PHP爬虫技术(一)
摘要:本篇文章介绍PHP抓取网页内容技术,利用PHP cURL扩展获取网页内容,还可以抓取网页头部,设置cookie,处理302跳转。
一、cURL安装
采用源码安装PHP时,需要在configure时添加配置项,
cd php
./configure --with-curl
安装完毕,可以利用php -m命令查看,是否已经支持cURL扩展。
php -m | grep curl
也可以利用phpinfo查看,是否已经支持cURL扩展。

二、获取网页内容
cURL支持很多网络协议,如HTTP、HTTPS、FTP等。普通网页采用HTTP协议,一些安全性高的网页采用HTTPS(HTTPS协议采用数据加密技术,通过公钥技术交换密钥,加密传输内容。因此采用HTTPS协议的网页,在整个链路上传输的都是加密后的数据。例如Baidu采用HTTPS协议,你输入的关键字被网络传输协议加密,即使是运营商可以获得全部数据,也无法获得数据的内容。HTTPS协议也有缺点,就是加解密需要耗费计算时间,因此HTTPS网站会慢一些,而大多数网站都是采用HTTP协议)。HTTP协议中,定义了两种方法GET和POST。POST方法通常用于表单提交,能够提交文件等大数据。GET方法用来获取网页数据,也可以提交少量数据。本文主要介绍利用GET协议获取网页数据,将来再详细讲解cURL POST技术。
我们先看一些浏览器是怎么工作的,打开chrome浏览器,F12进入开发者模式,将工具栏切换到network,如下图,利用chrome工具可以查看每个文件的传输信息。
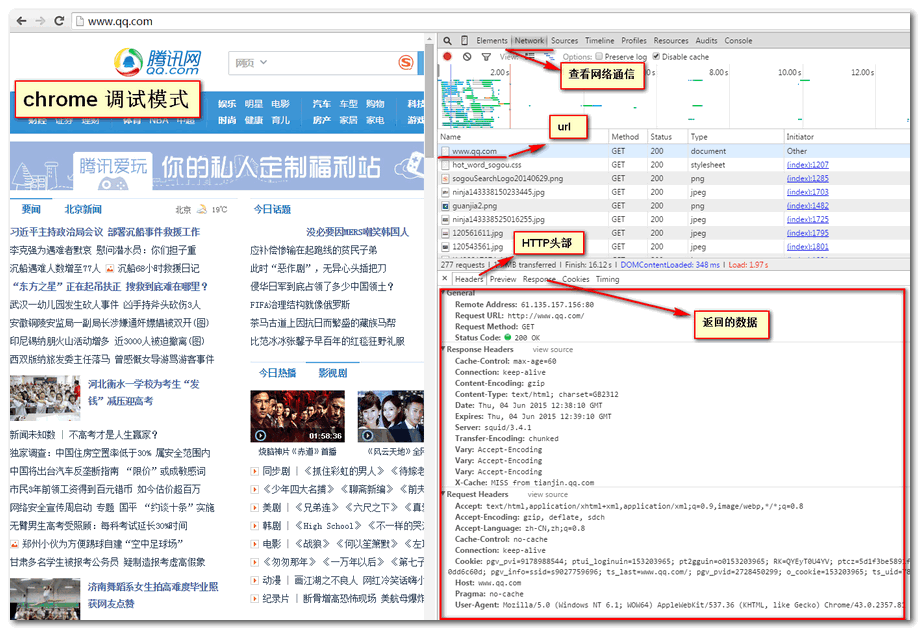
浏览器要加载一个网页,首先下载html文件,再下载js、css、图片等资源文件再进行渲染加载。通常数据抓取只需要抓取html文件,下图是chrome工具显示下载http文件的内容。

三、PHP实现
<?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "www.qq.com");
curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE);
$html = curl_exec($ch);
curl_close($ch);
var_dump($html);
?>
基本设置,返回网页内容。
四、获得HTTP头部设置cookie
有些网站,会采用cookie技术。当采集程序没带有相关cookie时,很容易被网站认定是“机器人”,拒绝对其服务。通过chrome调试www.sogou.com,发现cookie是包含在网页头信息中的。因此,我们需要两个步骤(1)HTTP头信息中获取cookie(2)发送请求时添加cookie。
头信息包含设置cookie,
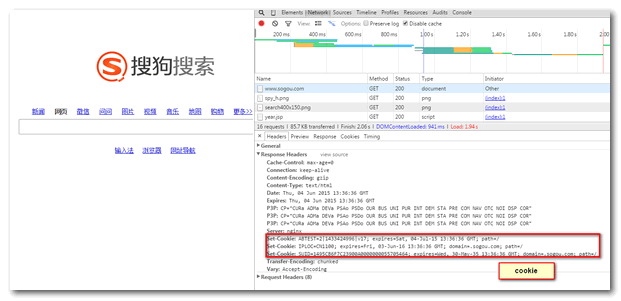
刷新网页,查看头信息,请求包含cookie信息
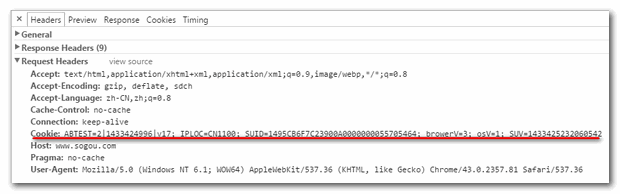
获取cookie
<?php
$url = "www.sogou.com";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_NOBODY, true);
curl_setopt($ch, CURLOPT_HEADERFUNCTION, function ($ch, $str) use(&$setcookie) {
// 第一个参数是curl资源,第二个参数是每一行独立的header!
