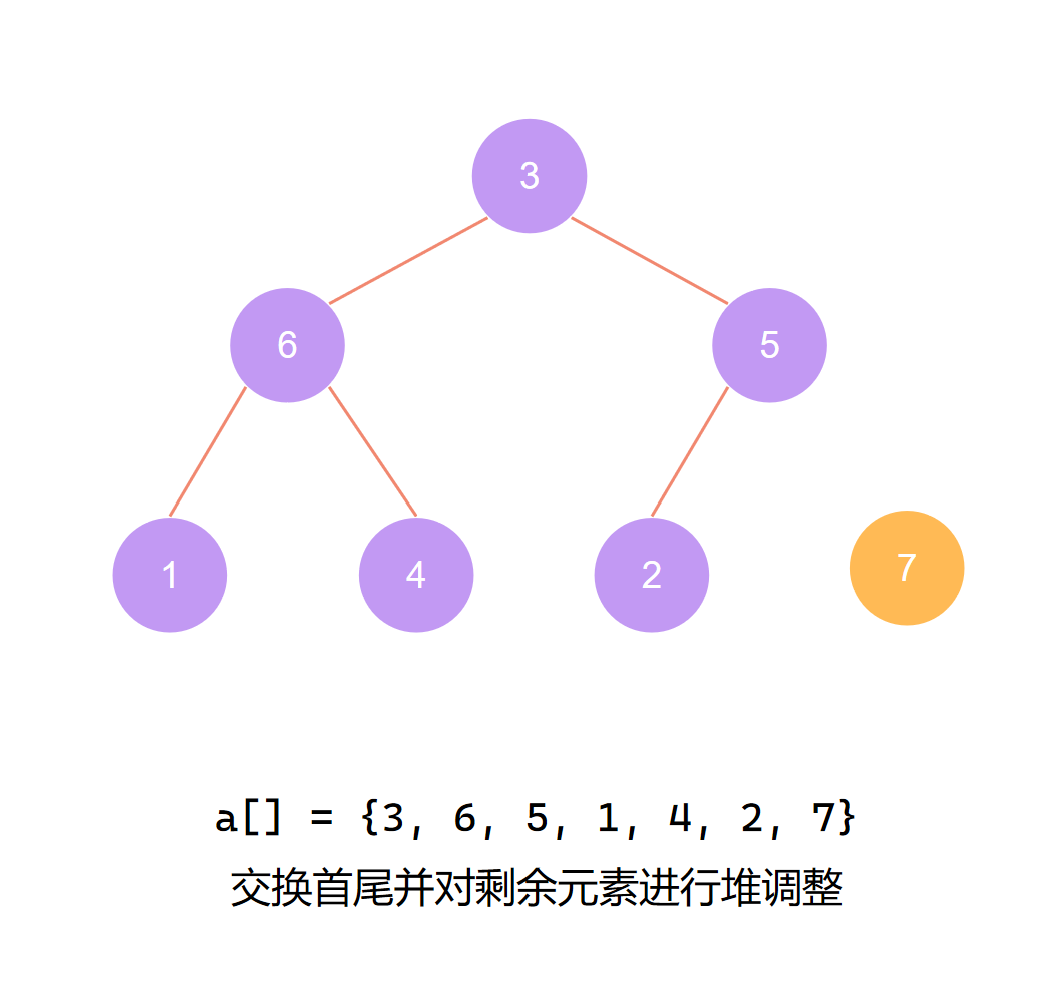
第一个元素归位后 再度调整(1)
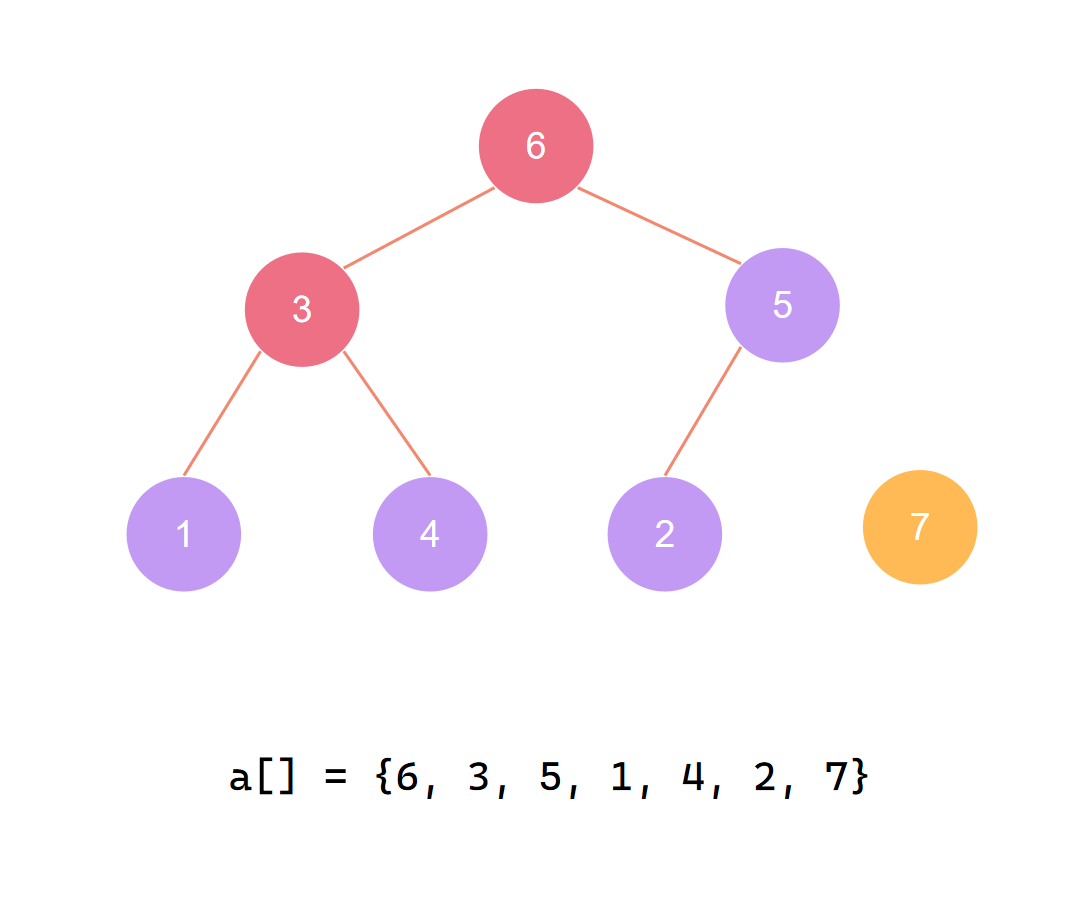
第一个元素归位后 再度调整(2)
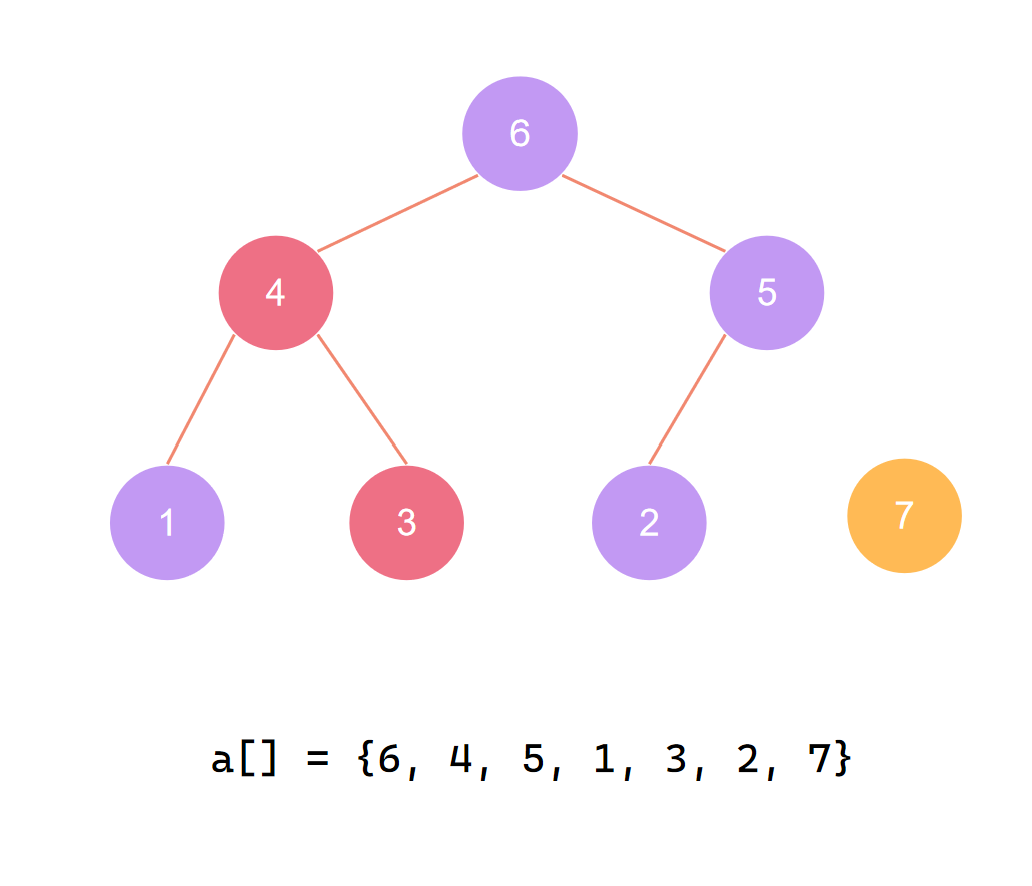
交换首尾 第二个元素归位
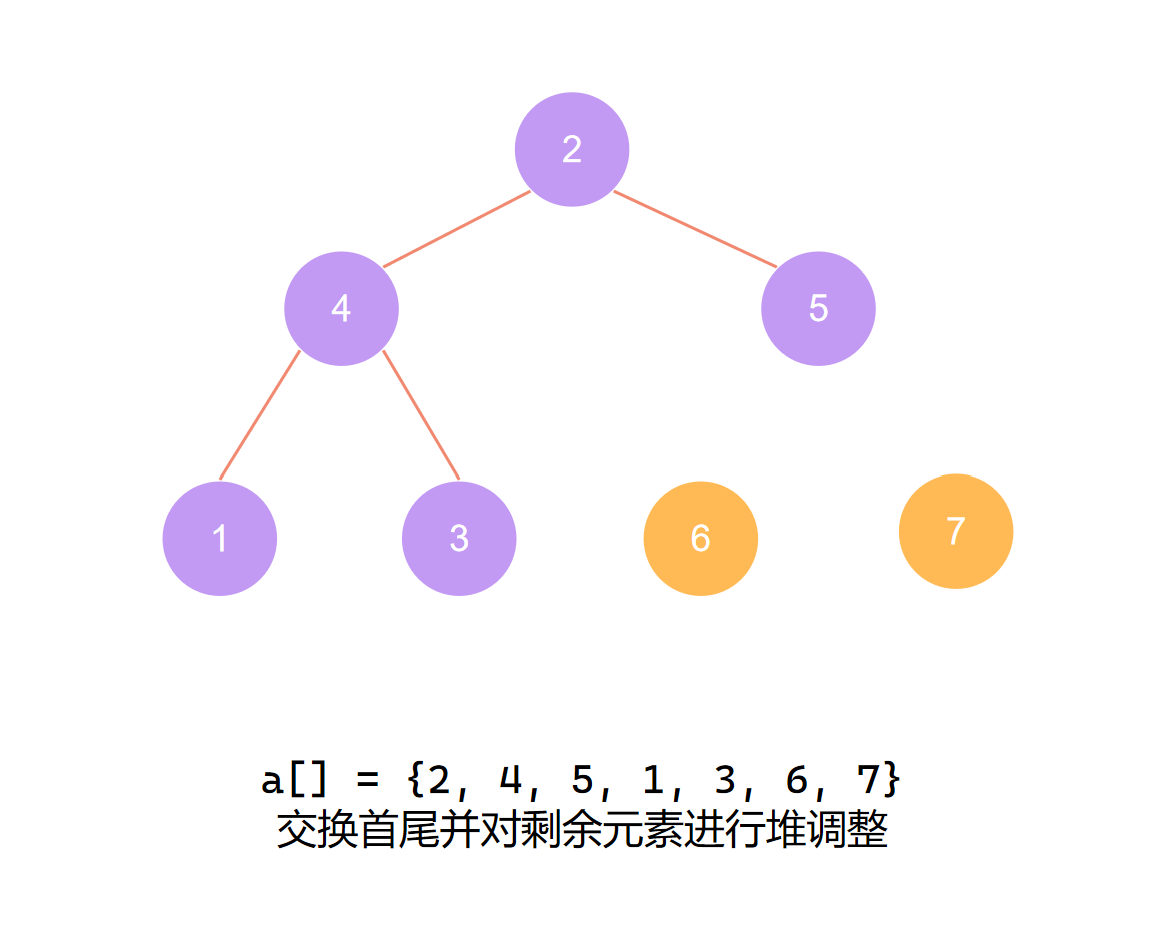
第二个元素归位后 再度调整
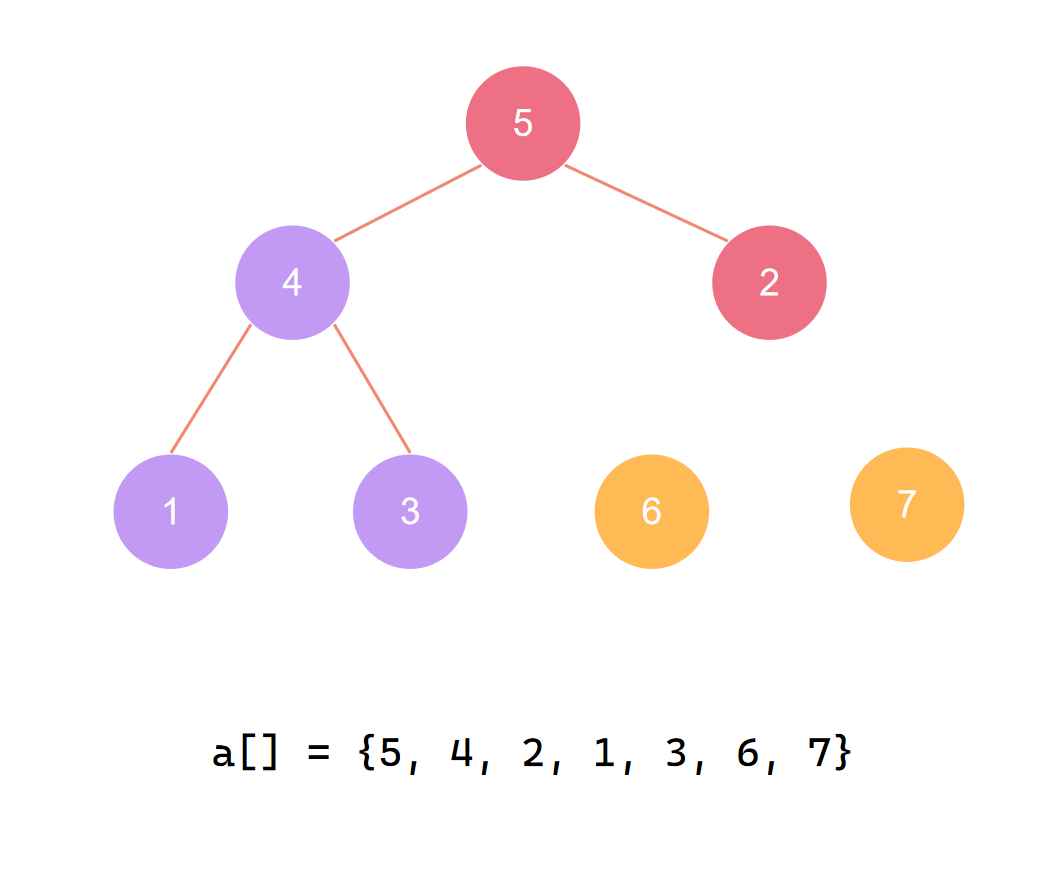
交换首尾 第三个元素归位
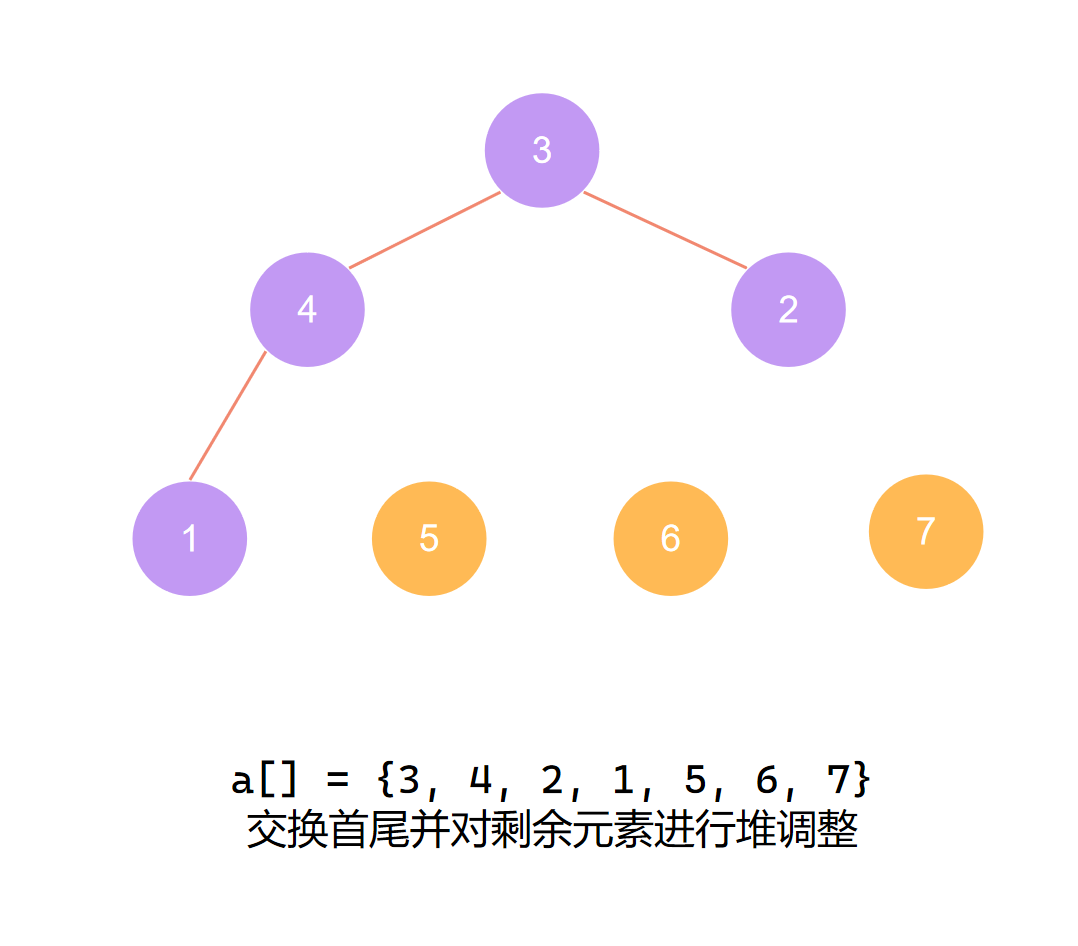
第三个元素归位后 再度调整
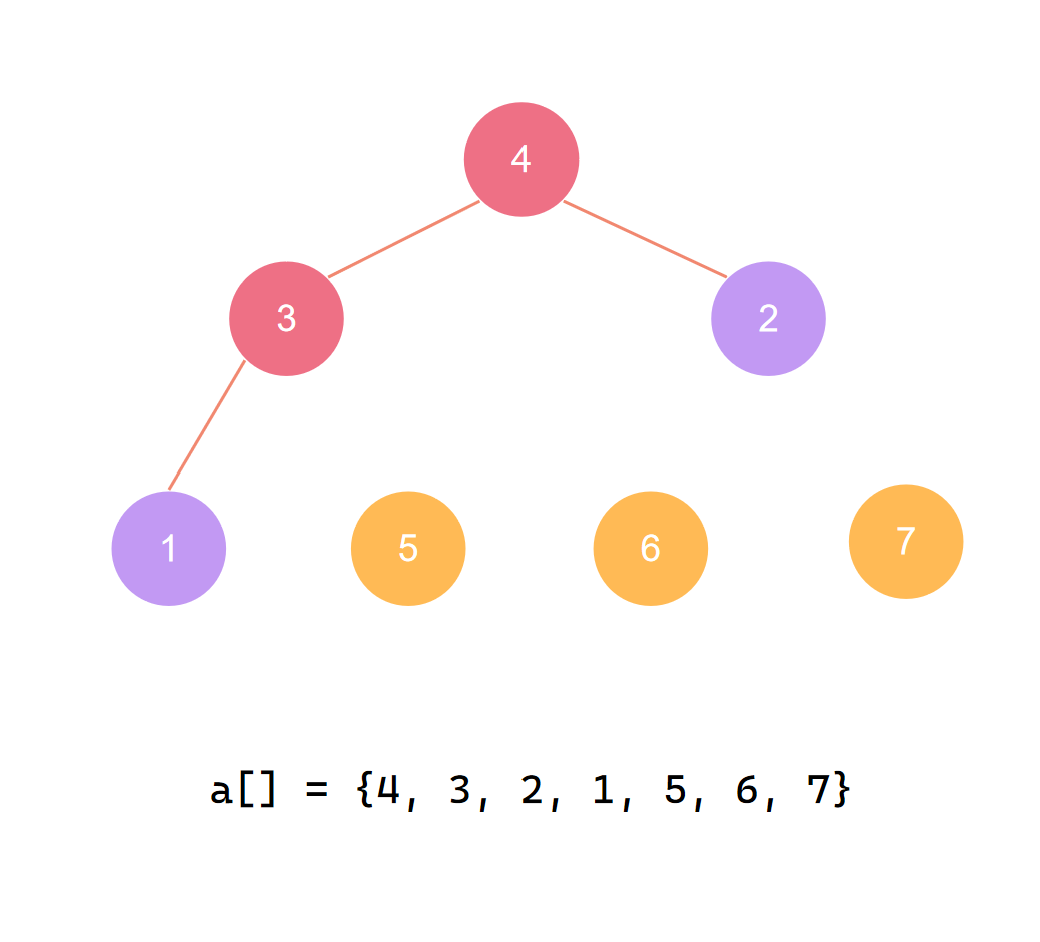
交换首尾 第四个元素归位
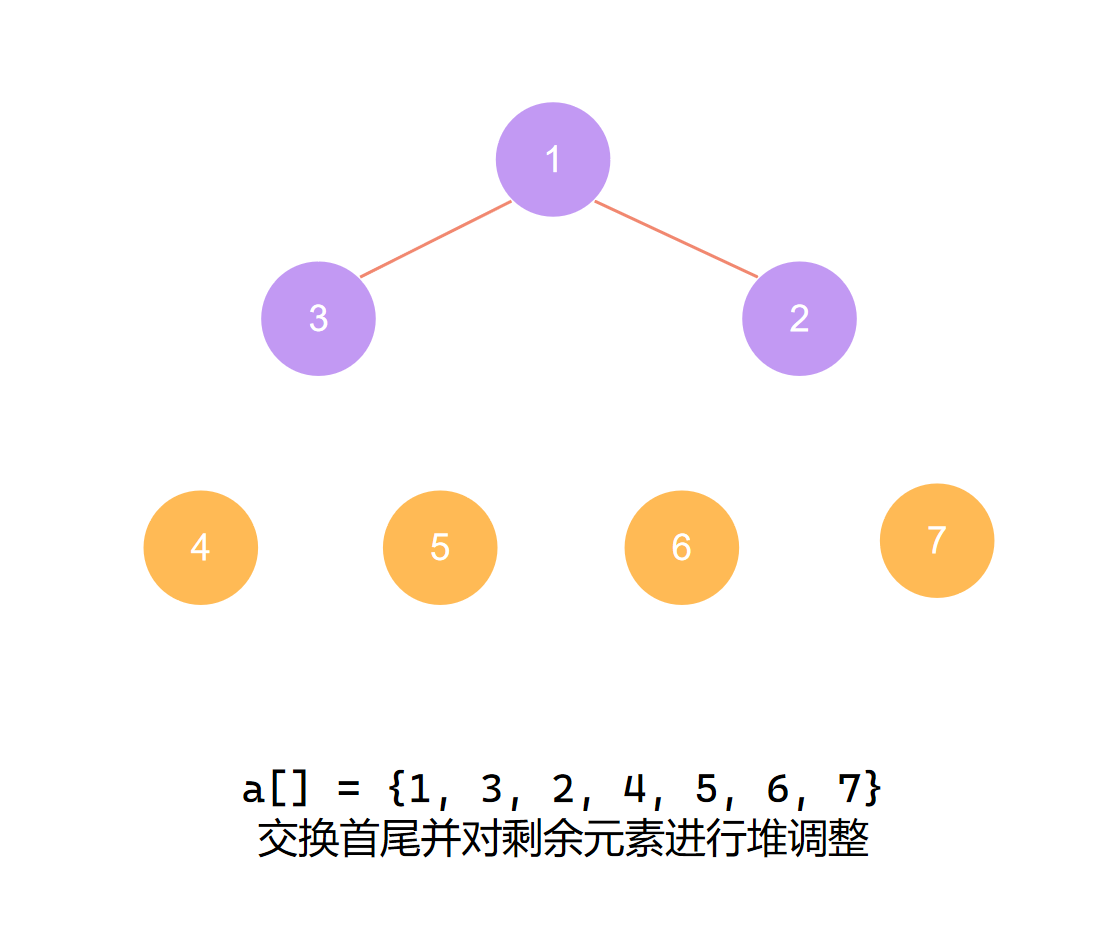
第四个元素归位后 再度调整
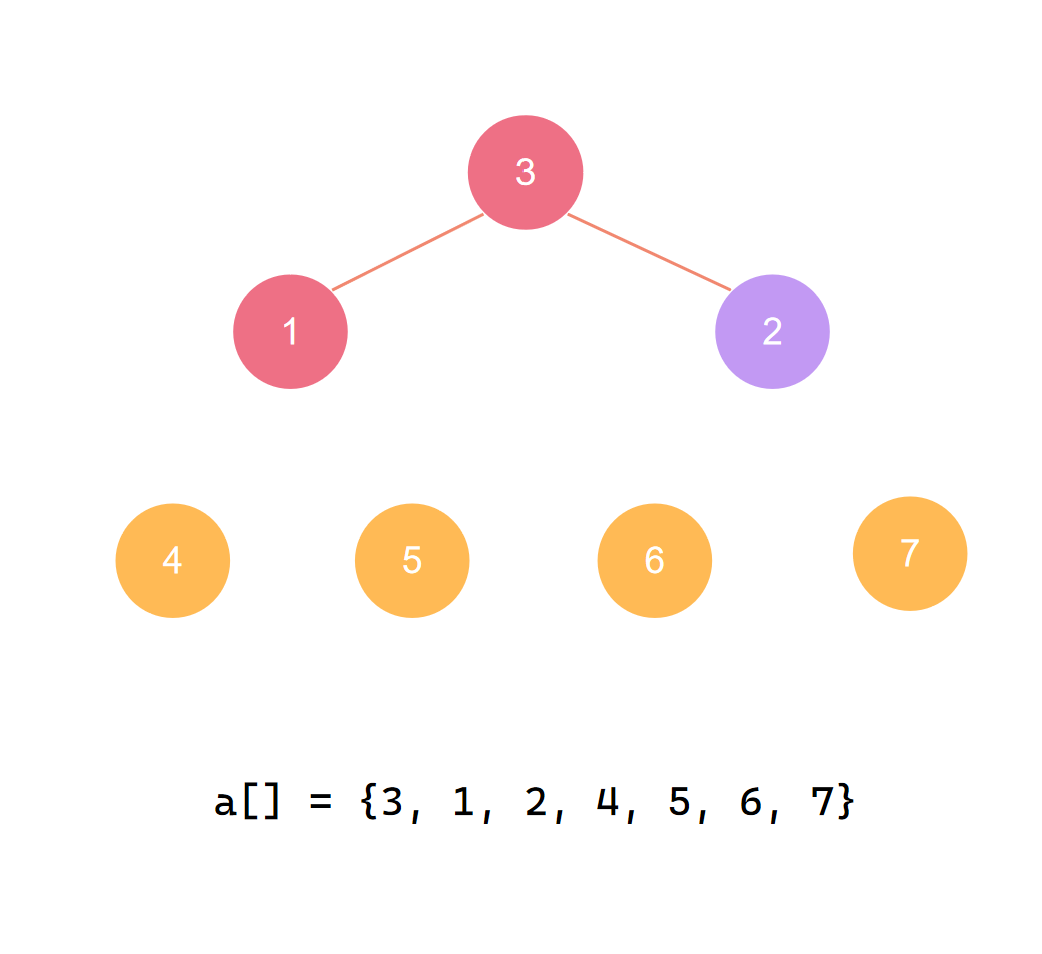
交换首尾 第五个元素归位
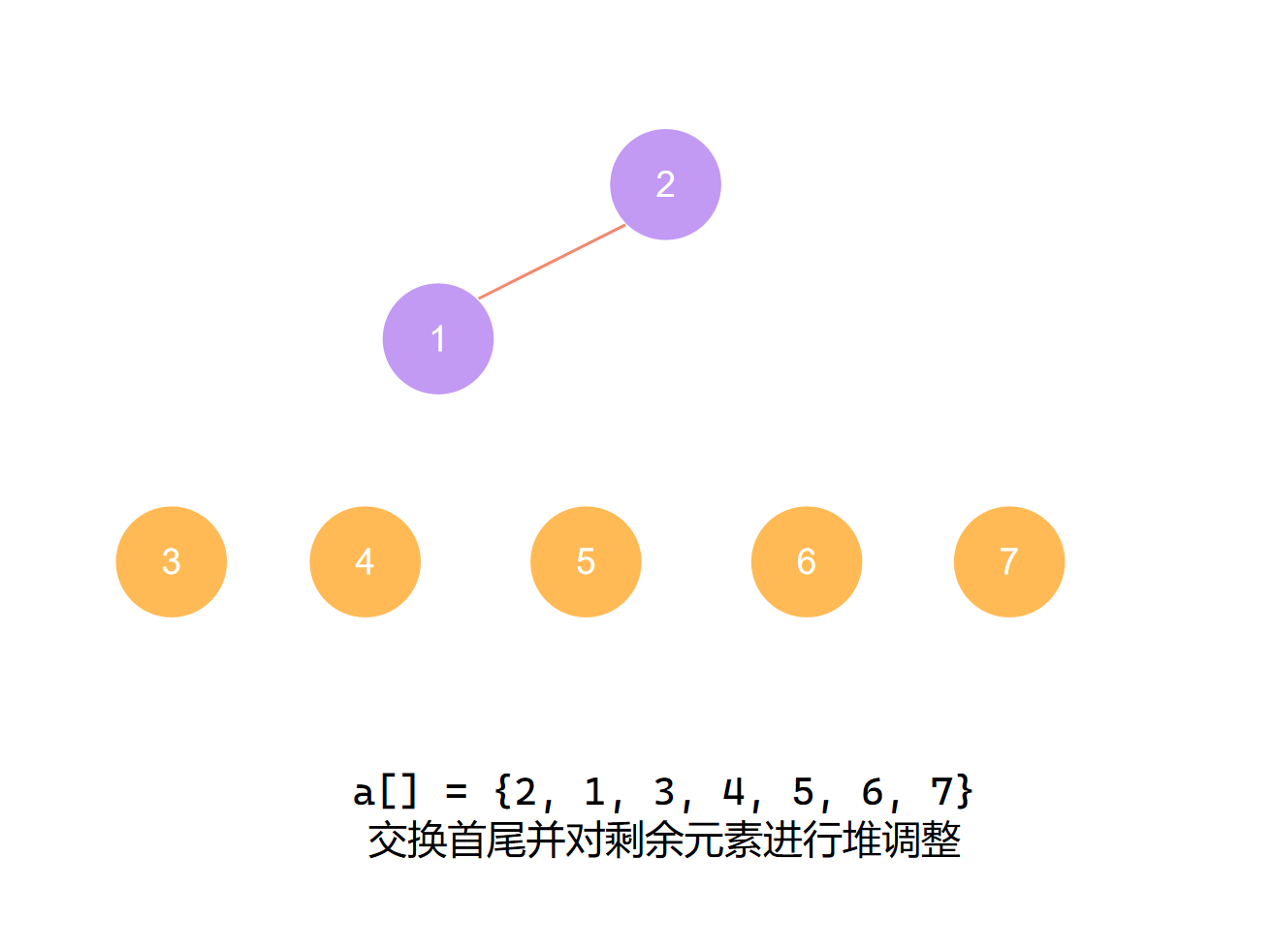
交换首尾 第六个元素归位
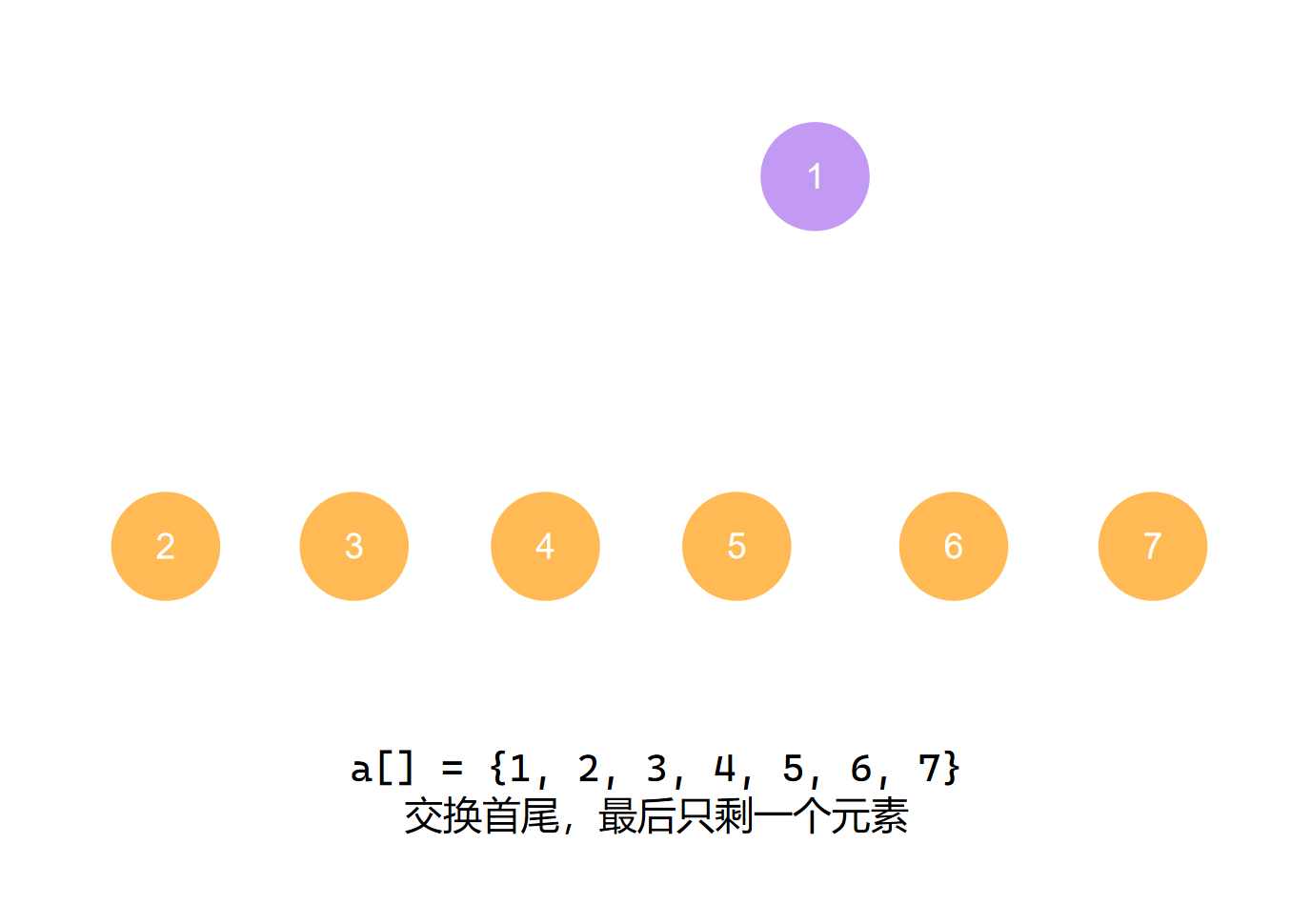
最后堆大小为1,排序完成
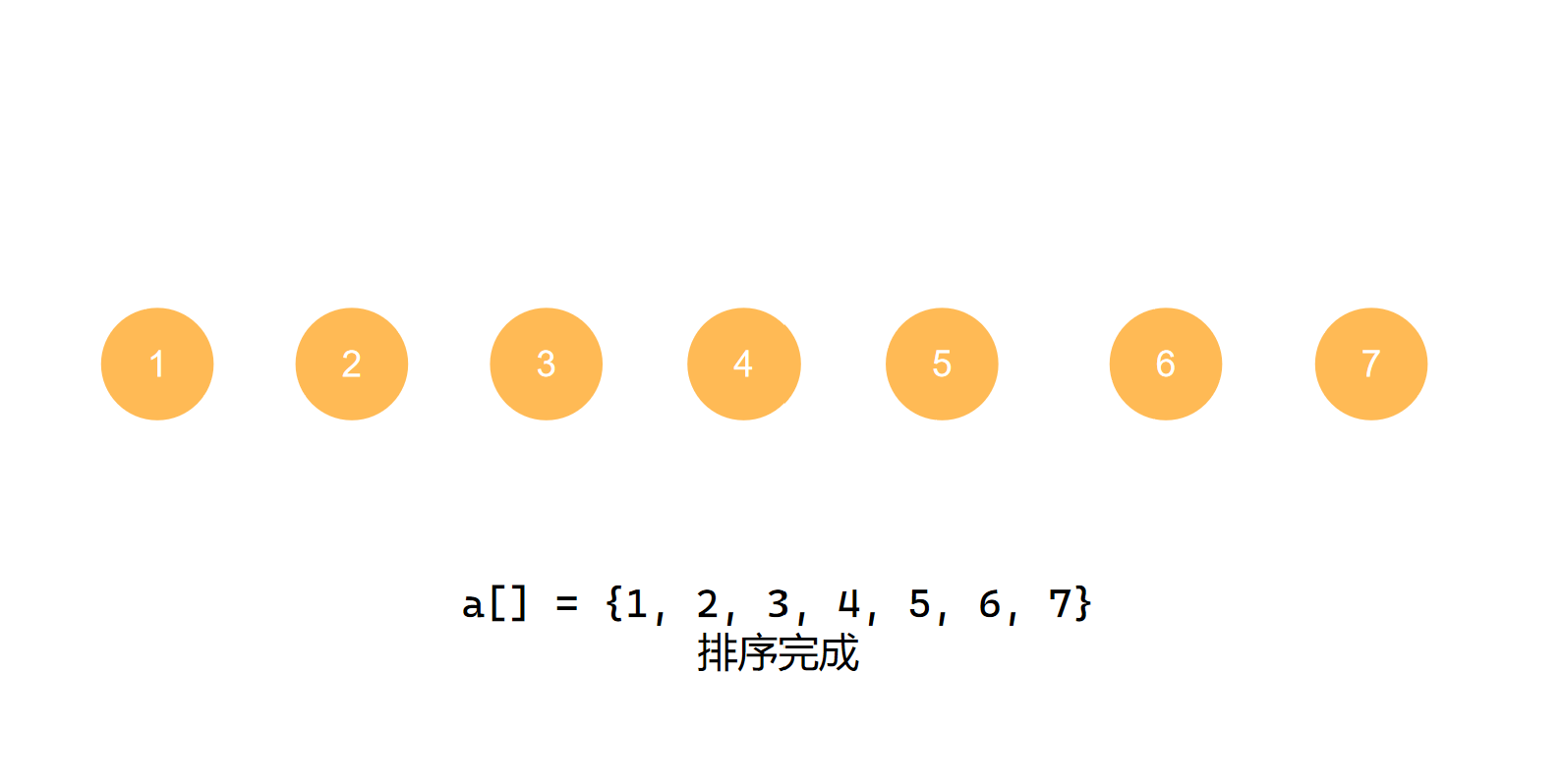
堆排序时间复杂度
构建初始的大根堆时间复杂度为O(n),
