SqlSever2005 一千万条以上记录分页数据库优化经验总结【索引优化 + 代码优化】
对普通开发人员来说经常能接触到上千万条数据优化的机会也不是很多,这里还是要感谢公司提供了这样的一个环境,而且公司让我来做优化工作。当数据库中的记录不超过10万条时,很难分辨出开发人员的水平有多高,当数据库中的记录条数超过1000万条后,还是蛮能考验开发人员的综合技术能力。
当然不是每个公司都能请得起专业的DBA,话又说过来专业的DBA也未必能来我们公司长期工作,这就不只是薪资待遇问题了还会涉及到人家的长期发展规划了,当然我也不是专业的DBA,本着能把问题解决好就是好猫的理念。
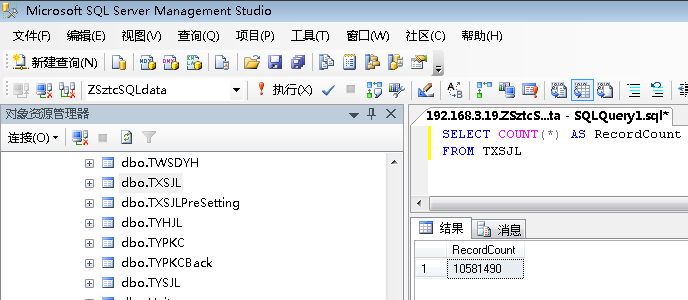
