kafka为什么吞吐量高,怎样保证高可用
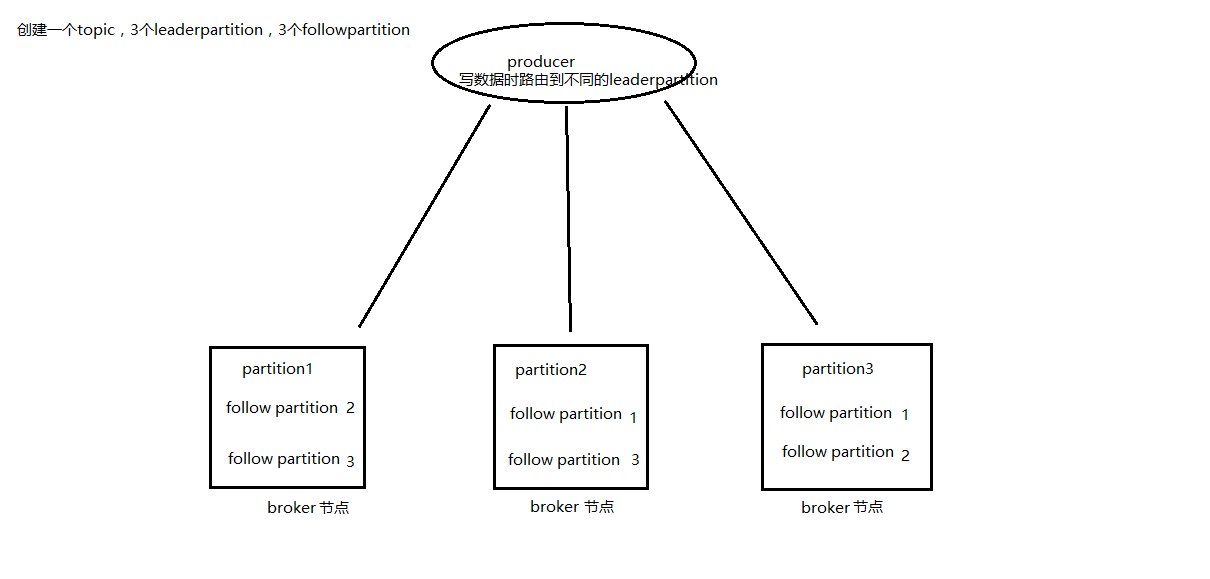
1:kafka可以通过多个broker形成集群,来存储大量数据;而且便于横向扩展。
2:kafka信息存储核心的broker,通过partition的segment只关心信息的存储,而生产者只负责向leader角色的partition提交数据,而消费者pull数据的时候自己通过zk存储offset信息,严格讲broker基本只关心存储数据;
3:kafka的ack策略也是提高吞吐量的手段:
1)生产者的acks如果设置0则只向leader发送数据,并不关心leader数据是否存储成功;
2)如果设置为1在向leader发送数据后需要等待leader存储成功后才会认为一次操作成功;
3)如果设置为-1在向leader发送数据后不但需要等待leader存储成功,还要等待各个follow角色的partition,从leader拉取数据后存储完成才算一次完整的ack,当然这种情况会降低kafka的吞吐量;
而且follow从leader拉去后存储完成才能将本地的(segmentLog)LEO标记移动到最后,如果follow未同步完成kafka为了保证数据一致性“HW高水位线”也只能保证到一个较低水平;
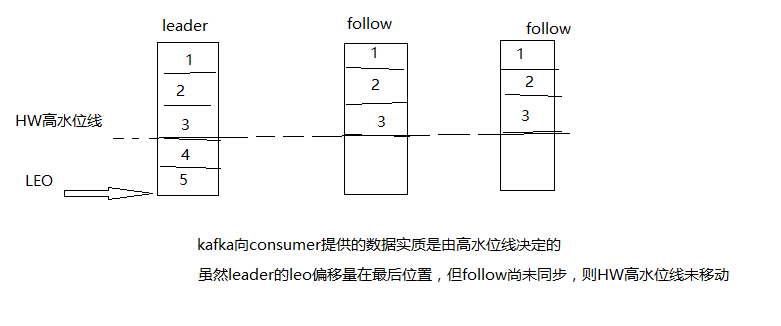
高可用:
ps:而且kafka底层是通过NIO顺序写数据,效率也是非常高的
kafka为什么吞吐量高,怎样保证高可用的更多相关文章
- redis高可用,保证高并发
目录 redis如何通过读写分离来承载读请求QPS超过10万+ redis replication以及master持久化对主从架构的安全意义 redis主从复制原理.断点续传.无磁盘化复制.过期key ...
- 5.如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍一下么?redis 的哨兵原理能介绍一下么?
作者:中华石杉 面试题 如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍一下么?redis 的哨兵原理能介绍一下么? 面试官心理分析 其实问这个问题,主要是考考你,redis ...
