Tesseract-OCR引擎 入门
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布。当前版本为3.01.
项目地址为:http://code.google.com/p/tesseract-ocr
Windows 命令行使用Tesseract-OCR引擎识别验证码:
1、下载安装Tesseract-OCR引擎(3.0版本+才支持中文识别)
tesseract-ocr-setup-3.01-1.exe
下载完后进行安装,默认情况下安装程序会给你配置系统环境变量,以指向安装目录(之后可以通过DOS界面在任意目录运行tesseract)。安装完成后目录如下:
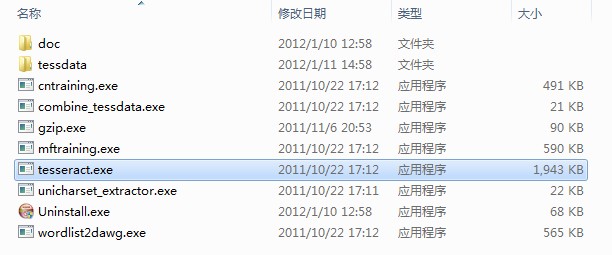
附录:
tessdata 目录存放的是语言字库文件,和在命令行界面中可能用到的参数所对应的文件. 这个安装程序默认包含了英文字库。
如果想能识别中文,可以到http://code.google.com/p/tesseract-ocr/downloads/list下载对应的语言的字库文件.
简体中文字库文件下载地址为:http://tesseract-ocr.googlecode.com/files/chi_sim.traineddata.gz 下载完成后解压,然后将该文件剪切到tessdata目录下去就可以了。
2、使用Tessract-OCR引擎识别验证码
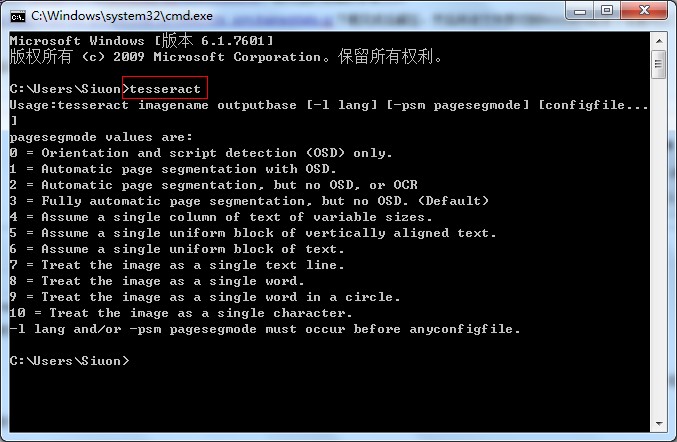
打开DOS界面,输入tesseract:
http://www.cnblogs.com/roucheng/p/csslogin.html
如果出现如上输出,表示安装正常。
我准备了一张验证码code.jpg放在D盘根目录下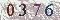 ,上图:
,上图:
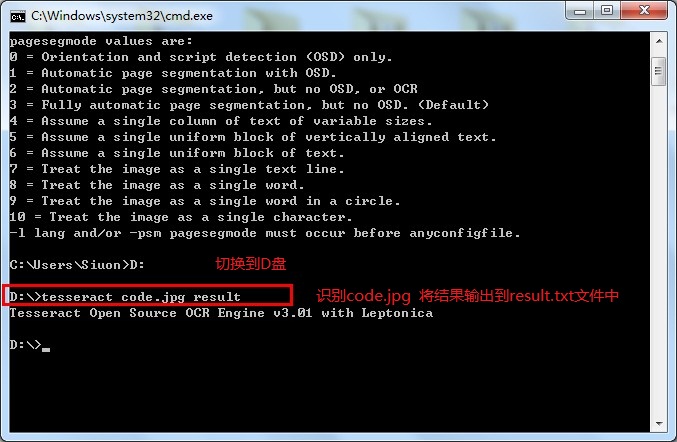
结果为:
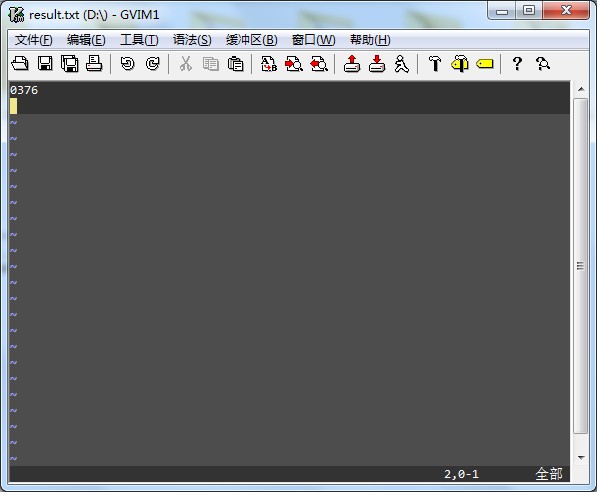
附录:
Usage:tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
pagesegmode values are:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
-l lang and/or -psm pagesegmode must occur before anyconfigfile.