我们先看图,数据库中的记录数如下:记录数为10581490条同时还需要从另外一个表读取7万多条数据。
页面运行效果如下: 这是查看某个单位的数据,每页显示16条、记录数1087292条、分页数为67956页。 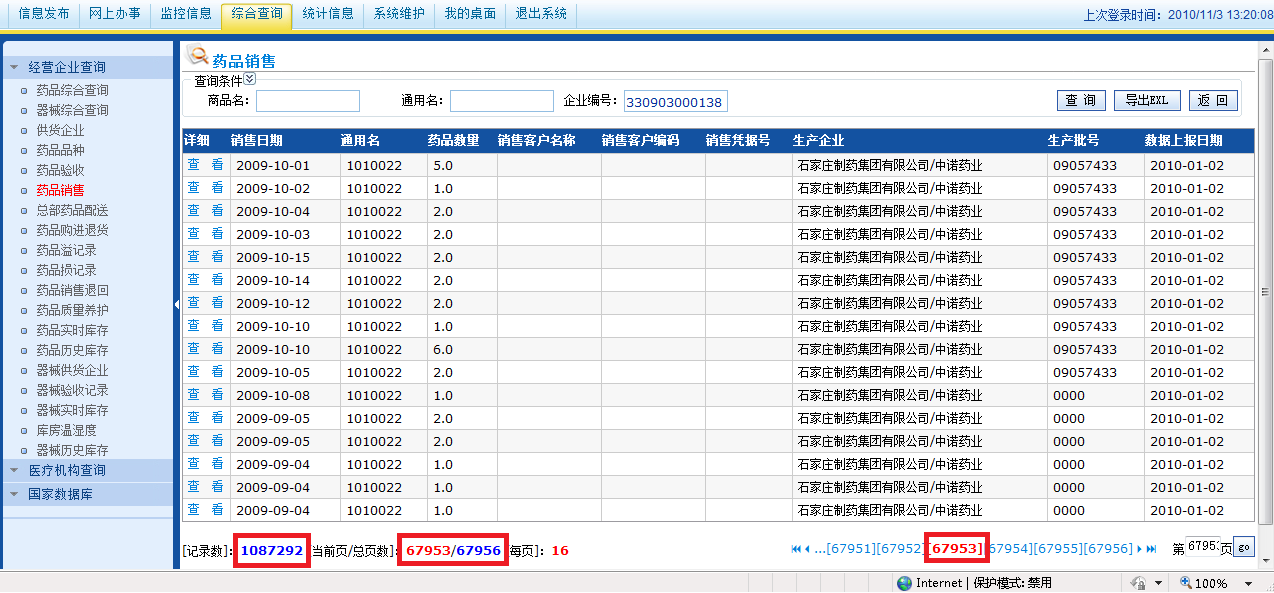
遇到的难题如下:
1:当客户用了几年后数据变得很庞大分页速度缓慢得要命几乎到了无法忍受的程度。
2:分页到最后一页时往往速度很慢会有死机现象出现,特别是记录条数很多时死机现象比较多。
那再讲讲,解决问题的方法步骤:
1:首先优化数据库、因为程序也很复杂一时也看不过来也不敢乱改,先从数据库字段类型优化开始入手会好很多。
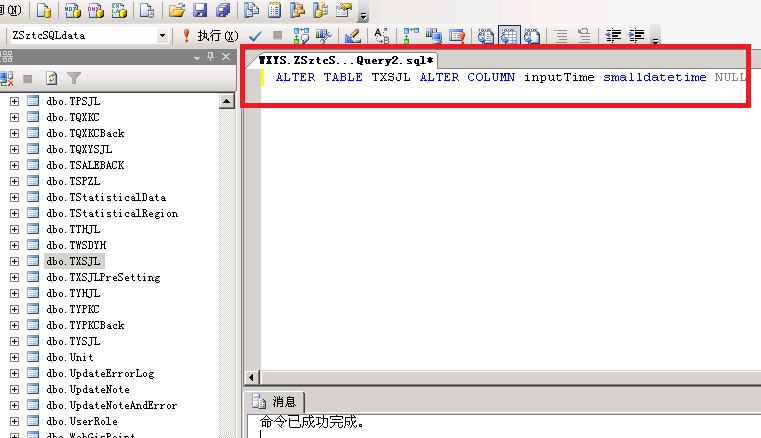
