Step-by-step from Markov Process to Markov Decision Process
In this post, I will illustrate Markov Property, Markov Reward Process and finally Markov Decision Process, which are fundamental concepts in Reinforcement Learning.
Markov Property
'The state is independent of the past given the present'
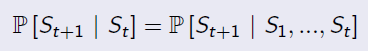
Markov Process (Markov Chain)
Keywords: state, transition matrix
A Markov Process is defined by a Tuple(S,P), in which S is the state space, and P is the transition matrix. The following chart is an example.
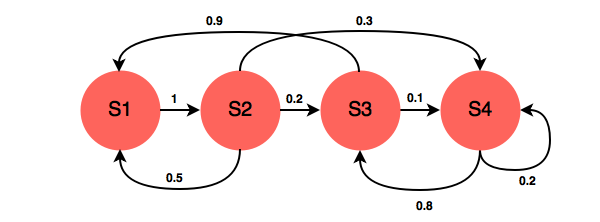
A transition matrix demonstrates the probabilities of transitioning from one state to another.


In the example above, the transition matrix is:

Markov Reward Process: Markov Process with Value Judgement
Keywords: Reward, Return, Discount Factor, Value Function
MRP add two additional properties into Markov Chain: one is Reward, who represents the immediate feedback an agent can receive at time t+1 if he is in state s at time t; another property is Discount Factor γ∈[0,1]. So the representation tuple is [S,P,R,γ].
Formally, Reward is the immediate feedback, which means when agent gets to state s at time t, it can definetly receive this reward at time t+1. It is defined by:

Given reward and discount factor, we can calculate the Return for a given senario by this equation:
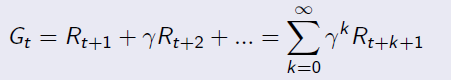
Example for Return calculation:
Senario: Class1->Class2->Class3->Pass->Sleep, and the agent is at state=Class1.
Case 1: when gamma=0, g=-2+(-2)*0+(-2)*0+10*0=-2
Case 2: when gamma=1, g=-2+(-2)*1+(-2)*1+10*1=4
Case 3: when gamma=0.8, g=-2+(-2)*0.8+(-2)*0.64+10*=-4-1.6+5.12=-0.48
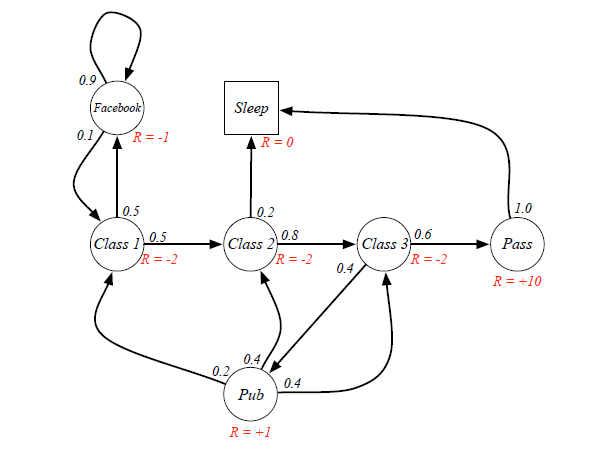
From different γ, we know our agent can be exetremely short-sighted (far-sighted) only for immediate reward, or trying to seek balance between short and long term reward.
When an agent is in a certain state, the way to measure the total reward from this state over time is calculating expected Returns for all possible senarios. The function to calculate it is called Value Function:
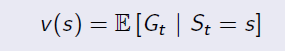
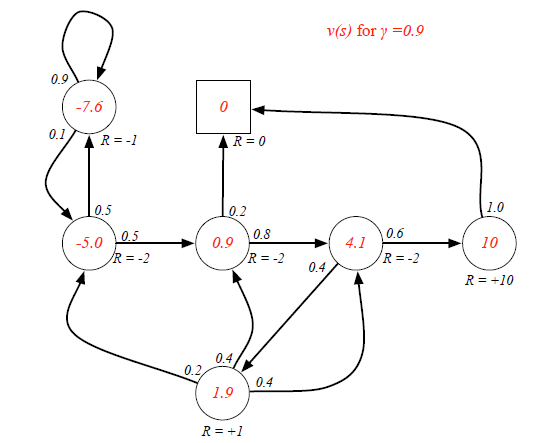
Ex. If the agent is at Class3 state, it has 0.6 and 0.4 probabilities to transite to Pass and Pub respectively. Because there are loops inside the graph, it's difficult to directly derive expected return from value function. (Forget the red labeled value, they are result...)
