百万年薪python之路 -- 模块
1.自定义模块
1.1.1 模块是什么?
模块就是文件,存放一堆常用的函数和变量的程序文件(.py)文件
1.1.2 为什么要使用模块?
1.避免写重复代码,从文件级别组织程序,更方便管理
2.可以多次利用,我们不仅仅可以把这些文件当做脚本去执行,还可以把他们当做模块来导入到其他的模块中,实现了功能的重复利用
3.拿来主义,提升开发效率 同样的原理,我们也可以下载别人写好的模块然后导入到自己的项目中使用,这种拿来主义,可以极大地提升我们的开发效率,避免重复造轮子.
1.1.3 模块的分类
Python语言中,模块分为三类。
第一类:内置模块,也叫做标准库。此类模块就是python解释器给你提供的
eg:time模块,os模块。标准库的模块非常多(200多个,每个模块又有很多功能)
第二类:第三方模块,第三方库。必须通过pip install 指令安装的模块,比如BeautfulSoup, Django,等等
第三类:自定义模块。我们自己在项目中定义的一些模块。
1.2.1 import 使用 (import 翻译为 导入)
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块import很多次,为了防止你重复导入,python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载到内存中的模块对象增加了一次引用,不会重新执行模块内的语句)
重复导入会直接引用内存中已经加载好的结果
1.2.2 第一次导入模块执行三件事
1.创建一个以模块名命名的名称空间。
2.执行这个名称空间(即导入的模块)里面的代码。
3.通过此模块名. 的方式引用该模块里面的内容(变量,函数名,类名等)
1.2.3 被导入模块有独立的名称空间
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突。
1.2.4 为模块起别名
1. 好处可以将很长的模块名改成很短,方便使用.
import time as t
t.time()2. 有利于代码的扩展和优化。
#mysql.py
def sqlparse():
print('from mysql sqlparse')
#oracle.py
def sqlparse():
print('from oracle sqlparse')
#test.py
db_type=input('>>: ')
if db_type == 'mysql':
import mysql as db
elif db_type == 'oracle':
import oracle as db
db.sqlparse()1.2.5 导入多个模块
推荐多行导入
多行导入:易于阅读 易于编辑 易于搜索 易于维护。
1.3.1 from ... import ... 使用
from time import time
start = time()
func()
end = time()
ret = end - start # 测试func函数的执行时间1.3.2 from...import... 与import对比
import :
缺点:占用内存比较大
优点:不会和当前文件定义的变量或者函数发生冲突
import test
name = "章超印"
print(test.name)
print(name)from...import... :
缺点:会和当前文件定义的变量或者函数发生冲突
name = "章超印"
from test import name
print(name)
解决方法:
name = "章超印"
from test import name as n
print(name)
print(n)优点:占用内存比较小
注意点:
1.执行文件有与模块同名的变量或者函数名,会有覆盖效果。
2.当前位置直接使用B,执行时,仍然以A文件全局名称空间
1.3.3 from … import也支持as改名
1.3.4 一行导入多个(不推荐)
1.3.5 from ... import *(不推荐)
from meet import * 把meet中所有的不是以下划线(_)开头的名字都导入到当前位置
可读性极其的差,,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字,在交互式环境中导入时没有问题。
可以使用all来控制*(用来发布新版本),在A文件中新增一行
__all__=['变量名','函数名'] #这样在另外一个文件中用from A import *就这能导入列表中规定的两个名字(没写在列表里的函数名和变量不能被导入)没写在列表里的函数名和变量不能被导入
1.3.6 模块循环导入问题
模块循环/嵌套导入抛出异常的根本原因是由于在python中模块被导入一次之后,就不会重新导入,只会在第一次导入时执行模块内代码
1.4 模块的两种用法:
1.脚本(在cmd中执行 python test.py),一个文件就是整个程序,用来被执行
2.模块(不使用或者导入),用来被导入使用 python为我们内置了全局变量_ _ name _ _ , 当文件被当做脚本执行时: _ _ name _ _ 等于'_ _ main _ ' 当文件被当做模块导入时: _ name _ _ 等于 模块名 作用:用来控制.py文件在不同的应用场景下执行不同的逻辑(或者是在模块文件中测试代码)
1.5 模块的搜索路径