交换及重建大顶堆的过程中,需要交换n-1次,重建大顶堆的过程根据完全二叉树,log2(n-1),log2(n-2)...1 近似为nlogn。
堆排序核心代码
//调整堆
void Heapify(vector<int> &v, int i, int len){
int left = 2 * i + 1, right = 2 * i + 2; //二叉树当前节点的左右节点的索引
int maxindex = i; //先默认i为最大值索引 即当前非叶子节点
if(left < len && v[left] > v[maxindex]) //如果有左节点且左节点值更大
maxindex = left;
if(right < len && v[right] > v[maxindex]) //如果有右节点且右节点值更大
maxindex = right;
if(maxindex != i){
//发现最大值并非当前非叶子节点,则需调整 即交换最大值到非叶子节点处
swap(v[i], v[maxindex]);
//互换之后,子节点值发生变化,子节点若也有其子节点,则需继续调整其子结构
Heapify(v, maxindex, len); //递归 调整堆
}
}
//无序数组 构建大根堆
void BuildMaxHeap(vector<int> &v, int len){
//从最后一个非叶子节点开始遍历,调整每个子结构,构建形成大根堆
for(int i = len / 2 - 1; i >= 0; i--)
Heapify(v, i, len);
}
//堆排序
void HeapSort(vector<int> &v){
int len = v.size();
BuildMaxHeap(v, len); //构建大根堆
while(len > 1){
swap(v[0], v[len - 1]); //交换首尾数据 尾部最大 且出现在合适位置
Heapify(v, 0, --len); //重置大根堆
}
}
完整程序源代码
#include<iostream>
#include<vector>
#include<ctime>
using namespace std;
//调整堆
void Heapify(vector<int> &v, int i, int len){
int left = 2 * i + 1, right = 2 * i + 2; //二叉树当前节点的左右节点的索引
int maxindex = i; //先默认i为最大值索引 即当前非叶子节点
if(left < len && v[left] > v[maxindex]) //如果有左节点且左节点值更大
maxindex = left;
if(right < len && v[right] > v[maxindex]) //如果有右节点且右节点值更大
maxindex = right;
if(maxindex != i){
//发现最大值并非当前非叶子节点,则需调整 即交换最大值到非叶子节点处
swap(v[i], v[maxindex]);
