理解OVER子句
简介
Over子句在SQLServer 2005中回归,并且在2012中得到了扩展。这个功能主要结合窗口函数来使用;也可以在序列函数“NEXT VALUE FOR”使用。OVER子句确定哪些来自查询的列被应用到函数中,在函数中这些列被如何排序,并且何时重启函数计算。由于篇幅限制,本篇仅仅就OVER子句讨论,不再深入各种函数了(提供几个2014中新增的函数)。
语法:
<function> OVER ( [PARTITION BY clause]
[ORDER BY clause]
[ROWS or RANGE clause])
这个语法中,显示所有的子句都是可选的,实际上,每个函数使用OVER子句的函数都能确定哪个子句被允许哪个被需要。下图是展示那些函数是允许或者需要的:
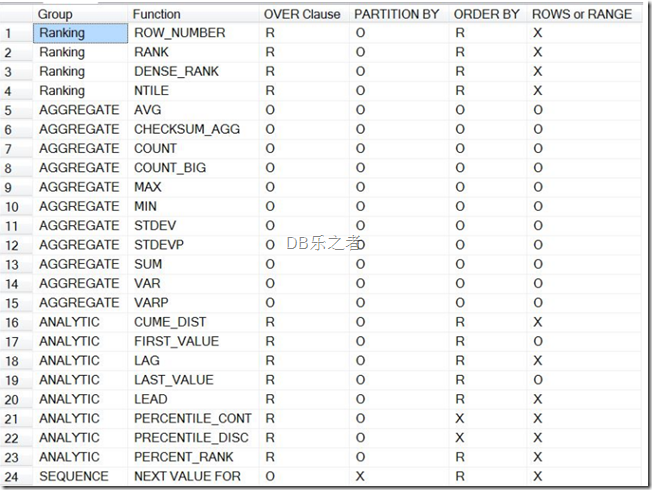
R-需要, O-可选, X-不允许
PARTITION BY子句用来区分查询结果集到数据子集中,或者分区。如果不使用PARTITION BY子句,整个来自查询的结果集都将被使用。窗口函数被应用到每个独立的分区数据,并且每个函数对于每个分区都是重新运算。通过定义一套确定分区的值来区分查询到子集,这些值可以使列,标量函数,子查询或者变量
举例如下:
SELECT COUNT(*)
FROM [msdb].sys.indexes;
查询结果如下:
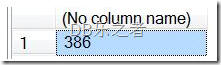
这种情况下查询仅仅返回一个数字,这就是msdb数据库的索引的数量。现在让我们加入OVER子句到这个查询中:
SELECT object_id, index_id, COUNT(*) OVER ()
FROM [msdb].sys.indexes;
结果集如下:
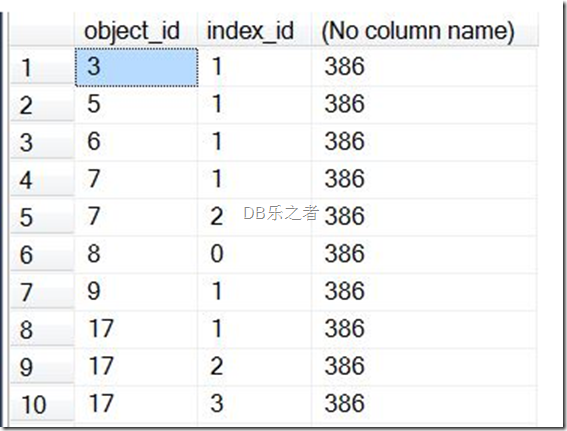
这个查询返回每个索引的对象ID和索引ID,并且还有结果集的索引总数。由于没使用PARTITION BY子句,整个结果集都被当做一个分区。
现在我们加入PARTITION BY子句来看看结果如何改变:
SELECT object_id, index_id, COUNT(*) OVER (PARTITION BY object_id)
FROM [msdb].sys.indexes;
返回结果如下:
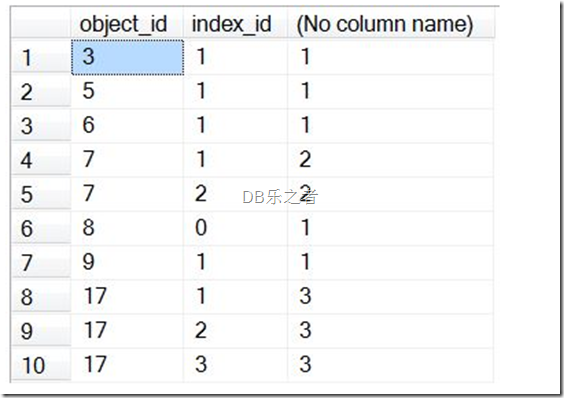
查询返回每个索引的行数,但是现在查询指定子句按照object_id 列来分区,因此count函数返回的是按object_id 分组的索引的数量。ORDER BY子句来控制排序。ROWS 或者 RANGE子句可以决定在分区内部的行数的子集。当使用ROWS 和 RANGE的时候,可以指定窗口函数的开始和结束点 ,如下图所示:

有两种语法指定窗口函数的范围:
BETWEEN <beginning frame> AND <ending frame>
<beginning frame>
如果只有“开始点”,默认结束点为CURRENT ROW。
UNBOUNDED 关键字指定分区开端或者结束。CURRENT ROW 指定当前行是否是窗口的开始或者结束,这取决于窗口使用的位置。上图中的“N”指定了之前当前列的或之后的行数。
下面是有效规范的窗口函数:
-- 从分区中指定整个结果集
BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING -- 指定五行,并且在当前行的前四行