Python中引用模块是按照一定的规则以及顺序去寻找的,这个查询顺序为:先从内存中已经加载的模块进行寻找,找不到再从内置模块中寻找,内置模块如果也没有,最后去sys.path中路径包含的模块中寻找。它只会按照这个顺序从这些指定的地方去寻找,如果最终都没有找到,那么就会报错。
内存中已经加载的模块 -->内置模块 -->sys.path路径中包含的模块
模块的查找顺序
- 在第一次导入某个模块时,会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用(ps:python解释器在启动时会自动加载一些模块到内存中,可以使用sys.modules查看)
- 如果没有,解释器则会查找同名的内置模块
- 如果还没有找到就从sys.path给出的目录列表中依次寻找.py文件。
需要特别注意的是:我们自定义的模块名不应该与系统内置模块重名。
1.6导入路径:
内存加载 > 自定义 > 内置 > 第三方
使用相对路径:
from day15.t1 import meet
print(meet.name)使用绝对路径:
# 错误示例:
from r"D:\" import meet
from ../
# 正确的绝对路径:
from sys import path
path.insert(0,"D:\\")
import meet
print(meet.name)2.time模块
time.time() # 时间戳 浮点型
# print(time.time()) # 时间戳 浮点数
# print(time.time() + 5000000000) # 时间戳 浮点数time.sleep() # 阻塞,睡眠 秒单位
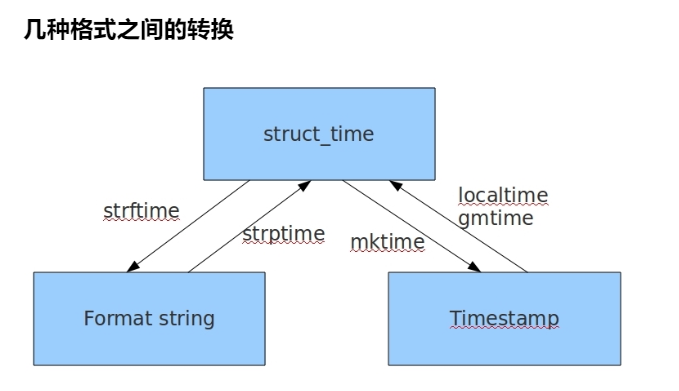
time.sleep(3)time.gmtime() / time.localtime() # 时间戳 -- 结构化
# print(time.gmtime()) # 结构化时间 数据类型是是命名元组
# print(time.gmtime()[0])
# print(time.gmtime().tm_year)
结果:
time.struct_time(tm_year=2019, tm_mon=7, tm_mday=25, tm_hour=8, tm_min=16, tm_sec=33, tm_wday=3, tm_yday=206, tm_isdst=0)
2019
2019time.strftime("格式化","结构化时间") # 结构化 - 字符串
print(time.strftime("%Y-%m-%d %H:%M:%S")) # 给人看的
结果:
2019-07-25 16:15:31# 将时间戳转换成字符串时间
print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime(1564028611.631374)))
#结果:
#2019-07-25 04:23:31time.strptime("字符串","格式化") # 字符串 - 结构化
print(time.strptime("2024-3-16 12:30:30","%Y-%m-%d %H:%M:%S"))
结果:
time.struct_time(tm_year=2024, tm_mon=3, tm_mday=16, tm_hour=12, tm_min=30, tm_sec=30, tm_wday=5, tm_yday=76, tm_isdst=-1)
tm_year:年
tm_mon:月
tm_mday:日
tm_hour:小时
tm_min:分钟
tm_sec:秒
tm_wday:第几周算第几天,用来做输入时间,判断星期几,0表示星期天
tm_yday:按年来算第几天,用来做输入时间,判断这一年的第几天
tm_isdst:夏令营日time.mktime() # 结构化 -- 时间戳
# 将字符串时间转换成时间戳
# print(time.mktime(time.strptime("2024-3-16 12:30:30","%Y-%m-%d %H:%M:%S")))
结果:
1710563430.03.datetime模块
如何导入:
from datetime import datetime
datetime -- 对象
print(type(datetime.now())) # 获取当前时间
结果:
2019-07-25 16:27:21.273176 <class 'datetime.datetime'>print(datetime(2019,5,20,15,14,00) - datetime(2018,3,30,19,20,00))
结果:
415 days, 19:54:00将当前时间转化成时间戳
t = datetime.now()
print(t.timestamp())
结果:
1564043445.324886将时间戳转化成当前时间
print(datetime.fromtimestamp(15000000000))
结果:
2445-05-01 10:40:00将字符串转成对象
print(type(datetime.strptime("2019-10-10 22:23:24","%Y-%m-%d %H:%M:%S")))
结果:
<class 'datetime.datetime'>将对象转成字符串
print(str(datetime.now()))
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
结果:
2019-07-25 16:34:37.383207
2019-07-25 16:34:37datetime加减
