HashTable源码解读
一:总述
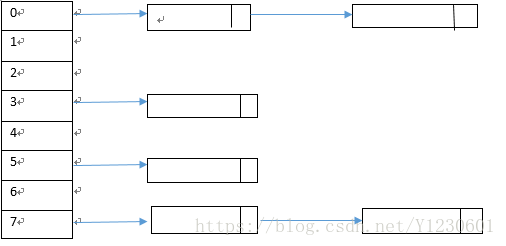
底层实现原理是用数组+链表,与HashMap一样,但HashTable是线程安全的,HashMap是非线程安全的
下面是其结构图(与hashMap类似)
二:属性说明
/**
* The hash table data.
*/
private transient Entry<?,?>[] table;//数据保存的数组,与HashMap一样 /**
* The total number of entries in the hash table.
*/
private transient int count;//总条数 /**
* The table is rehashed when its size exceeds this threshold. (The
* value of this field is (int)(capacity * loadFactor).)
*
* @serial
*/
private int threshold;//加载因子,默认为0.75 /**
* The load factor for the hashtable.
*
* @serial
*/
private float loadFactor;//扩容门槛相对于 数组的比例计算公式 table.length * loadFactor = threshold /**
* The number of times this Hashtable has been structurally modified
* Structural modifications are those that change the number of entries in
* the Hashtable or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the Hashtable fail-fast. (See ConcurrentModificationException).
*/
private transient int modCount = 0;
三:构造方法
由构造方法可得知,hashtable没有size规定默认为11,在hashMap中默认为16,并且hashMap必须是大于16的2的次方(特殊指定除外,但是hashMap自动会计算得出大于指定值得2的次方)
/**
* Constructs a new, empty hashtable with the specified initial
* capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hashtable.
* @param loadFactor the load factor of the hashtable.
* @exception IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive.
*/
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor); if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
} /**
* Constructs a new, empty hashtable with the specified initial capacity
* and default load factor (0.75).
*
* @param initialCapacity the initial capacity of the hashtable.
* @exception IllegalArgumentException if the initial capacity is less
* than zero.
*/
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
} /**
* Constructs a new, empty hashtable with a default initial capacity (11)
* and load factor (0.75).
*/
public Hashtable() {
//默认数组大小为11,加载因子为0.75
this(11, 0.75f);
}
四:扩容方法
rehash()
他也是和hashmap差不多 就是直接扩容两倍,但是hashTable中会在加1,并且扩容后要重新计算每个元素对应的数组位子,相对于hashMap来说性能会有点差距,hashMap少一步取余的计算,他们在插入数据时都是放在链表的头位子上。
/**
* Increases the capacity of and internally reorganizes this
* hashtable, in order to accommodate and access its entries more
* efficiently. This method is called automatically when the
* number of keys in the hashtable exceeds this hashtable's capacity
* and load factor.
*/
@SuppressWarnings("unchecked")
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// todo hashMap中的length 都市2的次方倍数并且扩容都是 * 2的 但是hashTable 实在原来的基础上* 2 还要加1
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity]; modCount++;
// 这里计算 下次扩容的门槛数量
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap; for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
// 这里是重新计算hash 但是hashMap中优化的比较好,不需要重新计算, 根据二进制来 判断hash和老长度 与运算 是否
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
// 这里相同hashMap和 hashTable都是放在第一个
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
五:addEntry方法
这里面就是实际的插入过程,但是这里面判断了是否需要扩容,没有判断是否已经包含,是否包含都是在调用这个方法前判断的。
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
六:put()方法
方法前加了synchronized。所有对外提供的方法上基本独有这个关键字。hashTable中value不能为空,HashMap中是可以的。而且如果key已经存在就直接覆盖老的value
/**
* Maps the specified <code>key</code> to the specified
* <code>value</code> in this hashtable. Neither the key nor the
* value can be <code>null</code>. <p>
*
* The value can be retrieved by calling the <code>get</code> method
* with a key that is equal to the original key.
*
* @param key the hashtable key
* @param value the value
* @return the previous value of the specified key in this hashtable,
* or <code>null</code> if it did not have one
* @exception NullPointerException if the key or value is
* <code>null</code>
* @see Object#equals(Object)
* @see #get(Object)
*/
public synchronized V put(K key, V value) {
// Make sure the value is not null
//不能插入空值
if (value == null) {
throw new NullPointerException();
}
// 查找key对应的数组下标 以便获取所在的链表
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length; //这里判断是否存在当前key
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
// 这里也不太一样 hashMap中可以设置判断value是否相等类判断是否覆盖老value
// hashMap中相当于 就有一个cas的原理可供选择
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
} addEntry(hash, key, value, index);
return null;
}
七:get()方法
比较简单,就是根据key计算数组下标,在遍历链表查找是否相同的key
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key.equals(k))},
* then this method returns {@code v}; otherwise it returns
* {@code null}. (There can be at most one such mapping.)
*
* @param key the key whose associated value is to be returned
* @return the value to which the specified key is mapped, or
* {@code null} if this map contains no mapping for the key
* @throws NullPointerException if the specified key is null
* @see #put(Object, Object)
*/
@SuppressWarnings("unchecked")
public synchronized V get(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return (V)e.value;
}
}
return null;
}
八:remove()方法
根据key计算数组下标,在遍历链表并记录当前元素的上一个元素,查找是否相同的key,将上一个元素的next节点=当前元素的下一个节点(将当前元素的next节点赋值给上一个节点的next节点)
/**
* Removes the key (and its corresponding value) from this
* hashtable. This method does nothing if the key is not in the hashtable.