//互换之后,子节点值发生变化,子节点若也有其子节点,则需继续调整其子结构
Heapify(v, maxindex, len); //递归 调整堆
}
}
//无序数组 构建大根堆
void BuildMaxHeap(vector<int> &v, int len){
//从最后一个非叶子节点开始遍历,调整每个子结构,构建形成大根堆
for(int i = len / 2 - 1; i >= 0; i--)
Heapify(v, i, len);
}
//堆排序
void HeapSort(vector<int> &v){
int len = v.size();
BuildMaxHeap(v, len); //构建大根堆
while(len > 1){
swap(v[0], v[len - 1]); //交换首尾数据 尾部最大 且出现在合适位置
Heapify(v, 0, --len); //重置大根堆
}
}
//打印数据
void show(vector<int> &v){
for(auto &x : v)
cout<<x<<" ";
cout<<endl;
}
main(){
vector<int> v;
srand((int)time(0));
int n = 50;
while(n--)
v.push_back(rand() % 100 + 1);
show(v);
HeapSort(v);
cout<<endl<<endl;
show(v);
}
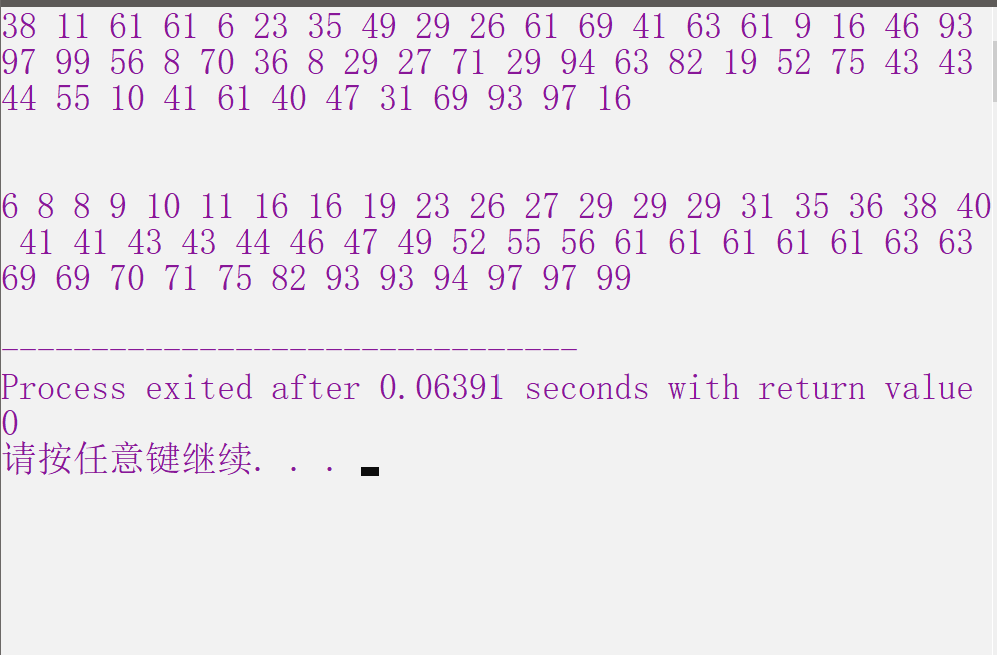
程序运行结果图