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库(需要下载中文字库文件,解压后,存放到tessdata目录下去,字库文件扩展名为 .raineddata 简体中文字库文件名为: chi_sim.traineddata)
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
推荐:http://www.cnblogs.com/roucheng/p/winformtj.html
Tesseract-OCR引擎 入门的更多相关文章
- Tesseract——OCR图像识别 入门篇
Tesseract——OCR图像识别 入门篇 最近给了我一个任务,让我研究图像识别,从我们项目的screenshot中识别文字信息,so我开始了学习,与大家分享下. 我看到目前OCR技术有很多,最主要 ...
- Tesseract Ocr引擎
Tesseract Ocr引擎 1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/t ...
- Python下Tesseract Ocr引擎及安装介绍
1.Tesseract介绍 tesseract 是一个google支持的开源ocr项目,其项目地址:https://github.com/tesseract-ocr/tesseract,目前最新的源码 ...
- c/c++语言实现tesseract ocr引擎编程实例
编译下面的程序操作系统必须在安装了tesseract库和leptonica库才可以 Basic example c++ code: #include <tesseract/baseapi.h&g ...
- 开源图片文字识别引擎——Tesseract OCR
Tessseract为一款开源.免费的OCR引擎,能够支持中文十分难得.虽然其识别效果不是很理想,但是对于要求不高的中小型项目来说,已经足够用了. 文字识别可应用于许多领域,如阅读.翻译.文献资料的检 ...
- [转]Tesseract-OCR (Tesseract的OCR引擎最先由HP实验室于1985年开始研发)
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程.OCR技术非常专业,一般多是印刷.打印行 ...
- tesseract ocr文字识别Android实例程序和训练工具全部源代码
tesseract ocr是一个开源的文字识别引擎,Android系统中也可以使用.可以识别50多种语言,通过自己训练识别库的方式,可以大大提高识别的准确率. 为了节省大家的学习时间,现将自己近期的学 ...
- Tesseract ocr 3.02学习记录一
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程.OCR技术非常专业,一般多是印刷.打印行 ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- Tesseract OCR使用介绍
#Tesseract OCR使用介绍 ##目录[TOC] ##下载地址及介绍 官网介绍:http://code.google.com/p/tesseract-ocr/wiki/TrainingTess ...
随机推荐
- 关于Server Sql 2008触发器的使用
1.创建同一个服务器下同一个数据库实例两个不同数据库表同步方法 --==================================== -- Create database trigger -- ...
- ECSHOP始终显示全部分类方法
商品分类树需要始终显示所有类别,默认的Ecshop的显示方式为在当前产品页面只显示当前的产品所在的同级及下级分类,这就导致当点开某个产品或者子分 类的时候全局的分类树就不见了. 其实修改的方法很简单. ...
- Mac OS X Terminal 101:终端使用初级教程
Mac OS X Terminal 101:终端使用初级教程 发表于 2012 年 7 月 29 日 由 Renfei Song | 文章目录 1 为什么要使用命令行/如何开启命令行? 2 初识Com ...
- android studio ndk使用openMP
好久没碰ndk了,之前都是在eclipse下写makefile配置c++程序的,现在发现主流都是用android studio,eclipse俨然已经被遗弃了,正好最近项目需要用openMP做算法加速 ...
- 为什么要提倡“Design Pattern呢
为什么要提倡“Design Pattern呢?根本原因是为了代码复用,增加可维护性. 那么怎么才能实现代码复用呢?面向对象有几个原则:开闭原则(Open Closed Principle,OCP).里 ...
- python 字符串复制
通过变量来进行赋值 fstr = 'strcpy'sstr = fstrfstr = 'strcpy2'print sstr
- rm: 无法删除"/run/user/root/gvfs": 是一个目录 问题
2013-03-02 bxd@linux:~$ sudo su [sudo] password for bxd: root@linux:/home/bxd# exit exit rm: 无法删 ...
- [转]OOPC:Object-Oriented Programming in C
转载自:http://www.cnblogs.com/stli/archive/2010/10/16/1853190.html OOPC是指OOP(Object-Oriented Programmin ...
- Codeforces Perfect Pair (JAVA)
http://codeforces.com/problemset/problem/317/A 题意:给两个数字,可以两数相加去替换其中一个数字.问要做多少次,可以让两个数字钟至少一个 >= 目标 ...
- Ip 地址
访问 ip.mayfirst.org可以显示你的ip地址,如果你可以联网的话.