[hdu-6395]Sequence 分块+矩阵快速幂
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6395
因为题目数据范围太大,又存在递推关系,用矩阵快速幂来加快递推。
每一项递推时 加的下取整的数随着n变化,但因为下取整有连续性(n一段区间下取整的数是相同的),可以分块,相同的用矩阵快速幂加速
想了好久。。如果最小的开始的值是【p/i】的数为i,那连续的一段长度是【p/(p/i)】-i+1,但为什么分段数是根号n级别啊?。。。
套矩阵快速幂,时间复杂度O(sqrt(n) * log(n))
一个递推关系式 可以用矩阵乘法来表示递推关系
可以用矩阵乘法来表示递推关系
有两种写法
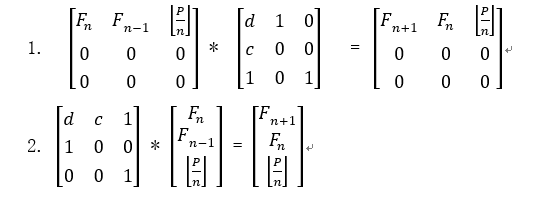
至于怎么求特征值矩阵(用来加速的那个矩阵),就是根据关系式,观察前后两个的变化与联系填就好了
为了写着省事用了第一种,但其实它复杂度高,推荐第二种
坑:
1.n=1 和 n=2 要特判
2.如果n>p,最后加的下取整的数为0,要特判,且特判的时候,注意长度不是【n-p】,p可能比2小,而我们矩阵的第一项是从F2 开始的,应为[n-max(2,p)]
3.矩阵快速幂三层循环的变量不要写错,。。一开始把第三层的k写成 i 死循环了
4.运算符重载后不要用scanf输入,在一些oj上会超时
5.max、min函数比较的是同一种变量
#include<iostream>
#include<cstdio>
#include<cmath>
#include<cstring>
using namespace std;
typedef long long ll;
const int p=1e9+;
ll aa,b,c,d,mo,n;
struct matrix
{
ll a[][];
ll* operator [](int x) {return a[x];}//这里是*不是&
matrix operator *(matrix b)//重载*运算符
{
matrix c;
memset(c.a,,sizeof(c.a));
ll tmp;
for (int i=;i<=;i++) {
tmp=;
for (int j=;j<=;c[i][j]=tmp%p,tmp=,j++)
for (int k=;k<=;k++) tmp+=(a[i][k]*b[k][j])%p;
}
//前提p^3不爆LL可以在第二层再取模
return c;
}
matrix operator ^(ll T)
{
matrix a=*this,b;//this是指针,所以是*this,这样才可以保证原来的a并不改变
memset(b.a,,sizeof(b.a));
for (int i=;i<=;i++) b[i][i]=;
for (;T;a=a*a,T>>=) if (T&) b=b*a;
return b;
}
};
matrix ans;
void work(ll ci,ll chang){
ans[][]=chang;
matrix node;
node[][]=d,node[][]=,node[][]=;
node[][]=c,node[][]=,node[][]=;
node[][]=,node[][]=,node[][]=;
matrix ping=node^ci;
ans=ans*ping;
}
int main(){
int t;
scanf("%d",&t);
for(int p=;p<=t;p++){
cin>>aa>>b>>c>>d>>mo>>n;
if(n==){
cout<<aa;continue;//运算符重载后不要用scanf输入
}
else if(n==){
cout<<b;continue;
}
else{ ans[][]=b,ans[][]=aa;
for(int i=;i<=;i++){
ans[][i]=;ans[][i]=;
}
for(ll i=,j;i<=n;i=j+){
if(mo/i==)break;
j=mo/(mo/i);
if(n<j)j=n;
work(j-i+,mo/i);
}
ll w=;
if(mo>w)w=mo;
if(n>mo)work(n-w,);//一定不要直接用n-mo,如果mo是1会错误,要与2进行大小比较
cout<<ans[][]<<endl;
}
}
return ;
}
再附上一个矩阵快速幂的板子:
struct matrix
{
int n,m;
LL a[maxk][maxk];
LL* operator [](int x) {return a[x];}//这里是*不是&
matrix operator *(matrix b)
{
int i,j,kk;
matrix c;
c.n=n,c.m=b.m;
memset(c.a,,sizeof(c.a));
LL tmp;
for (i=;i<=n;i++) for (j=,tmp=;j<=b.m;c[i][j]=tmp%p,tmp=,j++)
for (kk=;kk<=m;kk++) tmp+=a[i][kk]*b[kk][j];
return c;
}
matrix operator ^(LL T)
{
matrix a=*this,b;//this是指针,所以是*this,这样才可以保证原来的a并不改变
memset(b.a,,sizeof(b.a));
b.n=n,b.m=m;
for (int i=;i<=n;i++) b[i][i]=;
for (;T;a=a*a,T>>=) if (T&) b=b*a;
return b;
}
};
/*
ll* 返回的是指针,也就是 a[x]是一个指针(相当于返回第x行第0列的数值的指针),a[x][y]是一个数值,在外面调用a[x][y]时,相当于(m.a[x])[y]
F1F2Fn===ABC⋅Fn−2+D⋅Fn−1+⌊Pn⌋
[hdu-6395]Sequence 分块+矩阵快速幂的更多相关文章
- HDU 6395 Sequence 【矩阵快速幂 && 暴力】
任意门:http://acm.hdu.edu.cn/showproblem.php?pid=6395 Sequence Time Limit: 4000/2000 MS (Java/Others) ...
