最佳实践 | RDS & POLARDB归档到X-Pack Spark计算
X-Pack Spark服务通过外部计算资源的方式,为Redis、Cassandra、MongoDB、HBase、RDS存储服务提供复杂分析、流式处理及入库、机器学习的能力,从而更好的解决用户数据处理相关场景问题。
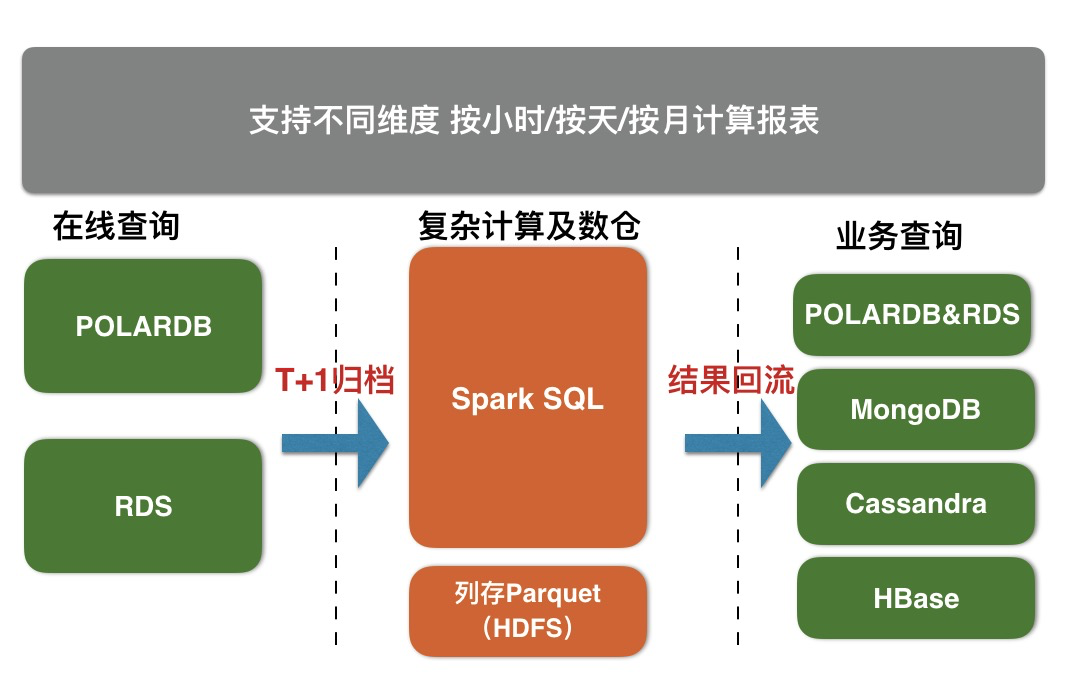
RDS & POLARDB分表归档到X-Pack Spark步骤
一键关联POLARDB到Spark集群
一键关联主要是做好spark访问RDS & POLARDB的准备工作。
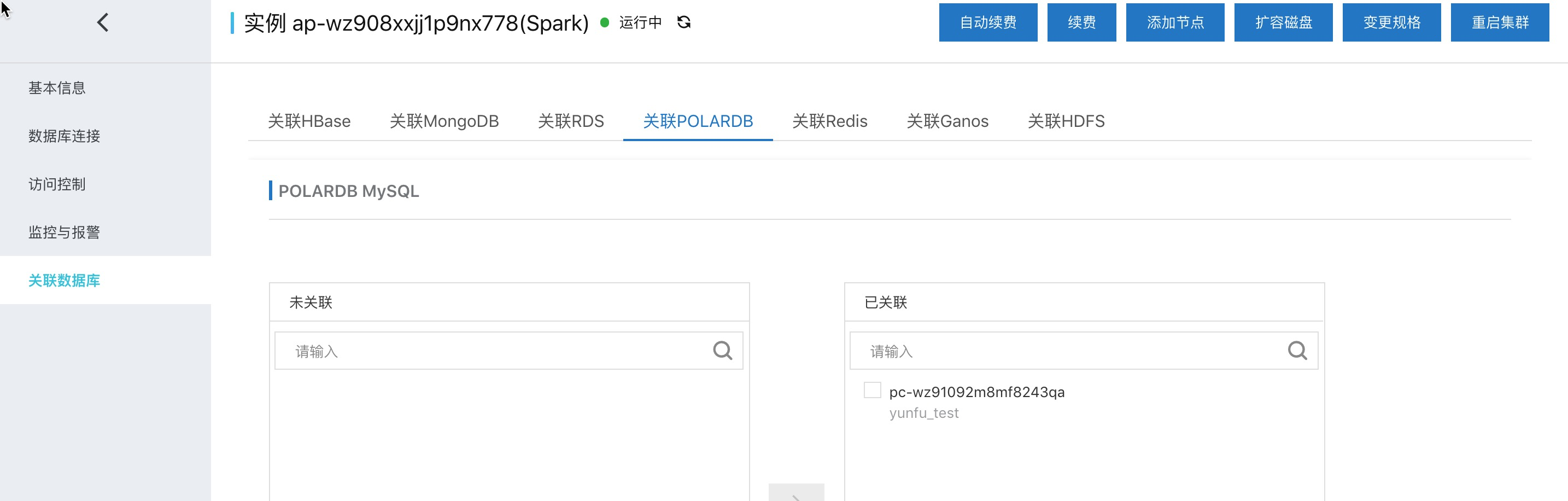
POLARDB表存储
在database ‘test1’中每5分钟生成一张表,这里假设为表 'test1'、'test2'、'test2'、...
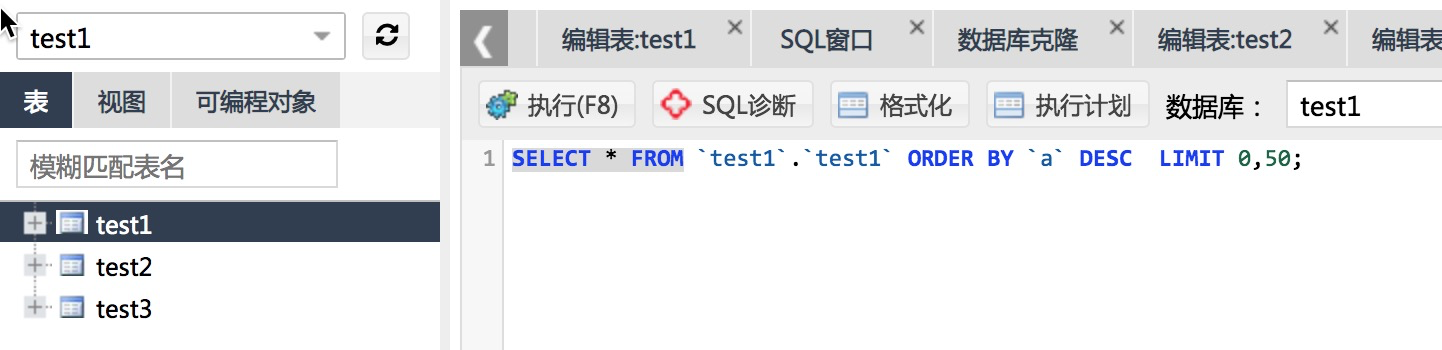
具体的建表语句如下:
CREATE TABLE `test1` ( `a` int(11) NOT NULL,
`b` time DEFAULT NULL,
`c` double DEFAULT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
归档到Spark的调试
x-pack spark提供交互式查询模式支持直接在控制台提交sql、python脚本、scala code来调试。
1、首先创建一个交互式查询的session,在其中添加mysql-connector的jar包。
wget https://spark-home.oss-cn-shanghai.aliyuncs.com/spark_connectors/mysql-connector-java-5.1.34.jar
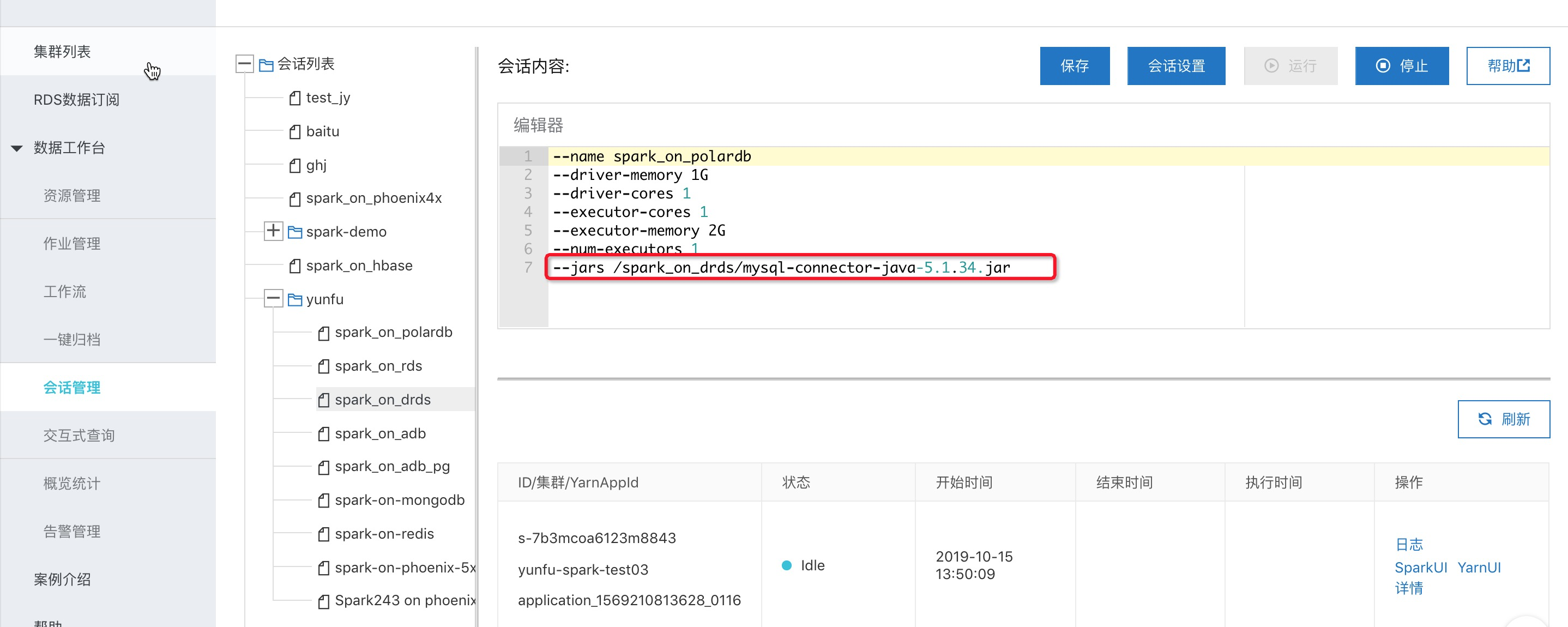
2、创建交互式查询
以pyspark为例,下面是具体归档demo的代码:
spark.sql("drop table sparktest").show()
# 创建一张spark表,三级分区,分别是天、小时、分钟,最后一级分钟用来存储具体的5分钟的一张polardb表达的数据。字段和polardb里面的类型一致
spark.sql("CREATE table sparktest(a int , b timestamp , c double ,dt string,hh string,mm string) "
