学习Spring-Data-Jpa(八)---定义方法查询
1、查询策略
spring-data一共有三种方法查询策略:
QueryLookupStrategy.Key.CREATE,尝试根据方法名进行创建。通用方法是从方法名中删除一组特定的前缀,然后解析该方法的其余部分。如果方法名不符合规则,则抛出异常。
QueryLookupStrategy.Key.USE_DECLARED_QUERY,尝试查找已声明的查询,如果找不到则抛出异常。该查询可以通过某处的注释定义,也可以通过其他方式声明。
QueryLookupStrategy.Key.CREATE_IF_NOT_FOUND,(默认)组合CREATE和USE_DECLARED_QUERY。它首先查找一个声明的查询,如果找不到声明的查询,它将创建一个基于名称的自定义方法查询。 如果我们想要修改查询策略,可以通过@EnableJpaRepositories的queryLookupStrategy属性设置。
@EnableJpaRepositories(queryLookupStrategy = QueryLookupStrategy.Key.CREATE_IF_NOT_FOUND)
public class StudySpringDataJpaApplication { public static void main(String[] args) {
SpringApplication.run(StudySpringDataJpaApplication.class, args);
} }
2、查询创建
2.1、spring-data内置了根据方法名创建查询的构建器,对于在存储库的实体上构建约束查询很有用。该机制的方法前缀有find…By,read…By,query…By,count…By,和get…By,从这些方法可以解析它的其余部分。引入子句可以包含其他表达式,例如Distinct,以在要创建的查询上设置不同的标志。但是,第一个By充当分隔符以指示实际标准的开始。在最基本
的级别上,可以定制实体属性条件,并使用AND和OR进行串连。 2.2、解析该方法的实际结果取决与创建查询的持久性存储。但是,需要注意一些一般事项:
2.2.1、表达式通常时可以连接的运算符的属性遍历。可以使用组合属性表达式AND和OR,也可以使用运算关键字Between,LessThan,GreaterThan,和Like作为属性表达式。支持的运算符可能因数据库而异,需要参阅官方文档。
2.2.2、方法解析器支持为单个属性忽略大小写(IgnoreCase),或全部忽略大小写(AllIgnoreCase),是否支持忽略大小写因数据库而异,需要参阅数据库支持。
2.2.3、可以通过OrderBy子句附加引用属性,为查询方法提供排序方向(Asc或Desc)。
2.2.4、当实体中的属性也是一个实体时,我们一般使用下划线_来手动定义遍历点(所以我们的属性命名要规范,使用驼峰)。 2.3、关键字列表
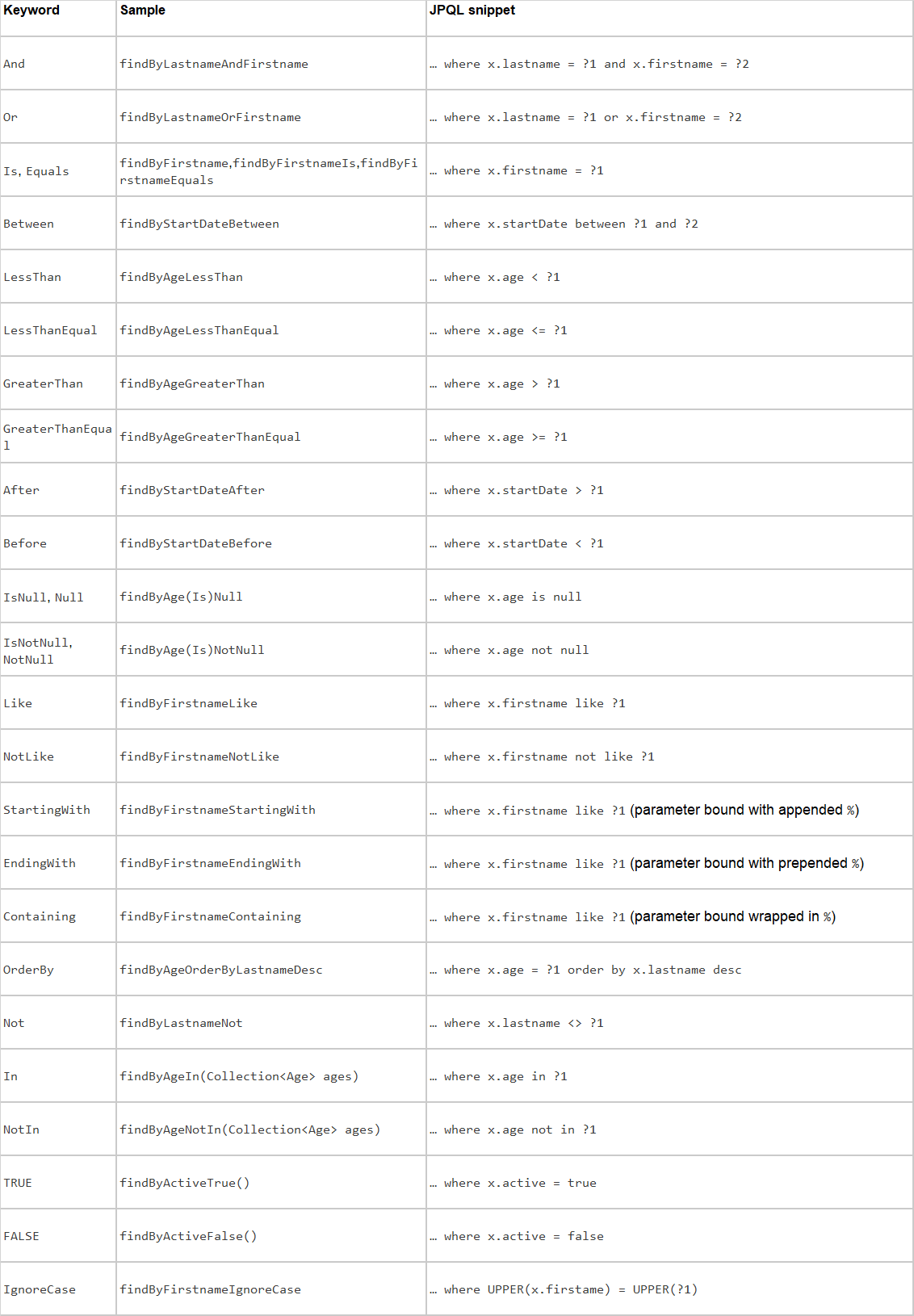
3、特殊参数处理
框架可以识别Pageable和Sort,动态的将分页和排序应用到查询中。可以返回Page<T> 、Slice<T> 、List<T>。
3.1、Sort和Pageable不能传null值,如果不想应用排序或分页,使用Sort.unsorted()和Pageable.unpaged()。
3.2、返回Page<T>,可以知道一些附加信息,如页面总数。他会额外执行一条count语句去查询总数,如果数据量很大,会很消耗资源,可以使用下面的来替代。
