Python自动化运维技术与最佳实现
第一章 系统基础信息模块详解
系统基础信息采集模块最为监控模块的重要组成部分,能够帮助运维人员了解当前系统的健康程度,同时也是衡量业务的服务质量的依据,比如系统资源吃紧,会直接影响业务的质量以及用户的体验,另外获取设备的流量信息,也可以让运维人员更好地评估带宽、设备资源是否应该扩容。
本章通过具体的实例来帮助读者学习、理解并掌握。在本章接下来的内容中,可以通过运用Python第三方系统基础模块,获取服务关键运营指标数据,其中包括Linux基本性能、块设备、网卡接口、系统信息、网络地址库等信息。当采集到在这些信息后,可以全方位的了解系统服务的状态,结合告警机制,可以在第一时间响应,将异常刚刚出现时得以及时的处理。
以下实例都是在一个连续的Python=交互环境中进行。
1.1 系统性能信息模块psutil
psutil是一个跨平台库,可以轻松地实现获取系统运行的进程和系统利用率其中包括CPU、内存、硬盘、网络信息等。主要用于系统监控,分析和限制系统资源以及进程的管理。
支持的命令包括:ps、top、lsof、netstat、ifconfig、who、df、kill、free、nice、ionice、iostat、iotop、uptime、pidof、tty、taskst、pmap等。
通常获取系统信息采用编写shell来实现,如获取当前物理机的内存总大小以及使用大小,shell命令
total: free -m | grep Mem | awk ‘{print $2}’
used: free -m | grep Mem | awk ‘{print $3}’
使用psutil库实现就更加简单明了。psutil大小单位采用的是字节,实例如下图:

源码安装:

1.1.1 获取系统性能信息
psutil已经封装了获取系统性能信息的方法,可以根据用户的应用场景,来调用相应的方法妈祖用户需求。
(1)CPU信息
linux中的cpu利用率包括以下几部分:
User Time 执行用户进程的时间百分比
System Time 执行内核进程和中断的时间百分比
Wait IO 由于IO等待而使CPU处于idle(空闲)状态的时间百分比
Idle Cpu处于空心状态的时间百分比
使用psutil.cpu_times()方法可以非常简单的得到信息,同时获取CPU的硬件信息,比如CPU的物理个数与逻辑个数,如下图:

使用psutil.cpu_times()获取cpu完整信息,需要显示所有逻辑CPU信息,指定方法变量percpu=True,例如psutil.cpu_times(percpu=True)。
获取单项数据信息,用户user的CPU时间比
(2)内存信息
Linux操作系统中的内存利用率包括total(内存总数),used(已使用的内存数),free(空闲内存数),buffers(缓冲使用数),cache(缓存使用数),swap(交换分区使用数)等等。分别使用 psutil.virtual_memory()和psutil.swap_memory()方法获取这些信息。详细操作如下图:



(3) 磁盘信息
在系统地所有磁盘信息中,主要关注地是磁盘的利用率以及IO信息,其中磁盘利用率使用psutil.disk_usage获取。磁盘IO信息包括:read_count(读IO数)、write_count(写IO数)、read_bytes(IO读字节数)、write_bytes(IO写字节数)、read_time(磁盘读时间)、write_time(磁盘写时间)等。这些IO信息可以使用psutil.disk_io_counters()获取,如下图实例:


(4) 网络信息
系统的网络信息与磁盘IO类似,包括:bytes_sent(发送字节数)、bytes_resv(接收字节数)、packets_sent(发送数据包数)、packets_recv(接收数据包数)等。使用psutil_net_io_counters()方法获取,操作如下:

(5)其他系统信息
psutil模块支持获取用户登录、开机时间等信息,如下图:

