51、Spark Streaming之输入DStream和Receiver详解
输入DStream代表了来自数据源的输入数据流。在之前的wordcount例子中,lines就是一个输入DStream(JavaReceiverInputDStream),
代表了从netcat(nc)服务接收到的数据流。除了文件数据流之外,所有的输入DStream都会绑定一个Receiver对象,该对象是一个关键的组件,
用来从数据源接收数据,并将其存储在Spark的内存中,以供后续处理。 Spark Streaming提供了两种内置的数据源支持:
1、基础数据源:StreamingContext API中直接提供了对这些数据源的支持,比如文件、socket、Akka Actor等。
2、高级数据源:诸如Kafka、Flume、Kinesis、Twitter等数据源,通过第三方工具类提供支持。这些数据源的使用,需要引用其依赖。
3、自定义数据源:我们可以自己定义数据源,来决定如何接受和存储数据。 要注意的是,如果你想要在实时计算应用中并行接收多条数据流,可以创建多个输入DStream。这样就会创建多个Receiver,从而并行地接收多个数据流。
但是要注意的是,一个Spark Streaming Application的Executor,是一个长时间运行的任务,因此,它会独占分配给Spark Streaming Application的cpu core。
所以只要Spark Streaming运行起来以后,这个节点上的cpu core,就没法给其他应用使用了。 使用本地模式,运行程序时,绝对不能用local或者local[1],因为那样的话,只会给执行输入DStream的executor分配一个线程。而Spark Streaming底层的
原理是,至少要有两条线程,一条线程用来分配给Receiver接收数据,一条线程用来处理接收到的数据。因此必须使用local[n],n>=2的模式。 如果不设置Master,也就是直接将Spark Streaming应用提交到集群上运行,那么首先,必须要求集群节点上,有>1个cpu core,其次,给Spark Streaming的
每个executor分配的core,必须>1,这样,才能保证分配到executor上运行的输入DStream,两条线程并行,一条运行Receiver,接收数据;一条处理数据。
否则的话,只会接收数据,不会处理数据。 企业工作中,机器肯定是不只一个cpu core,这个问题应该不大。
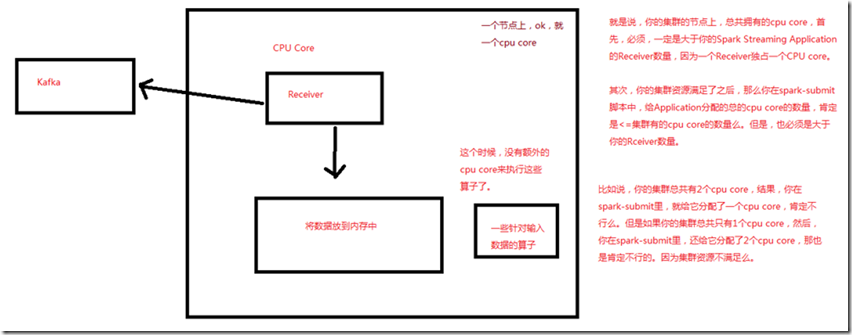
所以说,集群的节点上,总共拥有的cpu core,首先,必须是大于Spark Streaming Application的Receiver数量,因为一个Receiver独占一个CPU core; 其次,在spark-submit脚本中,给Application分配的总的cpu core,肯定小于等于集群的cpu core的数量,大于Receiver的数量;
51、Spark Streaming之输入DStream和Receiver详解的更多相关文章
- 输入DStream和Receiver详解
输入DStream代表了来自数据源的输入数据流.在之前的wordcount例子中,lines就是一个输入DStream(JavaReceiverInputDStream),代表了从netcat(nc) ...
- StreamingContext详解,输入DStream和Reveiver详解
StreamingContext详解,输入DStream和Reveiver详解 一.StreamingContext详解 1.1两种创建StreamingContext的方式 1.2SteamingC ...
- 52、Spark Streaming之输入DStream之基础数据源以及基于HDFS的实时wordcount程序
一.概述 1.Socket:之前的wordcount例子,已经演示过了,StreamingContext.socketTextStream() 2.HDFS文件 基于HDFS文件的实时计算,其实就是, ...
- Spark Streaming初步使用以及工作原理详解
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着电商企业的发展,hadoop只适用于一些离线数据的处理,无法应对一些实时数据的处理分析,我们需要一些实时计算框架来分析数据.因此出现了很多 ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
本期内容 : Receiver启动的方式设想 Receiver启动源码彻底分析 多个输入源输入启动,Receiver启动失败,只要我们的集群存在就希望Receiver启动成功,运行过程中基于每个Tea ...
- Spark Streaming之三:DStream解析
DStream 1.1基本说明 1.1.1 Duration Spark Streaming的时间类型,单位是毫秒: 生成方式如下: 1)new Duration(milli seconds) 输入毫 ...
- Spark RDD、DataFrame原理及操作详解
RDD是什么? RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用. RDD内部可以 ...
- 输入一个url全过程详解
1. 用户在浏览器中输入url,浏览器接收到url. 2.浏览器接收到这个url之后,会根据这个url会先查看缓存,如果有缓存且没有过期的话直接提供给客户端,完成页面渲染. 3.否则浏览器就会通过DN ...
随机推荐
- Java调用Http/Https接口(2)--HttpURLConnection/HttpsURLConnection调用Http/Https接口
HttpURLConnection是JDK自身提供的网络类,不需要引入额外的jar包.文中所使用到的软件版本:Java 1.8.0_191. 1.服务端 参见Java调用Http接口(1)--编写服务 ...
- Python进阶----异常处理
Python进阶----异常处理 一丶错误和异常 错误: 语法错误(这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正) #语法错误示范一 if #语法错误示范二 ...
- MySQL-By孙胜利-sifangku.com
一.数据库基本概念 数据库:信息存储的仓库,包括一系列的关系措施! 表:一个数据库中可以有若干张表(形式上你可以看出我们日常生活中建立的表) 字段:表里面的信息会分若干个栏目来存,这些栏目呢,我们在数 ...
- Android 下拉列表Spinner 使用
1.布局文件 <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:t ...
- 如何自行给指定的SAP OData服务添加自定义日志记录功能
有的时候,SAP标准的OData实现或者相关的工具没有提供我们想记录的日志功能,此时可以利用SAP系统强大的扩展特性,进行自定义日志功能的二次开发. 以SAP CRM Fiori应用"My ...
- 基于GDI显示png图像
intro 先前基于GDI已经能够显示BITMAP图像:windows下控制台程序实现窗口显示 ,其中BMP图像是使用LoadImage()这一Win32 API函数来做的.考虑到LoadImage( ...
- IPC机制和生产者消费者模型
IPC机制:(解决进程间的数据隔离问题) 进程间通信:IPC(inter-Process Comminication) 创建共享的进程列队,Queue 是多进程的安全列队,可以使用Queue 实现多进 ...
- jquery 子元素 后代元素 兄弟元素 相邻元素
<!DOCTYPE html> <html> <head> <meta http-equiv="Content-type" content ...
- 基于Docker容器使用NVIDIA-GPU训练神经网络
一,nvidia K80驱动安装 1, 查看服务器上的Nvidia(英伟达)显卡信息,命令lspci |grep NVIDIA 05:00.0 3D controller: NVIDIA Corpo ...
- 通过iptables限制docker容器端口
如何限制docker暴露的对外访问端口 docker 会在iptables上加上自己的转发规则,如果直接在input链上限制端口是没有效果的.这就需要限制docker的转发链上的DOCKER表. # ...