CUDA页锁定内存(Pinned Memory)
对CUDA架构而言,主机端的内存被分为两种,一种是可分页内存(pageable memroy)和页锁定内存(page-lock或 pinned)。可分页内存是由操作系统API malloc()在主机上分配的,页锁定内存是由CUDA函数cudaHostAlloc()在主机内存上分配的,页锁定内存的重要属性是主机的操作系统将不会对这块内存进行分页和交换操作,确保该内存始终驻留在物理内存中。
GPU知道页锁定内存的物理地址,可以通过“直接内存访问(Direct Memory Access,DMA)”技术直接在主机和GPU之间复制数据,速率更快。由于每个页锁定内存都需要分配物理内存,并且这些内存不能交换到磁盘上,所以页锁定内存比使用标准malloc()分配的可分页内存更消耗内存空间。
页锁定内存的内配、操作和可分页内存的对比:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "iostream"
#include <stdio.h>
using namespace std;
float cuda_host_alloc_test(int size, bool up)
{
//耗时统计
cudaEvent_t start, stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
int *a, *dev_a;
//在主机上分配页锁定内存
cudaError_t cudaStatus = cudaHostAlloc((void **)&a, size * sizeof(*a), cudaHostAllocDefault);
if (cudaStatus != cudaSuccess)
{
printf("host alloc fail!\n");
return -1;
}
//在设备上分配内存空间
cudaStatus = cudaMalloc((void **)&dev_a, size * sizeof(*dev_a));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!\n");
return -1;
}
//计时开始
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
//从主机到设备复制数据
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy Host to Device failed!\n");
return -1;
}
//从设备到主机复制数据
cudaStatus = cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy Device to Host failed!\n");
return -1;
}
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaFreeHost(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return (float)elapsedTime / 1000;
}
float cuda_host_Malloc_test(int size, bool up)
{
//耗时统计
cudaEvent_t start, stop;
float elapsedTime;
cudaEventCreate(&start);
cudaEventCreate(&stop);
int *a, *dev_a;
//在主机上分配可分页内存
a = (int*)malloc(size * sizeof(*a));
//在设备上分配内存空间
cudaError_t cudaStatus = cudaMalloc((void **)&dev_a, size * sizeof(*dev_a));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!\n");
return -1;
}
//计时开始
cudaEventRecord(start, 0);
for (int i = 0; i < 100; i++)
{
//从主机到设备复制数据
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(*dev_a), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy Host to Device failed!\n");
return -1;
}
//从设备到主机复制数据
cudaStatus = cudaMemcpy(a, dev_a, size * sizeof(*dev_a), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy Device to Host failed!\n");
return -1;
}
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
free(a);
cudaFree(dev_a);
cudaEventDestroy(start);
cudaEventDestroy(stop);
return (float)elapsedTime / 1000;
}
int main()
{
float allocTime = cuda_host_alloc_test(100000, true);
cout << "页锁定内存: " << allocTime << " s" << endl;
float mallocTime = cuda_host_Malloc_test(100000, true);
cout << "可分页内存: " << mallocTime << " s" << endl;
getchar();
return 0;
}
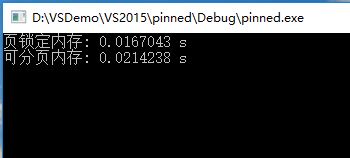
对比效果,页锁定内存的访问时间约为可分页内存的访问时间的一半:
CUDA页锁定内存(Pinned Memory)的更多相关文章
- 6.1 CUDA: pinned memory固定存储
CPU和GPU内存交互 在CUDA编程中,内存拷贝是非常费时的一个动作. 从上图我们可以看出:1. CPU和GPU之间的总线bus是PCIe,是双向传输的. 2. CPU和GPU之间的数据拷贝使用DM ...
- 如何启用“锁定内存页”选项 (Windows)
默认情况下,禁用 Windows 策略"锁定内存页"选项.必须启用此权限才能配置地址窗口化扩展插件 (AWE).此策略将确定哪些帐户可以使用进程将数据保留在物理内存中,从而阻止系统 ...
- [SPDK/NVMe存储技术分析]015 - 理解内存注册(Memory Registration)
使用RDMA, 必然关系到内存区域(Memory Region)的注册问题.在本文中,我们将以mlx5 HCA卡为例回答如下几个问题: 为什么需要注册内存区域? 注册内存区域有嘛好处? 注册内存区域的 ...
