简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器

这是简易数据分析系列的第 9 篇文章。
今天我们说说 Web Scraper 的一些小功能:自动控制 Web Scraper 抓取数量和 Web Scraper 的父子选择器。
如何只抓取前 100 条数据?
如果跟着上篇教程一步一步做下来,你会发现这个爬虫会一直运作,根本停不下来。网页有 1000 条数据,他就会抓取 1000 条,有 10W 条,就会抓取 10W 条。如果我们的需求很小,只想抓取前 200 条怎么办?
如果你手动关闭抓取数据的网页,就会发现数据全部丢失,一条都没有保存下来,所以说这种暴力的方式不可取。我们目前有两种方式停止 Web Scraper 的抓取。
1.断网大法
当你觉得数据抓的差不多了,直接把电脑的网络断了。网络一断浏览器就加载不了数据,Web Scraper 就会误以为数据抓取完了,然后它会自动停止自动保存。
断网大法简单粗暴,虽不优雅,但是有效。缺点就是你得在旁边盯着,关键点手动操作,不是很智能。
2.通过数据编号控制条数
比如说上篇文章的少数派热门文章爬虫,container 的 Selector 为 dl.article-card,他会抓取网页里所有编号为 dl.article-card 的数据。

我们可以在这个 Selector 后加一个 :nth-of-type(-n+100),表示抓取前 100 条数据,前 200 条就为 :nth-of-type(-n+200),1000 条为 :nth-of-type(-n+1000),以此类推。

这样,我们就可以通过控制数据的编号来控制需要抓取的数据。
抓取链接数据时,页面跳转怎么办?
在上文抓取数据时,可能会遇到一些问题,比如说抓取标题时,标题本身就是个超链接,点击圈选内容后打开了新的网页,干扰我们确定圈选的内容,体验不是很好。
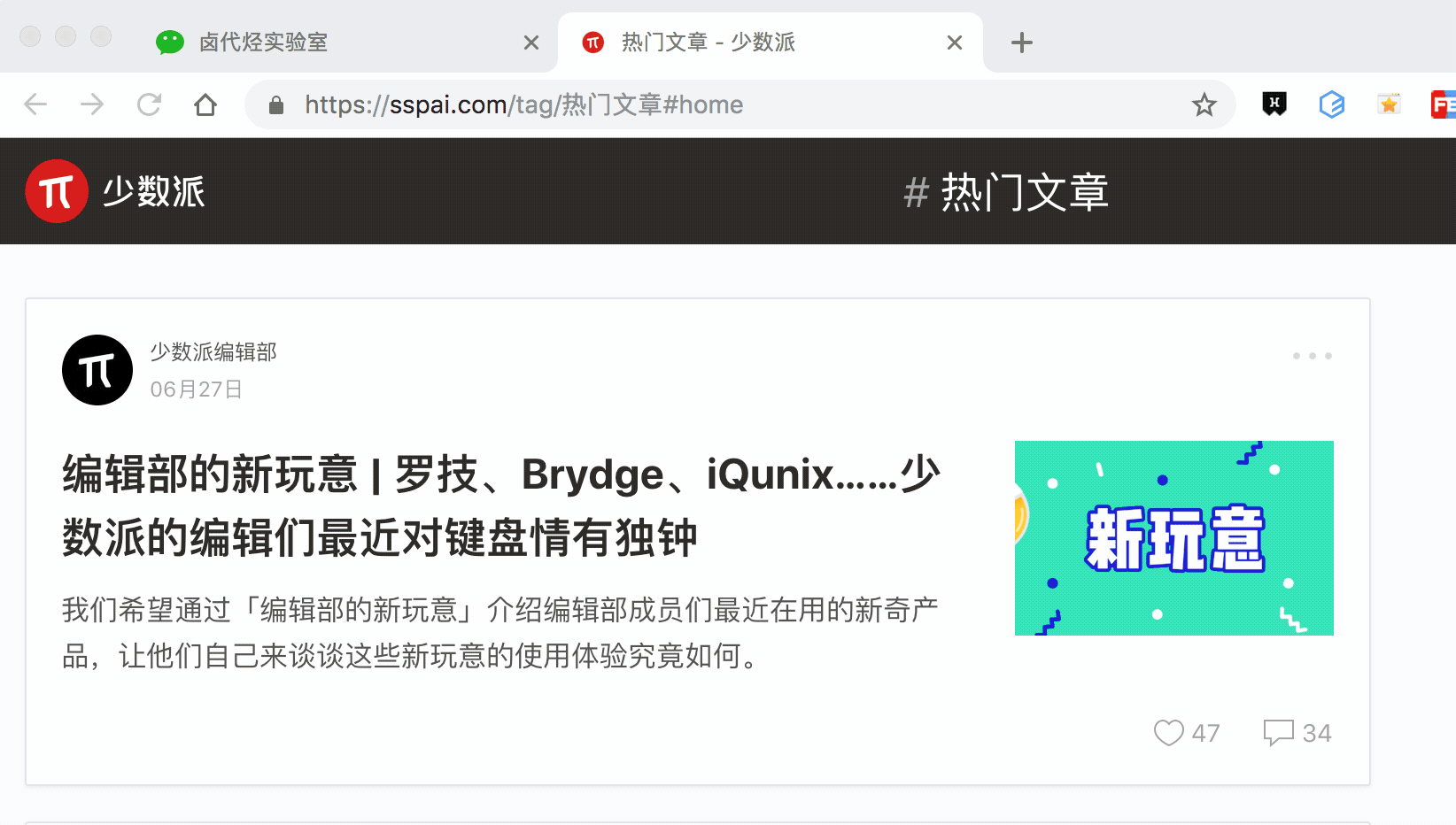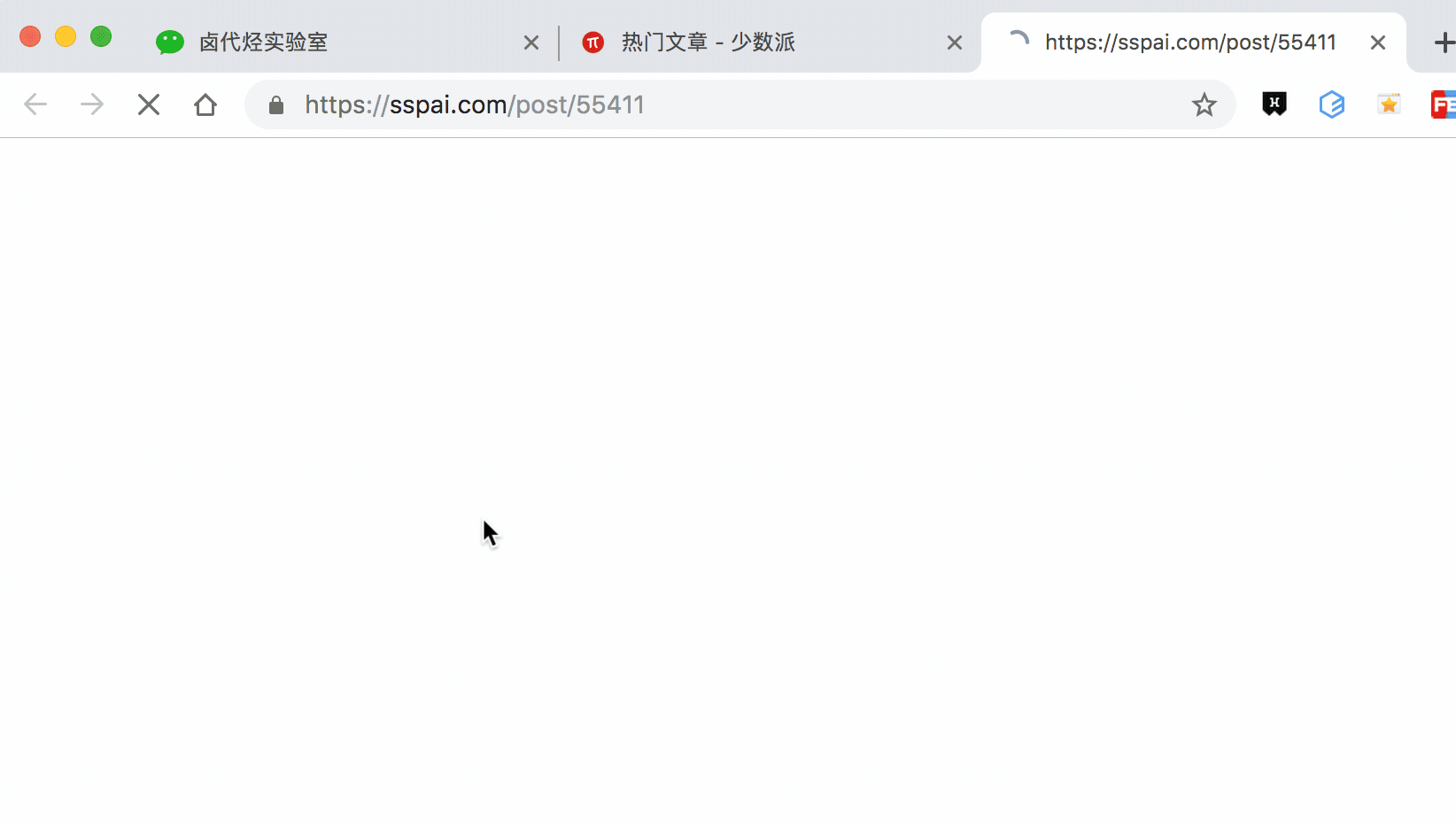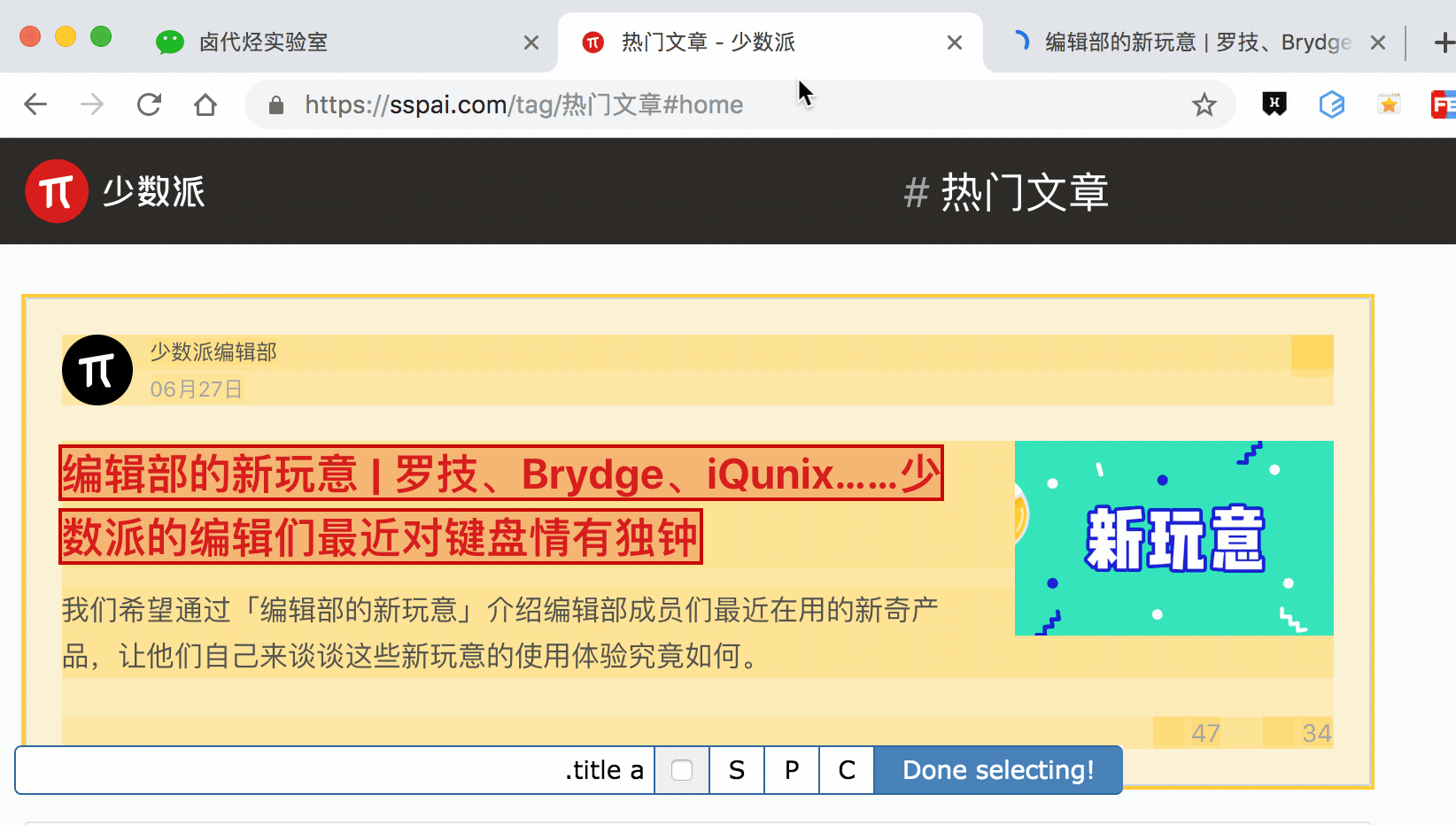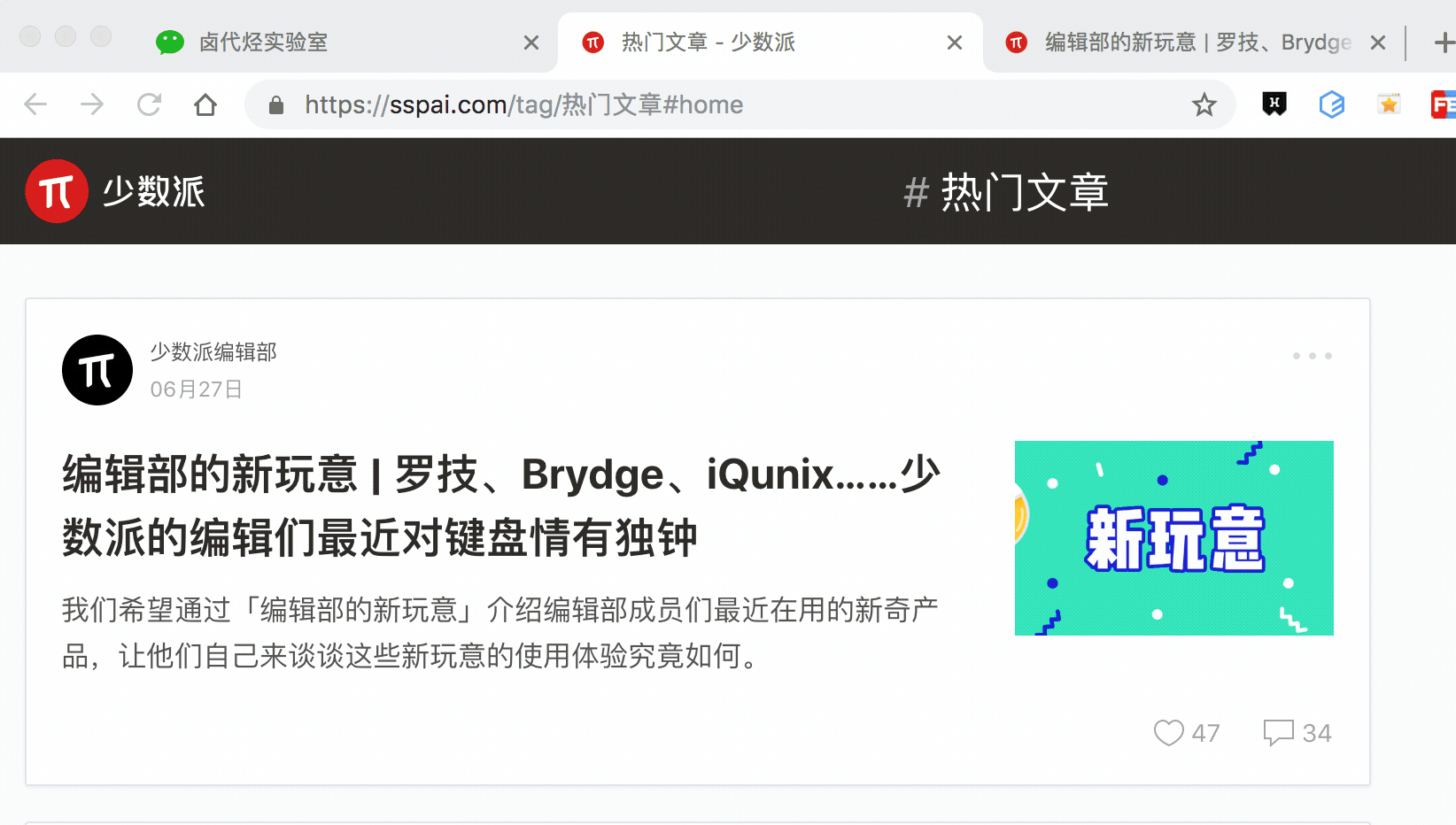
