通过ZipKin整理调用链路
缘由
思路
Zipkin的相关了解
一、Zipkin的由来
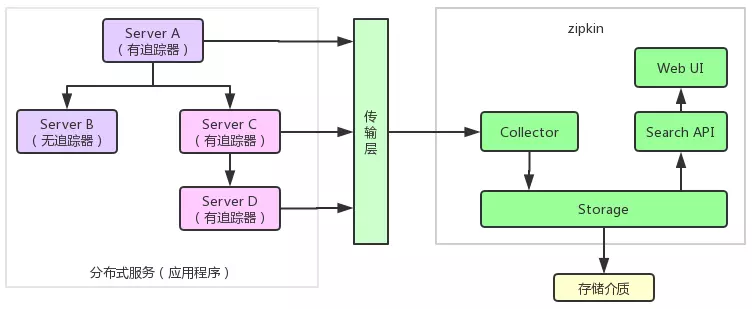
二、什么是ZipKin

curl http://localhost:9411/api/v2/trace/2e0d4019eb7aae31
curl http://localhost:9411/api/v2/services
[
{
"traceId": "string", // 追踪链路ID
"name": "string", // span名称,一般为方法名称
"parentId": "string", // 调用者ID
"id": "string", // spanID
"kind": "CLIENT", // 替代zipkin v1的注解中的四个核心状态,详细介绍见下文
"timestamp": , // 时间戳,调用时间
"duration": , // 持续时间-调用的服务所消耗的时间
"debug": true,
"shared": true,
"localEndpoint": { // 本地网络节点上下文
"serviceName": "string",
"ipv4": "string",
"ipv6": "string",
"port":
},
"remoteEndpoint": { // 远端网络节点上下文
"serviceName": "string",
"ipv4": "string",
"ipv6": "string",
"port":
},
"annotations": [ // value通常是缩写代码,对应的时间戳表示代码标记事件的时间
{
"timestamp": ,
"value": "string"
}
],
"tags": { // span的上下文信息,比如:http.method、http.path
"additionalProp1": "string",
"additionalProp2": "string",
"additionalProp3": "string"
}
}
]

cqlsh 172.10.0.5
cqlsh> describe keyspaces;
cqlsh> use zipkin2;
cqlsh> describe tables;
#查询前得对查询列建立索引
cqlsh:zipkin2> create index on span(trace_id);
cqlsh:zipkin2> select * from trace_by_service_span where trace_id='f81a638649326474';
通过ZipKin整理调用链路的更多相关文章
- spring cloud 入门系列八:使用spring cloud sleuth整合zipkin进行服务链路追踪
好久没有写博客了,主要是最近有些忙,今天忙里偷闲来一篇. =======我是华丽的分割线========== 微服务架构是一种分布式架构,微服务系统按照业务划分服务单元,一个微服务往往会有很多个服务单 ...
- Net和Java基于zipkin的全链路追踪
在各大厂分布式链路跟踪系统架构对比 中已经介绍了几大框架的对比,如果想用免费的可以用zipkin和pinpoint还有一个忘了介绍:SkyWalking,具体介绍可参考:https://github. ...
- Zipkin — 微服务链路跟踪.
一.Zipkin 介绍 Zipkin 是什么? Zipkin的官方介绍:https://zipkin.apache.org/ Zipkin是一款开源的分布式实时数据追踪系统(Distributed ...
- 跟我学SpringCloud | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
SpringCloud系列教程 | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪 Springboot: 2.1.6.RELEASE SpringCloud: ...
- Spring Cloud Sleuth+ZipKin+ELK服务链路追踪(七)
序言 sleuth是spring cloud的分布式跟踪工具,主要记录链路调用数据,本身只支持内存存储,在业务量大的场景下,为拉提升系统性能也可通过http传输数据,也可换做rabbit或者kafka ...
- 个推基于 Zipkin 的分布式链路追踪实践
作者:个推应用平台基础架构高级研发工程师 阿飞 01业务背景 随着微服务架构的流行,系统变得越来越复杂,单体的系统被拆成很多个模块,各个模块通过轻量级的通信协议进行通讯,相互协作,共同实现系统 ...
- net core 微服务框架 Viper 调用链路追踪
1.Viper是什么? Viper 是.NET平台下的Anno微服务框架的一个示例项目.入门简单.安全.稳定.高可用.全平台可监控.底层通讯可以随意切换thrift grpc. 自带服务发现.调用链追 ...
- Springboot+Dubbo使用Zipkin进行接口调用链路追踪
Zipkin介绍: Zipkin是一个分布式链路跟踪系统,可以采集时序数据来协助定位延迟等相关问题.数据可以存储在cassandra,MySQL,ES,mem中.分布式链路跟踪是个老话题,国内也有类似 ...
- zipkin:调用链显示分析
为什么使用了httpclient,客户端没有向zipkin server发送日志? 因为我实在main方法中调用的,完事后这个线程就没了:httpclient用的还是异步的发送日志方式:所以没发日志. ...
随机推荐
- Linux系统调用列表(转)
以下是Linux系统调用的一个列表,包含了大部分常用系统调用和由系统调用派生出的的函数.这可能是你在互联网上所能看到的唯一一篇中文注释的Linux系统调用列表,即使是简单的字母序英文列表,能做到这么完 ...
- change事件同一文件多次选中
最近在做图片上传的时候,碰到了一点问题,那就是选择内容相同,change事件执行不了 网上搜索了答案,使用off('change')好像也不行 最终找到一种解决办法 使用replaceWith重置in ...
- Mysql和Hadoop+Hive有什么关系?
1.Hive不存储数据,Hive需要分析计算的数据,以及计算结果后的数据实际存储在分布式系统上,如HDFS上. 2.Hive某种程度来说也不进行数据计算,只是个解释器,只是将用户需要对数据处理的逻辑, ...
- Jira7.10.1在Windows环境下的安装和配置
jira安装的环境准备 1. jira7.10的运行是依赖java环境的,也就是说需要安装jdk并且要是1.8以上版本: Java -version 2. 还需要为jira创建对应的数据 ...
- MySQL 使用join操作时出现重复数据
使用 group by 'id'' 如:SELECT e.* FROM excel e INNER JOIN task t ON t.eid=e.id where e.id>0 and t. ...
- 两种语言实现设计模式(C++和Java)(二:单例模式)
本篇介绍单例模式,可以说是使用场景最频繁的设计模式了.可以根据实例的生成时间,分为饿汉模式和懒汉模式 懒汉模式:饿了肯定要饥不择食.所以在单例类定义的时候就进行实例化. 饿汉模式:故名思义,不到万不得 ...
- 正则表达式andJS内存空间详细图解
http://www.runoob.com/js/js-regexp.html https://blog.csdn.net/pingfan592/article/details/55189622
- 大数据 - hadoop三台linux虚拟服务器 - 初始化部署
搭建hadoop环境 1.解压Hadoop的安装包,解压到modules文件夹中.(安装包下载地址:http://archive.apache.org/dist/hadoop/core/hadoop- ...
- .Net memory management Learning Notes
Managed Heaps In general it can be categorized into 1) SOH and 2) LOH. size lower than 85K will be ...
- SpringJPA主键生成采用自定义ID,自定义ID采用年月日时间格式
自定义主键生成策略 在entity类上添加注解 @Id @GeneratedValue(strategy = GenerationType.AUTO, generator = "custom ...