springboot + mybatis + mycat整合
1、mycat服务
搭建mycat服务并启动,windows安装参照。
系列文章:
[Mycat 简介]
2、相关配置文件
此处我的配置为:
schema.xml
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> <!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!-- random sharding using mod sharind rule -->
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<!-- <table name="dual" primaryKey="ID" dataNode="dnx,dnoracle2" type="global"
needAddLimit="false"/> <table name="worker" primaryKey="ID" dataNode="jdbc_dn1,jdbc_dn2,jdbc_dn3"
rule="mod-long" /> -->
<table name="employee" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"
parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema> <schema name="springboot" checkSQLschema="false" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="tb_user" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> <!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<table name="tb_company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<!-- <readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" /> -->
</writeHost>
<!-- <writeHost host="hostS1" url="localhost:3316" user="root"
password="123456" /> -->
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<!--
<dataHost name="sequoiadb1" maxCon="1000" minCon="1" balance="0" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost> <dataHost name="oracle1" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="oracle" dbDriver="jdbc"> <heartbeat>select 1 from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="123456" > </writeHost> </dataHost> <dataHost name="jdbchost" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="123456" ></writeHost> </dataHost> <dataHost name="sparksql" maxCon="1000" minCon="1" balance="0" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> --> <!-- <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost>
</dataHost> -->
</mycat:schema>
server.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="useHandshakeV10">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 --> <property name="sequnceHandlerType">2</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property> <!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">1</property> <!--
单位为m
-->
<property name="memoryPageSize">64k</property> <!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property> <property name="useStreamOutput">0</property> <!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property> <!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property> <!-- XA Recovery Log日志路径 -->
<!--<property name="XARecoveryLogBaseDir">./</property>--> <!-- XA Recovery Log日志名称 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property> <property name="useZKSwitch">true</property> </system> <!-- 全局SQL防火墙设置 -->
<!--白名单可以使用通配符%或着*-->
<!--例如<host host="127.0.0.*" user="root"/>-->
<!--例如<host host="127.0.*" user="root"/>-->
<!--例如<host host="127.*" user="root"/>-->
<!--例如<host host="1*7.*" user="root"/>-->
<!--这些配置情况下对于127.0.0.1都能以root账户登录-->
<!--
<firewall>
<whitehost>
<host host="1*7.0.0.*" user="root"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
--> <user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB,springboot</property> <!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user> <user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user> </mycat:server>
rule.xml
<?xml version="1.0" encoding="UTF-8"?>
<!-- - - Licensed under the Apache License, Version 2.0 (the "License");
- you may not use this file except in compliance with the License. - You
may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0
- - Unless required by applicable law or agreed to in writing, software -
distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT
WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the
License for the specific language governing permissions and - limitations
