hive -- 自定义函数和Transform
hive -- 自定义函数和Transform
UDF操作单行数据,
UDAF:聚合函数,接受多行数据,并产生一个输出数据行
UDTF:操作单个数据
使用udf方法:
第一种:
add jar xxx.jar
cteate temporary function 方法名;
注销一个jar方法:drop temporay function 方法名;
第二种:写一个脚本
vi cat hive_init
add jar /home/data/xxx.jar
create temporary fucntion 方法名 as '类的全限定名'
hive -i hive_init
第三种:
自定义UDF注册为hive的内置函数
自定义函数:(UDF)
数据:
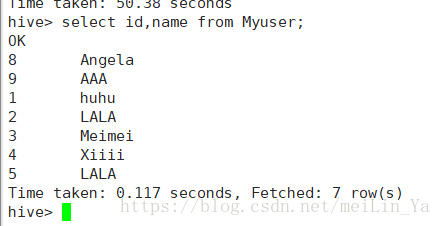
package UDF;
import java.util.HashMap;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
*
* @author huhu_k
*
*/
public class ToLowerCase extends UDF {
public static HashMap<String, String> provinceMap = new HashMap<>();
static {
provinceMap.put("136", "beijing");
provinceMap.put("137", "shanghai");
provinceMap.put("138", "shenzhen");
}
// 必须是public
public String evaluate(String field) {
String lowerCase = field.toLowerCase();
return lowerCase;
}
// 必须是public
public String evaluate(int field) {
String pn = String.valueOf(field);
return provinceMap.get(pn.substring(0, 3)) == null ? "huoxing" : provinceMap.get(pn.substring(0, 3));
}
}1.将name大写变为小写:
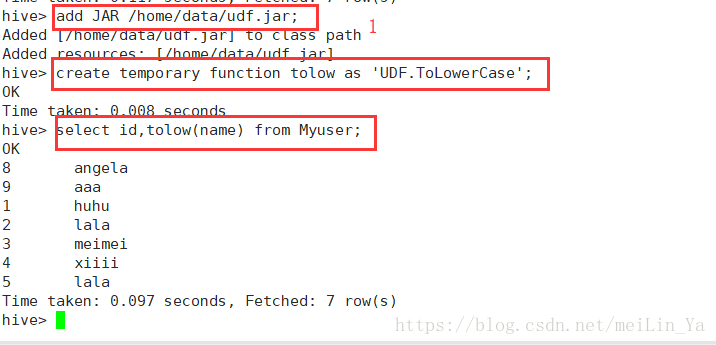
2.数据:

通过手机号获取手机地址:
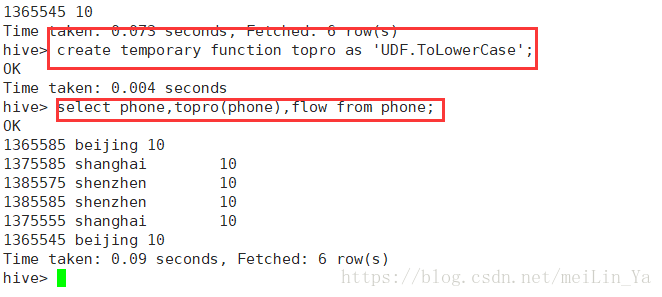
当你在一个类中再次写了方法时,再次导入jar时,要先推出hive,然后在进入hive,然后进行add JAR XXXXX;
3.数据:
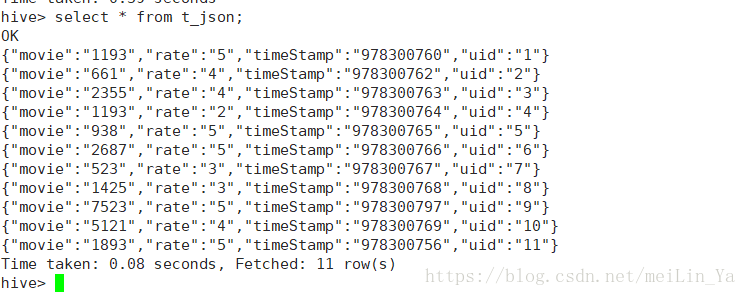
使用json数据