- linux内核剖析(十一)进程间通信之-共享内存Shared Memory
共享内存 共享内存是进程间通信中最简单的方式之一. 共享内存是系统出于多个进程之间通讯的考虑,而预留的的一块内存区. 共享内存允许两个或更多进程访问同一块内存,就如同 malloc() 函数向不同进程 ...
- 内存管理 - MEMORY POOL
内存池优势: 效率高,频繁的new和delete效率低下 减少内存碎片,反复向系统申请和释放内存会产生大量内存碎片 防止内存泄露 内存池设计思路: 内存池可以根据实际需要,设计成不同的样子.下面是针对 ...
- 内存分配器 (Memory Allocator)
对于大多数开发人员而言,系统的内存分配就是一个黑盒子,就是几个API的调用.有你就给我,没有我就想别的办法. 来UC前,我就是这样觉得的.实际深入进去时,才发现这个领域里也是百家争鸣.非常热闹.有操作 ...
- 从五大结构体,带你掌握鸿蒙轻内核动态内存Dynamic Memory
摘要:本文带领大家一起剖析了鸿蒙轻内核的动态内存模块的源代码,包含动态内存的结构体.动态内存池初始化.动态内存申请.释放等. 本文分享自华为云社区<鸿蒙轻内核M核源码分析系列九 动态内存Dyna ...
- Android 内存管理 &Memory Leak & OOM 分析
转载博客:http://blog.csdn.net/vshuang/article/details/39647167 1.Android 进程管理&内存 Android主要应用在嵌入式设备当中 ...
- 关于Linux的缓存内存 Cache Memory详解<转>
转自 http://www.ha97.com/4337.html PS:前天有童鞋问我,为啥我的Linux系统没运行多少程序,显示的可用内存这么少?其实Linux与Win的内存管理不同,会尽量缓存内存 ...
随机推荐
- MongoDbHelper 帮助类(下)
对MongoDbHelper帮助类进行了一下整合,但是代码中一个方法需要将string类型转化为BsonValue类型一直出错.所以欢迎留言指正 using System; using System. ...
- 第三方插件将数据转成json
1.需要使用第三方jar commons-beanutils-1.7.0.jar /commons-collections-3.1.jar/commons-lang-2.5jar /commons-l ...
- 前端js常用正则表达式实例讲解
本文内容整理自他人优秀的博客,非纯原创.仅借此学习和整理. 1.匹配用户名 规则描述: 长度4-6位: {4,16} 字母: [a-z] [A-Z] 数字: [0-9] 下划线: [_] 减号: [- ...
- 14、编写一个通用的Makefile
编译test_Makefile的方法:a. gcc -o test a.c b.c对于a.c: 预处理.编译(C文件转换成汇编).汇编(汇编转换成机器码)对于b.c:预处理.编译.汇编最后链接优点:命 ...
- android Fragment与Activity交互,互相发数据(附图具体解释)
笔者最近看官方training.发现了非常多实用又好玩的知识. 当中.fragment与Activity通信就是一个. fragment与Activity通信主要是两点: 1.fragment传递信息 ...
- php 面试题一(看视频的学习量比网上瞎转悠要清晰和明了很多)(看视频做好笔记)(注重复习)
php 面试题一(看视频的学习量比网上瞎转悠要清晰和明了很多)(看视频做好笔记)(注重复习) 一.总结 1.无线分类的本质是树(数据结构)(数的话有多种储存结构可以实现,所以对应的算法也有很多),想到 ...
- stm32的电源
有人说rtc会不工作
- [outlook] [vba] Highlight text in body of incoming emails
http://www.outlookcode.com/threads.aspx?forumid=2&messageid=33313 Sub CustomMailMessageRule(MyMa ...
- UTC、GTC时间和本地时间(Linux默认使用UTC时间,要修改一下)
1.问题 对于装有Windows和Linux系统的机器,进入Windows显示的时间和Linux不一致,Linux中的时间比Windows提前8个小时. 2.解决方法 修改/etc/default/r ...
- 如何知道刚刚插入数据库那条数据的id
如何知道刚刚插入数据库那条数据的id 一.总结 一句话总结:这些常见功能各个框架里面都有,可以查看手册,thinkphp里面是$userId = Db::name('user')->getLas ...