机器学习--PCA降维和Lasso算法
1、PCA降维
降维有什么作用呢?
数据在低维下更容易处理、更容易使用;
相关特征,特别是重要特征更能在数据中明确的显示出来;如果只有两维或者三维的话,更便于可视化展示;
去除数据噪声
降低算法开销
常见的降维算法有主成分分析(principal component analysis,PCA)、因子分析(Factor Analysis)和独立成分分析(Independent Component Analysis,ICA),其中PCA是目前应用最为广泛的方法。
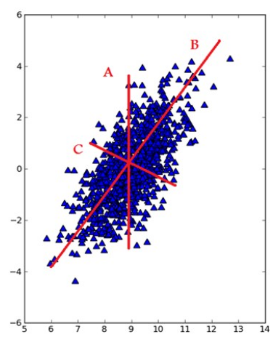
在PCA中,数据从原来的坐标系转换到新的坐标系,新坐标系的选择是由数据本身决定的。第一个坐标轴的选择是原始数据中方差最大的方向,从数据角度上来讲,这其实就是最重要的方向,
即下图总直线B的方向。第二个坐标轴则是第一个的垂直或者说正交(orthogonal)方向,即下图中直线C的方向。该过程一直重复,重复的次数为原始数据中特征的数目。
而这些方向所表示出的数据特征就被称为“主成分”。
Principal Component Analysis(PCA)是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,
以此使用较少的数据维度,同时保留住较多的原数据点的特性。
通俗的理解,如果把所有的点都映射到一起,那么几乎所有的信息(如点和点之间的距离关系)都丢失了,而如果映射后方差尽可能的大,那么数据点则会分散开来,以此来保留更多的信息。可以证明,PCA是丢失原始数据信息最少的一种线性降维方式。(实际上就是最接近原始数据,但是PCA并不试图去探索数据内在结构)
2、Lasso算法
参考自:http://blog.csdn.net/slade_sha/article/details/53164905
先看一波过拟合:

图中,红色的线存在明显的过拟合,绿色的线才是合理的拟合曲线,为了避免过拟合,我们可以引入正则化。
下面可以利用正则化来解决曲线拟合过程中的过拟合发生,存在均方根误差也叫标准误差,即为√[∑di^2/n]=Re,n为测量次数;di为一组测量值与真值的偏差。

实际考虑回归的过程中,我们需要考虑到误差项,


这个和简单的线性回归的公式相似,而在正则化下来优化过拟合这件事情的时候,会加入一个约束条件,也就是惩罚函数:

这边这个惩罚函数有多种形式,比较常用的有l1,l2,大概有如下几种:

讲一下比较常用的两种情况,q=1和q=2的情况:
q=1,也就是今天想讲的lasso回归,为什么lasso可以控制过拟合呢,因为在数据训练的过程中,可能有几百个,或者几千个变量,再过多的变量衡量目标函数的因变量的时候,可能造成结果的过度解释,而通过q=1下的惩罚函数来限制变量个数的情况,可以优先筛选掉一些不是特别重要的变量,见下图:

作图只要不是特殊情况下与正方形的边相切,一定是与某个顶点优先相交,那必然存在横纵坐标轴中的一个系数为0,起到对变量的筛选的作用。
q=2的时候,其实就可以看作是上面这个蓝色的圆,在这个圆的限制下,点可以是圆上的任意一点,所以q=2的时候也叫做岭回归,岭回归是起不到压缩变量的作用的,在这个图里也是可以看出来的。
lasso回归:
lasso回归的特色就是在建立广义线型模型的时候,这里广义线型模型包含一维连续因变量、多维连续因变量、非负次数因变量、二元离散因变量、多元离散因变,除此之外,无论因变量是连续的还是离散的,lasso都能处理,总的来说,lasso对于数据的要求是极其低的,所以应用程度较广;除此之外,lasso还能够对变量进行筛选和对模型的复杂程度进行降低。这里的变量筛选是指不把所有的变量都放入模型中进行拟合,而是有选择的把变量放入模型从而得到更好的性能参数。 复杂度调整是指通过一系列参数控制模型的复杂度,从而避免过度拟合(Overfitting)。 对于线性模型来说,复杂度与模型的变量数有直接关系,变量数越多,模型复杂度就越高。 更多的变量在拟合时往往可以给出一个看似更好的模型,但是同时也面临过度拟合的危险。
lasso的复杂程度由λ来控制,λ越大对变量较多的线性模型的惩罚力度就越大,从而最终获得一个变量较少的模型。除此之外,另一个参数α来控制应对高相关性(highly correlated)数据时模型的性状。 LASSO回归α=1,Ridge回归α=0,这就对应了惩罚函数的形式和目的。
机器学习--PCA降维和Lasso算法的更多相关文章
- 机器学习: t-Stochastic Neighbor Embedding 降维算法 (一)
Introduction 在计算机视觉及机器学习领域,数据的可视化是非常重要的一个应用,一般我们处理的数据都是成百上千维的,但是我们知道,目前我们可以感知的数据维度最多只有三维,超出三维的数据是没有办 ...
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
- 机器学习(Machine Learning)算法总结-决策树
一.机器学习基本概念总结 分类(classification):目标标记为类别型的数据(离散型数据)回归(regression):目标标记为连续型数据 有监督学习(supervised learnin ...
- 机器学习实战(一)k-近邻算法
转载请注明源出处:http://www.cnblogs.com/lighten/p/7593656.html 1.原理 本章介绍机器学习实战的第一个算法——k近邻算法(k Nearest Neighb ...
- UCI机器学习库和一些相关算法(转载)
UCI机器学习库和一些相关算法 各种机器学习任务的顶级结果(论文)汇总 https://github.com//RedditSota/state-of-the-art-result-for-machi ...
- 【机器学习详解】SMO算法剖析(转载)
[机器学习详解]SMO算法剖析 转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/51227754 CSDN−勿在浮沙筑高台 本文力 ...
- 《机器学习实战》——k-近邻算法Python实现问题记录(转载)
py2.7 : <机器学习实战> k-近邻算法 11.19 更新完毕 原文链接 <机器学习实战>第二章k-近邻算法,自己实现时遇到的问题,以及解决方法.做个记录. 1.写一个k ...
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- 降维和PCA
简介 要理解什么是降维,书上给出了一个很好但是有点抽象的例子. 说,看电视的时候屏幕上有成百上千万的像素点,那么其实每个画面都是一个上千万维度的数据:但是我们在观看的时候大脑自动把电视里面的场景放在我 ...
随机推荐
- MySQL5.7.9(GA)的安装
1.解压ZIP文件到安装目录: 2.进入到bin目录,试运行mysqld --console,查看可能的出错信息,安装相应的辅助软件,如.net V4.0等: 3.编辑my.ini文件,关键内容如下: ...
- C++拷贝构造函数(深拷贝,浅拷贝)
http://www.cnblogs.com/BlueTzar/articles/1223313.html C++拷贝构造函数(深拷贝,浅拷贝) 对于普通类型的对象来说,它们之间的复制是很简单的,例如 ...
- C++的栈
栈,是一种存储受限的线性数据结构,在存储和访问数据的时候只能访问栈的一端.栈类似于一摞盘子,只能拿去最上面的盘子,也只能把盘子放到最上面.由于这种特点,栈是一种后进先出(Last in / First ...
- CSS缎带效果
1. [代码]ribbon.html <!DOCTYPE HTML><html><head><style type="text/css&qu ...
- hdu 1503 Advanced Fruits(最长公共子序列)
Advanced Fruits Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)T ...
- PL/SQL学习笔记_03_存储函数与存储过程
ORACLE 提供可以把 PL/SQL 程序存储在数据库中,并可以在任何地方来运行它.这样就叫存储过程或函数. 存储函数:有返回值,创建完成后,通过select function() from dua ...
- input 限制输入
只能输入数字 :<input type="text" onkeyup="value=value.replace(/[^\d]/g,'')" /> 只 ...
- leetcode 204. Count Primes(线性筛素数)
Description: Count the number of prime numbers less than a non-negative number, n. 题解:就是线性筛素数的模板题. c ...
- 基于v4l2 ffmpeg x264的视频远程监控(附上编译好的库文件)
说明:主要是基于ghostyu网友整理的< arm mini2440 基于v4l2 ffmpeg x264的视频远程监控>.自己做了一遍,遇到不少问题,就整理记录下来. 1.平台 硬件:a ...
- LeetCode Majority Element I
原题链接在这里:https://leetcode.com/problems/majority-element/ 题目: Given an array of size n, find the major ...