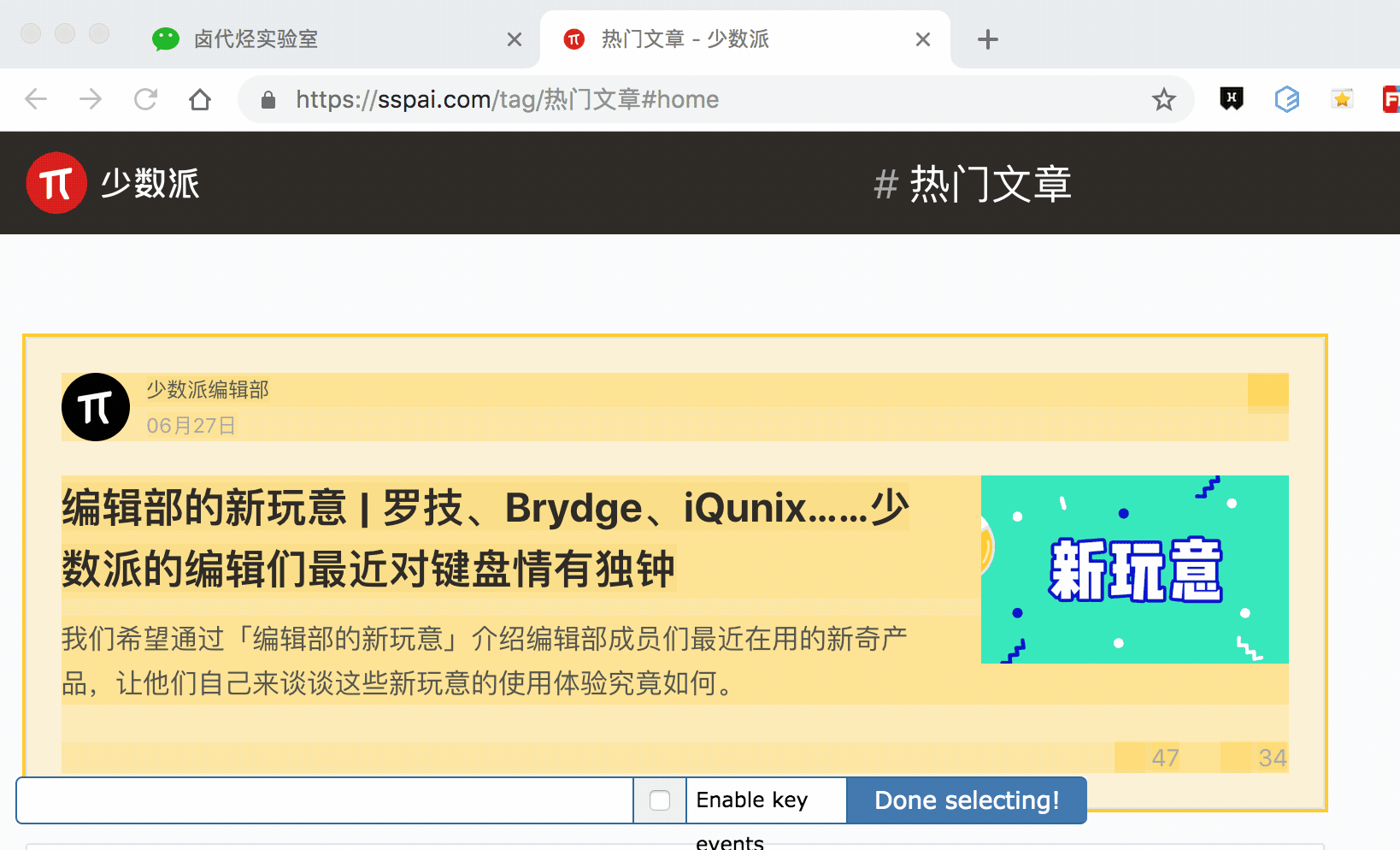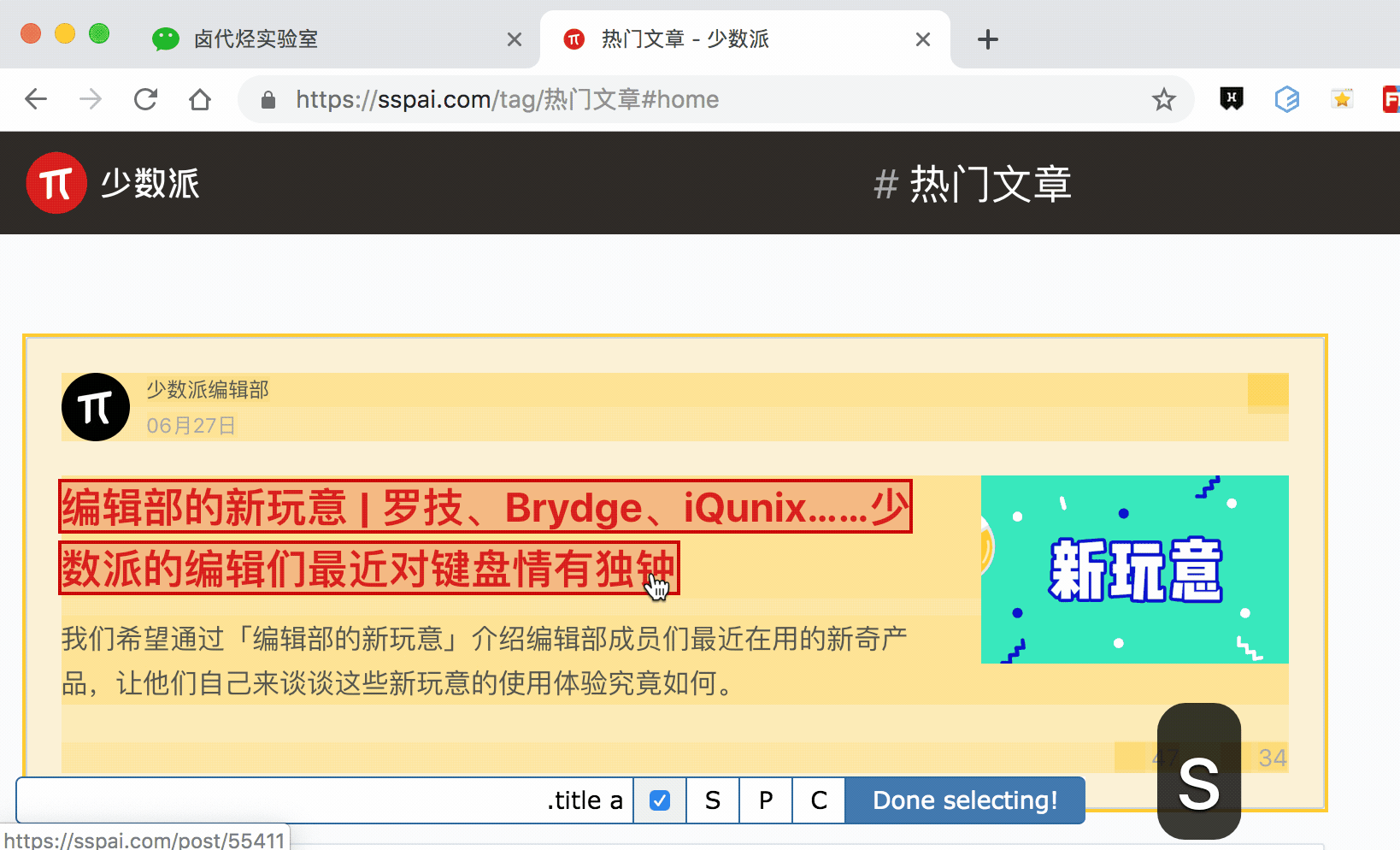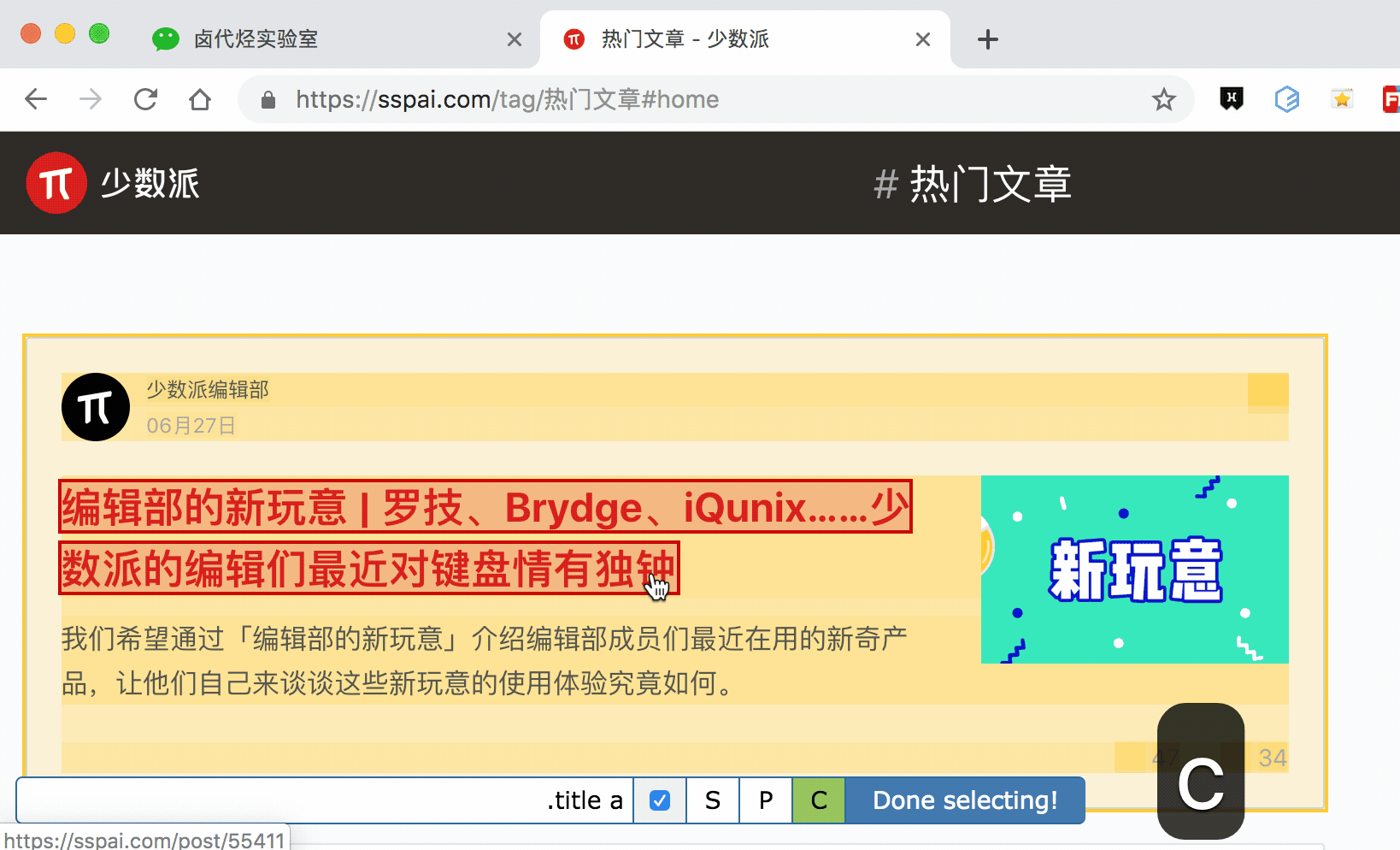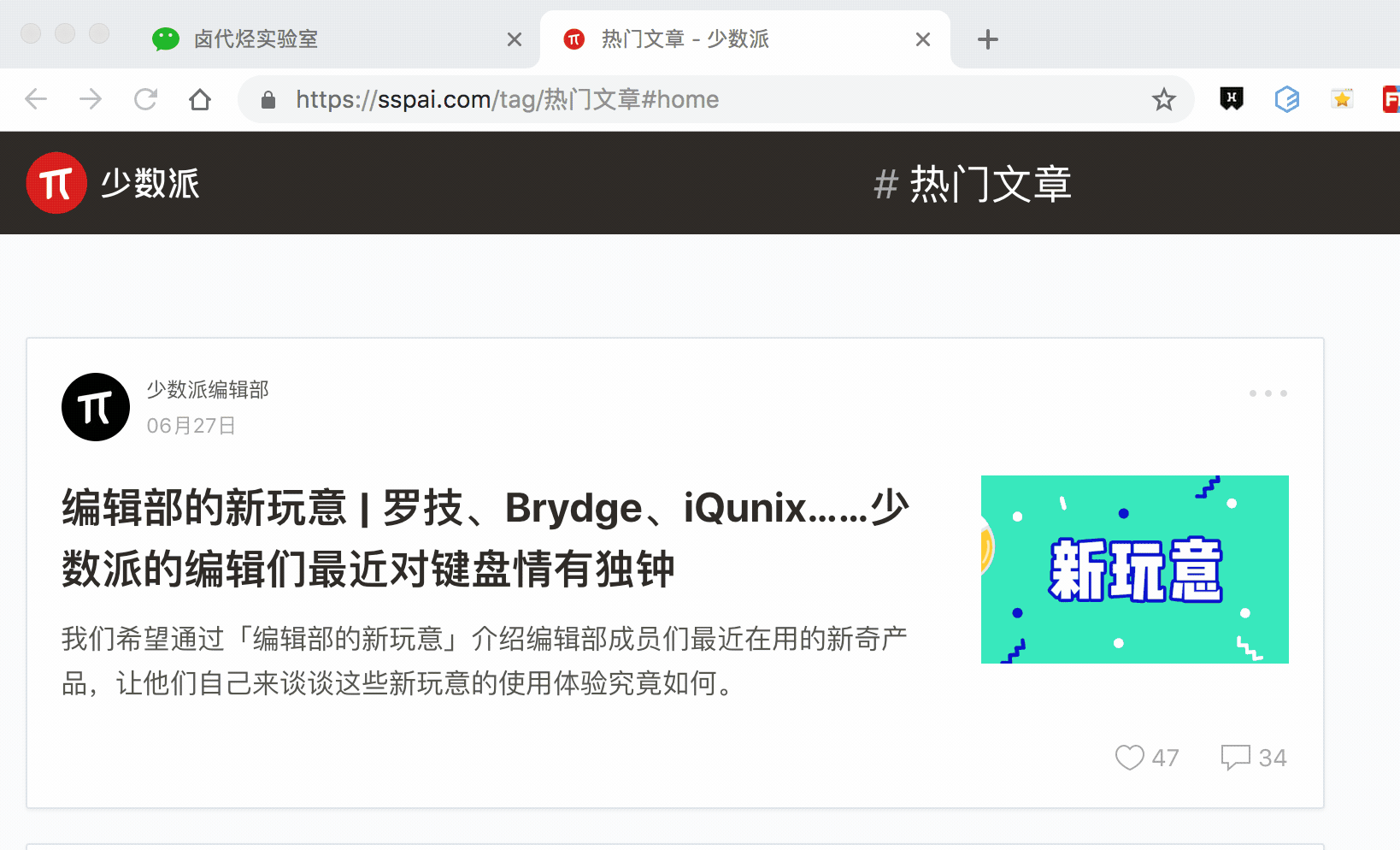
其实 Web scraper 提供了对应的解决方案,那就是通过键盘来选择元素,这样就不会触发点击打开新的网页的问题了。具体的操作面板如下所示,就是我们点击 Done Selecting 的那个控制条。

我们把单选按钮选择后,会出现 S ,P, C 三个字符,意思分别如下:

S:Select,按下键盘的 S 键,选择选中的元素
P:Parent,按下键盘的 P 键,选择选中元素的父节点
C:Child,按下键盘的 C 键,选择选中元素的子节点
我们分别演示一下,首先是通过 S 键选择标题节点:
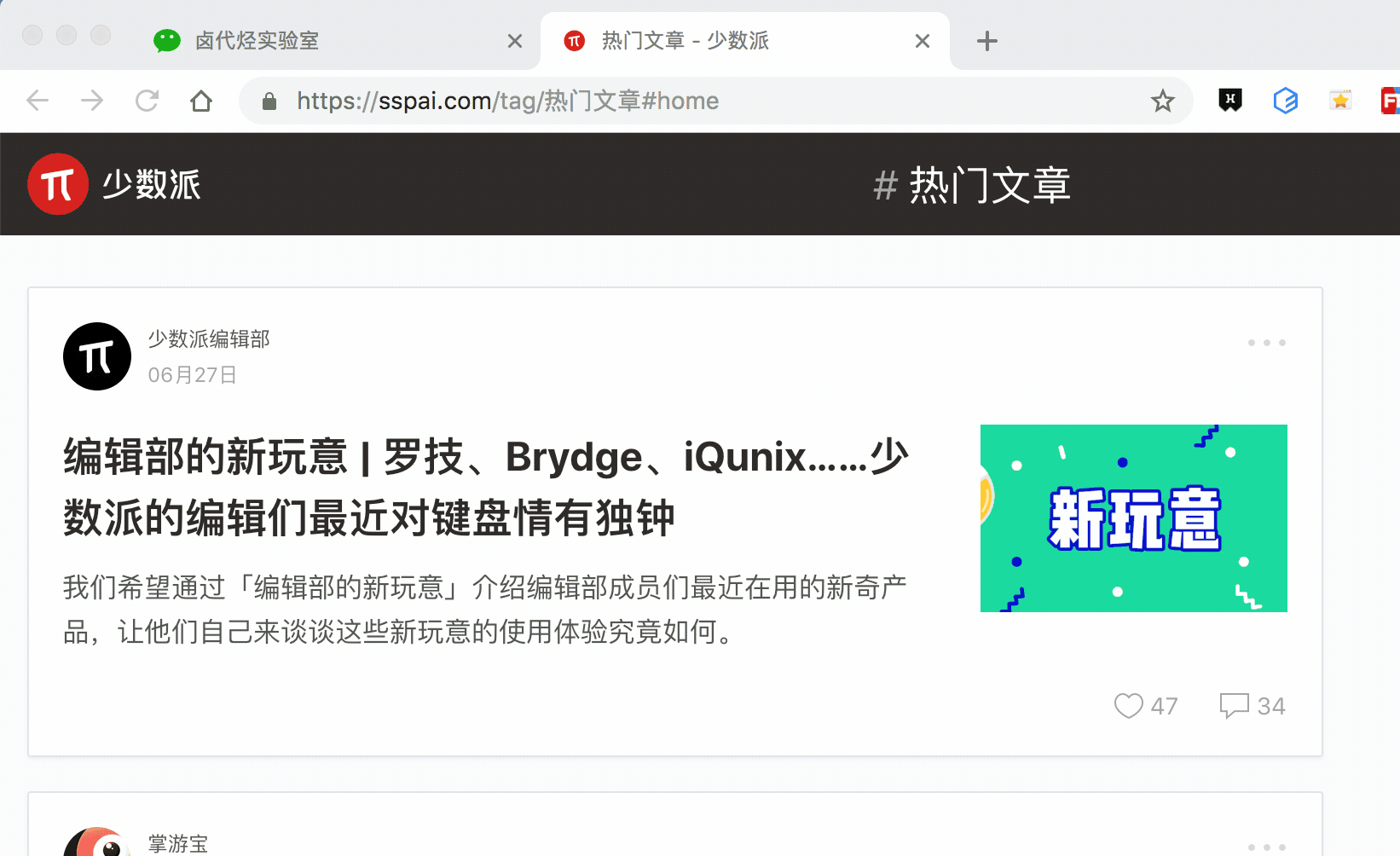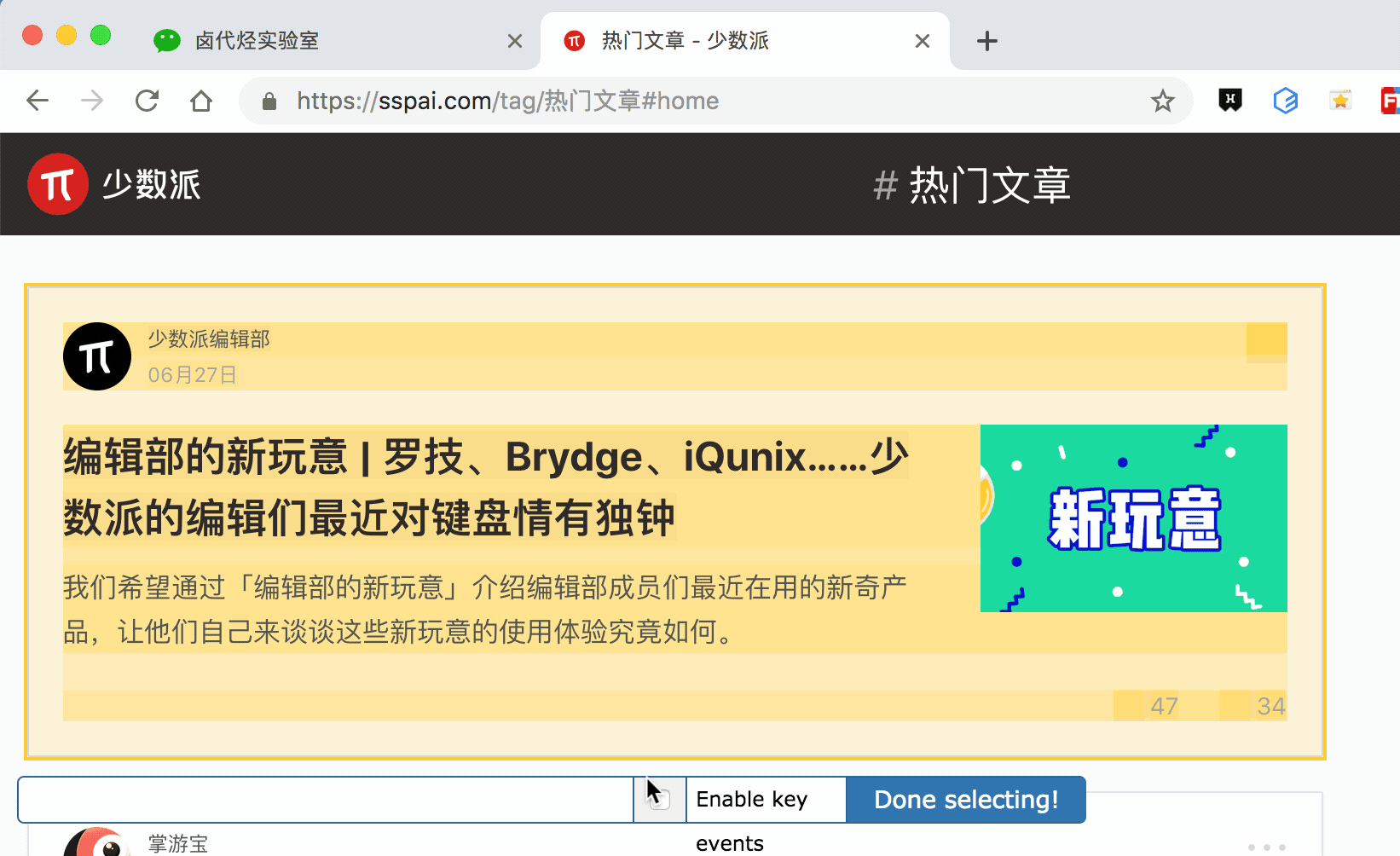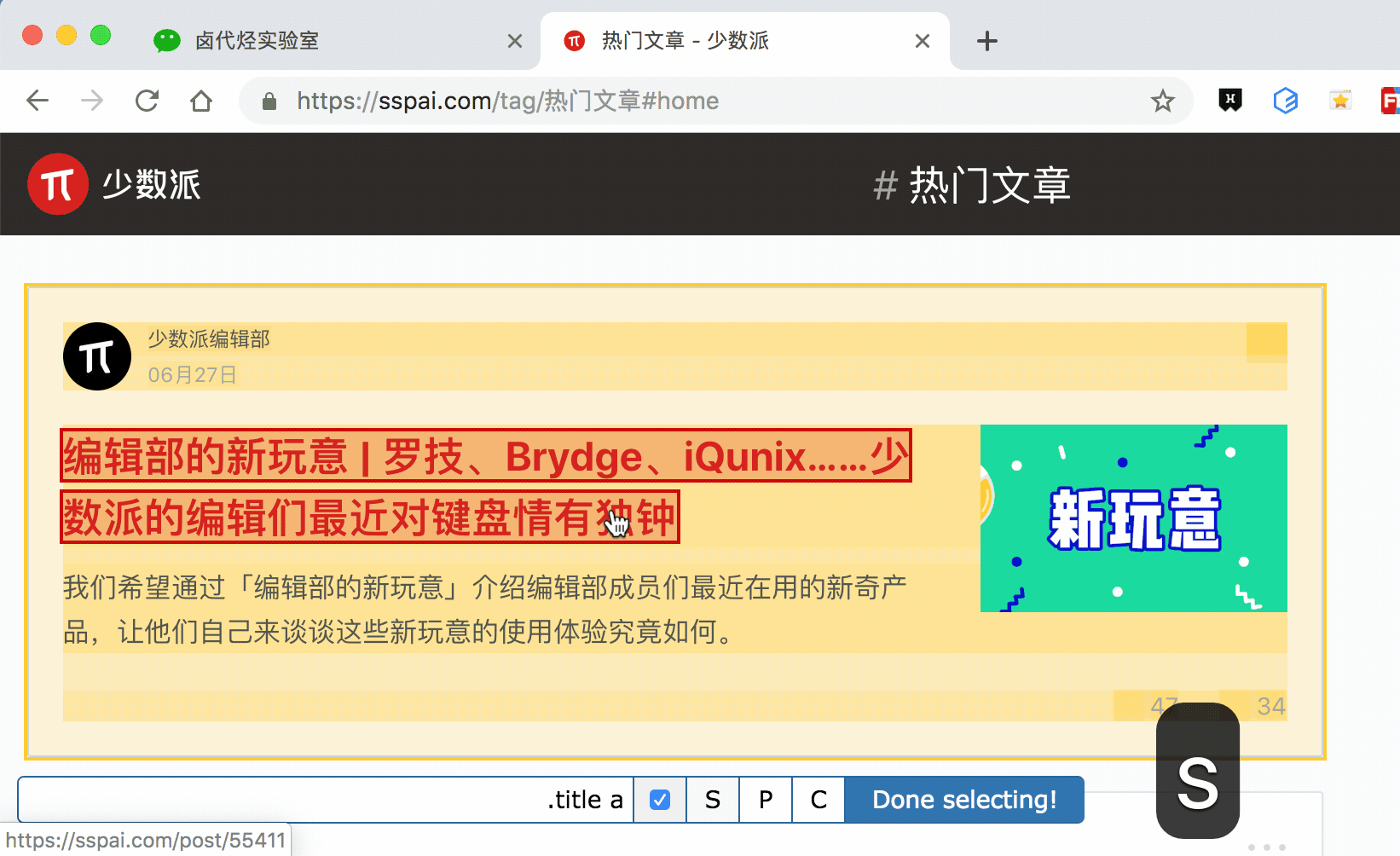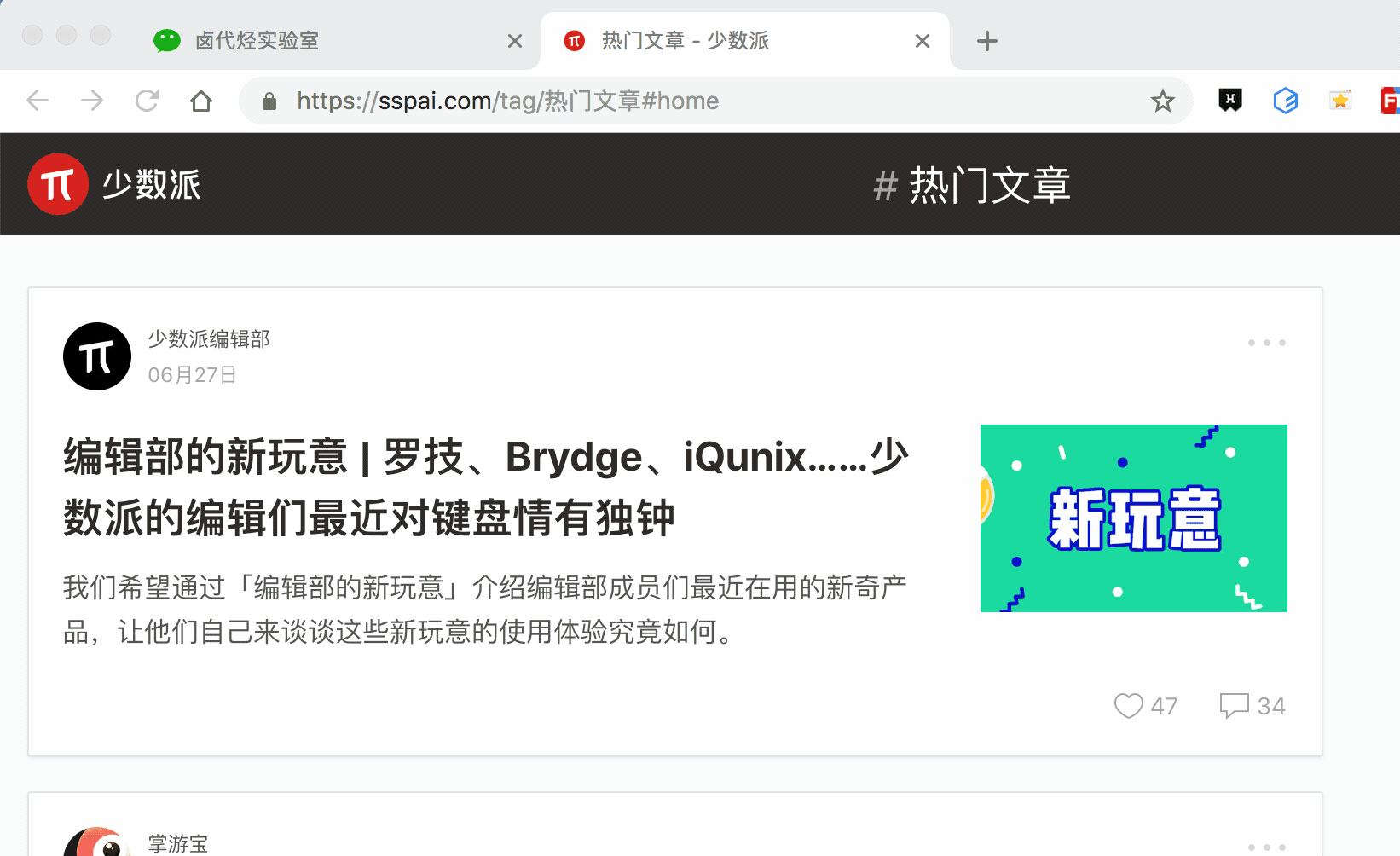