先把数据库里的 datetime 都修改为 smalldatetime,数据库变小了几百M很有成就感,最起码磁盘的读取压力减少不少吧。由于数据库数据有上千万条,无法用管理工具修改结构,只能用新建查询执行SQL命令才可以。
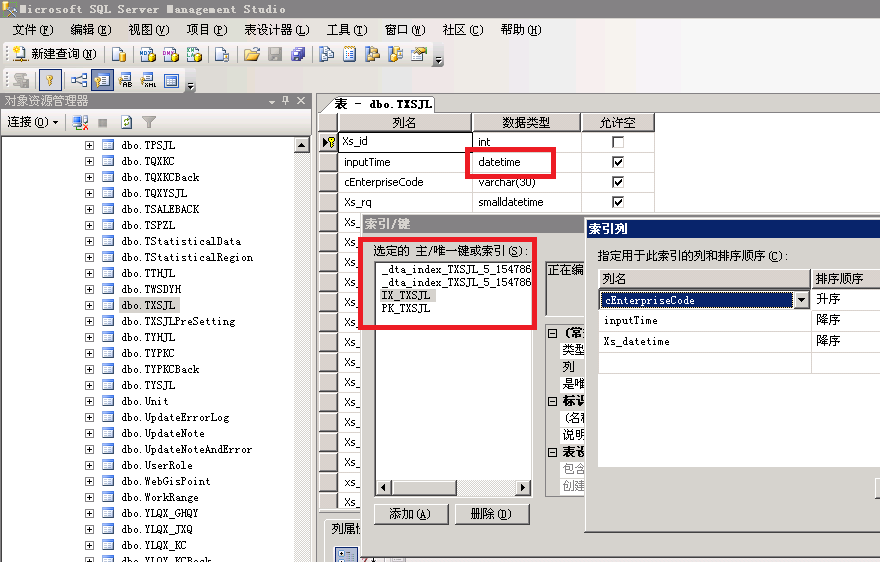
会有如下超时现象会发生。
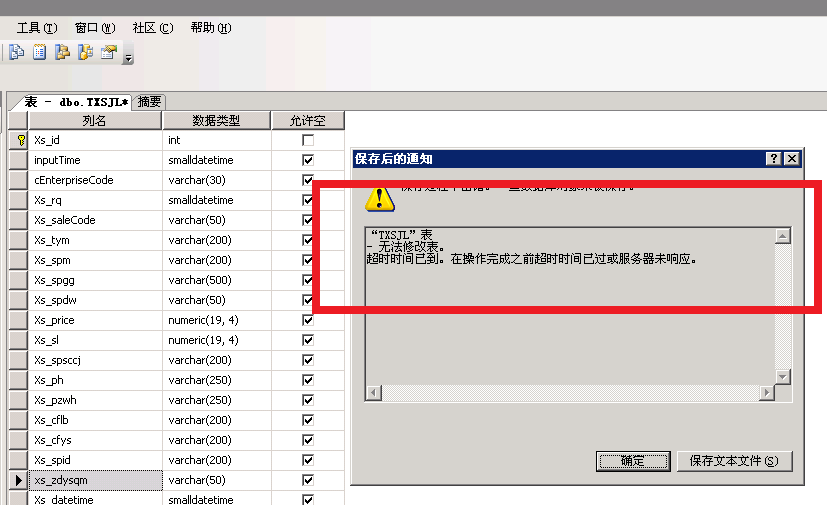
那我们只能用执行查询的方式对表结构进行调整了,每次执行一个SQL指令大概需要10分钟时间才能顺利执行好,数据量实在是太大了。
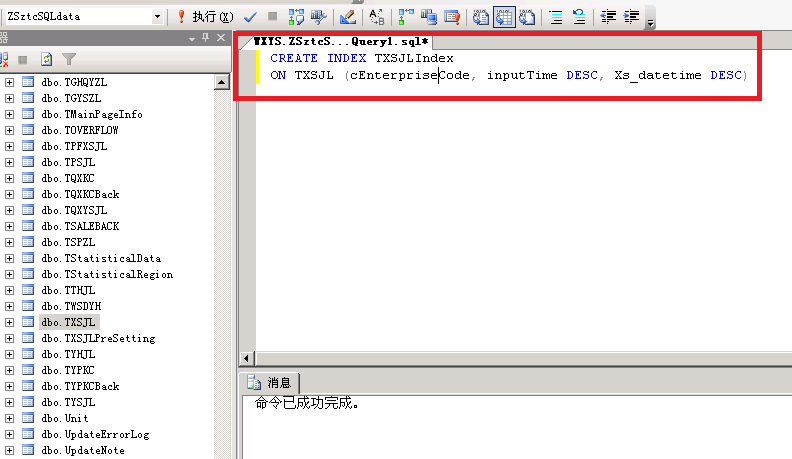
2:接着再优化,数据库索引,原先的索引很乱可以理解为是乱来的所以我全部干掉重新进行了组织。