Bellman Equation helps to solve this complexity:
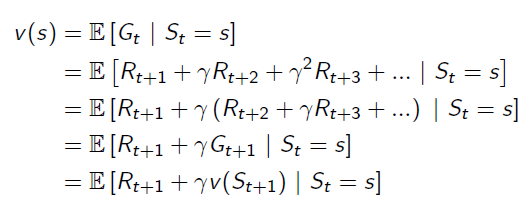
It breaks the value function into two parts: Immediate Reward and Future Reward: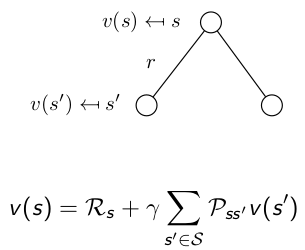 The future reward is discounted by γ, and it has probabilities on different states, so actually the future reward is an expectation.
The future reward is discounted by γ, and it has probabilities on different states, so actually the future reward is an expectation.
Now we can use Bellman Equation to solve value function: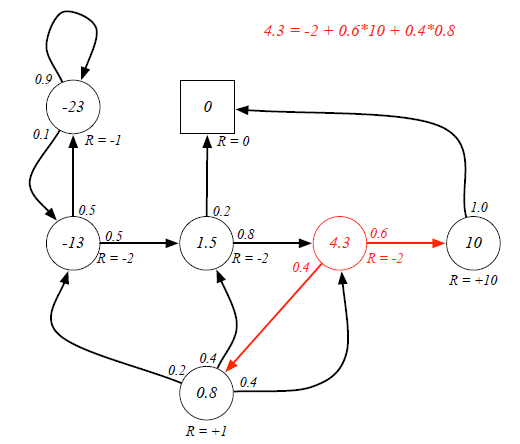
Markov Decision Process: MRP with Actions
Keywords: Action
Markov Decision Process adds more complexity onto MRP, it is defined by a tuple(S,A,P,R,γ), in which:
S is state space, and γ is discount factor, they are same as MRP.
A is a finite set of Actions, which is new. Then because of the existense of Action, Transition Matrix and Reward Function are all conditional on both State and Action.
P is State Transition Matrix: it is conditional on state and action at time t, which means different actions would result in different distribution of state at time t+1.
R is Reward Function conditional upon state and action: also, different actions lead to different reward, despite of the same state s.
A graph(from Wikipedia) helps understanding the role of actions:
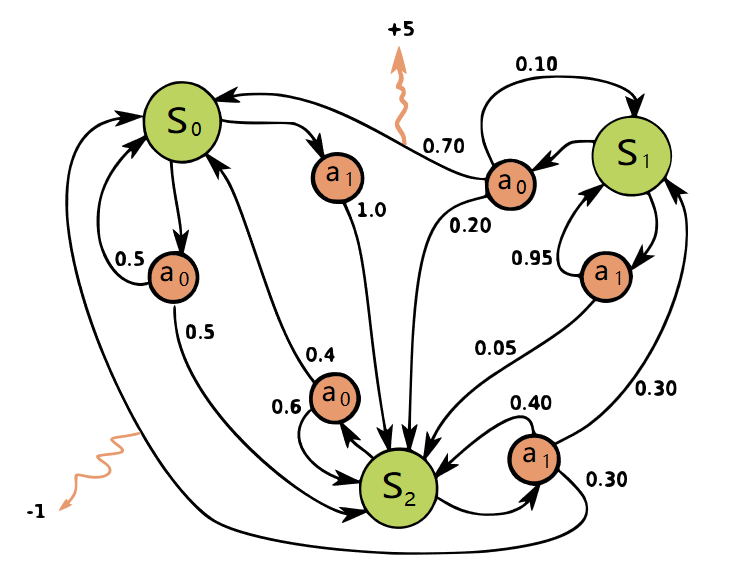
So by now, we have already had the model of the environment: all states, all possible actions and transition matrix conditional on state and actions.
Step-by-step from Markov Process to Markov Decision Process的更多相关文章
- Step by step Process of creating APD
Step by step Process of creating APD: Business Scenario: Here we are going to create an APD on top o ...