3.3、返回Slice<T>,Slice的作用是,只知道是否有下一个Slice可用,不会执行count语句,所以当查询较大的数据量时,也没必要关心页数。
3.4、返回List<T>,分页也可以返回List,这种情况下,也不会额外执行count语句,仅仅是将范围内的结果装入List。 4、限制查询结果
可以通过使用first或者top关键字来限制查询方法的返回结果,可以互换使用。可以将可选的数值追加到它们后面,指定返回结果大小。如果省略数字,则假定结果大小为1。限制表达式也支持Distinct关键字。对于结果集限制为1个的示例查询,支持将结果包装到Optional中。如果将分页或切片
应用于限制查询分页(以及对可用页面数的计算),则会在限制结果内应用分页或切片(不建议分页和限制同使使用)。 5、常用的返回结果的不同形式
5.1、void,对于我们不关乎结果的操作,可以选择不返回结果,一般用作更新。
5.2、Primitives,Java的基本类型,一般用作统计返回,(如long,boolean)。
5.3、Wrapper types,Java的包装类型。
5.4、T,返回一个实体,没有查询结果,返回null,如果超过一个返回结果,抛出IncorrectResultSizeDataAccessException异常。
5.5、Iterator<T>、Collection<T>、List<T>,Set<T>,返回多个结果时,可以使用迭代器,集合,List及其子类,Set及其子类。
5.6、Optional<T>,Java8或者Guava的Optional类,查询方法最多返回一个结果,如果不存在返回Optional.empty()或Optional.absent(),如果超出一个结果,抛出IncorrectResultSizeDataAccessException异常。
5.7、Stream<T>,Java8的Stream。必须在使用后关闭流。可以使用try-with-resources,也可以使用Stream的close()方法。
5.7、Streamable<T>,Spring-Data提供的Streamable,可以作为Iterator或任何集合类型的替代。
5.8、自定义Streamable的类型,实现Streamable并提供一个将Streamable作为参数的公开的构造方法或方法名为of(…) or valueOf(…)的静态工厂方法。
5.9、Slice<T>、Page<T>,分页相关,需要提供一个Pageable入参。Page继承自Slice,Slice继承自Streamable。
5.10、Future<T>,查询方法上需要添加@Async注解,并开启Spring异步执行方法功能。
5.11、CompletableFuture<T>,Java8的CompletableFuture,需要在方法上添加@Async注解,并开启Spring异步执行方法功能。
5.12、ListenableFuture,返回org.springframework.util.concurrent.ListenableFuture,需要在方法上添加@Async注解,并开启Spring异步执行方法功能。
5.13、关联查询时,可返回Object[] 和 Map
源码地址:https://github.com/caofanqi/study-spring-data-jpa
学习Spring-Data-Jpa(八)---定义方法查询的更多相关文章
- Spring Data JPA 梳理 - 使用方法
1.下载需要的包. 需要先 下载Spring Data JPA 的发布包(需要同时下载 Spring Data Commons 和 Spring Data JPA 两个发布包,Commons 是 Sp ...
