51、Spark Streaming之输入DStream和Receiver详解
输入DStream代表了来自数据源的输入数据流。在之前的wordcount例子中,lines就是一个输入DStream(JavaReceiverInputDStream),
代表了从netcat(nc)服务接收到的数据流。除了文件数据流之外,所有的输入DStream都会绑定一个Receiver对象,该对象是一个关键的组件,
用来从数据源接收数据,并将其存储在Spark的内存中,以供后续处理。 Spark Streaming提供了两种内置的数据源支持:
1、基础数据源:StreamingContext API中直接提供了对这些数据源的支持,比如文件、socket、Akka Actor等。
2、高级数据源:诸如Kafka、Flume、Kinesis、Twitter等数据源,通过第三方工具类提供支持。这些数据源的使用,需要引用其依赖。
3、自定义数据源:我们可以自己定义数据源,来决定如何接受和存储数据。 要注意的是,如果你想要在实时计算应用中并行接收多条数据流,可以创建多个输入DStream。这样就会创建多个Receiver,从而并行地接收多个数据流。
但是要注意的是,一个Spark Streaming Application的Executor,是一个长时间运行的任务,因此,它会独占分配给Spark Streaming Application的cpu core。
所以只要Spark Streaming运行起来以后,这个节点上的cpu core,就没法给其他应用使用了。 使用本地模式,运行程序时,绝对不能用local或者local[1],因为那样的话,只会给执行输入DStream的executor分配一个线程。而Spark Streaming底层的
原理是,至少要有两条线程,一条线程用来分配给Receiver接收数据,一条线程用来处理接收到的数据。因此必须使用local[n],n>=2的模式。 如果不设置Master,也就是直接将Spark Streaming应用提交到集群上运行,那么首先,必须要求集群节点上,有>1个cpu core,其次,给Spark Streaming的
每个executor分配的core,必须>1,这样,才能保证分配到executor上运行的输入DStream,两条线程并行,一条运行Receiver,接收数据;一条处理数据。
否则的话,只会接收数据,不会处理数据。 企业工作中,机器肯定是不只一个cpu core,这个问题应该不大。
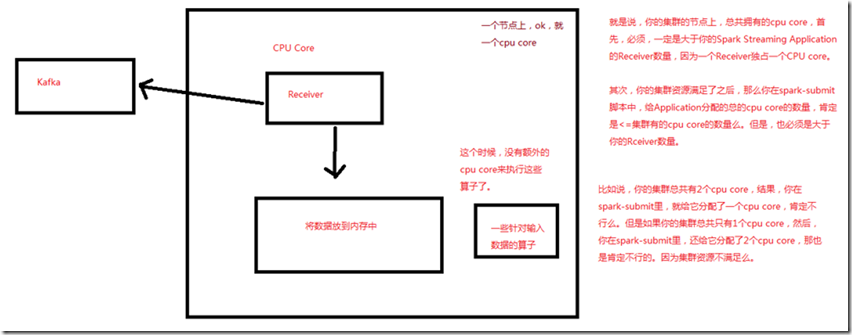
所以说,集群的节点上,总共拥有的cpu core,首先,必须是大于Spark Streaming Application的Receiver数量,因为一个Receiver独占一个CPU core; 其次,在spark-submit脚本中,给Application分配的总的cpu core,肯定小于等于集群的cpu core的数量,大于Receiver的数量;
51、Spark Streaming之输入DStream和Receiver详解的更多相关文章
- 输入DStream和Receiver详解
输入DStream代表了来自数据源的输入数据流.在之前的wordcount例子中,lines就是一个输入DStream(JavaReceiverInputDStream),代表了从netcat(nc) ...
- StreamingContext详解,输入DStream和Reveiver详解
StreamingContext详解,输入DStream和Reveiver详解 一.StreamingContext详解 1.1两种创建StreamingContext的方式 1.2SteamingC ...
- 52、Spark Streaming之输入DStream之基础数据源以及基于HDFS的实时wordcount程序
一.概述 1.Socket:之前的wordcount例子,已经演示过了,StreamingContext.socketTextStream() 2.HDFS文件 基于HDFS文件的实时计算,其实就是, ...