from datetime import datetime,timedelta
print(datetime.now() + timedelta(hours=30 * 24 * 12))
print(datetime.now() - timedelta(hours=30 * 24 * 12))
结果:
2020-07-19 16:36:12.919699
2018-07-30 16:36:12.9196994.random模块
import random
# print(random.random()) # 0 ~ 1
# print(random.uniform(1,10)) # 1 ~ 10
# print(random.randint(1,50)) # 1 ~ 50(闭区间)
# print(random.randrange(1,5,2)) # randrange(起始,终止,步长)
# print(random.choice([1,2,3,4,5,])) # 选择一个元素
# print(random.choices([1,2,3,4,5,],k=2)) # 选择两个元素,会有重复
# print(random.sample((1,2,3,4,5),k=2)) # 选择两个元素,不会有重复(除非只有两个)
# lst = [1,2,3,4,5,6,7,8,9,0]
# random.shuffle(lst) # 把顺序打乱
# print(lst)
#练习题:验证码5.一日内容
# 1.自定义模块
# import 工具箱
# from 工具箱 import 工具
# from 工具箱 import *
# __all__ = ["func","name"] # 控制*获取的工具
# 起别名 import from
# 模块的两个功能:
# if __name__ == '__main__':
# 在当前模块中使用,if下边的代码会执行
# 当模块被导入的时候 if下边的代码不会执行
# 模块导入的坑:
# 模块导入的路径:
# 相对路径:
# from 工具箱.工具箱 import 工具
# 绝对路径:
# from sys import path
# path.insert(0,绝对路径)
# 自定义 > 内置 > 第三方
# 2.time
# time.time() # 时间戳 浮点型
# time.sleep() # 睡眠 秒单位
# time.gmtime() / time.localtime() # 时间戳 -- 结构化
# time.strftime("格式化","结构化时间") # 结构化 - 字符串
# time.strptime("字符串","格式化") # 字符串 - 结构化
# time.mktime() # 结构化 -- 时间戳
# 3.datetime
# 将当前时间转化成时间戳
# t = datetime.now()
# print(t.timestamp())
# 将时间戳转化成当前时间
# import time
# print(datetime.fromtimestamp(15000000000))
# 将字符串转成对象
# print(type(datetime.strptime("2019-10-10 22:23:24","%Y-%m-%d %H:%M:%S")))
# 将对象转成字符串
# print(str(datetime.now()))
# print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# datetime加减
# print(datetime.now() + timedelta(hours=30 * 24 * 12))
# print(datetime.now() - timedelta(hours=30 * 24 * 12))
# 4.random (随机数)
# print(random.random()) # 0 ~ 1
# print(random.uniform(1,10)) # 1 ~ 10
# print(random.randint(1,50)) # 1 ~ 50(闭区间)
# print(random.randrange(1,5,2)) # randrange(起始,终止,步长)
# print(random.choice([1,2,3,4,5,])) # 选择一个元素
# print(random.choices([1,2,3,4,5,],k=2)) # 选择两个元素,会有重复
# print(random.sample((1,2,3,4,5),k=2)) # 选择两个元素,不会有重复(除非只有两个)
# lst = [1,2,3,4,5,6,7,8,9,0]
# random.shuffle(lst) # 顺序打乱
# print(lst)743183dc6dd2890e29ec5324eebe0113
743183dc6dd2890e29ec5324eebe0113百万年薪python之路 -- 模块的更多相关文章
- 百万年薪python之路 -- 模块三
logging 日志模块 loggin模块参数 灵活配置日志级别,日志格式,输出位置: import logging logging.basicConfig(level=logging.DEBUG, ...
- 百万年薪python之路 -- 模块二
1. 序列化模块 什么是序列化呢? 序列化的本质就是将一种数据结构(如字典.列表)等转换成一个特殊的序列(字符串或者bytes)的过程就叫做序列化. 为什么要有序列化模块? 如果你写入文件中的字符串是 ...