under the License. -->
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule> <tableRule name="rule2">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule> <tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<tableRule name="mod-long">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<tableRule name="crc32slot">
<rule>
<columns>id</columns>
<algorithm>crc32slot</algorithm>
</rule>
</tableRule>
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>partbymonth</algorithm>
</rule>
</tableRule>
<tableRule name="latest-month-calldate">
<rule>
<columns>calldate</columns>
<algorithm>latestMonth</algorithm>
</rule>
</tableRule> <tableRule name="auto-sharding-rang-mod">
<rule>
<columns>id</columns>
<algorithm>rang-mod</algorithm>
</rule>
</tableRule> <tableRule name="jch">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule> <function name="murmur"
class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function> <function name="crc32slot"
class="io.mycat.route.function.PartitionByCRC32PreSlot">
</function>
<function name="hash-int"
class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function> <function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth"
class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2015-01-01</property>
</function> <function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function> <function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">3</property>
</function>
</mycat:rule>
需要的可自行修改。
3、整合
pom依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency> <dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
application.yml配置文件:
#设置应用端口
server:
port: 8080 spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
# Mycat连接
url: jdbc:mysql://localhost:8066/springboot?useUnicode=true&characterEncoding=utf-8&autoReconnect=true&zeroDateTimeBehavior=convertToNull&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456 # MyBatis
mybatis:
type-aliases-package: com.example.springbootmybatismycat.domain
mapper-locations: classpath:/mybatis/*.xml
#sql打印配置
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
整体文件结构如图:
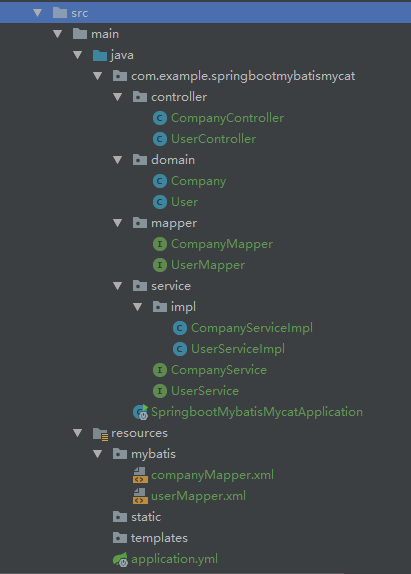
其他实体类等就不放上去了,有需要的可自行到github上下载测试。
4、测试
打开浏览器,使用测试接口测试
4.1 tb_company表测试
添加公司:
查看公司:

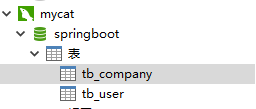
查看mycat:
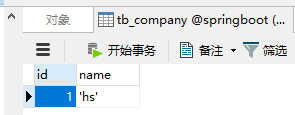
查看mysql:
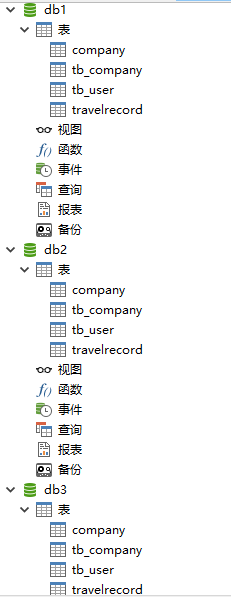
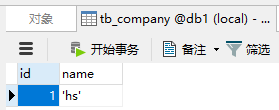

可以看到正如配置的:
<table name="tb_company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
tb_company配置为了全局,所以在每个数据库中都有数据。
4.2 tb_User表测试
添加用户:

查看用户:
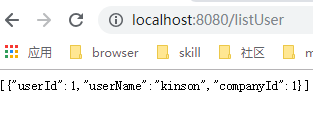
查看mycat:
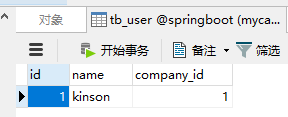
查看mysql:
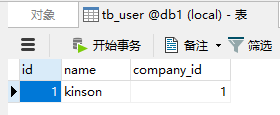
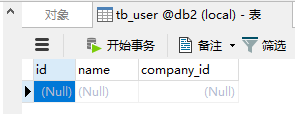
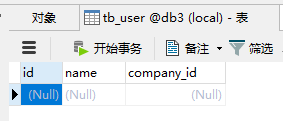
因为schema.xml配置中tb_user的配置为:
<table name="tb_user" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
对应rule规则为:
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long"
class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
autopartition-long.txt文件为:
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
按照规则auto-sharding-long进行分区处理,id为1时对应0,即db1数据库。
5、问题
在新增用户时报错:partition table, insert must provide ColumnList错误,解决:
将insert into tb_user VALUES (#{userId}, #{userName},#{companyId});
改为
insert into tb_user(id, name, company_id) VALUES (#{userId}, #{userName},#{companyId});
即加上所有的列字段
springboot + mybatis + mycat整合Github源码参照
springboot + mybatis + mycat整合的更多相关文章
- SpringBoot+Mybatis+MybatisPlus整合实现基本的CRUD操作
SpringBoot+Mybatis+MybatisPlus整合实现基本的CRUD操作 1> 数据准备 -- 创建测试表 CREATE TABLE `tb_user` ( `id` ) NOT ...
- Springboot+mybatis中整合过程访问Mysql数据库时报错
报错原因如下:com.mysql.cj.core.exceptions.InvalidConnectionAttributeException: The server time zone.. 产生这个 ...