list ($name, $value) = array_map('trim', explode(':', $str, 2));
$name = strtolower($name);
if('set-cookie'==$name)
{
$setcookie[]=$value;
}
return strlen($str);
});
curl_exec($ch);
curl_close($ch);
$cookie = array();
foreach($setcookie as $c)
{
$tmp = explode(";",$c);
$cookie[] = $tmp[0];
}
$cookiestr = "Cookie:".implode(";", $cookie);
echo $cookiestr;
?>
返回结果
Cookie:ABTEST=0|1433425917|v17;IPLOC=CN1100;SUID=3295CB6F1220920A00000000557057FD
设置cookie
<?php $url = "www.sogou.com"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, TRUE); $headers[] = $cookie; curl_setopt($ci, CURLOPT_HTTPHEADER, $headers); $html = curl_exec($ch); curl_close($ch); var_dump($html); ?>
五、抓取302跳转
在Baidu中搜索关键词,返回的结果链接是一个Baidu加密过的链接,通过二次跳转才是真正的网址。(Baidu为了防止360抓取,把结果都加密了)。
我们可以抓取头部中的location信息找到真实地址,
<?php
$url = "https://www.baidu.com/link?url=b34APzBjz-cGLoxsG4-nviHmtVS0tCvEftS6ApCAsojT1a0h9oFFPprwK4JpNYgGaQE29QPUtRdPUeu3lIz2M7GW7dqLMi5ytlHLOVa3v_VY23dOoRiUSyV9zr_cI8Rg&wd=&eqid=c89cf372000002cc0000000255705961&ie=utf-8";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_NOBODY, true);
curl_setopt($ch, CURLOPT_HEADERFUNCTION, function ($ch, $str) use(&$location) {
// 第一个参数是curl资源,第二个参数是每一行独立的header!
list ($name, $value) = array_map('trim', explode(':', $str, 2));
$name = strtolower($name);
if('location'==$name)
{
$location = $value;
return 0;
}
return strlen($str);
});
curl_exec($ch);
curl_close($ch);
echo $location;
?>
抓取302跳转还有另外一种方式,利用ob重定向流的方式,并且设置允许curl跳转到新地址。代码如下
<?php
function getContents($url){
$header = array("Referer: http://www.baidu.com/");
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_TIMEOUT, 30);
curl_setopt($ch, CURLOPT_HTTPHEADER,$header);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION,1); //能无法 抓取跳转后的页面
ob_start();
curl_exec($ch);
$contents = ob_get_contents();
ob_end_clean();
curl_close($ch);
return $contents;
}
$url = "https://www.baidu.com/link?url=b34APzBjz-cGLoxsG4-nviHmtVS0tCvEftS6ApCAsojT1a0h9oFFPprwK4JpNYgGaQE29QPUtRdPUeu3lIz2M7GW7dqLMi5ytlHLOVa3v_VY23dOoRiUSyV9zr_cI8Rg&wd=&eqid=c89cf372000002cc0000000255705961&ie=utf-8";
$contents = getContents($url);
echo $contents;
?>
PHP爬虫技术(一)的更多相关文章
- 总结整理 -- 爬虫技术(C#版)
爬虫技术学习总结 爬虫技术 -- 基础学习(一)HTML规范化(附特殊字符编码表) 爬虫技术 -- 基本学习(二)爬虫基本认知 爬虫技术 -- 基础学习(三)理解URL和URI的联系与区别 爬虫技术 ...