- Spark Streaming初步使用以及工作原理详解
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着电商企业的发展,hadoop只适用于一些离线数据的处理,无法应对一些实时数据的处理分析,我们需要一些实时计算框架来分析数据.因此出现了很多 ...
- 64、Spark Streaming:StreamingContext初始化与Receiver启动原理剖析与源码分析
一.StreamingContext源码分析 ###入口 org.apache.spark.streaming/StreamingContext.scala /** * 在创建和完成StreamCon ...
- Spark Streaming源码解读之Receiver生成全生命周期彻底研究和思考
本期内容 : Receiver启动的方式设想 Receiver启动源码彻底分析 多个输入源输入启动,Receiver启动失败,只要我们的集群存在就希望Receiver启动成功,运行过程中基于每个Tea ...
- Spark Streaming之三:DStream解析
DStream 1.1基本说明 1.1.1 Duration Spark Streaming的时间类型,单位是毫秒: 生成方式如下: 1)new Duration(milli seconds) 输入毫 ...
- Spark RDD、DataFrame原理及操作详解
RDD是什么? RDD (resilientdistributed dataset),指的是一个只读的,可分区的分布式数据集,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用. RDD内部可以 ...
- 输入一个url全过程详解
1. 用户在浏览器中输入url,浏览器接收到url. 2.浏览器接收到这个url之后,会根据这个url会先查看缓存,如果有缓存且没有过期的话直接提供给客户端,完成页面渲染. 3.否则浏览器就会通过DN ...
随机推荐
- centos8安装chromium浏览器
1/yum install epel* [root@localhost framework]# yum list epl* Last metadata expiration check: 0:57:4 ...
- angular http interceptors 拦截器使用分享
拦截器 在开始创建拦截器之前,一定要了解 $q和延期承诺api 出于全局错误处理,身份验证或请求的任何同步或异步预处理或响应的后处理目的,希望能够在将请求移交给服务器之前拦截请求,并在将请求移交给服务 ...
- JavaScript之控制标签css
控制标签css标签.style.样式='样式具体的值'如果样式出现中横线,如border-radius,将中横线去掉,中横线后面的单词首字母大写,写成borderRadius如果原来就要该样式,表示修 ...
- weblogic unable to get file lock问题
非正常结束weblogic进程导致weblogic无法启动 由于先前服务器直接down掉了,所有进程都非正常的进行关闭了,也就导致了下次启动weblogic的时候报了以下错误: <2012-3- ...
- 京信通信成功打造自动化工厂(MES应用案例)
企业介绍: 京信通信成立于1997年,是一家集研发.生产.销售及服务于一体的移动通信外围设备专业厂商,致力于为客户提供无线覆盖和传输的整体解决方案,于2003年在香港联交所主板上市(2342.HK), ...
- Git版本管理工具使用
1.Git简介 Git(读音为/gɪt/.)是一个开源的分布式版本控制系统,可以有效.高速地处理从很小到非常大的项目版本管理. Git 是 Linus Torvalds 为了帮助管理 Linux 内核 ...
- es截取指定的字段返回
SearchResponse response = client.prepareSearch(index_name).setTypes("lw_devices") .setFrom ...
- 图记 2016.1.7 获取本地图片、Bitmap转image
这几天完成的内容有: 1.“添加图片”按钮 2.添加图片功能 遇到的问题: 我想要将添加图片按钮放在右下角,所以采用了相对布局,但是问题随之二来,因为将导航栏设置成了半透明,所以图片放到右下角之后,半 ...
- Python入门篇-类型注解
Python入门篇-类型注解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.函数定义的弊端 1>.动态语言很灵活,但是这种特性也是弊端 Python是动态语言,变量随时可 ...
- TPA测试项目管理系统-测试用例管理
Test Project Administrator(简称TPA)是经纬恒润自主研发的一款专业的测试项目管理工具,目前已广泛的应用于国内二十余个整车厂和零部件供应商.它可以管理测试过程 ...