package UDF;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.codehaus.jackson.map.ObjectMapper;
public class JsonParser extends UDF {
public String evaluate(String json) {
ObjectMapper objectMapper = new ObjectMapper();
try {
Moive readValue = objectMapper.readValue(json, Moive.class);
return readValue.toString();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
package UDF;
public class Moive {
private String movie;
private String rate;
private String timeStamp;
private String uid;
public String getMovie() {
return movie;
}
public void setMovie(String movie) {
this.movie = movie;
}
public String getRate() {
return rate;
}
public void setRate(String rate) {
this.rate = rate;
}
public String getTimeStamp() {
return timeStamp;
}
public void setTimeStamp(String timeStamp) {
this.timeStamp = timeStamp;
}
public String getUid() {
return uid;
}
public void setUid(String uid) {
this.uid = uid;
}
@Override
public String toString() {
return movie + "\t" + rate + "\t" + timeStamp + "\t" + uid;
}
}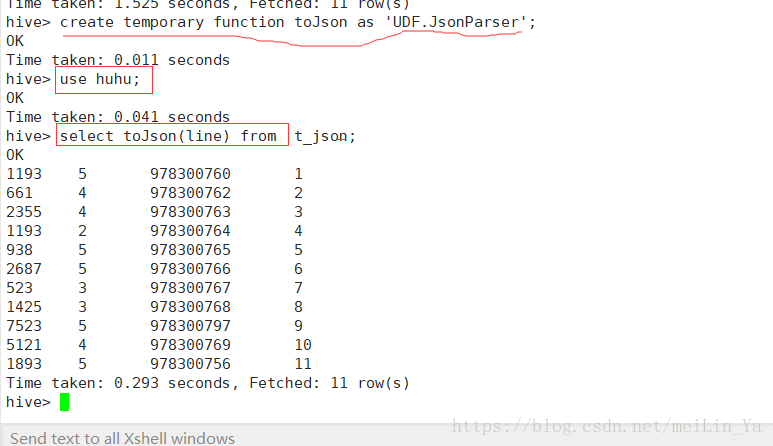
然后将查询出来的数据插入到一张表中
1.使用hive中的自带函数可以解析简单的json数据格式
create table t_json2 as select get_json_object(line,'$.movie')as movie,get_json_object(line,'$.rate')as rate,get_json_object(line,'$.timeStamp')as timeStamps,get_json_object(line,'$.uid')as uid from t_json;