- 爬虫技术 -- 基础学习(四)HtmlParser基本认识
利用爬虫技术获取网页源代码后,针对网页抽取出它的特定文本内容,利用正则表达式和抽取工具,能够更好地抽取这些内容. 下面介绍一种抽取工具 -- HtmlParser HtmlParser是一个用来解析H ...
- 爬虫技术浅析 | WooYun知识库
爬虫技术浅析 | WooYun知识库 爬虫技术浅析 好房通ERP | 房产中介软件最高水准领导者 undefined
- 爬虫技术实战 | WooYun知识库
爬虫技术实战 | WooYun知识库 爬虫技术实战 大数据分析与机器学习领域Python兵器谱-大数据邦-微头条(wtoutiao.com) 大数据分析与机器学习领域Python兵器谱
- 爬虫技术浅析 | z7y Blog
爬虫技术浅析 | z7y Blog 爬虫技术浅析
- .net 爬虫技术
关于爬虫 从搜索引擎开始,爬虫应该就出现了,爬的对象当然也就是网页URL,在很长一段时间内,爬虫所做的事情就是分析URL.下载WebServer返回的HTML.分析HTML内容.构建HTTP请求的模拟 ...
- 使用webcollector爬虫技术获取网易云音乐全部歌曲
最近在知乎上看到一个话题,说使用爬虫技术获取网易云音乐上的歌曲,甚至还包括付费的歌曲,哥瞬间心动了,这年头,好听的流行音乐或者经典老歌都开始收费了,只能听不能下载,着实很郁闷,现在机会来了,于是开始研 ...
- 使用htmlparse爬虫技术爬取电影网页的全部下载链接
昨天,我们利用webcollector爬虫技术爬取了网易云音乐17万多首歌曲,而且还包括付费的在内,如果时间允许的话,可以获取更多的音乐下来,当然,也有小伙伴留言说这样会降低国人的知识产权保护意识,诚 ...
- 利用python的爬虫技术爬去糗事百科的段子
初次学习爬虫技术,在知乎上看了如何爬去糗事百科的段子,于是打算自己也做一个. 实现目标:1,爬取到糗事百科的段子 2,实现每次爬去一个段子,每按一次回车爬取到下一页 技术实现:基于python的实现, ...
- python简单爬虫技术
项目中遇到这个只是点,捣鼓了半天最后没用上,但是大概对爬虫技术有了些许了解 要先 比如: #抓取网页代码 import urllib2 import json url_data = urllib2.u ...
随机推荐
- 利用should.js进行测试
nodejs 环境 , 安装should.js包 (npm install should) var should = require('should'); //正确1, 错误0 100 precent ...
- shell中单引号和双引号
在shell中声明变量后直接使用: #!/bin/bash na=zhagnsan ag=11 echo '$na is $ag years old' 输出:$na is $ag years old ...
- ASP.NET ZERO 学习 JTable的ChildTable用法
效果图: Jtable的子表用法: _$masterTable.jtable({ title: app.localize('PharmacyInventory'), openChildAsAccord ...
- 关于jquery判断对象是否为空
1. jquery对象分为两种,一种是dom对象,dom对象会自带一个length属性,所以这种情况: obj.length == 0 可以判断对象为空 2. jquery也可以自定义对象,如 var ...
- nil、Nil、NULL和NSNull的区别和联系
一.nil 我们给对象赋值时一般会使用object = nil,表示我想把这个对象释放掉: 或者对象由于某种原因,经过多次release,于是对象引用计数器为0了,系统将这块内存释放掉,这个时候这个对 ...
- OA项目之导出
要导出页的前台: <asp:Button runat="server" ID="btnExport" Text="导出" CssCla ...
- dede channelartlist 中引用channel 并且设置当前选择类的样式,currentstyle暂时没有效果.特发求助!!!!
在dede中需要达到当前选择了该类,样式不同的话.如果是channelartlist 的话. 可以使用下面的情况: {dede:channelartlist typeid='6' row='3' cu ...
- ReferenceQueue的使用
转:http://www.iflym.com/index.php/java-programe/201407140001.html 1 何为ReferenceQueue 在java的引用体系中,存在着强 ...
- [vb.net]最简单的邮件发送
Imports Microsoft.Office.Interop.Outlook Private Sub sendMail() Dim outObj As New Application Dim it ...
- Android双向滑动菜单完全解析,教你如何一分钟实现双向滑动特效
转载请注明出处:http://blog.csdn.net/guolin_blog/article/details/9671609 记得在很早之前,我写了一篇关于Android滑动菜单的文章,其中有一个 ...