pandas数据读取(DataFrame & Series)
1、pandas数据的读取
pandas需要先读取表格类型的数据,然后进行分析
| 数据说明 | 说明 | pandas读取方法 |
| csv、tsv、txt | 用逗号分割、tab分割的纯文本文件 | pd.read_csv |
| excel | 微软xls或者xlsx文件 | pd.read_excel |
| mysql | 关系向数据库表 | pd.read_sql |
#本代码示例: import pandas as pd #导入包 #1读取csv,使用默认的标题行、逗号分割
fpath = “要打开文件的路径”
ratings = pd.read_csv(fpath) #使用pd.read_csv读取数据
ratings.head() #查看前几行(默认5行)
ratings.shape #查看数据的形状,返回(行数、列数)
ratings.columns # 查看列名列表
ratings.index #查看索引列
ratings.dtypes #查看每一列的数据类型 #1.2读取txt文件,自己制定分隔符、列名
fpath = “文件的路径”
pvuv = pd.read_csv(
fpath,
sep = “\t”, #l列的分隔符
header = None,
names = ['pdate','pv','uv']
)
print(pvuv) #读取excel文件
fpath = “文件的路径”
pvuv = pd.read_excel(fpath)
print(pvuv) #读取Mysql数据库
import pmysql
conn = pmysql.connect(
host = '127.0.0.1',
user = 'root',
password = '',
database = 'test',
charest = 'utf8'
)
mysql_page = pd.read_sql("select * from 表名",con=conn)
print(mysql_page)
2、pandas数据结构(DataFrame & Series)
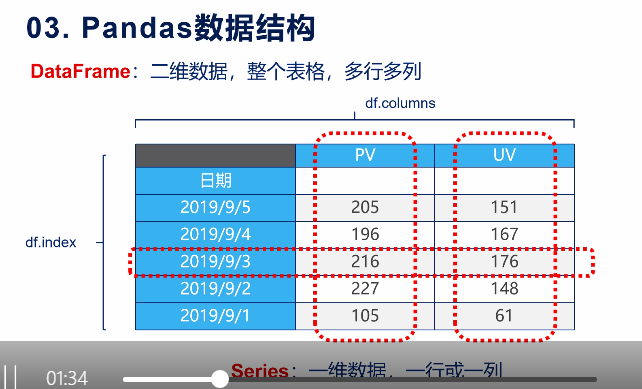
DataFrame:二维数据,整个表格,多行多列
df.columns 查询列
df.index 查询行
Series:一维数据,一行或者一列
#1、 Series
#2、DataFrame
#3、从DAtaFrame中查询出Series import pandas as pd
import numpy as np #series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数#据标签(即索引)组成。 #1.1仅有数据列表即可产生最简单的series
s1 = pd.Series([1,'a',5.2,6])
# print(s1) #左侧为索引,右侧为数据
print(s1.index) #获取索引 结果:RangeIndex(start=0, stop=4, step=1)
print(s1.values) #获取数据 结果:[1 'a' 5.2 6] #1.2 创建一个具有标签索引的Series
s2 = pd.Series([1,'a',5.2,6],index = ['d','b','a','c'])
print(s2)
print(s2.index) #Index(['d', 'b', 'a', 'c'], dtype='object') #1.3 使用python字典创建Series
sdata = {'ohio':3500,'Texas':72000,'Oregs':16000,'Ggrqg':5000}
s3 = pd.Series(sdata)
print(s3) #1.4 根据标签索引查询数据(类似python的字典dict)
print(s2['a'])#5.2
print(type(s2['a']))#<class 'float'>
print(s2[['b','a']]) #2 DataFrame
# DataFrame是一个表格型的数据结构
# 每一列可以是不同的值类型(数值、字符串、布尔值)
# 既有行索引index,也有列索引columns
# 可以被看由Series组成的字典 #2.1根据多个字典序列创建dataframe
data = {
'state':['ofjg','sdfg','werw','wrgwer','rgwg'],
'year':[2000,3000,5000,6000,9000],
'pop':[1.5,1.7,1.6,5.3,3.5]
}
df = pd.DataFrame(data)
print(df) #3.从DataFrame中查询Series
# 如果只查询一列,返回的是pd.Series
# 如果查询多行、多列,返回的是pd.DataFrame # 3.1 查询一列 结果是一个pd.Series
print(df['year'])
print(type(df['year']))#<class 'pandas.core.series.Series'> # 3.2 查询多列,结果是一个pd.DataFrame print(df[['year','pop']])
print(type(df[['year','pop']]))#<class 'pandas.core.frame.DataFrame'> # 3.3 查询一行,结果是一个pd.Series
print(df.loc[1])
print(type(df.loc[1]))#<class 'pandas.core.series.Series'> # 3.4 查询多行,结果是一个pd.DataFrame
print(df.loc[1:3])
print(type(df.loc[1:3]))#<class 'pandas.core.frame.DataFrame'>
pandas数据读取(DataFrame & Series)的更多相关文章
- pandas数据排序(series排序 & DataFrame排序)