"USING parquet PARTITIONED BY (dt ,hh ,mm )").show()
#本例子在polardb里面创建了databse test1,具有三张表test1 ,test2,test3,这里遍历这三张表,每个表存储spark的一个5min的分区
# CREATE TABLE `test1` (
# `a` int(11) NOT NULL,
# `b` time DEFAULT NULL,
# `c` double DEFAULT NULL,
# PRIMARY KEY (`a`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8
for num in range(1, 4):
#构造polardb的表名
dbtable = "test1." + "test" + str(num)
#spark外表关联polardb对应的表
externalPolarDBTableNow = spark.read \
.format("jdbc") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://pc-xxx.mysql.polardb.rds.aliyuncs.com:3306") \
.option("dbtable", dbtable) \
.option("user", "name") \
.option("password", "xxx*") \
.load().registerTempTable("polardbTableTemp")
#生成本次polardb表数据要写入的spark表的分区信息
(dtValue, hhValue, mmValue) = ("20191015", "13", str(05 * num))
#执行导数据sql
spark.sql("insert into sparktest partition(dt= %s ,hh= %s , mm=%s ) "
"select * from polardbTableTemp " % (dtValue, hhValue, mmValue)).show()
#删除临时的spark映射polardb表的catalog
spark.catalog.dropTempView("polardbTableTemp")
#查看下分区以及统计下数据,主要用来做测试验证,实际运行过程可以删除
