<一> 爬虫的原理
一、爬虫是什么?
#1、什么是互联网?
互联网是由网络设备(网线,路由器,交换机,防火墙等等)和一台台计算机连接而成,像一张网一样。
#2、互联网建立的目的?
互联网的核心价值在于数据的共享/传递:数据是存放于一台台计算机上的,而将计算机互联到一起的目的就是为了能够方便彼此之间的数据共享/传递,否则你只能拿U盘去别人的计算机上拷贝数据了。
#3、什么是上网?爬虫要做的是什么?
我们所谓的上网便是由用户端计算机发送请求给目标计算机,将目标计算机的数据下载到本地的过程。
#3.1 只不过,用户获取网络数据的方式是:
浏览器提交请求->下载网页代码->解析/渲染成页面。
#3.2 而爬虫程序要做的就是:
模拟浏览器发送请求->下载网页代码->只提取有用的数据->存放于数据库或文件中
#3.1与3.2的区别在于:
我们的爬虫程序只提取网页代码中对我们有用的数据
#4、总结爬虫
#4.1 爬虫的比喻:
如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的猎物/数据
#4.2 爬虫的定义:
向网站发起请求,获取资源后分析并提取有用数据的程序
#4.3 爬虫的价值:
互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,
可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,
掌握了爬虫技能,你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
二、爬虫的基本流程
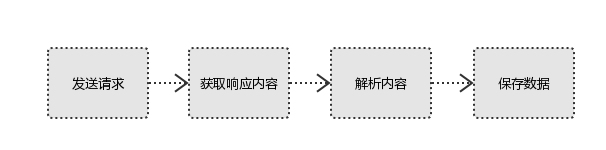
#1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
#2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
#3、解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以b的方式写入文件
#4、保存数据
数据库
文
三、请求与响应
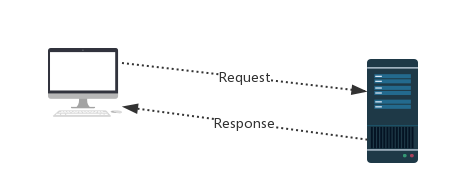
#http协议:http://www.cnblogs.com/haiyan123/p/7298967.html
#Request:用户将自己的信息通过浏览器(socket client)发送给服务器(socket server)
#Response:服务器接收请求,分析用户发来的请求信息,然后返回数据(返回的数据中可能包含其他链接,如:图片,js,css等)
#ps:浏览器在接收Response后,会解析其内容来显示给用户,而爬虫程序在模拟浏览器发送请求然后接收Response后,是要提取其中的有用数据。
四、Request
#1、请求方式:
常用的请求方式:GET,POST
其他请求方式:HEAD,PUT,DELETE,OPTHONS
ps:用浏览器演示get与post的区别,(用登录演示post)
post与get请求最终都会拼接成这种形式:k1=xxx&k2=yyy&k3=zzz
post请求的参数放在请求体内:
可用浏览器查看,存放于form data内
get请求的参数直接放在url后
#2、请求url
url全称统一资源定位符,如一个网页文档,一张图片
一个视频等都可以用url唯一来确定
url编码
https://www.baidu.com/s?wd=图片
图片会被编码(看示例代码)
网页的加载过程是:
加载一个网页,通常都是先加载document文档,
在解析document文档的时候,遇到链接,则针对超链接发起下载图片的请求
#3、请求头
User-agent:告诉它这是浏览器发过来的请求(请求头中如果没有user-agent客户端配置,服务端可能将你当做一个非法用户)务必加上
host
cookies:cookie用来保存登录信息
Referer:上一次的跳转路径
一般做爬虫都会加上请求头
#4、请求体
如果是get方式,请求体没有内容
如果是post方式,请求体是format data
ps:
1、登录窗口,文件上传等,信息都会被附加到请求体内
2、登录,输入错误的用户名密码,然后提交,就可以看到post,正确登录后页面通常会跳转,无法捕捉到post
import requests
from urllib.parse import urlencode
# 请求方式
kwords = input("请输入关键字:>>").strip()
res = urlencode({"wd":kwords}) # # 请求的url,当你在百度输入中文的时候,你把url拿下来会变成下面的这样格式的url,所以得urlencode一下
url ="https://www.baidu.com/s?"+res #https://www.baidu.com/s?wd=%E5%9B%BE%E7%89%87 response = requests.get(
# 请求的url,当你在百度输入中文的时候,你把url拿下来会变成下面的这样格式的url
url,
# 请求头
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36",
},
)
with open("a.html","w",encoding="utf-8") as f:
f.write(response.text)
# print(response.status_code) 示例代码1
五、Response
#1、响应状态
200:代表成功
301:代表跳转
404:文件不存在
403:权限
502:服务器错误 #2、Respone header
Location:跳转
set-cookie:可能有多个,是来告诉浏览器,把cookie保存下来 #3、preview就是网页源代码
最主要的部分,包含了请求资源的内容
如网页html,图片
二进制数据等
#1、总结爬虫流程:
爬取--->解析--->存储
#2、爬虫所需工具:
请求库:requests,selenium
解析库:正则,beautifulsoup,pyquery
存储库:文件,MySQL,Mongodb,Redis
#3、爬虫常用框架:
scrapy
源自老铁:海燕
<一> 爬虫的原理的更多相关文章
- 开源磁力搜索爬虫dhtspider原理解析
开源地址:https://github.com/callmelanmao/dhtspider. 开源的dht爬虫已经有很多了,有php版本的,python版本的和nodejs版本.经过一些测试,发现还 ...