- 面试系列15 如何保证Redis的高并发和高可用
就是如果你用redis缓存技术的话,肯定要考虑如何用redis来加多台机器,保证redis是高并发的,还有就是如何让Redis保证自己不是挂掉以后就直接死掉了,redis高可用 我这里会选用我之前讲解 ...
- 【Distributed】大型网站高并发和高可用
一.DNS域名解析 二.大型网站系统应有的特点 三.网站架构演变过程 3.1 传统架构 3.2 分布式架构 3.3 SOA架构 3.4 微服务架构 四.高并发设计原则 4.1 拆分系统 4.2 服务化 ...
- java亿级流量电商详情页系统的大型高并发与高可用缓存架构实战视频教程
亿级流量电商详情页系统的大型高并发与高可用缓存架构实战 完整高清含源码,需要课程的联系QQ:2608609000 1[免费观看]课程介绍以及高并发高可用复杂系统中的缓存架构有哪些东西2[免费观看]基于 ...
- 5. 支撑高并发,高可用,海量数据备份恢复的Redis重要性
商品详情页的架构实现 缓存架构 第一块儿,要掌握的很好的,就是redis架构 高并发,高可用,海量数据,备份,随时可以恢复,缓存架构如果要支撑这些要点,首先呢,redis就得支撑 redis架构,每秒 ...
- Spark Streaming高吞吐、高可靠的一些优化
分享一些Spark Streaming在使用中关于高吞吐和高可靠的优化. 目录 1. 高吞吐的优化方式 1.1 更改序列化的方式 1.2 修改Receiver接受到的数据的存储级别 1.3 广播配置变 ...
- [ 高并发]Java高并发编程系列第二篇--线程同步
高并发,听起来高大上的一个词汇,在身处于互联网潮的社会大趋势下,高并发赋予了更多的传奇色彩.首先,我们可以看到很多招聘中,会提到有高并发项目者优先.高并发,意味着,你的前雇主,有很大的业务层面的需求, ...
- 斯坦福大学公开课机器学习: machine learning system design | error analysis(误差分析:检验算法是否有高偏差和高方差)
误差分析可以更系统地做出决定.如果你准备研究机器学习的东西或者构造机器学习应用程序,最好的实践方法不是建立一个非常复杂的系统.拥有多么复杂的变量,而是构建一个简单的算法.这样你可以很快地实现它.研究机 ...
随机推荐
- shell history 命令
1.history命令可以显示历史执行过的命令: 2.使用!+序号执行该序号对应的命令: 例子 $ history sed 's/haha/hello/g' test cat test cat tes ...
- 记一次vue+vuex+vue-router+axios+elementUI开发(一)
记录自己的vue开发之旅,方便之后查询 一.开发环境 1.安装node.js 自带npm https://nodejs.org/en/ 2. 全局安装vue-cli脚手架 npm install v ...
- python3 之metaclass
如果希望创建某一批类全部具有某种特征,则可通过 metaclass 来实现.使用 metaclass 可以在创建类时动态修改类定义. 为了使用 metaclass 动态修改类定义,程序需要先定义 me ...
- 常用app分类
西瓜视频 今日头条(极速版) 喜马拉雅 扫描全能王 蜻蜓FM 每天影视 抖音 小读 樊登读书 微信读书 懒人听书 京东 找靓机 拼多多 淘宝 小米有品 当当 什么值得买 小米商城 淘票票 懂车帝 小红 ...
- php手记之07-tp5 cookie与session
ThinkPHP采用 01-think\facade\Cookie类提供Cookie支持. 02-think\Cookie 配置文件位于 config/cookie.php中,一般会配置一个超时时间. ...
- 范仁义html+css课程---1、html基本结构
范仁义html+css课程---1.html基本结构 一.总结 一句话总结: html标签中包含head标签和body标签,head标签里面主要写用户不可见的内容,比如字符集编码,body标签里面主要 ...
- ssh端口映射总结
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/boliang319/article/det ...
- 两个Double类型相减出现精度丢失问题
两个Double类型相减出现精度丢失问题 720.50-279.5=440.099999999 而不是440.1 解决方法,将数据库中的类型改为decimal类型,小数精确到2位
- 部署gerrit环境完整记录【转】
开发同事提议在线上部署一套gerrit代码审核环境,废话不多说,部署gerrit的操作记录如下:提前安装好java环境,mysql环境,nginx环境测试系统:centos6.5下载下面三个包,放到/ ...
- 修改layui的表单手机、邮箱验证可以为空怎么实现?
修改layui的表单手机.邮箱验证可以为空 解决办法: 修改源码: 把表单验证源代码(form.js)的正则表达式改一下,例如手机的正则为:/^1d{10}$/,可以改成/^$|^1d{10} ...