把多余的索引先通通干掉,然后重新建立索引,因为记录数太庞大了,有多余的索引会使数据库变大很庞大,给他先减轻减轻体重。
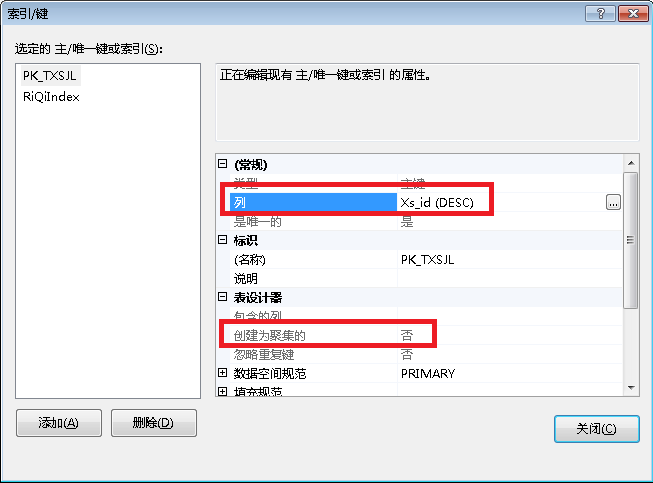
把主键设置为倒序的、非聚集的,这样的好处是可以把最新的数据排序在最前面。
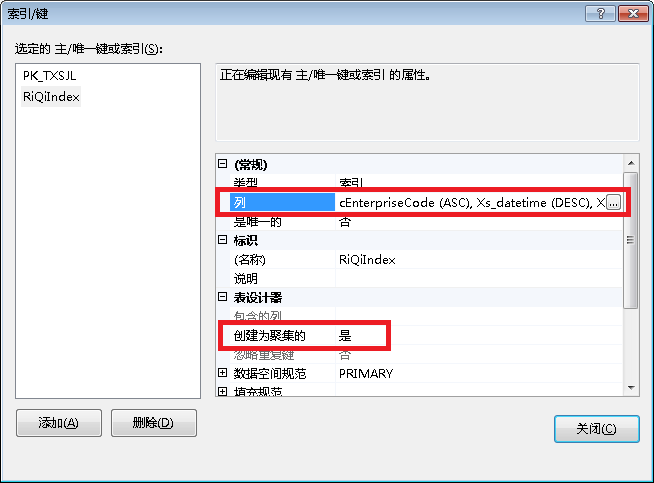
把主要查询的条件设置为索引,Group By 的放第一个位置然后设置为聚集索引,这样的好处时查询时会快很多很多,普通所以没这个效率高,数据实在是太庞大了,超过了1000万条数据后,对比一下还是很明显的,都能感觉得到。
完成以上2个步骤后分页速度快了很多最起码没死机现象了, 还有一点遗憾是当数据量大时最后一页的分页速度还是有些慢,有些难以忍受的感觉,但是最起码不会死机了。