spark.sql("show partitions sparktest").show(1000, False)
spark.sql("select count(*) from sparktest").show()
归档作业上生产
交互式查询定位为临时查询及调试,生产的作业还是建议使用spark作业的方式运行,使用文档参考。这里以pyspark作业为例:
/polardb/polardbArchiving.py 内容如下:
# -*- coding: UTF-8 -*-
from __future__ import print_function
import sys
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("PolardbArchiving") \
.enableHiveSupport() \
.getOrCreate()
spark.sql("drop table sparktest").show()
# 创建一张spark表,三级分区,分别是天、小时、分钟,最后一级分钟用来存储具体的5分钟的一张polardb表达的数据。字段和polardb里面的类型一致
spark.sql("CREATE table sparktest(a int , b timestamp , c double ,dt string,hh string,mm string) "
"USING parquet PARTITIONED BY (dt ,hh ,mm )").show()
#本例子在polardb里面创建了databse test1,具有三张表test1 ,test2,test3,这里遍历这三张表,每个表存储spark的一个5min的分区
# CREATE TABLE `test1` (
# `a` int(11) NOT NULL,
# `b` time DEFAULT NULL,
# `c` double DEFAULT NULL,
# PRIMARY KEY (`a`)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8
for num in range(1, 4):
#构造polardb的表名
dbtable = "test1." + "test" + str(num)
#spark外表关联polardb对应的表
externalPolarDBTableNow = spark.read \