- springboot+mybatis+springmvc整合实例
以往的ssm框架整合通常有两种形式,一种是xml形式,一种是注解形式,不管是xml还是注解,基本都会有一大堆xml标签配置,其中有很多重复性的.springboot带给我们的恰恰是“零配置”,&quo ...
- springboot + mybatis +easyUI整合案例
概述 springboot推荐使用的是JPA,但是因为JPA比较复杂,如果业务场景复杂,例如企业应用中的统计等需求,使用JPA不如mybatis理想,原始sql调优会比较简单方便,所以我们的项目中还是 ...
- SpringBoot + Mybatis + Redis 整合入门项目
这篇文章我决定一改以往的风格,以幽默风趣的故事博文来介绍如何整合 SpringBoot.Mybatis.Redis. 很久很久以前,森林里有一只可爱的小青蛙,他迈着沉重的步伐走向了找工作的道路,结果发 ...
- springboot mybatis 分页整合
spring boot 整合mybatis ,分两块mybatis 整合,分页整合. 1.pom文件增加 <dependency> <groupId>org.mybatis ...
- 7.springboot+mybatis+redis整合
选择生成的依赖 选择保存的工程路径 查询已经生成的依赖,并修改mysql的版本 <dependencies> <dependency> <groupId>org.s ...
- springboot+mybatis+pagehelper
springboot+mybatis+pagehelper整合 springboot 版本2.1.2.RELEASE mybatis 版本3.5 pagehelper 版本5.18 支持在map ...
- 零基础IDEA整合SpringBoot + Mybatis项目,及常见问题详细解答
开发环境介绍:IDEA + maven + springboot2.1.4 1.用IDEA搭建SpringBoot项目:File - New - Project - Spring Initializr ...
随机推荐
- volatile底层实现原理
前言 当共享变量被声明为volatile后,对这个变量的读/写操作都会很特别,下面我们就揭开volatile的神秘面纱. 1.volatile的内存语义 1.1 volatile的特性 一个volat ...
- [python] - 读取文件内容,并输出
1.读取文件,并逐行输出内容,代码如下: # coding=gbk import os path = 'E:\python_practice' os.chdir(path) fname = raw_i ...
- codeforces 807 E. Prairie Partition(贪心+思维)
题目链接:http://codeforces.com/contest/807/problem/E 题意:已知每个数都能用x=1 + 2 + 4 + ... + 2k - 1 + r (k ≥ 0, 0 ...
- codeforces 161 D. Distance in Tree(树形dp)
题目链接:http://codeforces.com/problemset/problem/161/D 题意:给出一个树,问树上点到点的距离为k的一共有几个. 一道简单的树形dp,算是一个基础题. 设 ...
- codeforces 264 B. Good Sequences(dp+数学的一点思想)
题目链接:http://codeforces.com/problemset/problem/264/B 题意:给出一个严格递增的一串数字,求最长的相邻两个数的gcd不为1的序列长度 其实这题可以考虑一 ...
- Patch
http://www.cnblogs.com/cute/archive/2011/04/29/2033011.html zhezhelin diff和patch使用指南 diff和patch是一对工具 ...
- 【Bit String Reordering UVALive - 6832 】【模拟】
题意分析 题目讲的主要是给你一个01串,然后给你要变成的01串格式,问你要转换成这一格式最少需要移动的步数. 题目不难,但当时并没有AC,3个小时的个人赛1道没AC,归根到底是没有逼自己去想,又想的太 ...
- 【Offer】[10-1] 【斐波那契数列】
题目描述 思路分析 Java代码 代码链接 题目描述  大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0). 思路分析 递归的思路,会出现很多重复的 ...
- java 手机号码+邮箱的验证
import java.util.regex.Pattern; //导入的包 1:String REGEX_MOBILE = "^((17[0-9])|(14[0-9])|(13[0-9]) ...
- 手机端特有的meta标签有哪些?
3.1 meta 语法 定义和用法:name 属性把 content 属性连接到 name. 语法:name=author|description|keywords|generator|revised ...