BETWEEN 4 PRECEDING AND CURRENT ROW -- 指定当前行到分区结束的所有行
BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING -- 指定从分区开始到当前行的所有行 UNBOUNDED PRECEDING
为了展示以上说法,我们创建一些测试数据:两个账户,每个账户四个日期,以及四个金额。然后执行查询展示前面提到的语法的不同使用方式:
DECLARE @Test TABLE (
Account INTEGER,
TranDate DATE,
TranAmount NUMERIC(5,2));
INSERT INTO @Test (Account, TranDate, TranAmount)
VALUES (1, '2015-01-01', 50.00),
(1, '2015-01-15', 25.00),
(1, '2015-02-01', 50.00),
(1, '2015-02-15', 25.00),
(2, '2015-01-01', 50.00),
(2, '2015-01-15', 25.00),
(2, '2015-02-01', 50.00),
(2, '2015-02-15', 25.00); SELECT Account, TranDate, TranAmount,
COUNT(*) OVER (PARTITION BY Account
ORDER BY TranDate
ROWS UNBOUNDED PRECEDING) AS RowNbr,
COUNT(*) OVER (PARTITION BY TranDate) AS DateCount,
COUNT(*) OVER (PARTITION BY Account
ORDER BY TranDate
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS Last2Count
FROM @Test
ORDER BY Account, TranDate;
查询返回如下结果:
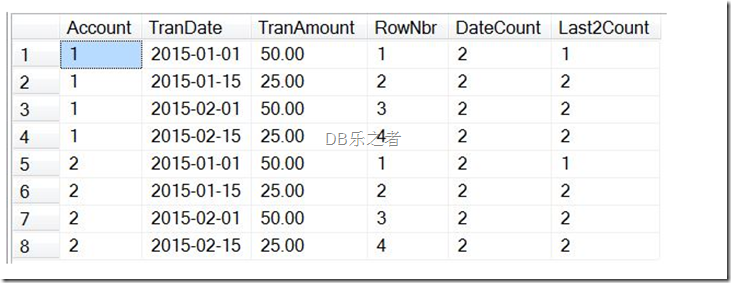
“RowNbr”列使用了count 函数返回分区后有多少行。这个分区是按照TranDate进行排序的,然后我们指定从分区的开始到当前行的窗口。对于第一行,‘2015-01-01’是第一行,座椅返回值就是1,然后第二行就是就是‘2015-01-15’,就是2,以此类推,其他这个账户的行往下排序。由于PARTITION BY 指定了Account 列,当Account 改变后这个函数被重置,于是可以看到Account 为2的时候RowNbr重新开始排序。
“DateCount”列根据“date”分组分区展示有多少个相同的date值。例子中每个交易的日期都有两个所以该列值都是2。与group by 相似,不同点是总的返回行数。尤其当计算当前行所占的总行数的百分比的时候应用比较多。
“Last2Count” 列表示在分区内对于当前行和其前面一行的行数。有点拗口,具体点就是对于每个Account 最小date的数据就是第一行,那么对于第一行距离第一行的计数就是1,其他行和都是计算它和它前面一行的数值都是2。比较常见的应用就是计算最近两个月销售的情况来计算奖金。
此时,我们已经展示了ROWS的子句。我们通过下面的例子可以快速理解两者的不同(注意4和5行以及12和13行是相同的值,此处产生不同):