.format("jdbc") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://pc-.mysql.polardb.rds.aliyuncs.com:3306") \
.option("dbtable", dbtable) \
.option("user", "ma,e") \
.option("password", "xxx*") \
.load().registerTempTable("polardbTableTemp")
#生成本次polardb表数据要写入的spark表的分区信息
(dtValue, hhValue, mmValue) = ("20191015", "13", str(05 * num))
#执行导数据sql
spark.sql("insert into sparktest partition(dt= %s ,hh= %s , mm=%s ) "
"select * from polardbTableTemp " % (dtValue, hhValue, mmValue)).show()
#删除临时的spark映射polardb表的catalog
spark.catalog.dropTempView("polardbTableTemp")
#查看下分区以及统计下数据,主要用来做测试验证,实际运行过程可以删除
spark.sql("show partitions sparktest").show(1000, False)
spark.sql("select count(*) from sparktest").show()
spark.stop()
本文作者:Roin123
本文为云栖社区原创内容,未经允许不得转载。
最佳实践 | RDS & POLARDB归档到X-Pack Spark计算的更多相关文章
- RDS最佳实践(一)—如何选择你的RDS
在去年双11之前,为了帮助商家准备天猫双11的大促,让用户更好的使用RDS,把RDS的性能发挥到最佳,保障双11当天面对爆发性增加的压力,不会由于RDS的瓶颈导致系统出现问题,编写了 RDS的最佳实践 ...
- 阿里云RDS for SQL Server使用的一些最佳实践
了解RDS的概念 这也是第一条,也是最重要的一条,在使用某项产品和服务之前,首先要了解该产品或服务的功能与限制,就像你买一个冰箱或洗衣机,通常也只有在阅读完说明书之后才能利用起来它们的所以功能,以及使 ...