1.1.2 系统进程管理方法
获得当前的系统信息地进程信息,可以让运维人员得知应用程序的运行状态,包括进程的启动时间、查看或者设置CPU亲和度、内存使用率、IO信息、socket连接、线程数等,这些信息可以呈现出指定进程是否存活、资源利用情况,为开发人员的代码优化、问题定位提供很好的数据参考。
(1)进程信息
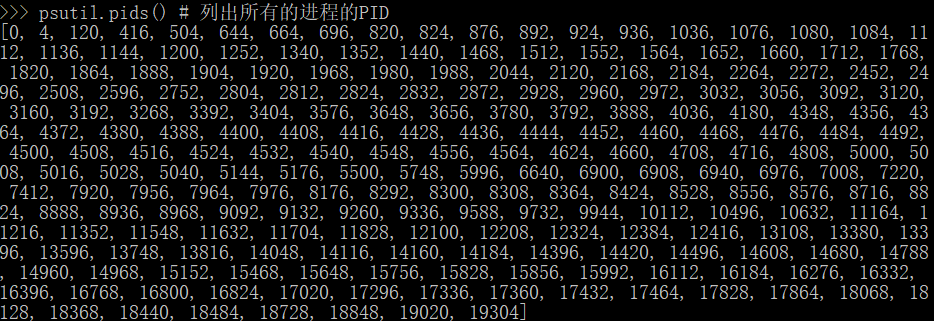
psutil.pids()获取所有进程的PID,使用psutil.Process()方法获取的那个进程的名称、路径、状态、系统资源利用率等信息,如下图:

当输入p.exe()出现错误



(2)popen类的使用
psutil提供的popen类的作用是获取用户启动的应用程序进程信息,以便跟踪程序进程的运行状态。如下图:

1.2 实用的IP地址处理模块IPy
IP地址规划是网络设计中非常重要的环节,规划的好坏会直接影响路由协议算法的效率,其中摆阔网络性能、可扩展性等,在这过程中,是避免不了要计算大量的IP地址,例如网段、网络掩码、广播地址、子网数、IP类型等。Python提供了强大的第三方模块IPy,可以很好的辅助我们高效完成IP的规划工作。
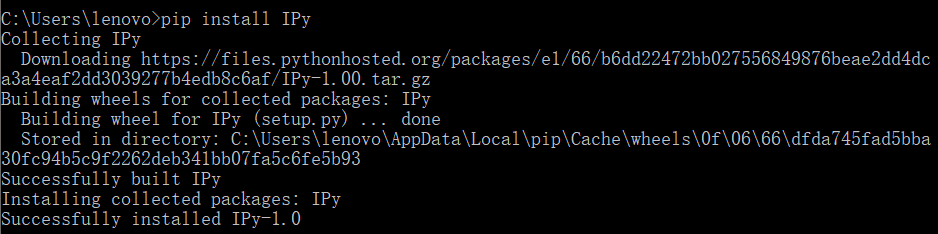
(1)IPy模块安装
(2)IP地址、网段的基本处理
IPy模块包含IP类,使用他可以方便处理绝大部分格式为IPv6以及IPv4的网络和地址。
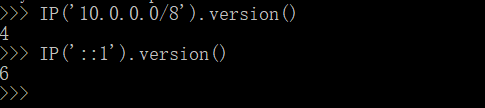
可以通过cersion()来区分,首先要导入IPy库,from IPy import IP ,之后进行操作,如下图:
通过指定的网段输出该网段的IP个数以及所有IP地址清单,代码如下:

下面介绍IP类几个常见的方法,包括反向解析名称,IP类型,IP转换等。iptype()代表ip类型,strHex()转换成十六进制,strBin()转换成二进制格式,IP(0x8080808)十六进制转换成IP格式。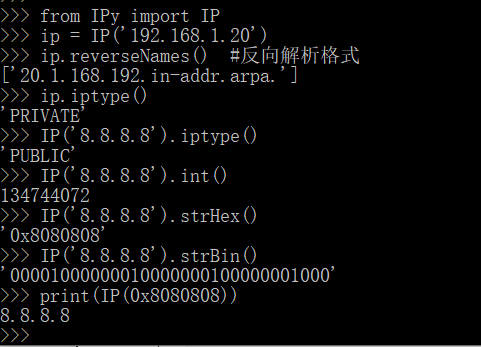
IP方法支持网络地址的转换,例如根据IP与掩码生产网段格式,如下:

也可以通过strNormal方法指定不同wantprefixlen参数值以定制不同输出类型的网段,输出另外i行字符串,如下:

wantprefixlen = 0,无返回,如192.168.1.0
wantprefixlen = 1,prefix格式,192.168.1.0/24
wantprefixlen = 2,decima net mask格式,192.168.1.0/255.255.255.0
wantprefixlen = 3,lastIP格式,192.168.1.0-192.168.1.255
(3) 多网络计算方法详解
比较两个网段是否存在包含、重叠等关系,同网络但不同prefixlen会认为是不同的网段,例如192.168.0.0/16不等于192.168.0.0/24,另外即使具有相同的prefixlen但会处于不同的网络地址,同样视为不相等,例如10.0.0.0/16不等于192.0.0.0/16.IPy支持类似于数值型数据的比较,以帮助IP对象进行比较,如:

判断IP地址和网段是否包含于另一个网段中:

判断两个网段是否存在重叠,采用IPy提供的overlaps方法,如下图:(返回1有重叠,0没有重叠)

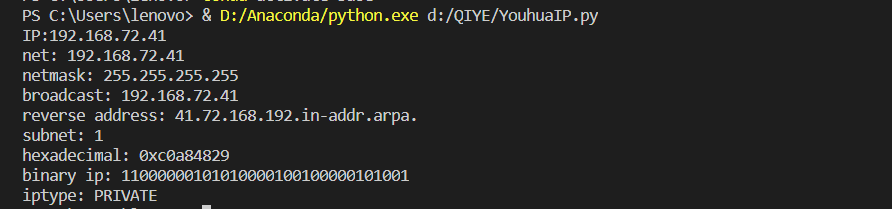
实例 根据输入的IP地址或者子网返回网络、掩码、广播、反向解析、子网数、IP类型等信息。
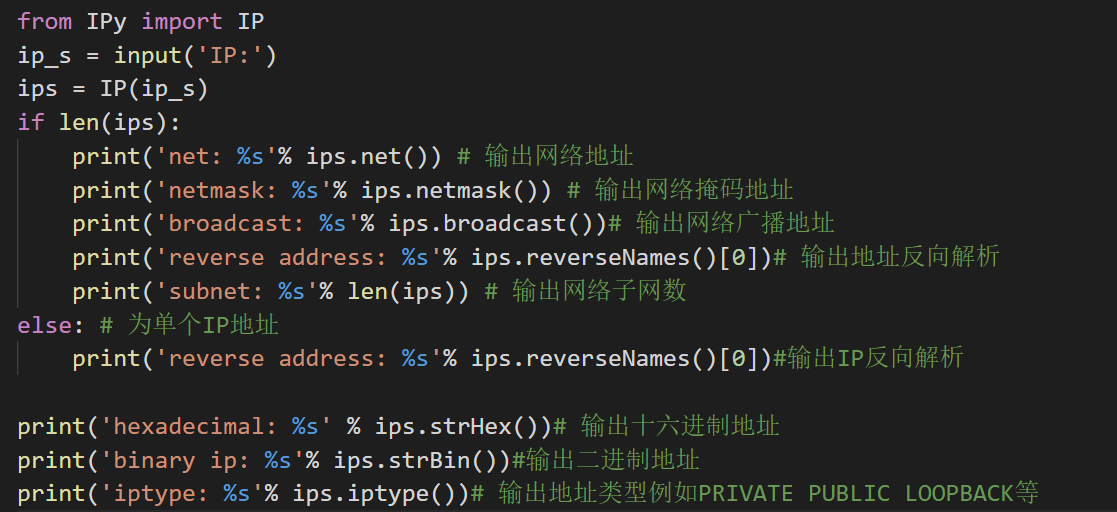
运行结果:
1.3 DNS处理模块dnspython
dnspython是Python实现的一个DNS工具包,他支持几乎所有的记录类型,可以用于查询、传输并动态更i新ZONE信息,同时支持TSIG(事务签名)验证消息和EDNS0(扩展DNS)。在系统管理方面,我们可以利用其查询功能来实现DNS服务监控以及解析结果的校验,可以代替nslookup及dig等工具,轻松做到与现有平台的整合,下面进行详细介绍。
安装:

(1)模块域名解析方案详解
dnspython模块提供了大量的DNS处理方法,最常用的方法是域名查询。dnspython提供了DNS的解析器类----resolver,使用他的query方法来实现域名的查询功能。query方法如下:

