基于Filebeat+Kafka+Flink仿天猫双11实时交易额
1. 写在前面
在大数据实时计算方向,天猫双11的实时交易额是最具权威性的,当然技术架构也是相当复杂的,不是本篇博客的简单实现,因为天猫双11的数据是多维度多系统,实时粒度更微小的。当然在技术的总体架构上是相近的,主要的组件都是用到大数据实时计算组件Flink(当然阿里是用了基于Flink深度定制和优化改装的Blink)。下图是天猫双11实时交易额的大体架构模型及数据流向(参照https://baijiahao.baidu.com/s?id=1588506573420812062&wfr=spider&for=pc)
2. 仿天猫双11实时交易额技术架构
利用Linux shell自动化模拟每秒钟产生一条交易额数据,数据内容为用户id,购买商品的付款金额,用户所在城市及所购买的商品

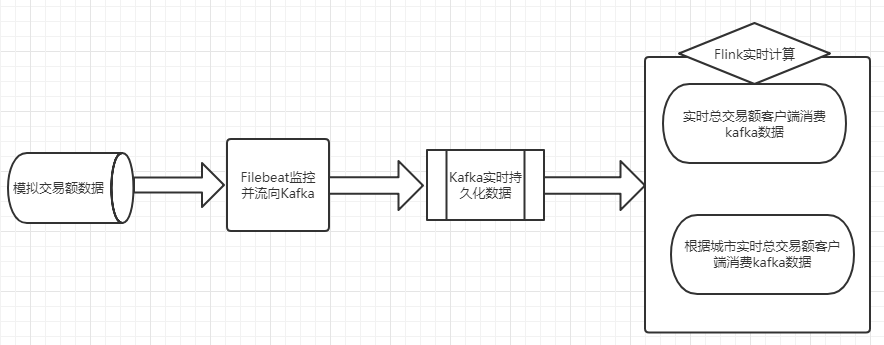
技术架构上利用Filebeat去监控每生产的一条交易额记录,Filebeat将交易额输出到Kafka(关于Filebeat和kafka的安装或应用请参照之前的博客),然后编写Flink客户端程序去实时消费Kafka数据,对数据进行两块计算,一块是统计实时总交易额,一块是统计不同城市的实时交易额
技术架构图
3.具体实现
3.1. 模拟交易额数据double11.sh脚本
#!/bin/bash
i=1
for i in $(seq 1 60)
do
customernum=`openssl rand -base64 8 | cksum | cut -c1-8`
pricenum=`openssl rand -base64 8 | cksum | cut -c1-4`
citynum=`openssl rand -base64 8 | cksum | cut -c1-2`
itemnum=`openssl rand -base64 8 | cksum | cut -c1-6`
echo "customer"$customernum","$pricenum",""city"$citynum",""item"$itemnum >> /home/hadoop/tools/double11/double11.log
sleep 1
done
将double11.sh放入Linux crontab
#每分钟执行一次
* * * * * sh /home/hadoop/tools/double11/double11.sh
3.2. 实时监控double11.log
Filebeat实时监控double11.log产生的每条交易额记录,将记录实时流向到Kafka的topic,这里只需要对Filebeat的beat-kafka.yml做简单配置,kafka只需要启动就好

3.3. 核心:编写Flink客户端程序
这里将统计实时总交易额和不同城市的实时交易额区分写成两个类(只提供Flink Java API)
需要导入的maven依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.0.0</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.8_2.11</artifactId>
<version>1.0.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
</dependencies>
统计实时总交易额代码
package com.fastweb;
import java.util.Properties;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
public class Double11Sum {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.enableCheckpointing(1000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.184.12:9092");
properties.setProperty("zookeeper.connect", "192.168.184.12:2181");
properties.setProperty("group.id", "test");
FlinkKafkaConsumer08<String> myConsumer = new FlinkKafkaConsumer08<String>("test", new SimpleStringSchema(),
properties);
DataStream<String> stream = env.addSource(myConsumer);
DataStream<Tuple2<String, Integer>> counts = stream.flatMap(new LineSplitter()).keyBy(0).sum(1);
counts.print();
env.execute("Double 11 Real Time Transaction Volume");
