hive -- 自定义函数和Transform
hive -- 自定义函数和Transform
UDF操作单行数据,
UDAF:聚合函数,接受多行数据,并产生一个输出数据行
UDTF:操作单个数据
使用udf方法:
第一种:
add jar xxx.jar
cteate temporary function 方法名;
注销一个jar方法:drop temporay function 方法名;
第二种:写一个脚本
vi cat hive_init
add jar /home/data/xxx.jar
create temporary fucntion 方法名 as '类的全限定名'
hive -i hive_init
第三种:
自定义UDF注册为hive的内置函数
自定义函数:(UDF)
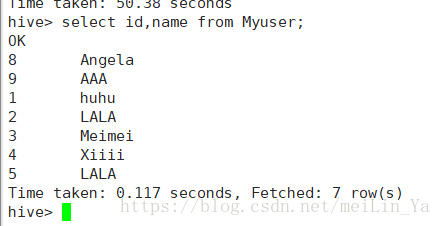
数据:
package UDF;
import java.util.HashMap;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
*
* @author huhu_k
*
*/
public class ToLowerCase extends UDF {
public static HashMap<String, String> provinceMap = new HashMap<>();
static {
provinceMap.put("136", "beijing");
provinceMap.put("137", "shanghai");
provinceMap.put("138", "shenzhen");
}
// 必须是public
public String evaluate(String field) {
String lowerCase = field.toLowerCase();
return lowerCase;
}
// 必须是public
public String evaluate(int field) {
String pn = String.valueOf(field);
return provinceMap.get(pn.substring(0, 3)) == null ? "huoxing" : provinceMap.get(pn.substring(0, 3));
}
}1.将name大写变为小写:
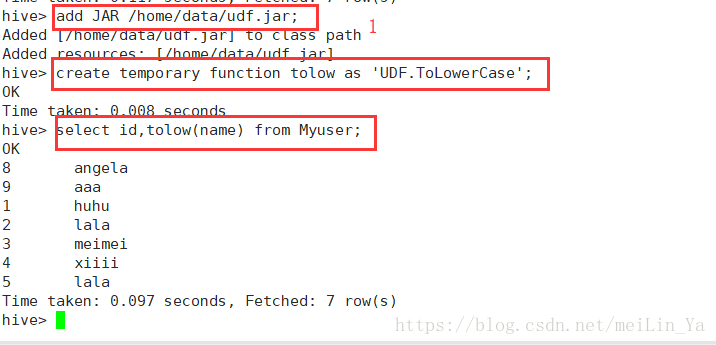
2.数据:

通过手机号获取手机地址:
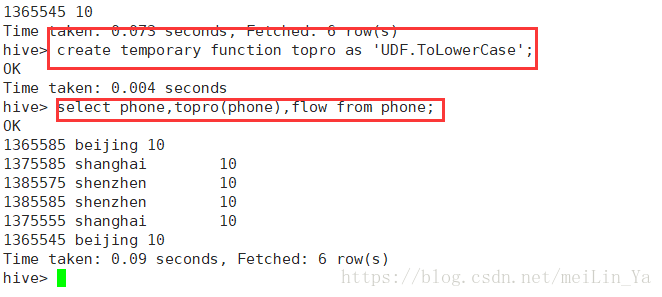
当你在一个类中再次写了方法时,再次导入jar时,要先推出hive,然后在进入hive,然后进行add JAR XXXXX;
3.数据:
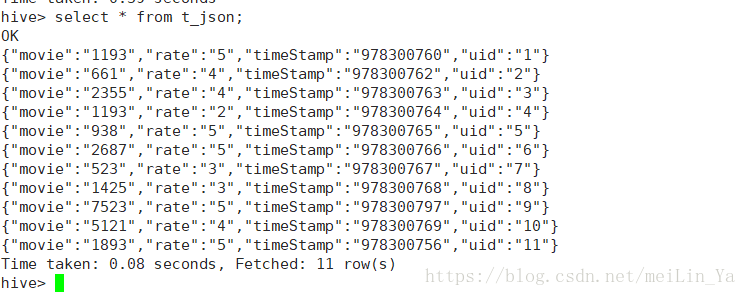
使用json数据
package UDF;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.codehaus.jackson.map.ObjectMapper;