- AWS 架构最佳实践(十二)
可靠性 基本概念 可靠性 系统从基础设施或服务故障中恢复.动态获取计算资源以满足需求减少中断的能力 系统为最坏情况做好准备,对不同组件实施缓解措施,对恢复程序进行提前测试并且自动执行. 可靠性实践 测 ...
- AWS 架构最佳实践概述(十一)
AWS 架构最佳实践 AWS合理架构的框架支柱 安全性 - 保护并监控系统 能够保护信息.系统和资产 通过风险评估和缓解策略 可靠性 - 从故障中恢复并减少中断 从基础设施或服务故障中恢复 动态获取计 ...
- MaxCompute表设计最佳实践
MaxCompute表设计最佳实践 产生大量小文件的操作 MaxCompute表的小文件会影响存储和计算性能,因此我们先介绍下什么样的操作会产生大量小文件,从 而在做表设计的时候考虑避开此类操作. 使 ...
- 探索云数据库最佳实践 阿里云开发者大会数据库专场邀你一起Code up!
盛夏.魔都.科技 三者在一起有什么惊喜? 7月24日,阿里云峰会·上海——开发者大会将在上海世博中心盛大启程,与未来世界的开发者们分享数据库.云原生.开源大数据等领域的技术干货,共同探讨前沿科技趋势, ...
- MySQL · 答疑解惑 · MySQL 锁问题最佳实践
http://mysql.taobao.org/monthly/2016/03/10/ 前言 最近一段时间处理了较多锁的问题,包括锁等待导致业务连接堆积或超时,死锁导致业务失败等,这类问题对业务可能会 ...
- 基于AWS的云服务架构最佳实践
ZZ from: http://blog.csdn.net/wireless_com/article/details/43305701 近年来,对于打造高度可扩展的应用程序,软件架构师们挖掘了若干相关 ...
- atitit.压缩算法 ZLib ,gzip ,zip 最佳实践 java .net php
atitit.压缩算法 ZLib ,gzip ,zip 最佳实践 java .net php 1. 压缩算法的归类::: 纯算法,带归档算法 1 2. zlib(适合字符串压缩) 1 3. gz ...
随机推荐
- git操作命令行
前言 git操作各种软件五花八门,懒得研究,用最原始的方法敲命令行. 操作 1.网上下载git 网上百度一下好多直接下载就好 2.配置用户名邮箱 $ git config --global user. ...
- Nmon监控服务端性能
一.安装1.查看服务器操作系统的版本信息 lsb_release -a cat /etc/*release2.下载 a.nmon下载地址:http://nmon.sourceforge.net/pmw ...
- session应用:
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8" ...
- 单词计数-MapReduceJob
pom文件 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3. ...
- vue父组件异步数据子组件接收遇到的坑
大家都知道父组件给子组件传值,子组件给父组件传值,两者通信并不难,官网上也有给案例,但是如果子组件想拿到父组件的异步数据,常规的写法是不行的,下面我记录我常用的两者写法: 方法1: 子组件用v-if, ...
- paper 154:姿态估计(Hand Pose Estimation)相关总结
Awesome Works !!!! Table of Contents Conference Papers 2017 ICCV 2017 CVPR 2017 Others 2016 ECCV 20 ...
- Delphi 判断特定字符是为单字节还是双字节
判断特定字符是为单字节还是双字节 // mbSingleByte 单字节字符 //mbLeadByte 双字节字符首字节 //mbTrailByte 双字节字符尾字节 Edit1.Text:='010 ...
- day 109结算中心.
from django.db import models from django.contrib.contenttypes.fields import GenericForeignKey,Generi ...
- trizip haskell implementation
1 trizip :: [a] -> [b] -> [c] -> [(a,b,c)] 2 trizip a b c 3 | null a = [] 4 | null b = [] 5 ...
- byte与base64string的相互转化以及加密算法
//在C#中 //图片到byte[]再到base64string的转换: Bitmap bmp = new Bitmap(filepath); MemoryStream ms = new Memory ...