}
//统计总的实时交易额
public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
JSONObject object = JSONObject.parseObject(value);
String message = object.getString("message");
Integer price = Integer.parseInt(message.split(",")[1]);
out.collect(new Tuple2<String, Integer>("price", price));
}
}
}
统计不同城市的实时交易额
package com.fastweb;
import java.util.Properties;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.flink.util.Collector;
public class Double11SumByCity {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.enableCheckpointing(1000);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.184.12:9092");
properties.setProperty("zookeeper.connect", "192.168.184.12:2181");
properties.setProperty("group.id", "test");
FlinkKafkaConsumer08<String> myConsumer = new FlinkKafkaConsumer08<String>("test", new SimpleStringSchema(),
properties);
DataStream<String> stream = env.addSource(myConsumer);
DataStream<Tuple2<String, Integer>> cityCounts = stream.flatMap(new CitySplitter()).keyBy(0).sum(1);
cityCounts.print();
env.execute("Double 11 Real Time Transaction Volume");
}
//按城市分类汇总实时交易额
public static final class CitySplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
JSONObject object = JSONObject.parseObject(value);
String message = object.getString("message");
Integer price = Integer.parseInt(message.split(",")[1]);
String city = message.split(",")[2];
out.collect(new Tuple2<String, Integer>(city, price));
}
}
}
代码解释:这里可以方向两个类里面只有flatMap的对数据处理的内部类不同,但两个内部类的结构基本相同,在内部类里面利用fastjson解析了一层获取要得到的数据,这是因为经过Filebeat监控的数据是json格式的,Filebeat这样实现是为了在正式的系统上确保每条数据的来源IP,时间戳等信息
3.4. 验证
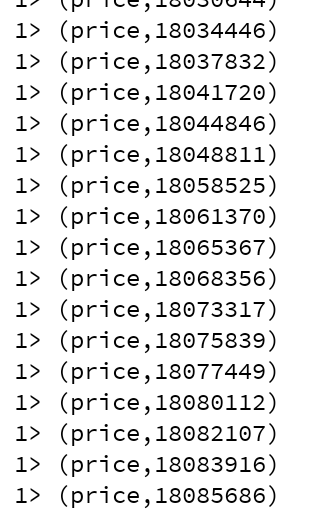
启动Double11Sum类的main方法就可以得到实时的总交易额,按城市分类的实时交易额也一样,这个结果是实时更新的,每条记录都是新的
基于Filebeat+Kafka+Flink仿天猫双11实时交易额的更多相关文章
- 2018天猫双11各类目品牌成交额top10排行榜
2018天猫双11总成交额213,550,497,011元,你知道各类目品牌成交额排行吗?一起来看看吧,赶紧收藏,以后就知道要怎么买了! 相关阅读: 2018天猫双11各类目品牌成交额top10排行榜 ...
- 天猫双11红包前端jQuery
[01] 浏览器支持:IE10+和其他现代浏览器. 效果图: 步骤: HTML部分: <div class="opacity" style=&qu ...
- 我们知道CDN护航了双11十年,却不知道背后有那么多故事……
情不知如何而起,竟一往情深.恰如我们.十年前,因为相信,所以看见.十年后,就在眼前,看见一切. 当2018天猫双11成交额2135亿元的大屏上,打出这么一段字的时候,参与双11护航的阿里云CDN技术掌 ...
- 2684亿!阿里CTO张建锋:不是任何一朵云都撑得住双11
2019天猫双11 成交额2684亿! "不是任何一朵云都能撑住这个流量.中国有两朵云,一朵是阿里云,一朵叫其他云."11月11日晚,阿里巴巴集团CTO张建锋表示,"阿里 ...