[排序算法] 堆排序 (C++)的更多相关文章
- 使用 js 实现十大排序算法: 堆排序
使用 js 实现十大排序算法: 堆排序 堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法. 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列: 小顶堆:每个 ...
- 八大排序算法——堆排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演示 二.思路分析 先来了解下堆的相关概念:堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆:或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆.如 ...
- 排序算法-堆排序(Java)
package com.rao.linkList; import java.util.Arrays; /** * @author Srao * @className HeapSort * @date ...
- JavaScript排序算法——堆排序
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Java排序算法——堆排序
堆排序 package sort; public class Heap_Sort { public static void main(String[] args) { // TODO 自动生成的方法存 ...
- 七种常见经典排序算法总结(C++实现)
排序算法是非常常见也非常基础的算法,以至于大部分情况下它们都被集成到了语言的辅助库中.排序算法虽然已经可以很方便的使用,但是理解排序算法可以帮助我们找到解题的方向. 1. 冒泡排序 (Bubble S ...
- Java常见排序算法之堆排序
在学习算法的过程中,我们难免会接触很多和排序相关的算法.总而言之,对于任何编程人员来说,基本的排序算法是必须要掌握的. 从今天开始,我们将要进行基本的排序算法的讲解.Are you ready?Let ...
- 排序算法c语言描述---堆排序
排序算法系列学习,主要描述冒泡排序,选择排序,直接插入排序,希尔排序,堆排序,归并排序,快速排序等排序进行分析. 文章规划: 一.通过自己对排序算法本身的理解,对每个方法写个小测试程序.具体思路分析不 ...
- 七内部排序算法汇总(插入排序、Shell排序、冒泡排序、请选择类别、、高速分拣合并排序、堆排序)
写在前面: 排序是计算机程序设计中的一种重要操作,它的功能是将一个数据元素的随意序列,又一次排列成一个按keyword有序的序列.因此排序掌握各种排序算法很重要. 对以下介绍的各个排序,我们假定全部排 ...
- Java排序算法之堆排序
堆的概念: 堆是一种完全二叉树,非叶子结点 i 要满足key[i]>key[i+1]&&key[i]>key[i+2](最大堆) 或者 key[i]<key[i+1] ...
随机推荐