我们对比上个动图,会发现节点选中变红的同时,并没有打开新的网页。
如何抓取选中元素的父节点 or 子节点?
通过 P 键和 C 键选择父节点和子节点:
按压 P 键后,我们可以明显看到我们选择的区域大了一圈,再按 C 键后,选择区域又小了一圈,这个就是父子选择器的功能。
这期介绍了 Web Scraper 的两个使用小技巧,下期我们说说 Web Scraper 如何抓取无限滚动的网页。
推荐阅读:
简易数据分析 08 | Web Scraper 翻页——点击「更多按钮」翻页
简易数据分析 09 | Web Scraper 自动控制抓取数量 & Web Scraper 父子选择器的更多相关文章
- 联系我们_鲲鹏Web数据抓取 - 专业Web数据采集服务提供者
联系我们_鲲鹏Web数据抓取 - 专业Web数据采集服务提供者 首页 > 联系我们 我们的联系方式如下: 029 - 82542052(陕西 西安) 13389148466 或 13571845 ...
- selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例 这种方式抓百度的搜索关键字结果非常容易抓长尾关键词,根据热门关键词去抓更多内容可以用抓google,百度的这种内容容易给屏蔽,用这 ...
- C#实现通过程序自动抓取远程Web网页信息的代码
http://www.jb51.net/article/9499.htm 通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析系统在 ...
- Web网页数据抓取(C/S)
通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析系统在根据得到的数据进行数据分析.为业务提供参考数据. 为了完成以上的需求,我们 ...
- C#抓取远程Web网页信息的代码
来自:http://www.jb51.net/article/9499.htm 通过程序自动的读取其它网站网页显示的信息,类似于爬虫程序.比方说我们有一个系统,要提取BaiDu网站上歌曲搜索排名.分析 ...
- delphi 用idhttp做web页面数据抓取 注意事项
这里不讨论webbrowse方式了 .直接采用indy的 idhttp Get post 可以很方便的获取网页数据. 但如果要抓取大量数据 程序稳定运行不崩溃就不那么容易了.这几年也做了不少类似工具 ...