其中,qname参数为查询的域名。rdtype参数来制定RR资源的类型,常用的有以下几种:
A记录:将主机名转换成IP地址
MX记录:邮件交换记录,定义邮件服务器的域名
CNAME:指的是别名记录,实现域名间的映射
NS记录:标记区域的域名服务器以及授权子域
PTR记录:反向解析,与A记录相反,将IP转换成主机名
SOA记录:SOA标记,一个其实授权区的定义
rdclass参数由于指定网络类型(IN,CH,HS)其中IN是默认,使用广泛。tcp参数由于指定查询是否启用TCP协议,默认False(不启用)。source与source_port参数指定查询源地址与端口,默认值为查询设备IP地址和0。raise_on_answer参数用于指定当查询无应答是是否触发异常,默认为True。
(2)常见解析类型示例说明
常见的DNS解析类型包括A,MX,NS,CNAME等。利用dnspython的dns.resolver.query方法可以简单的实现简单的DNS类型的查询,为后面要实现的功能提供数据来源,比如对各使用DNS轮循业务的域名进行可用性监控,需要得到当前的解析结果。下面一一进行介绍。
A记录:
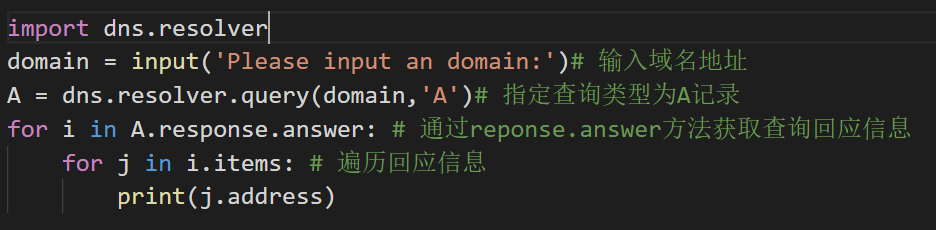
运行结果:www.google.com

MX记录:

运行结果:163.com

NS记录:
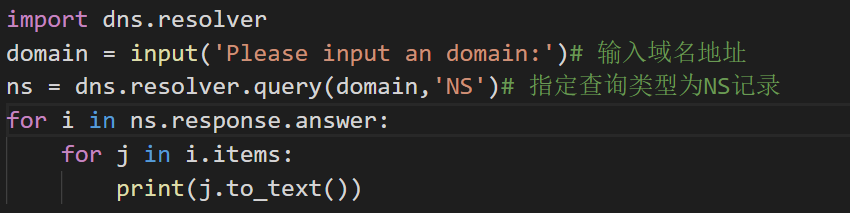
运行结果:baidu.com
CNAME记录:

运行结果:www.baidu.com

(3)实践:DNS域名轮循业务监控
大部分的DNS解析都是一个域名对应一个IP地址,但是通过DNS轮循技术可以做到一个域名对应多个IP,从而实现最简单且高效的负载均衡,不过此方案最大的弊端是目标主机不可用时无法被自动解除,因此做好业务主机的服务可用监控至关重要。本实例通过分析当前域名的解析IP,再结合服务端口探测来实现自动监控,在域名解析中添加,删除IP时,无需对监控脚本进行更改。架构图:
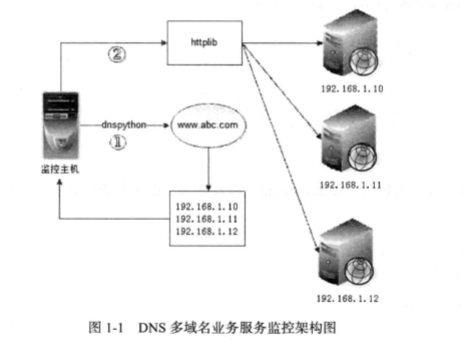
步骤
1.实现域名的解析,获取域名所有的A记录解析IP列表;
2.对IP列表进行HTTP级别的探测
代码解析
第一步通过dns.resolver.query()方法获取业务域名A记录,查询出所有的IP地址列表,在使用httplib模块的request()方法以GET方式请求监控页面,监控业务所有服务的IP是否正常。
Python自动化运维技术与最佳实现的更多相关文章
- Python自动化运维 技术与最佳实践PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:7bl4 一.内容简介 <python自动化运维:技术与最佳实践>一书在中国运维领域将有"划时代"的重要意义:一方面,这是国内第一本从纵.深和实践角度探 ...
- python自动化运维技术读书笔记
import psutilprint(psutil.cpu_times(percpu=True)) #使用cpu_times方法获取CPU完整信息需要显示所有逻辑CPU信息 import psutil ...
- Python自动化运维:技术与最佳实践 PDF高清完整版|网盘下载内附地址提取码|
内容简介: <Python自动化运维:技术与最佳实践>一书在中国运维领域将有“划时代”的重要意义:一方面,这是国内第一本从纵.深和实践角度探讨Python在运维领域应用的著作:一方面本书的 ...
- python自动化运维篇
1-1 Python运维-课程简介及基础 1-2 Python运维-自动化运维脚本编写 2-1 Python自动化运维-Ansible教程-Ansible介绍 2-2 Python自动化运维-Ansi ...
- Day1 老男孩python自动化运维课程学习笔记
2017年1月7日老男孩python自动化运维课程正式开课 第一天学习内容: 上午 1.python语言的基本介绍 python语言是一门解释型的语言,与1989年的圣诞节期间,吉多·范罗苏姆为了在阿 ...
- python自动化运维学习第一天--day1
学习python自动化运维第一天自己总结的作业 所使用到知识:json模块,用于数据转化sys.exit 用于中断循环退出程序字符串格式化.format字典.文件打开读写with open(file, ...
- 【目录】Python自动化运维
目录:Python自动化运维笔记 Python自动化运维 - day2 - 数据类型 Python自动化运维 - day3 - 函数part1 Python自动化运维 - day4 - 函数Part2 ...
- Python自动化运维的职业发展道路(暂定)
Python职业发展之路 Python自动化运维工程 Python基础 Linux Shell Fabric Ansible Playbook Zabbix Saltstack Puppet Dock ...
- 技术沙龙|京东云DevOps自动化运维技术实践
自动化测试体系不完善.缺少自助式的持续交付平台.系统间耦合度高服务拆分难度大.成熟的DevOps工程师稀缺,缺少敏捷文化--这些都是DevOps 在落地过程中,或多或少会碰到的问题,DevOps发展任 ...
随机推荐
- Delphi驱动方式WINIO模拟按键 可用
http://www.delphitop.com/html/yingjian/152.html Delphi驱动方式WINIO模拟按键 作者:admin 来源:未知 日期:2010/2/1 1:14: ...
- ABAP基本数据类型
ABAP 程序中共包含8种基本数据类型: 数据类型名称 描述 属 性 C Character Text(字符类型) 默认长度=1,默认值=blank,最大长度无限制 N Numeric Text(数 ...
- oracle rman catalog--ORA-01580: error creating control backup file
在测试rman catalog时,错误的设置了snapshot路径,报错 RMAN> show snapshot controlfile name; RMAN configuration par ...
- hibernate 2 多对多映射
一.实体类 1.Classes.java package cn.gs.wwg.entity; import java.util.Set; public class Classes { private ...
- Our growth depends not on how many experiences we devour, but on how manywe digest.
rot. v/n. 腐烂 vibration.n. 震动 charcoal. n 木炭 wrinkle. v. 长皱纹 geometry. n. 几何学 walnut.n. 核桃 tailor. n. ...
- Dos - 学习总结(1)
1.控制台复制 1>鼠标右键,标记. 2>选定复制内容后,鼠标右键,完成复制. 2.
- 【JZOJ 3918】蛋糕
题面: 正文: 根据数据\(4\leq R,C\leq 75\)我们大概可以先枚举切横的刀再二分答案. 更具体的: 假设我们已经枚举到这样横切: 再假设我们已经二分到最小的巧克力是\(7\) 康康第一 ...
- UvaLive 6664 Clock Hands
链接:http://vjudge.net/problem/viewProblem.action?id=49409 题意:给一个奇怪的能够记录N小时内时间的表(生活中的表是12小时计时的). 而且给出一 ...
- #define 宏实现函数功能可能存在的问题
#define 宏实现函数功能的问题 情形1 #define free_ptr(p) \ if(p) delete p; p = nullptr; 在调用free_ptr(p)的地方展开看这段代码: ...
- Show Profile
1.是什么:是mysql提供可以用来分析当前会话中语句执行的资源消耗情况.可以用于SQL的调优的测量 2.官网:http://dev.mysql.com/doc/refman/5.7/en/show- ...