3:接着重点优化,数据库分页的存储过程,最后一页难以忍受的问题先解决一下。分页是用了 SELECT TOP N 的反转的方式,我把最后一页到底获取多少条记录准确数字计算出来,适当的修改了一下最后一页慢得死去活来的问题,得到了适当的环节,虽然没能彻底解决也速度明显快了一些,由于写的这个分页程序也有些复杂,我也不敢乱动,就把问题解决好就完事大吉的目的了,不去惹更多的麻烦了。
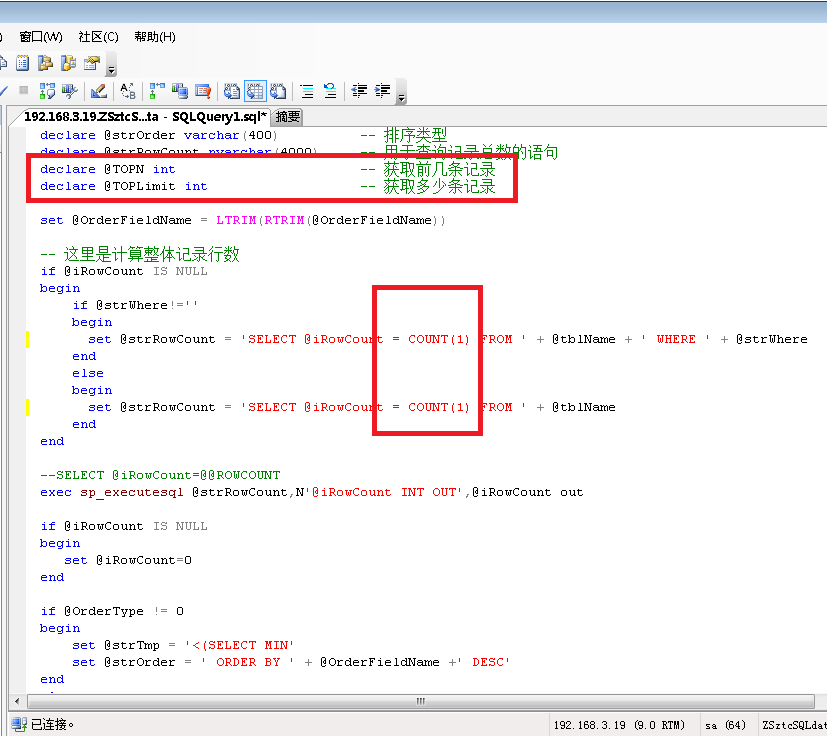
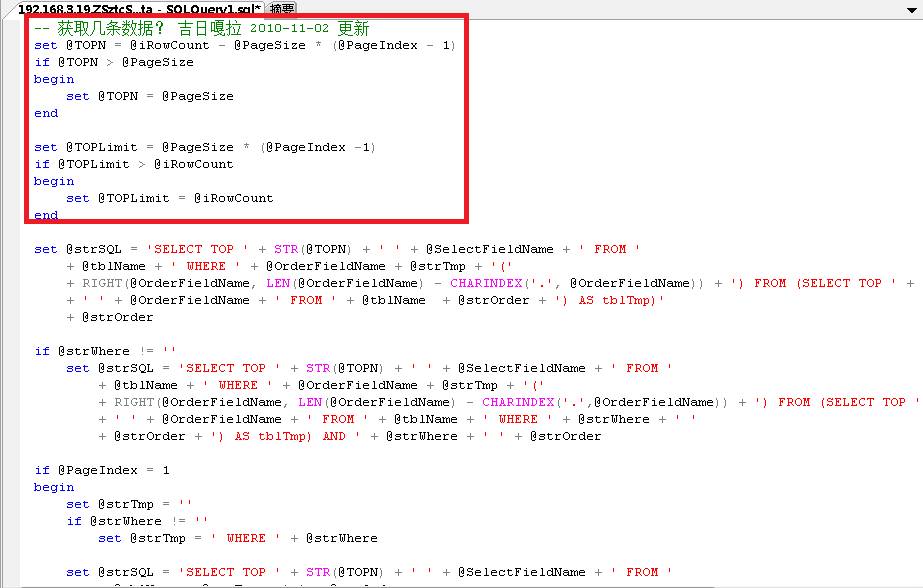
4:对比一下数据库结构优化后的前后如下图
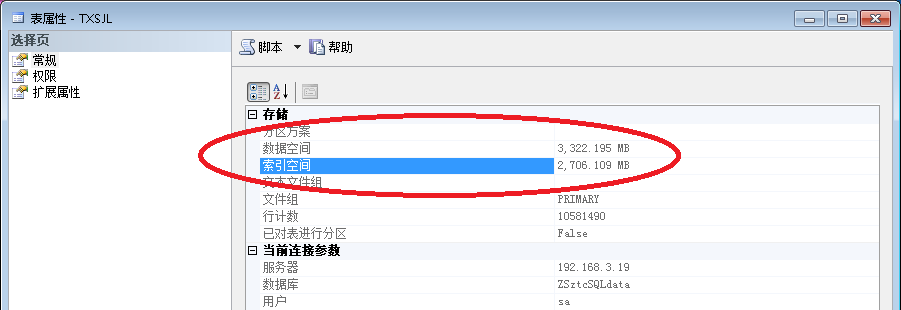
索引优化前索引占用空间 2706.109M
索引优化后索引占用空间 520.805M