public class JsonParser extends UDF {
public String evaluate(String json) {
ObjectMapper objectMapper = new ObjectMapper();
try {
Moive readValue = objectMapper.readValue(json, Moive.class);
return readValue.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
package UDF;
public class Moive {
private String movie;
private String rate;
private String timeStamp;
private String uid;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public String getRate() {
return rate;
}
public void setRate(String rate) {
this.rate = rate;
}
public String getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(String timeStamp) {
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
@Override
public String toString() {
return movie + "\t" + rate + "\t" + timeStamp + "\t" + uid;
}
}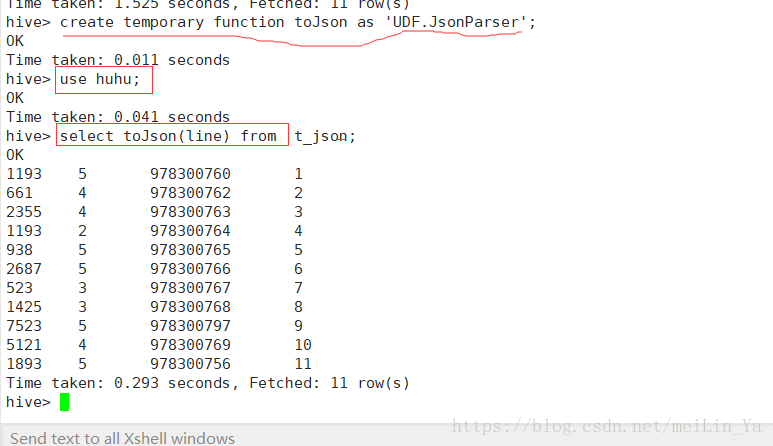
然后将查询出来的数据插入到一张表中
1.使用hive中的自带函数可以解析简单的json数据格式
create table t_json2 as select get_json_object(line,'$.movie')as movie,get_json_object(line,'$.rate')as rate,get_json_object(line,'$.timeStamp')as timeStamps,get_json_object(line,'$.uid')as uid from t_json;
2.使用自定义函数
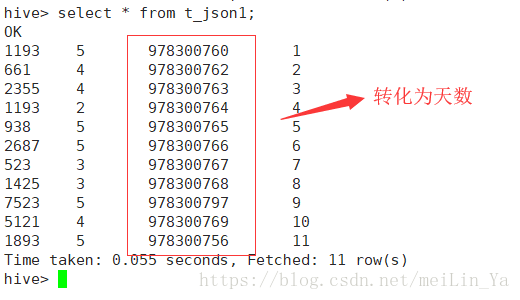
create table t_json1 as select split(toJson(line),'\t')[0]as movieid,split(toJson(line),'\t')[1]as,split(toJson(line),'\t')[2]as timestring,split(toJson(line),'\t')[3]as uid from t_json;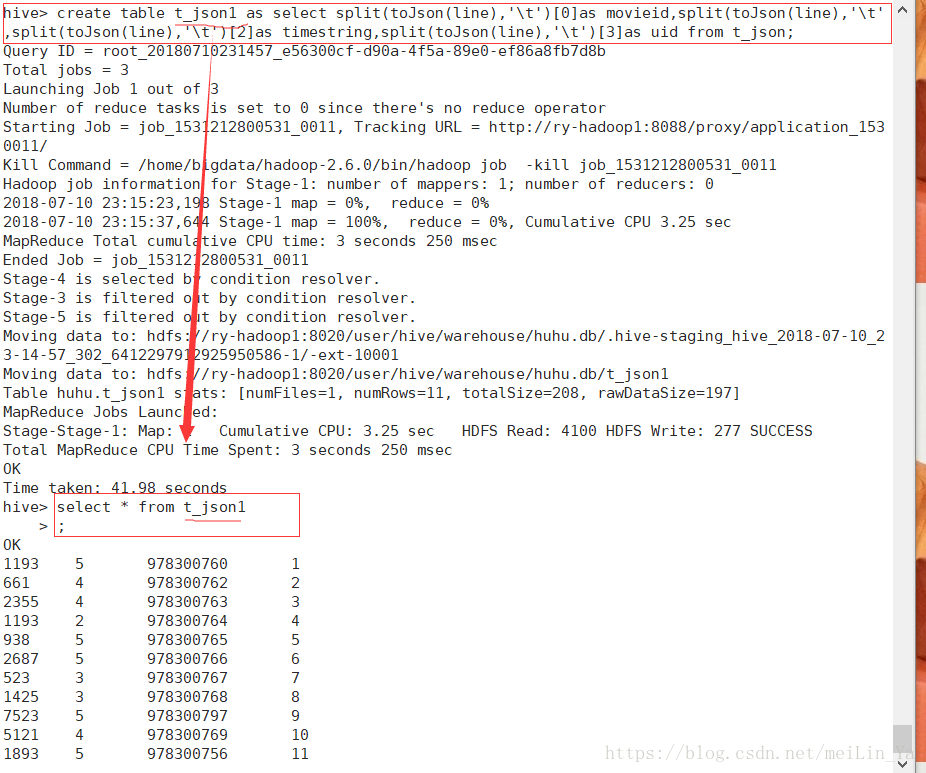
ok!!!