SELECT FName,
Salary,
SumByRows = SUM(Salary) OVER (ORDER BY Salary
ROWS UNBOUNDED PRECEDING),
SumByRange = SUM(Salary) OVER (ORDER BY Salary
RANGE UNBOUNDED PRECEDING)
FROM (VALUES (1, 'George', 800),
(2, 'Sam', 950),
(3, 'Diane', 1100),
(4, 'Nicholas', 1250),
(5, 'Samuel', 1250),
(6, 'Patricia', 1300),
(7, 'Brian', 1500),
(8, 'Thomas', 1600),
(9, 'Fran', 2450),
(10,'Debbie', 2850),
(11,'Mark', 2975),
(12,'James', 3000),
(13,'Cynthia', 3000),
(14,'Christopher', 5000)
) dt(RowID, FName, Salary);
查询结果如下:
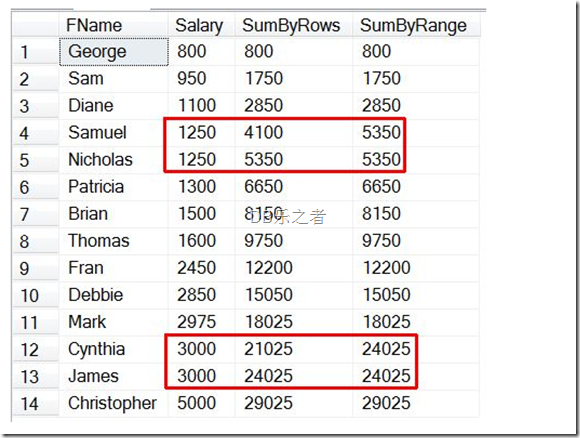
后两列的OVER子句除了ROWS/RANGE 的子句不同以外完全相同,注意,结束两个的结束点都没有指定,默认就是当前行。SumByRows 列通过计算第一行到当前行的所有行的值作为总数,而RANGE子句是计算到排序字段(SALARY)的值相同的列的所有值得总和。所以当有重复薪水值得时候就发现了两者的不同,如上所示。
重要提示:ORDER BY在OVER子句中只控制在窗口函数中使用分区行的顺序,而不控制最终结果集的顺序。如果需要制定结果集顺序,还要在查询后加上ORDER BY 语句。
下面介绍几种2014加入的新的窗口函数,以便我们使用,个人觉得很有帮助,性能非常不错。
1.LAG() and LEAD()
–向前或者向后N行
2.FIRST_VALUE() 与 LAST_VALUE()
–第一行或最后一行
3.PERCENT_RANK() 与 CUME_DIST()
–计算排序(统计分析常用)
4.PERCENTILE_DISC() 与 PERCENTILE_CONT()
–根据百分比取值(统计分析)
总结:
本篇主要介绍了OVER的用法,通过对比不同关键字的对比展示如何使用。在很多缺少排序和分区分组的条件下,能够简化t-sql语句提高语句效率。希望对大家的使用有帮助。
理解OVER子句的更多相关文章
- where 子句和having子句中的区别
1.where 不能放在GROUP BY 后面 2.HAVING 是跟GROUP BY 连在一起用的,放在GROUP BY 后面,此时的作用相当于WHERE 3.WHERE 后面的条件中不能有聚集函数 ...
- oracle中where 子句和having子句中的区别
1.where 不能放在GROUP BY 后面 2.HAVING 是跟GROUP BY 连在一起用的,放在GROUP BY 后面,此时的作用相当于WHERE 3.WHERE 后面的条件中不能有聚集函数 ...
- 在oracle中where 子句和having子句中的区别
在oracle中where 子句和having子句中的区别 1.where 不能放在GROUP BY 后面 2.HAVING 是跟GROUP BY 连在一起用的,放在GROUP BY 后面,此时的作用 ...