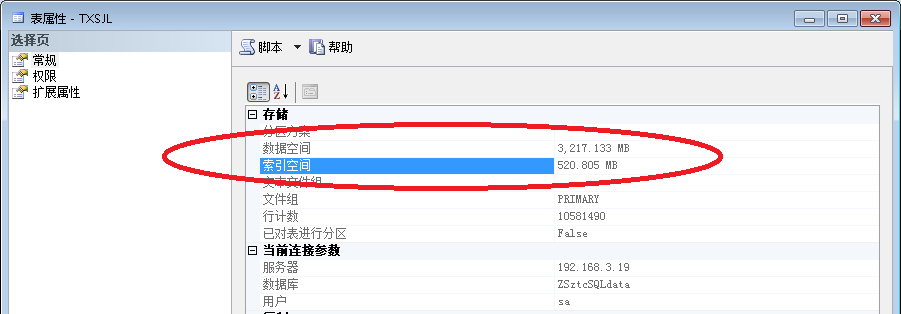
我想就这么一个1000w条记录的表光索引就优化了2200M空间,就单单这个也提高不少性能了。
5:接着重点优化,程序代码部分了,其实代码优化是在索引优化之前的,因为先读懂了代码、读懂了业务逻辑才好优化索引,这边文章写着写着顺序有些颠倒了,大家心里有数就可以了,我还是按照我的思路继续写吧。
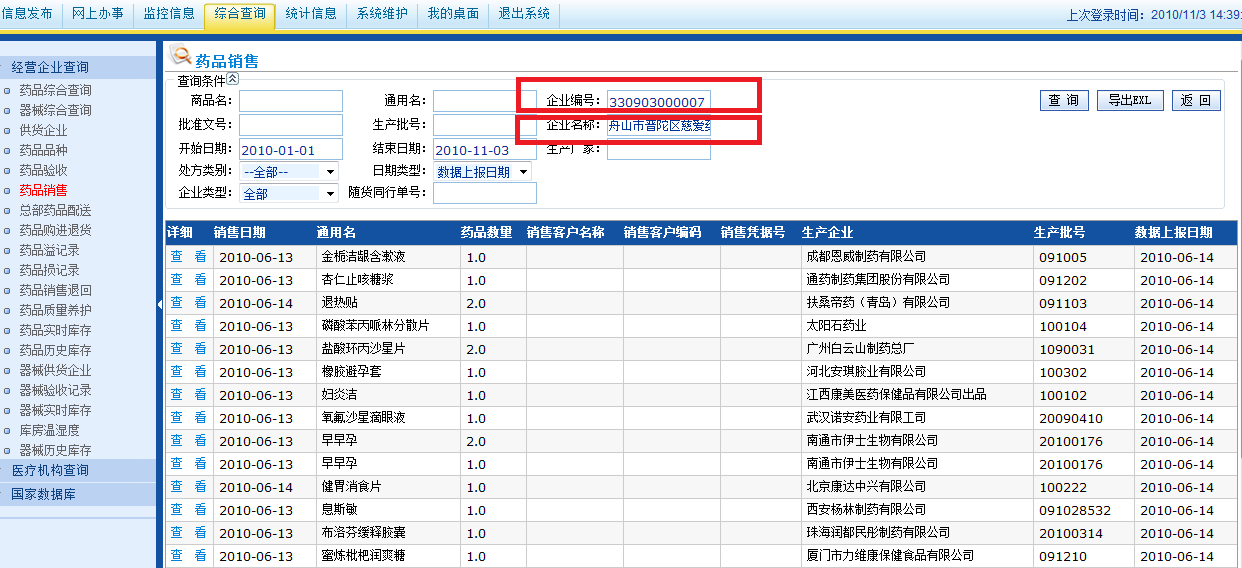
在上图的企业编号、企业名称等,在程序里都进行了LIKE处理,当数据库记录超过1000万条时,对字符进行Like操作,那真是会要命的,毕竟那么多数据都进行一次匹配,虽然电脑的运算速度很快,但是上千万条记录,这么被计算过一下,能快到哪里去啊?