- 图片抓取器web + winform
原文发布时间为:2009-11-21 -- 来源于本人的百度文章 [由搬家工具导入] 请先学习:http://hi.baidu.com/handboy/blog/item/bfef61000a67ea ...
- 网页抓取解析,使用JQuery选择器进行网页解析
最近开发一个小功能,数据库中一个基础表的数据从另一个网站采集. 因为网站的数据不定时更新,需要更新后自动采集最新的内容. 怎么判断更新数据没有? 好在网站有一个更新日志提示的地方,只需要对比本地保留的 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
随机推荐
- code forces 1173 C. Nauuo and Cards
本文链接:https://www.cnblogs.com/blowhail/p/10990833.html Nauuo and Cards 原题链接:http://codeforces.com/con ...
- 004-python-列表、元组、字典
1. 什么是列表 列表是一个可变的数据类型 列表由[]来表示, 每一项元素使用逗号隔开. 列表什么都能装. 能装对象的对象. 列表可以装大量的数据 2. 列表的索引和切片 列表和字符串一样. 也有索引 ...
- django基础知识之POST属性:
POST属性 QueryDict类型的对象 包含post请求方式的所有参数 与form表单中的控件对应 问:表单中哪些控件会被提交? 答:控件要有name属性,则name属性的值为键,value属性的 ...
- Excel中RATE函数的Java实现
public class RATE { /** * calculateRate:类excel中的RATE函数,计算结果值为月利率,年华利率 需*12期. <br/> * rate = ca ...
- 百度小程序自定义通用toast组件
百度小程序Toast组件 author: @TiffanysBear 百度小程序自定义通用toast组件 BdToast百度小程序自定义通用组件-github地址 需求 手百小程序的toast仅支持在 ...
- java调用新浪接口根据Ip查询所属地区
import java.io.BufferedReader; import java.io.InputStream; import java.io.InputStreamReader; import ...
- centos 安装Python3 及对应的pip
安装Python3安装Python依赖:yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqli ...
- C语言调用VIX_API开关虚拟机
#include <stdio.h> #include <stdlib.h> #include "vix.h" #define USE_WORKSTATIO ...
- Excel催化剂开源第1波-自定义函数的源代码全公开
Excel催化剂插件从2018年1月1日开始运营,到今天刚好一周年,在过去一年时间里,感谢社区里的许多友人们的关心和鼓励,得以坚持下来,并收获一定的用户量和粉丝数和少量的经济收入回报和个人知名度的提升 ...
- YOLO V1损失函数理解
YOLO V1损失函数理解: 首先是理论部分,YOLO网络的实现这里就不赘述,这里主要解析YOLO损失函数这一部分. 损失函数分为三个部分: 代表cell中含有真实物体的中心. pr(object) ...