- 欠了好久的CRM帖子,双11来读。
又一年双11了,觉得天猫双11越来越没特色了. 从折扣,音符旋律到红包,今年15年却找不出往年的热度,只是商家还是一样的急,备着活动目标计划,做着库存价格打标视觉设计这种苦逼的日子. 欠了好久的CRM ...
- 深入探访支付宝双11十年路,技术凿穿焦虑与想象极限 | CYZONE特写
小蚂蚁说: 双11十年间,交易规模的指数级增长不断挑战人们的想象力,而对蚂蚁技术团队来说,这不仅是一场消费盛宴,而是无数次濒临压力和焦虑极限的体验,更是技术的练兵场.如今双11对蚂蚁金服而言,已经绝不 ...
- 最强CP!阿里云联手支付宝小程序如何助力双11?
作为首次“全面上云”的双11,阿里云征服了每秒订单峰值54.4万笔的世界新记录.正是在阿里云的保驾护航下,即使访问量是平时的5到6倍,小程序也鲜少出现卡顿或者宕机的现象,“依靠阿里云,我们整个天猫双1 ...
- 不仅仅是双11大屏—Flink应用场景介绍
双11大屏 每年天猫双十一购物节,都会有一块巨大的实时作战大屏,展现当前的销售情况. 这种炫酷的页面背后,其实有着非常强大的技术支撑,而这种场景其实就是实时报表分析. 实时报表分析是近年来很多公司采用 ...
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台(elk5.2+filebeat2.11)
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台 参考:http://www.tuicool.com/articles/R77fieA 我在做ELK日志平台开始之初选择为 ...
随机推荐
- 「雅礼集训 2017 Day5」珠宝
题目描述 Miranda 准备去市里最有名的珠宝展览会,展览会有可以购买珠宝,但可惜的是只能现金支付,Miranda 十分纠结究竟要带多少的现金,假如现金带多了,就会比较危险,假如带少了,看到想买的右 ...
- 如何查看Linux命令的源代码
首先要在系统设置-->软件和更新-->Ubuntu软件中勾选源代码选项,否则在下载source时会报如下错: E:您必须在sources.list中指定源代码(deb-src)URI 然后 ...
- 如何隐藏overflow: scroll的滚动条
css3有一个直接调用的css,保证隐藏滚动条的同时还可以继续通过滚轮向下翻 ::-webkit-scrollbar { /*隐藏滚轮*/ display: none; } 但是仅限于支持css3的浏 ...
- mysql 在visual studio中的配置
视图-->其他窗口-->服务器资源管理器-->数据连接-->右键添加连接 servername:localhost username:root password:123456 ...
- Java基础 -- 字符串(格式化输出、正则表达式)
一 字符串 1.不可变String String对象是不可变的,查看JDK文档你就会发现,String类中每一个看起来会修改String值的方法,实际上都是创建一个全新的String对象,以包含修改后 ...
- (贪心 字符串 打好基础)51nod 1182完美字符串
约翰认为字符串的完美度等于它里面所有字母的完美度之和.每个字母的完美度可以由你来分配,不同字母的完美度不同,分别对应一个1-26之间的整数. 约翰不在乎字母大小写(也就是说字母A和a的完美度相同).给 ...
- 我的mybatis从oracle迁移转换mysql的差异【原】
仅此作为笔记 分页差异 oracle <select id="select" parameterClass="java.util.Map" resultC ...
- 《Unbroken》
<Unbroken> 献给正在奋力向前的你 You can’t connect the dots looking forward, you can only connect them lo ...
- 【转】Redis学习笔记(四)如何用Redis实现分布式锁(1)—— 单机版
原文地址:http://bridgeforyou.cn/2018/09/01/Redis-Dsitributed-Lock-1/ 为什么要使用分布式锁 这个问题,可以分为两个问题来回答: 为什么要使用 ...
- Arrays和String单元测试 20175301
要求 在IDEA中以TDD的方式对String类和Arrays类进行学习 一.String类相关方法的单元测试 1.ChatAt的测试 代码: import org.junit.Test; impor ...