改进方法:
A: 输入企业编号、企业名称修改为模糊查询,能明确定位一个药店的名称。
B: 若已经获得企业编号了,不再匹配企业名称,而且企业编号用 = 来判断,并把企业编号进行索引。
海量数据库分页优化总结:
折腾了接近1周左右,终于把这个1千多万条记录的数据表给优化好了,难题也解决好了虽然不太科学也不专业也缺少理论依据、试验数据、图表对比、性能调试工具等等,但是还好把问题都解决好了,老鼠抓到了就是好猫咪了哈哈。
数据库进行了彻底的翻天覆地的优化、程序代码也进行了彻底的翻天覆地的优化后,分页速度飞快了。每页显示16条、记录数1087292条、分页数为67956页,每页分页速度都完全在3秒内,最后一页也不会死机了,也蛮快的足够可以忍受了。
等有空时,再把最后一页分页速度慢的问题再深入解决一下,先不去惹麻烦了稍微休息一下再说。
优化的每个动作需要10分钟左右才会执行好,若做错一次基本上就代表半个小时白忙乎了,还需要删除掉,再重新执行修正过的SQL语句,所以一天下来优化的成果并不会非常明显、需要几天时间才能优化好。
销售记录表 TXSJL 记录数:1058 1490
批发销售记录表 TXSJL 记录数: 7 0814
|
日期区间 |
药店名称 |
药品数量 |
记录条数 |
第一页 |
第十页 |
最后一页 |
|
2010-08-01 2010-08-31 |
330903000011 舟山市普陀区芦花药店 |
4751 |
2261 |
0.235 秒 |
0.143 秒 |
0.21 秒 |
|
330903000142 舟山市万民大药房有限公司普陀分公司 |
70 5668 |
2 1019 |
0.47 秒 |
0.275 秒 |
0.2 秒 |
|
|
2010-07-01 2010-09-30 |
330903000011 舟山市普陀区芦花药店 |
1 2952 |
6580 |
0.268 秒 |
0.115 秒 |
0.155 秒 |
|
330903000138 舟山布衣大药房有限公司平阳浦分公司 |
136 8949 |
41 9478 |
0.26 秒 |
0.205 秒 |
0.815 秒 |
|
|
2010-04-01 2010-09-30 |
330903000011 舟山市普陀区芦花药店 |
2 6068 |
12423 |
0.155 秒 |
0.155 秒 |
0.125 秒 |
|
330903000138 舟山布衣大药房有限公司平阳浦分公司 |
260 6635 |
80 9012 |
0.29 秒 |
0.315 秒 |
0.74 秒 |
|
|
2010-01-01 2010-09-30 |
330903000048 舟山市布衣大药房有限公司 |
850 1598 |
217 3053 |
0.275 秒 |
0.34 秒 |
0.745 秒 |
SqlSever2005 一千万条以上记录分页数据库优化经验总结【索引优化 + 代码优化】的更多相关文章
- [转]SqlSever2005 一千万条以上记录分页数据库优化经验总结【索引优化 + 代码优化】一周搞定
对普通开发人员来说经常能接触到上千万条数据优化的机会也不是很多,这里还是要感 谢公司提供了这样的一个环境,而且公司让我来做优化工作.当数据库中的记录不超过10万条时,很难分辨出开发人员的水平有多高,当 ...
- SqlSever2005 一千万条以上记录分页数据库优化经验总结
http://www.cnblogs.com/jirigala/archive/2010/11/03/1868011.html 待测试???
- MS SqlSever一千万条以上记录分页数据库优化经验总结【索引优化 + 代码优化】[转]
对普通开发人员来说经常能接触到上千万条数据优化的机会也不是很多,这里还是要感谢公司提供了这样的一个环境,而且公司让我来做优化工作.当数据库中的记录不超过10万条时,很难分辨出开发人员的水平有多高,当数 ...
- 数据库系列:MySQL索引优化总结(综合版)
1 背景 作为一个常年在一线带组的Owner以及老面试官,我们面试的目标基本都是一线的开发人员.从服务端这个技术栈出发,问题的范围主要还是围绕开发语言(Java.Go)等核心知识点.数据库技术.缓存技 ...
