第五周周二练习:实验 5 Spark SQL 编程初级实践
1.题目:
 源码:
源码:
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrameReader
object TestMySQL {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("RddToDFrame").master("local").getOrCreate()
import spark.implicits._
val employeeRDD = spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" "))
val schema = StructType(List(StructField("id", IntegerType,true),StructField("name", StringType, true),StructField("gender", StringType,true),StructField("age", IntegerType, true)))
val rowRDD = employeeRDD.map(p => Row(p().toInt,p().trim,p().trim,p().toInt))
val employeeDF = spark.createDataFrame(rowRDD, schema)
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "hadoop")
prop.put("driver","com.mysql.jdbc.Driver")
employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest","sparktest.employee", prop)
val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee").option("user","root").option("password", "hadoop").load()
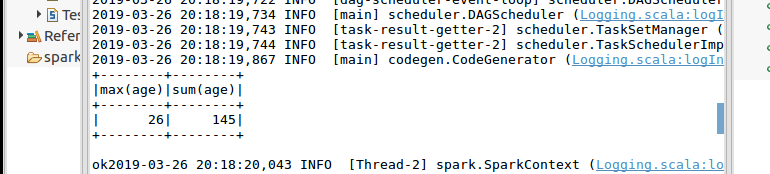
jdbcDF.agg("age" -> "max", "age" -> "sum").show()
print("ok")
}
}
数据库数据: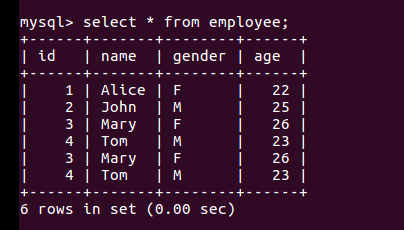
结果:
2.编程实现将 RDD 转换为 DataFrame

官网给出两种方法,这里给出一种(使用编程接口,构造一个 schema 并将其应用在已知的 RDD 上。):
源码:
import org.apache.spark.sql.types._
import org.apache.spark.sql.Encoder
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object RDDtoDF {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("RddToDFrame").master("local").getOrCreate()
import spark.implicits._
val employeeRDD =spark.sparkContext.textFile("file:///usr/local/spark/employee.txt")
val schemaString = "id name age"
val fields = schemaString.split(" ").map(fieldName => StructField(fieldName,
StringType, nullable = true))
val schema = StructType(fields)
val rowRDD = employeeRDD.map(_.split(",")).map(attributes =>
Row(attributes().trim, attributes(), attributes().trim))
val employeeDF = spark.createDataFrame(rowRDD, schema)
employeeDF.createOrReplaceTempView("employee")
val results = spark.sql("SELECT id,name,age FROM employee")
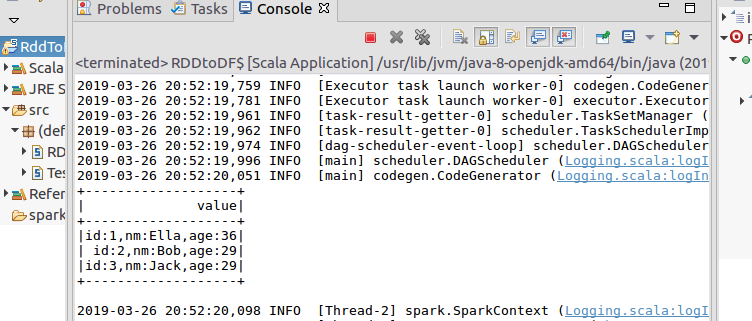
results.map(t => "id:"+t()+","+"name:"+t()+","+"age:"+t()).show()
}
}
结果:
第五周周二练习:实验 5 Spark SQL 编程初级实践的更多相关文章
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
- 实验5 Spark SQL 编程初级实践
源文件内容如下(包含 id,name,age),将数据复制保存到 ubuntu 系统/usr/local/spark 下, 命名为 employee.txt,实现从 RDD 转换得到 DataFram ...