2.使用自定义函数
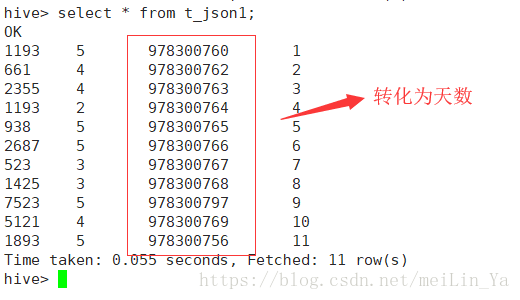
create table t_json1 as select split(toJson(line),'\t')[0]as movieid,split(toJson(line),'\t')[1]as,split(toJson(line),'\t')[2]as timestring,split(toJson(line),'\t')[3]as uid from t_json;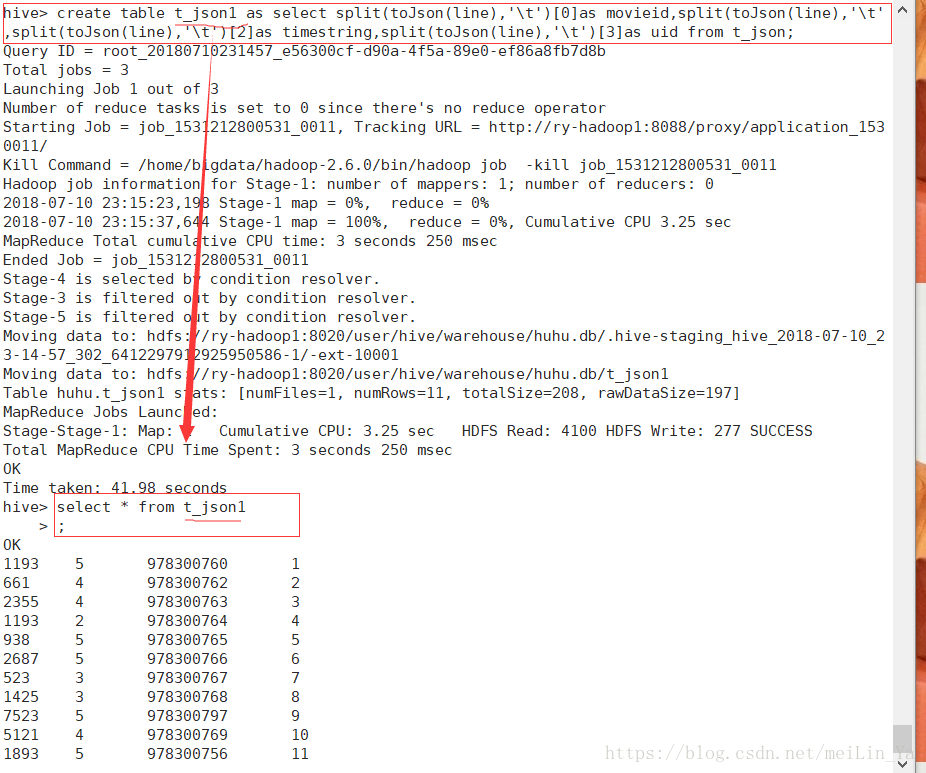
ok!!!
Transform:
Hive的Transform关键字提供了在SQL中调用自写脚本的功能
例子:
先编辑一个python脚本文件
#!/bin/python
import sys
import datetime
for line in sys.stdin:
line = line.strip()
movieid, rating, unixtime,userid = line.split('\t')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([movieid, rating, str(weekday),userid])将文件加入hive的路径classpath
add file /home/data/weekday_mapper.py;创建一个表:
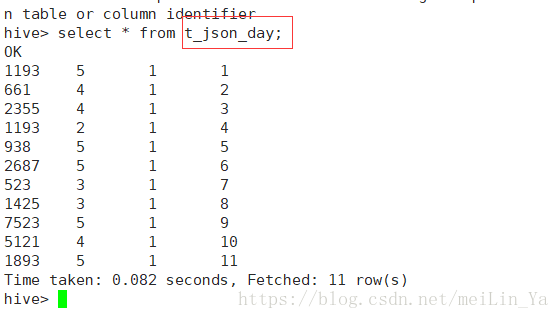
create table t_json_day as select transform (movieid,rate,timestring,uid) using 'python weekday_mapper.py' as (movieid,rate,weekday,uid) from t_json1;
hive -- 自定义函数和Transform的更多相关文章
- Hive自定义函数的学习笔记(1)
前言: hive本身提供了丰富的函数集, 有普通函数(求平方sqrt), 聚合函数(求和sum), 以及表生成函数(explode, json_tuple)等等. 但不是所有的业务需求都能涉及和覆盖到 ...
- hive自定义函数(UDF)
首先什么是UDF,UDF的全称为user-defined function,用户定义函数,为什么有它的存在呢?有的时候 你要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就 ...
- hive自定义函数学习
1介绍 Hive自定义函数包括三种UDF.UDAF.UDTF UDF(User-Defined-Function) 一进一出 UDAF(User- Defined Aggregation Funcat ...