- 用一条sql取得第10到第20条的记录-Mssql数据库
因为id可能不是连续的,所以不能用取得10<id<20的记录的方法. 有三种方法可以实现: 一.搜索前20条记录,指定不包括前10条 语句: select top 20 * from tb ...
- MySQL的一次优化记录 (IN子查询和索引优化)
这两天实习项目遇到一个网页加载巨慢的问题(10多秒),然后定位到是一个MySQL查询特别慢的语句引起的: SELECT * FROM ( SELECT DISTINCT t.vc_date, t.c_ ...
- MySQL数据库高级二:索引优化
索引优化非常的重要 1.预热 java开发 DBA培训很少,需要经验磨练 索引优化的效果非常好 左外连接 MySQL没有全连接 7种join一定要会写 具体见武林的例子 union的字段顺序要相同 6 ...
- MySql数据表设计,索引优化,SQL优化,其他数据库
MySql数据表设计,索引优化,SQL优化,其他数据库 1.数据表设计 1.1数据类型 1.2避免空值 1.3text类型优化 2.索引优化 2.1索引分类 2.2索引优化 3.SQL优化 3.1分批 ...
- Oracle数据库delete删除普通堆表千万条记录
Oracle数据库delete删除普通堆表千万条历史记录. 直接删除的影响: 1.可能由于undo表空间不足从而导致最终删除失败的问题: 2.可能导致undo表空间过度使用,影响到其他用户正常操作. ...
随机推荐
- C#学习笔记_12_枚举&结构体
12_枚举&结构体 枚举 是一种数据类型 适用于某些取值范围有限的数据 语法: [访问权限修饰符] enum 枚举名 { 枚举值 } 枚举名遵循大驼峰命名法 枚举一般情况下是和switch c ...
- STM32的USART发送数据时如何使用TXE和TC标志
在USART的发送端有2个寄存器,一个是程序可以看到的USART_DR寄存器,另一个是程序看不到的移位寄存器,对应USART数据发送有两个标志,一个是TXE=发送数据寄存器空,另一个是TC=发送结束. ...
- dubbo服务telnet命令的使用
转自:https://www.cnblogs.com/feiqihang/p/4387330.html dubbo服务发布之后,我们可以利用telnet命令进行调试.管理.Dubbo2.0.5以上版本 ...
- [LeetCode] 887. Super Egg Drop 超级鸡蛋掉落
You are given K eggs, and you have access to a building with N floors from 1 to N. Each egg is iden ...
- 大逃亡(escape.*)
给出数字N(1<=N<=10000),X(1<=x<=1000),Y(1<=Y<=1000),代表有N个敌人分布一个X行Y列的矩阵上,矩形的行号从0到X-1,列号从 ...
- c++ primer 第三章 标准库类型
1. string 标准库 1.1初始化 string s1; 默认构造函数s1为空 string s2(s1); 将s2初始化为s1的一个副本 string s3("value" ...
- 【ACM】poj_1579_Function Run Fun_201308121654
Function Run FunTime Limit: 1000MS Memory Limit: 10000K Total Submissions: 14940 Accepted: 7736 De ...
- systemtap dtrace与 oracle
https://fritshoogland.wordpress.com/page/3/ http://externaltable.blogspot.com/2013/06/dtrace-explora ...
- HDU 5293
树上DP题. 其实有点类似于01的问题.方程很容易想到.首先,因为一条链的节点其实都是在树上的,所以很容易想到应该先求一个LCA.然后,当某节点不是链的LCA时,它的转移就是: dp[i]=sum[i ...
- oracle强化练习之单行函数
1. 显示dname和loc中间用-分隔 Select dname ||'-'|| loc From dept; 2. 将部门名称左填充为10位 Select lpad( dnam ...