- spark实验(五)--Spark SQL 编程初级实践(1)
一.实验目的 (1)通过实验掌握 Spark SQL 的基本编程方法: (2)熟悉 RDD 到 DataFrame 的转化方法: (3)熟悉利用 Spark SQL 管理来自不同数据源的数据. 二.实 ...
- Spark SQL 编程初级实践
一.实验目的 (1) 通过实验掌握 Spark SQL 的基本编程方法: (2) 熟悉 RDD 到 DataFrame 的转化方法: (3) 熟悉利用 Spark ...
- 第五周学习总结&实验报告(三)
第五周学习总结&实验报告(三) 这一周又学习了新的知识点--继承. 一.继承的基本概念是: *定义一个类,在接下来所定义的类里面如果定义的属性与第一个类里面所拥有的属性一样,那么我们在此就不需 ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- 实验 2 Scala 编程初级实践
实验 2 Scala 编程初级实践 一.实验目的 1.掌握 Scala 语言的基本语法.数据结构和控制结构: 2.掌握面向对象编程的基础知识,能够编写自定义类和特质: 3.掌握函数式编程的基础知识,能 ...
- 第五周课程总结&实验报告(四)
第五周课程总结 本周主要学习了 1.抽象类 抽象类的定义格式 abstract class抽象类名称{ 属性; 访问权限返回值类型方法名称(参数){ //普通方法 [return返回值]; } 访问权 ...
随机推荐
- 002Excel冻结窗口(冻结第二行)
不知道是最近状态不好还是怎么回事Excel冻结前面两行居然弄了很久,而工作上又急需,为此还是记录一下 其实超级简单(不会的话就很难) 如果冻结一行 这个非常简单 那么冻结前面两行呢?我研究了很久,其实 ...
- 【2019.8.11上午 慈溪模拟赛 T3】欢迎回来(back)(设阈值+莫队)
设阈值 考虑对于询问的\(d\)设阈值进行分别处理. 对于\(d\le\sqrt{max\ d}\)的询问,我们可以\(O(n\sqrt{max\ d})\)预处理答案,\(O(1)\)输出. 对于\ ...
- Excel已损坏,无法打开
突然之间,很多EXCEL文件打开时报错:"已损坏,无法打开",这些文件共同点是从邮件中下载而来,这些文件可能面临着安全威协,原来是软件设置了受保护的视图,取消即可.
- Codeforces Round #596 (Div. 2, based on Technocup 2020 Elimination Round 2) C. p-binary 水题
C. p-binary Vasya will fancy any number as long as it is an integer power of two. Petya, on the othe ...
- C++ 回调函数的多种用法
什么是回调函数, 就是以函数指针做参数传递给另一个函数称之为回调函数, 字面意思很简单, 但就这几个字想理解回调函数, 那又很难.因此别就这这字面意思, 只要知道怎么用, 在什么情况下用就行了 什么场 ...
- Python之Flask框架项目Demo入门
Python+Flask框架项目Demo入门 本例子用到了 Flask+蓝图+Flask-Login+SQLAlchemy+WTForms+PyMySQL相关架构 Flask Web框架介绍 Flas ...
- 当职责链遇到DI
在GitHub上有个项目,本来是作为自己研究学习.net core的Demo,没想到很多同学在看,还给了很多星,所以觉得应该升成3.0,整理一下,写成博分享给学习.net core的同学们. 项目名称 ...
- multer 基础教程(英文版)
Multer is a node.js middleware for handling multipart/form-data, which is primarily used for uploadi ...
- Composer 的安装
最近在家休息了两个月,本来打算看看书,结果和朋友做了个小项目.项目也差不多接近尾声了,就准备找工作了,朋友推荐我去他们公司做事,不过是使用 PHP 进行开发了.我这一年来使用 Java 进行开发,今后 ...
- HashMap的底层原理(jdk1.7.0_79)
前言 在Java中我们最常用的集合类毫无疑问就是Map,其中HashMap作为Map最重要的实现类在我们代码中出现的评率也是很高的. 我们对HashMap最常用的操作就是put和get了,那么你知道它 ...