*
* @param key the key that needs to be removed
* @return the value to which the key had been mapped in this hashtable,
* or <code>null</code> if the key did not have a mapping
* @throws NullPointerException if the key is <code>null</code>
*
*
* 删除 置顶key的元素 源码相对hashMap简单很多
*/
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
for(Entry<K,V> prev = null; e != null ; prev = e, e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
九:与hashMap的区别
HashMap允许key和value为null,Hashtable不允许。 HashMap的默认初始容量为16,Hashtable为11。 HashMap的扩容为原来的2倍,Hashtable的扩容为原来的2倍加1。 HashMap是非线程安全的,Hashtable是线程安全的。
HashTable源码解读的更多相关文章
- 源码解读—HashTable
在上一篇学习过HashMap(源码解读—HashMap)之后对hashTable也产生了兴趣,随即便把hashTable的源码看了一下.和hashMap类似,但是也有不同之处. public clas ...
- HashTable、HashMap与ConCurrentHashMap源码解读
HashMap 的数据结构 hashMap 初始的数据结构如下图所示,内部维护一个数组,然后数组上维护一个单链表,有个形象的比喻就是想挂钩一样,数组脚标一样的,一个一个的节点往下挂. 我们可以 ...
- jdk1.8.0_45源码解读——HashMap的实现
jdk1.8.0_45源码解读——HashMap的实现 一.HashMap概述 HashMap是基于哈希表的Map接口实现的,此实现提供所有可选的映射操作.存储的是<key,value>对 ...
- jdk1.8.0_45源码解读——Map接口和AbstractMap抽象类的实现
jdk1.8.0_45源码解读——Map接口和AbstractMap抽象类的实现 一. Map架构 如上图:(01) Map 是映射接口,Map中存储的内容是键值对(key-value).(02) A ...
- SDWebImage源码解读之SDWebImageDownloaderOperation
第七篇 前言 本篇文章主要讲解下载操作的相关知识,SDWebImageDownloaderOperation的主要任务是把一张图片从服务器下载到内存中.下载数据并不难,如何对下载这一系列的任务进行设计 ...
- SDWebImage源码解读 之 NSData+ImageContentType
第一篇 前言 从今天开始,我将开启一段源码解读的旅途了.在这里先暂时不透露具体解读的源码到底是哪些?因为也可能随着解读的进行会更改计划.但能够肯定的是,这一系列之中肯定会有Swift版本的代码. 说说 ...
- SDWebImage源码解读 之 UIImage+GIF
第二篇 前言 本篇是和GIF相关的一个UIImage的分类.主要提供了三个方法: + (UIImage *)sd_animatedGIFNamed:(NSString *)name ----- 根据名 ...
- SDWebImage源码解读 之 SDWebImageCompat
第三篇 前言 本篇主要解读SDWebImage的配置文件.正如compat的定义,该配置文件主要是兼容Apple的其他设备.也许我们真实的开发平台只有一个,但考虑各个平台的兼容性,对于框架有着很重要的 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
随机推荐
- 以太网,IP,TCP,UDP数据包分析(此文言简意赅,一遍看不懂的话,耐心的看个10遍就懂了,感谢作者无私奉献)
1.ISO开放系统有以下几层: 7 应用层 6 表示层 5 会话层 4 传输层 3 网络层 2 数据链路层 1 物理层 2.TCP/IP 网络协议栈分为应用层(Application).传输层(Tra ...
- Hadoop集群(第1期)CentOS安装配置
1.准备安装 1.1 系统简介 CentOS 是什么? CentOS是一个基于Red Hat 企业级 Linux 提供的可自由使用的源代码企业级的 Linux 发行版本.每个版本的 CentOS 都会 ...
- java关键字-abstract
抽象:不具体,看不明白. 抽象类表象体现. 在不断抽取过程中,将共性内容中的方法声明抽取,但是方法不一样,没有抽取,这时抽取到的方法,并不具体,需要被指定关键字abstract所标示,声明为抽象方法. ...
- 3013C语言_输入输出
第三章 输入输出 3.1输入输出概念及其实现 (1)数据从计算机内部向外部输出设备(如显示器.打印机等)输送的操作称为 “输出”,数据从计算机外部向输入设备(如键盘.鼠标.扫描仪等)送入的操作称为 “ ...
- python 方法无法在线程中使用(附python获取网络流量)
在python中,定义一个方法,直接调用可以,但是创建一个线程来调用就可能导致失败.这种现象多出现在使用com对象进行系统操作时,而且是以线程的形式调用. 异常提示如下:syntax error.WM ...
- Hive 学习之路(七)—— Hive 常用DML操作
一.加载文件数据到表 1.1 语法 LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (p ...
- SSM(三)Mybatis动态SQL
1.查询语句,where: <resultMap id="xxx" type="xx..Student" autoMapping="false& ...
- Java:Web Service初入门
前言 Web Service技术在我第一次接触,又没有实际使用时完全不理解这是什么.以为是一种类似Spring,Shiro的编程框架.后来渐渐理解,WS(即Web Service缩写)是一种通用的接口 ...
- sql语句一些简单的用法
- BZOJ 1483:[HNOI2009]梦幻布丁(链表启发式合并)
http://www.lydsy.com/JudgeOnline/problem.php?id=1483 题意:中文. 思路:对于每一种颜色,用一个链表串起来,一开始保存一个答案,后面颜色替换的时候再 ...