- Spring Data Jpa的四种查询方式
一.调用接口的方式 1.基本介绍 通过调用接口里的方法查询,需要我们自定义的接口继承Spring Data Jpa规定的接口 public interface UserDao extends JpaR ...
- Spring Data JPA中的动态查询 时间日期
功能:Spring Data JPA中的动态查询 实现日期查询 页面对应的dto类private String modifiedDate; //实体类 @LastModifiedDate protec ...
- spring data jpa使用原生sql查询
spring data jpa使用原生sql查询 @Repository public interface AjDao extends JpaRepository<Aj,String> { ...
- Spring Data Jpa (四)注解式查询方法
详细讲解声明式的查询方法 1 @Query详解 使用命名查询为实体声明查询是一种有效的方法,对于少量查询很有效.一般只需要关心@Query里面的value和nativeQuery的值.使用声明式JPQ ...
- Spring data jpa 实现简单动态查询的通用Specification方法
本篇前提: SpringBoot中使用Spring Data Jpa 实现简单的动态查询的两种方法 这篇文章中的第二种方法 实现Specification 这块的方法 只适用于一个对象针对某一个固定字 ...
- Spring Data JPA 自定义对象接收查询结果集
Spring Data JPA 简介 Spring Data JPA 是 Spring 基于 ORM 框架.JPA 规范的基础上封装的一套JPA应用框架,可使开发者用极简的代码即可实现对数据库的访问和 ...
- 学习Spring Data JPA
简介 Spring Data 是spring的一个子项目,在官网上是这样解释的: Spring Data 是为数据访问提供一种熟悉且一致的基于Spring的编程模型,同时仍然保留底层数据存储的特殊 ...
- spring data jpa 利用@Query进行查询
参照https://blog.csdn.net/yingxiake/article/details/51016234#reply https://blog.csdn.net/choushi300/ar ...
- spring data jpa实现多条件查询(分页和不分页)
目前的spring data jpa已经帮我们干了CRUD的大部分活了,但如果有些活它干不了(CrudRepository接口中没定义),那么只能由我们自己干了.这里要说的就是在它的框架里,如何实现自 ...
随机推荐
- DBCP(MySql)+Servlet+BootStrap+Ajax实现用户登录与简单用户管理系统
目 录 简介 本次项目通过Maven编写 本文最后会附上代码 界面截图 登录界面 注册界面 登录成功进入主页 增加用户操作 删除用户操作 修改用户操作 主要代码 Dao层代码 DBCP代码 Se ...
- Java后台验证
前台的js验证,可以通过其他手段绕过,存在安全问题,所以引入Java后台进行验证 一.导入jar包 此为hibernate-validator jar包,进行Java后台验证使用,在Java 1.9及 ...
- day09——初识函数
day09 函数的定义 # len() s = 'alexdsb' count = 0 for i in s: count += 1 print(count) s = [1,2,23,3,4,5,6] ...
- Visual Studio 2019激活
Visual Studio 2019 Enterprise BF8Y8-GN2QH-T84XB-QVY3B-RC4DF Visual Studio 2019 Professional NYWVH-HT ...
- ubuntu supervisor管理uwsgi+nginx
一.概述 superviosr是一个Linux/Unix系统上的进程监控工具,他/她upervisor是一个Python开发的通用的进程管理程序,可以管理和监控Linux上面的进程,能将一个普通的命令 ...
- 通过对比ASCII编码来理解Unicode编码
Unicode是个规范,可以理解为一个索引表,世界上所有字符基本上在这个索引表中都能找到唯一一个数码与之对应,就像ASCII码表一样,也是一个规范,也可以看成是一个索引表,所有的英文字符都可以在这个索 ...
- H5页面跳转与传值
页面之间的跳转经常使用a标签,使用mvc框架的都是通过访问controller的请求方法,返回请求页面.但本次开发,前端与后台完全分离,前端APP使用HBuider来开发,后台数据就无法使用mvc框架 ...
- 定时任务-Windows任务
定时任务-Windows任务 什么是windows任务 windows系统自带一个任务管理组件.可以执行自己写的程序,发送电子邮件(需要邮件服务器),显示消息(就是桌面弹出一个窗口).用的最多的就 ...
- 2019 房多多java面试笔试题 (含面试题解析)
本人5年开发经验.18年年底开始跑路找工作,在互联网寒冬下成功拿到阿里巴巴.今日头条.房多多等公司offer,岗位是Java后端开发,因为发展原因最终选择去了房多多,入职一年时间了,也成为了面试官 ...
- Java自学-数组 二维数组
Java 如何使用二维数组 这是一个一维数组, 里面的每一个元素,都是一个基本类型int int a[] =new int[]{1,2,3,4,5}; 这是一个二维数组,里面的每一个元素,都是一个一维 ...