- Step by Step Process of Migrating non-CDBs and PDBs Using ASM for File Storage (Doc ID 1576755.1)
Step by Step Process of Migrating non-CDBs and PDBs Using ASM for File Storage (Doc ID 1576755.1) AP ...
- Tomcat Clustering - A Step By Step Guide --转载
Tomcat Clustering - A Step By Step Guide Apache Tomcat is a great performer on its own, but if you'r ...
- [ZZ] Understanding 3D rendering step by step with 3DMark11 - BeHardware >> Graphics cards
http://www.behardware.com/art/lire/845/ --> Understanding 3D rendering step by step with 3DMark11 ...
- e2e 自动化集成测试 架构 实例 WebStorm Node.js Mocha WebDriverIO Selenium Step by step (二) 图片验证码的识别
上一篇文章讲了“e2e 自动化集成测试 架构 京东 商品搜索 实例 WebStorm Node.js Mocha WebDriverIO Selenium Step by step 一 京东 商品搜索 ...
- Code Understanding Step by Step - We Need a Task
Code understanding is a task we are always doing, though we are not even aware that we're doing it ...
- enode框架step by step之saga的思想与实现
enode框架step by step之saga的思想与实现 enode框架系列step by step文章系列索引: 分享一个基于DDD以及事件驱动架构(EDA)的应用开发框架enode enode ...
- 课程五(Sequence Models),第一 周(Recurrent Neural Networks) —— 1.Programming assignments:Building a recurrent neural network - step by step
Building your Recurrent Neural Network - Step by Step Welcome to Course 5's first assignment! In thi ...
- 精通initramfs构建step by step
(一)hello world 一.initramfs是什么 在2.6版本的linux内核中,都包含一个压缩过的cpio格式 的打包文件.当内核启动时,会从这个打包文件中导出文件到内核的rootfs ...
随机推荐
- VS2010中解决Qt“Unable to find a Qt build“
转自:http://blog.sina.com.cn/s/blog_687960370101d0eu.html 三种方法: 1.在QT菜单下单击OPTION,然后单击ADD,选择QT安装路径. 2.运 ...
- OtterTune配置记录
0. 准备两台Ubuntu 18.04的虚拟机,安装mysql(供server-side存储调优数据用)和postgresql(供client-side存储业务数据用,这里以PostgreSQL为例. ...
- python实现不同条件下单据体的颜色不一样,比如直接成本分析表中关闭的细目显示为黄色
#引入clr运行库 import clr #添加对cloud插件开发的常用组件的引用 clr.AddReference('Kingdee.BOS') clr.AddReference('Kingdee ...
- NodeJS、npm安装步骤和配置(windows版本)
https://jingyan.baidu.com/article/48b37f8dd141b41a646488bc.html 上面这个链接很详细了,怕它没了自己记一遍.我的简洁一点. 1. 打开no ...
- Dorado环境启动出错Spring加载不到资源Bean配置 at org.springframework.asm.ClassReader.<init>(Unknown Source)
ERROR: org.springframework.web.context.ContextLoader - Context initialization failed org.springframe ...
- jquery 点击加载更多
html部分 <ul class="bill moreadd"> <div class="total"><span>-< ...
- Rsync+inotify 实时数据同步 inotify master 端的配置
强大的,细致的,异步的文件系统事件监控机制.Linux 内科从 2.6.13 起支持 inotify Inotify 实现的几款软件:Inotify,sersync,lsyncd ※Inotify 实 ...
- .net 项目中应用Web Services(vs2012)
一.在asp.net项目中添加Web services1.新建一个asp.net项目(目前尚未验证是否可以在MVC项目中添加)2.在项目名上右击,选择添加→新建项→Web服务,输好名称后确定即可 二. ...
- Linux--shell三剑客<sed>--07
1.sed(stream editor): 作为行编辑器,对文本进行编辑(以行为单位) 默认显示输出所有文件内容 注意:sed编辑文件,却不改变原文件 2.sed的工作原理: 指定一个文本文件,依次读 ...
- FTP服务器原理及配置
控制连接 21端口 用于发送ftp命令 数据连接 20端口 用于上传下载数据 数据连接的建立类型: 1主动模式: 服务器主动发起的数据连接 首先由客户端的21 端口建立ftp控制连接 当需要传输数 ...