- Java爬虫搜索原理实现
permike 原文 Java爬虫搜索原理实现 没事做,又研究了一下爬虫搜索,两三天时间总算是把原理闹的差不多了,基本实现了爬虫搜索的原理,本次实现还是俩程序,分别是按广度优先和深度优先完成的,广度优 ...
- C# 爬虫框架实现 流程_爬虫结构/原理
目录链接:C# 爬虫框架实现 概述 首先需要讲的是,爬虫的原理.其实在我看来,爬虫只是用来解决以下四个问题的工具: 提取哪些网页 提取网页上的哪些内容 存储到哪里(推荐数据库/开源类/Console) ...
- 爬虫的原理获取html中的图片到本地
如果你想获取哪个网页的图片,如果你想知道那个网址的美女,还等什么.代码走起:下载即可使用 完成这次瞎爬的原理如下: 第一步:获取html内容 * 第二步:然后在获取的html文本中寻找图片,根据htm ...
- python爬虫从入门到放弃(二)之爬虫的原理
在上文中我们说了:爬虫就是请求网站并提取数据的自动化程序.其中请求,提取,自动化是爬虫的关键!下面我们分析爬虫的基本流程 爬虫的基本流程 发起请求通过HTTP库向目标站点发起请求,也就是发送一个Req ...
- 爬虫 http原理,梨视频,github登陆实例,requests请求参数小总结
回顾:http协议基于请求响应的方式,请求:请求首行 请求头{'keys':vales} 请求体 :响应:响应首行,响应头{'keys':'vales'},响应体. import socket soc ...
- Python爬虫的原理
简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML.JS.CSS代码返回给浏览器,这些代码经过浏览器解析.渲染,将丰富多彩的网页呈现我们眼前: 一.爬虫是什么? ...
- python之爬虫(二)爬虫的原理
在上文中我们说了:爬虫就是请求网站并提取数据的自动化程序.其中请求,提取,自动化是爬虫的关键!下面我们分析爬虫的基本流程 爬虫的基本流程 发起请求通过HTTP库向目标站点发起请求,也就是发送一个Req ...
- python爬虫实现原理
前言 简单来说互联网是由一个个站点和网络设备组成的大网,我们通过浏览器访问站点,站点把HTML.JS.CSS代码返回给浏览器,这些代码经过浏览器解析.渲染,将丰富多彩的网页呈现我们眼前: 一.爬虫是什 ...
随机推荐
- cogs 49. 跳马问题
49. 跳马问题 ★ 输入文件:horse.in 输出文件:horse.out 简单对比时间限制:1 s 内存限制:128 MB [问题描述] 有一只中国象棋中的 “ 马 ” ,在半张 ...
- Python标准库:内置函数all(iterable)
假设可迭代的对象的所有元素所有非空(或者空迭代对象),就返回True.这个函数主要用来推断列表.元组.字典等对象是否有空元素.比方有10000个元素的列表,假设没有提供此函数,须要使用循环来实现.那么 ...
- 53.遇到SyntaxError: Unexpected token
转自:https://segmentfault.com/q/1010000002649920/a-1020000002655984 不知道你自己现在已经发现问题没, Unexpected token ...
- vue+mui+html5+ plus开发的混合应用底部导航的显示与隐藏
1. 模板相关内容(template) <template> <div> <transition :name="transitionName"> ...
- 00084_Map接口
1.Map接口概述 通过查看Map接口描述,发现Map接口下的集合与Collection接口下的集合,它们存储数据的形式不同. (1)Collection中的集合,元素是孤立存在的(理解为单身),向集 ...
- Android eclipse 提示java代码 快捷键
1.提示java代码能够用ALT+/ 键就能够了(前提是你要把你须要的类或方法的首字母打出来).我添加的部分:仅仅要输入sysout,然后alt+/键就能够输出System.out.prinln(), ...
- webclient类学习
(HttpWebRequest模拟请求登录):当一些硬件设备接口 或需要调用其他地方的接口时,模拟请求登录获取接口的数据就很有必要. webclient类:只想从特定的URI请求文件,则使用WebCl ...
- Oracle APEX 4.2公布RESTful Webservice
Purpose This tutorial covers creating a RESTful Web Service and accessing the Web Service through an ...
- windows 2016 配置 VNC 服务
windows 2016 配置 VNC 服务 下载windows版 https://www.realvnc.com/download/vnc/ 安装时勾选 vncserver 进入 "C:\ ...
- Funui-Theme 资源的替换
实现资源的替换,需要分为以下几个步骤 1.找到需要更改的模块 mediatek/packages/apps/FileManager 2.到主题模块下根据包名找到相应资源(以Grass为例) cd ve ...