# pandas数据排序 # series的排序: # Series.sort_values(ascending = True,inplace = False) # 参数说明: # ascending ...
- Pandas 数据读取
1.读取table # 读取普通分隔数据:read_table # 可以读取txt,csv import os os.chdir('F:/') #首先设置一下读取的路径 data1 = pd.read ...
- 『Pandas』数据读取&DataFrame切片
读取文件 numpy.loadtxt() import numpy as np dataset_filename = "affinity_dataset.txt" X = np.l ...
- pandas数据读取
02. Pandas读取数据 本代码演示: pandas读取纯文本文件 读取csv文件 读取txt文件 pandas读取xlsx格式excel文件 pandas读取mysql数据表 1.读取纯文本文件 ...
- Python数据分析之pandas基本数据结构:Series、DataFrame
1引言 本文总结Pandas中两种常用的数据类型: (1)Series是一种一维的带标签数组对象. (2)DataFrame,二维,Series容器 2 Series数组 2.1 Series数组构成 ...
- 数据分析——Pandas的用法(Series,DataFrame)
我们先要了解,pandas是基于Numpy构建的,pandas中很多的用法和numpy一致.pandas中又有series和DataFrame,Series是DataFrame的基础. pandas的 ...
- 吴裕雄--天生自然python学习笔记:pandas模块读取 Data Frame 数据
读取行数据 读取一个列数据的语法为: 例如,读取所有学生自然科目的成绩 : import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56 ...
- Spark:读取mysql数据作为DataFrame
在日常工作中,有时候需要读取mysql的数据作为DataFrame数据源进行后期的Spark处理,Spark自带了一些方法供我们使用,读取mysql我们可以直接使用表的结构信息,而不需要自己再去定义每 ...
- pandas 从txt读取DataFrame&DataFrame格式化保存到txt
前提 首先保证你txt里的文本内容是有规律可循的(例如,列与列之间通过“\t”.“,”等指定的可识别分隔符分隔): 例如我需要读取的数据,(\t)分隔: (此文件内容是直接以DataFrame格式化写 ...
随机推荐
- C++ Boost库的编译及使用
https://www.jianshu.com/p/de1fda741beb https://www.cnblogs.com/weizhixiang/p/5804778.html Windows编译 ...
- spark 学习网站和资料
spark 官网首页 https://spark.apache.org/ spark 官网文档 spark scala API 文档 https://spark.apache.org/docs/lat ...
- leetcode-mid-array-73 set matrix zeros
mycode 空间复杂度 m+n 思路:用set把为0元素所在行.列记录下来 注意:注释的方法更快 class Solution(object): def setZeroes(self, matrix ...
- review star 评论-评分 文本分析
<!DOCTYPE html> Title 立项背景: 0-突然被限制,无法访问原amazon_asin_reviews_us数据库: 1-原数据库asin类别.厂家信息不明: 2-自然语 ...
- vue +ts 在router的路由中import报错的解决方案
在router.ts中引入.vue文件,会提示打不到module,但是编译可能成功,运行也不报错 找了好久,发现了这个答案 https://segmentfault.com/a/11900000167 ...
- 阶段1 语言基础+高级_1-3-Java语言高级_06-File类与IO流_01 File类_5_File类获取功能的方法
获取的方法 GetAbsolutepath 传递一个相对路径进去,查看输出的结果 输出的还是绝对的路径 getPath 获取的就是构造方法中传递的路径,可以传递绝对路径也可以传递相对路径 实际上toS ...
- UI自动化之日志的处理
写自动化时,我们常常希望打印出浏览器的操作记录,也同时希望报错的记录能够保留并用于问题的排查,这时候可以用到loggging模块 目录 1.logging文件 2.调用日志 1.logging文件 # ...
- 【ABAP系列】SAP ABAP实现发送外部邮件(添加附件)功能
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP ABAP实现发送外部邮件(添 ...
- thead tbody tfoot
<!DOCTYPE html> <html lang="en"> <head> <title>Title</title> ...
- Vue 基础 day03
定义Vue 组件 什么是组件:组件的出现,就是为了拆分 Vue 实例的代码量,能够让我们以不同的组件,来划分不同的功能模块,将来我们需要什么样的功能,就可以去调用对应的组件: 组件化和模块化的不同: ...