- HDU 5667 Sequence(矩阵快速幂)
Problem Description Holion August will eat every thing he has found. Now there are many foods,but he ...
- HDU 5667 Sequence【矩阵快速幂+费马小定理】
题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=5667 题意: Lcomyn 是个很厉害的选手,除了喜欢写17kb+的代码题,偶尔还会写数学题.他找到 ...
- Sequence( 分块+矩阵快速幂 )
题目链接 #include<bits/stdc++.h> using namespace std; #define e exp(1) #define pi acos(-1) #define ...
- 杭电多校第七场 1010 Sequence(除法分块+矩阵快速幂)
Sequence Problem Description Let us define a sequence as below f1=A f2=B fn=C*fn-2+D*fn-1+[p/n] Your ...
- HDU.1575 Tr A ( 矩阵快速幂)
HDU.1575 Tr A ( 矩阵快速幂) 点我挑战题目 题意分析 直接求矩阵A^K的结果,然后计算正对角线,即左上到右下对角线的和,结果模9973后输出即可. 由于此题矩阵直接给出的,题目比较裸. ...
- hdu 3117 Fibonacci Numbers 矩阵快速幂+公式
斐波那契数列后四位可以用快速幂取模(模10000)算出.前四位要用公式推 HDU 3117 Fibonacci Numbers(矩阵快速幂+公式) f(n)=(((1+√5)/2)^n+((1-√5) ...
- HDU - 6395 Sequence (整除分块+矩阵快速幂)
定义数列: $\left\{\begin{eqnarray*} F_1 &=& A \\ F_2 &=& B \\ F_n &=& C\cdot{}F_ ...
- HDU-6395 多校7 Sequence(除法分块+矩阵快速幂)
Sequence Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total ...
随机推荐
- MinGW —— Minimalist GNU for Windows、Cygwin —— Windows 下的类 unix 系统
0. 楔子 Windows 下显然是没有 gcc 编译器的.对于一些软件或者工具如果想要在 Windows 平台下运行,而又需要依赖 gcc 编译其中的一些基于 C/C++ 实现的代码. 此时就借助 ...
- rocksdb源码——性能诊断
该文前三部份介绍 statistics.perf context和iostat context和thread status相关内容.最后介绍ThreadLocalPtr实现的原理. 0. 性能诊断类型 ...
- Ubuntu安装配置Qt 4.86环境
安装 QT4.8.6库+QT Creator 2.4.1 下载地址公布 QT4.8.6库 http://mirrors.hustunique.com/qt/official_releases/qt/ ...
- Linux C lock pages
虚拟内存按页划分,我们可以明确告诉系统:某一个虚拟内存页需要和实际内存帧相关联.这样一来,该内存页就被换进来了,而且不会被系统换出去.这一行为叫做锁页(locking a page). 一般来讲页 ...
- WPF DataGrid自动生成列
<Window x:Class="DataGridExam.MainWindow" xmlns="http://schemas.microsoft.c ...
- Win10中解决Prolific PL2303出现错误代码10的问题
PL2303 是Prolific 公司生产的一种高度集成的RS232-USB接口转换器,在Win10中默认安装的驱动程序会出现错误代码10的问题,如下图所示: 下载Win10上可以用的PL2303驱动 ...
- 自定义View实现图片热区效果
我司主要从事工业物联网领域软件的开发,现有个需求,在外废品处理时需要对产品的不良位置进行标记,点选图片实现图片网格的着色功能. 需求是通过自定义view来实现,实现思路如下: 首先将点击的小方格对象实 ...
- Win10《芒果TV》商店版更新v3.1.4.0:适配Xbox手柄B键后退、手机支持暗色主题不伤眼
在双十一全球剁手节.光棍节欢庆之际,<芒果TV>UWP版迅速更新v3.1.4版,适配Xbox手柄B键全局后退,支持手机切换暗色主题,优化并解决启动卡顿等问题. 芒果TV UWP V3.1. ...
- 【Windows10 IoT开发系列】配置篇
原文:[Windows10 IoT开发系列]配置篇 Windows10 For IoT是Windows 10家族的一个新星,其针对不同平台拥有不同的版本.而其最重要的一个版本是运行在Raspberry ...
- win7 64 下安装MyGeneration 遇到的问题解决方法
win7 64 下安装MyGeneration 遇到的问题 ---------------------------MyGeneration 1.3 Setup-------------------- ...