- centos7设置时间和上海时区并进行同步
1.设置时区(同步时间前先设置) timedatectl set-timezone Asia/Shanghai 2.安装组件 yum -y install ntp systemctl enable n ...
- kubectl top命令
kubectl top命令可显⽰节点和Pod对象的资源使⽤信息,它依赖于集群中的资源指标API来收集各项指标数据.它包含有node和pod两个⼦命令,可分别⽤于显⽰Node对象和Pod对象的相关资源占 ...
- 使用Prometheus和Grafana监控RabbitMQ集群 (使用RabbitMQ自带插件)
配置RabbitMQ集群 官方文档:https://www.rabbitmq.com/prometheus.html#quick-start 官方github地址:https://github.com ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第一篇:Debezium实现Mysql到Elasticsearch高效实时同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484358&idx=1&sn=3a78347 ...
- 报错 Invalid options in vue.config.js: "baseUrl" is not allowed 问题解决
报错 Invalid options in vue.config.js: "baseUrl" is not allowed vue3.0版本中 执行 npm run build会出 ...
- 工厂数字化转型离不开 MES 的原因是什么?
工厂数字化转型是离不开 MES,首先得弄清楚什么是工厂数字化转型.什么是MES,它们的关系是怎样的. 数字化的主要含义是构建"业务数字化.数字资产化.资产服务化.服务业务化"闭环, ...
- HQL中出现XXX is not mapped的错误
我的代码如下 @Test public void testCollection(){ String hql = "from Order where orderItems is not emp ...
- CentOS 7 安全基线检查
注意:操作时建议做好记录或备份 1.设置密码失效时间 | 身份鉴别 描述: 设置密码失效时间,强制定期修改密码,减少密码被泄漏和猜测风险,使用非密码登陆方式(如密钥对)请忽略此项. 加固建议: 使用非 ...
- 【杂谈】2021-CSP退役记
Part1:复赛前一周 感觉复赛来的好快...... 我还没 颓够 准备好就来了QAQ 根据模拟赛 爆零 的光辉事迹,这次复赛我特别慌,虽然但是还是不想复习 但无所谓了,复赛一下子就只剩一天了 Par ...
- hyperf-搭建初始化
官方文档* https://hyperf.wiki/2.0/#/README 初步搭建1. 安装项目 composer create-project hyperf/hyperf-skeleton 2. ...