- hive自定义函数UDF UDTF UDAF
Hive 自定义函数 UDF UDTF UDAF 1.UDF:用户定义(普通)函数,只对单行数值产生作用: UDF只能实现一进一出的操作. 定义udf 计算两个数最小值 public class Mi ...
- Hive 自定义函数(转)
Hive是一种构建在Hadoop上的数据仓库,Hive把SQL查询转换为一系列在Hadoop集群中运行的MapReduce作业,是MapReduce更高层次的抽象,不用编写具体的MapReduce方法 ...
- Hive 自定义函数
hive 支持自定义UDF,UDTF,UDAF函数 以自定义UDF为例: 使用一个名为evaluate的方法 package com.hive.custom; import org.apache.ha ...
- hive自定义函数——hive streaming
Hadoop Streaming提供了一个便于进行MapReduce编程的工具包,使用它可以基于一些可执行命令.脚本语言或其他编程语言来实现Mapper和 Reducer,Streaming方式是基于 ...
- Hive 自定义函数 UDF UDAF UDTF
1.UDF:用户定义(普通)函数,只对单行数值产生作用: 继承UDF类,添加方法 evaluate() /** * @function 自定义UDF统计最小值 * @author John * */ ...
- Hadoop之Hive自定义函数的陷阱
A left join B, 这个B会连到A. 如<A1,B>, <A2,B>,在处理第一条记录的时候将B.clear(),则第二条记录的B是[]空的这是自定义UDF函数必须注 ...
随机推荐
- css基础重点内容总结
一.目录引入 ./同级(当前) ../上级目录 ../../上上级目录 二.标签种类: 1.块级标签(block):独占一行,宽高可设: 2.行内块标签(inline-block):不独占一行,宽高 ...
- [转载]C# TimeSpan 计算时间差(时间间隔)
TimeSpan 结构 表示一个时间间隔. 命名空间:System 程序集:mscorlib(在 mscorlib.dll 中) 说明: 1.DateTime值类型代表了一个从公元0001年1月1日 ...
- IDEA建立Spring MVC Hello World 详细入门教程
https://www.cnblogs.com/wormday/p/8435617.html
- 2.获取指定目录及子目录下所有txt文件的个数,并将这些txt文件复制到F盘下任意目录
package cn.it.text; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import ...
- JZ2440学习笔记之内存设备
通过OM[1:0]选择启动的设备: OM[1:0]=00,地址0对应的是Internal 4K RAM,且Nand的前4K会被复制到这里,得到执行: OM[1:0]=01,地址0对应的是Nor Fla ...
- 利用matplotlib库和numpy库画数学图形
首先,电脑要安装到matplotlib库和numpy库,这可以通过到命令符那里输入“pip install matplotlib ”,两个操作一样 其次,参照下列代码: import numpy as ...
- 【读书笔记】使用JMeter创建数据库(Mysql)测试
读书笔记:<零成本实现Web性能测试>第4章 记得某天按照虫师博客的写的,折腾后成功了.今天又忘记了... 折腾后又成功了,赶紧记录下... 原文:http://www.cnblogs.c ...
- Java链接MySQL数据库的用配置文件和不用配置文件的代码
1.利用配置文件(db.properties)链接MySQL数据库 package tool; import java.io.FileInputStream;import java.sql.Conne ...
- 西安理工大学 李爱民 Xi'an University of Technology, Aimin Li
李爱民-西安理工大学计算机科学与工程学院 ● 简介(Introduction)-> 李爱民(Aimin Li),男,湖北随州人,西安电子科学大学博士(PhD),中共党员.中国计算机学会会员,CS ...
- 论文阅读: Siam FC
一.研究动机 一方面传统算法设计的跟踪模型过于简单,另一方面深度学习方法很难达到实时效果然而现实场景中的应用对速度要求较高. "shallow method"(HCFT)没有很好地 ...