Transform:
Hive的Transform关键字提供了在SQL中调用自写脚本的功能
例子:
先编辑一个python脚本文件
#!/bin/python
import sys
import datetime
for line in sys.stdin:
line = line.strip()
movieid, rating, unixtime,userid = line.split('\t')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([movieid, rating, str(weekday),userid])将文件加入hive的路径classpath
add file /home/data/weekday_mapper.py;创建一个表:
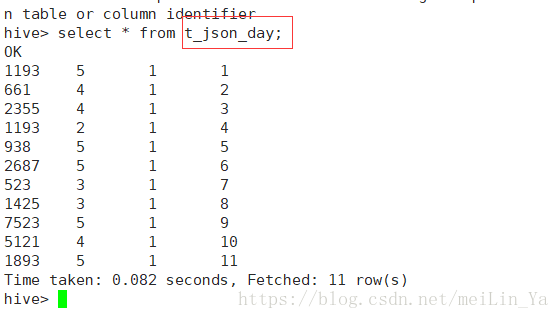
create table t_json_day as select transform (movieid,rate,timestring,uid) using 'python weekday_mapper.py' as (movieid,rate,weekday,uid) from t_json1;
hive -- 自定义函数和Transform的更多相关文章
- Hive自定义函数的学习笔记(1)
前言: hive本身提供了丰富的函数集, 有普通函数(求平方sqrt), 聚合函数(求和sum), 以及表生成函数(explode, json_tuple)等等. 但不是所有的业务需求都能涉及和覆盖到 ...
- hive自定义函数(UDF)
首先什么是UDF,UDF的全称为user-defined function,用户定义函数,为什么有它的存在呢?有的时候 你要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就 ...
- hive自定义函数学习
1介绍 Hive自定义函数包括三种UDF.UDAF.UDTF UDF(User-Defined-Function) 一进一出 UDAF(User- Defined Aggregation Funcat ...
- hive自定义函数UDF UDTF UDAF
Hive 自定义函数 UDF UDTF UDAF 1.UDF:用户定义(普通)函数,只对单行数值产生作用: UDF只能实现一进一出的操作. 定义udf 计算两个数最小值 public class Mi ...
- Hive 自定义函数(转)
Hive是一种构建在Hadoop上的数据仓库,Hive把SQL查询转换为一系列在Hadoop集群中运行的MapReduce作业,是MapReduce更高层次的抽象,不用编写具体的MapReduce方法 ...
- Hive 自定义函数
hive 支持自定义UDF,UDTF,UDAF函数 以自定义UDF为例: 使用一个名为evaluate的方法 package com.hive.custom; import org.apache.ha ...
- hive自定义函数——hive streaming
Hadoop Streaming提供了一个便于进行MapReduce编程的工具包,使用它可以基于一些可执行命令.脚本语言或其他编程语言来实现Mapper和 Reducer,Streaming方式是基于 ...
- Hive 自定义函数 UDF UDAF UDTF
1.UDF:用户定义(普通)函数,只对单行数值产生作用: 继承UDF类,添加方法 evaluate() /** * @function 自定义UDF统计最小值 * @author John * */ ...
- Hadoop之Hive自定义函数的陷阱
A left join B, 这个B会连到A. 如<A1,B>, <A2,B>,在处理第一条记录的时候将B.clear(),则第二条记录的B是[]空的这是自定义UDF函数必须注 ...
随机推荐
- Hadoop HDFS, YARN ,MAPREDUCE,MAPREDUCE ON YARN
HDFS 系统架构图 NameNode 是主节点,存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在的DataNode等.NameNode将 ...
- mac & ip
mac 解决本地网络机器的通信 ip 解决不同网络间主机的通信
- Java面试题整理---Redis篇
1.redis支持五种数据结构类型? 2.redis内部结构? 3.redis持久化机制? 4.redis集群方案与实现? 5.redis为什么是单线程的? 6.redis常见回收 ...
- FREERTOS学习笔记
2012-02-25 21:43:40 为提升自己对实时操作系统(RTOS)的认识,我学习了freeRTOS. 理解了OS任务的状态.优先级的概念.信号量的概念.互斥的概念.队列.内存管理.这都是和R ...
- 【.NET】 C# 时间戳和DataTime 互相转换
1.C# DateTime转换为Unix时间戳 System.DateTime startTime = TimeZone.CurrentTimeZone.ToLocalTime(, , )); // ...
- GPIO8种方式小总结
在输出3时写1时上反向为0,下为1,1时MOS不接通,0接通 为1时上导通输出高电平1: 为0时下导通输出低电平0: VDD为逻辑电源正 VSS为逻辑地 若为输出状态则施密特触发器总为开 然后经过上拉 ...
- Django视图层
本文目录 1 视图函数 2 HttpRequest对象 3 HttpResponse对象 4 JsonResponse 5 CBV和FBV 6 简单文件上传 回到目录 1 视图函数 一个视图函数,简称 ...
- Vue学习——学习vue必须了解的几个知识点
node.js介绍 Node 是一个让 JavaScript 运行在服务端的开发平台,使用JavaScript也可以开发后台服务.说明白些它仅仅是一个平台,我们使用vue开发必须要安装node.js. ...
- Android中粗字体
前言 最近UI大牛出了一版新的效果图,按照IOS的效果做的,页面里面有普通字体.中粗字体.加粗字体.对于IOS的小伙伴,分分钟搞定,但是对于Android开发的我,瞬间懵逼了.WTF! 安卓只有粗和不 ...
- 浅谈JavaScript的函数的call以及apply
我爱撸码,撸码使我感到快乐!大家好,我是Counter.今天就来谈谈js函数的call以及apply,具体以代码举例来讲解吧,例如有函数: function func(a, b) { return a ...