- 百万年薪python之路 -- MySQL数据库之 Navicat工具和pymysql模块
一. IDE工具介绍(Navicat) 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具,我们使用Navicat工具,这个工具本质上就是一个socket客户端,可视化的连接 ...
- 百万年薪python之路 -- re模块
re模块 re模块是python用来描述正则表达式的一个模块. 正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则. 官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先 ...
- 百万年薪python之路 -- socket()模块的用法
socket()模块的用法: import socket socket.socket(socket_family,socket_type,protocal=0) socket_family 可以是 A ...
- 百万年薪python之路 -- 并发编程之 协程
协程 一. 协程的引入 本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态 cpu正在运行一个任务,会在两 ...
- 百万年薪python之路 -- Socket
Socket 1. 为什么学习socket 你自己现在完全可以写一些小程序了,但是前面的学习和练习,我们写的代码都是在自己的电脑上运行的,虽然我们学过了模块引入,文件引入import等等,我可以在程序 ...
- 百万年薪python之路 -- 面向对象之 反射,双下方法
面向对象之 反射,双下方法 1. 反射 计算机科学领域主要是指程序可以访问.检测和修改它本身状态或行为的一种能力(自省) python面向对象中的反射:通过字符串的形式操作对象相关的属性.python ...
- 百万年薪python之路 -- 异常处理
异常处理 1.错误的分类: 1.语法错误:(这种错误,根本过不了python解释器的语法检测,必须在程序执行前就改正) #语法错误示范一 if #语法错误示范二 def test: pass #语法错 ...
随机推荐
- JavaScript之操作符
计算机被发明的初衷仅仅是为了快速实现一些数学计算,然而经过多年发展,计算机已经不单单能实现快速计算这么简单的工作了,现代计算机不仅能够进行数值的计算,还能进行逻辑计算,还具备存储记忆功能,是能够按照程 ...
- Ext.js中树勾选的四种操作
最近在做控件优化的时候产品提了一个需求,对树的勾选要满足四种勾选方案: 1.点击一次根节点,当根节点和子节点均未选中的情况下,根节点和子节点全都选中. 2.第二次点击根节点,当根节点和部分或全部子节点 ...
- Tomcat 报错 The APR based Apache Tomcat Native library which allows optimal performance in production environmen
这个问题在我一次重新装了tomcat和myeclipse时出现 说实话 出现这个问题头大 但是好在解决了 美滋滋 最开始到处寻找各种解决方案 最后直接注释了server.xml中的一行 直接解决这个报 ...
- 我面向 Google 编程,他面向薪资编程
面试官:同学,说一说面向对象有什么好处? 神仙开发者:我觉的面向对象编程没有什么好处. 面试官:为什么(摊手.问号脸)? 神仙开发者:因为在面向对象的时候,我对象总是跟我说话,问我在淘宝上挑的衣服哪个 ...
- electron教程(二): http服务器, ws服务器, 进程管理
我的electron教程系列 electron教程(一): electron的安装和项目的创建 electron教程(二): http服务器, ws服务器, 进程管理 electron教程(三): 使 ...
- Ubuntu 查看操作系统的位数
查看Ubuntu操作系统的位数是32位还是64位,可以通过以下命令来查看: getconf LONG_BIT 返回32或64 :如图
- 【SQL server基础】初步学习存储过程(好学易懂)
-------------------------------------------------------------------------- ------------------------- ...
- Angular 内嵌视图、宿主视图
解析视图: 内嵌视图 - 连接到模板的嵌入视图,在组件模板元素中添加模板(DOM元素.DOM元素组) 宿主视图 - 连接到组件的嵌入视图,在组件元素中添加别的组件 使用类说明: ElementRef ...
- vue运行报错webpack-dev-server: command not found
翻译过来就是: 'webpack-dev-server' 不是内部或外部命令,也不是可运行的程序 解决方法: 然后总结下成功的步骤: 1. 直接在项目目录下: cnpm install npm run ...
- laravel学习之旅
前言:之前写了二篇YII2.0的基本mvc操作,所以,打算laravel也来这一下 *安装现在一般都用composer安装,这里就不讲述了* 一.熟悉laravel (1)如果看到下面这个页面,就说明 ...