- LINQ简记(3):子句
LINQ查询表达式的子句如select,where,from等都是比较简单的子句,相信各位多练习练习,再结合MSDN的例子,基本上是可以理解的,因此,本文只挑几个有代表性的,以及有些难理解的子句来简述 ...
- 小贝_mysql select5种子句介绍
mysql select5种子句介绍 简要 一.五种字句 二.具体解释五种字句 一.五种字句 where.group by.having.order by.limit 二.具体解释五种字句 2.1.理 ...
- oracle中where子句和having子句中的区别
1.where 不能放在GROUP BY 后面2.HAVING 是跟GROUP BY 连在一起用的,放在GROUP BY 后面,此时的作用相当于WHERE3.WHERE 后面的条件中不能有聚集函数 ...
- where子句和having子句区别
感谢大佬:https://blog.csdn.net/XiaopinOo/article/details/78305008 where子句和having子句的区别: 1.where 不能放在grou ...
- MySQL知识树-查询语句
在日常的web应用开发过程中,一般会涉及到数据库方面的操作,其中查询又是占绝大部分的.我们不仅要会写查询,最好能系统的学习下与查询相关的知识点,这篇随笔我们就来一起看看MySQL查询知识相关的树是什么 ...
- T-SQL基础--TOP
理解TOP子句 众所周知,TOP子句可以通过控制返回行的数量来影响查询. 我们知道TOP子句能很容易的满足返回指定行数的子集,接下来有一些例子来展示什么情况下使用TOP子句来返回一个结果集: 你打算返 ...
随机推荐
- Atitit. 提升存储过程与编程语言的可读性解决方案v3 qc25.docx
Atitit. 提升存储过程与编程语言的可读性解决方案v3 qc25.docx 1. 大原则:分解+命名1 1.1. 命名规范1 1.2. 分层.DI和AOP是继OO1 1.3. 运算符可读性一般要比 ...
- PHP_VERSION_ID是如何定义的
PHP_VERSION_ID是一个整数,表示当前PHP的版本,从php5.2.7版本开始使用的,比如50207表示5.2.7.和PHP版本相关的宏定义在文件 phpsrcdir/main/php_ve ...
- Android开发-之监听button点击事件
一.实现button点击事件的方法 实现button点击事件的监听方法有很多种,这里总结了常用的四种方法: 1.匿名内部类 2.外部类(独立类) 3.实现OnClickListener接口 4.添加X ...
- 【.NET深呼吸】基于异步上下文的本地变量(AsyncLocal)
在开始吹牛之前,老周说两个故事. 第一个故事是关于最近某些别有用心的人攻击.net的事,其实我们不用管它们,只要咱们知道自己是.net爱好者就行了,咱们就是因为热爱.net才会选择它.这些人在这段时间 ...
- ES6之module
该博客原文地址:http://www.cnblogs.com/giggle/p/5572118.html 一.module概述 JavaScript一直没有模块体系,但是伴随着ES6的到来,modul ...
- linux mount/umount挂载命令解析。
如果想在运行的Linux下访问其它文件系统中的资源的话,就要用mount命令来实现. 2. mount的基本用法是?格式:mount [-参数] [设备名称] [挂载点] 其中常用的参数有: ...
- 利用Python进行数据分析(3) 使用IPython提高开发效率
一.IPython 简介 IPython 是一个交互式的 Python 解释器,而且它更加高效. 它和大多传统工作模式(编辑 -> 编译 -> 运行)不同的是, 它采用的工作模式是:执 ...
- Redis简单案例(四) Session的管理
负载均衡,这应该是一个永恒的话题,也是一个十分重要的话题.毕竟当网站成长到一定程度,访问量自然也是会跟着增长,这个时候, 一般都会对其进行负载均衡等相应的调整.现如今最常见的应该就是使用Nginx来进 ...
- HTML5学习笔记之History API
这系列文章主要是学习Html5相关的知识点,以学习API知识点为入口,由浅入深的引入实例,让大家一步一步的体会"h5"能够做什么,以及在实际项目中如何去合理的运用达到使用自如,完美 ...
- Eclipse Meaven Spring SpringMVC Mybaits整合
本示例是在:Ubuntu15上实现的:Windows上安装Maven将不太相同. Maven Install Run command sudo apt-get install maven, to in ...