scrapy图片-爬取哈利波特壁纸
话不多说,直接开始,直接放上整个程序过程
1、创建工程和生成spiders就不用说了,会用scrapy的都知道。
2、items.py
class HarryItem(scrapy.Item):
# define the fields for your item here like:
img_url = scrapy.Field()
img_name = scrapy.Field()
3、pipelines.py
import os
from harry.settings import IMAGES_STORE as IMGS
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class HarryPipeline(object):
def process_item(self, item, spider):
return item
class HarryDownLoadPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for imgurl in item['img_url']:
yield Request(imgurl)
#以下代码为自定义图片名称的新增代码
# def item_completed(self, results, item, info):
# print ('******the results is********:',results)
# os.rename(IMGS + '/' + results[0][1]['path'], IMGS + '/' + item['img_name'])
# def __del__(self):
# #完成后删除full目录
# os.removedirs(IMGS + '/' + 'full')
4、settings.py
BOT_NAME = 'harry'
SPIDER_MODULES = ['harry.spiders']
NEWSPIDER_MODULE = 'harry.spiders'
ROBOTSTXT_OBEY = False
IMAGES_URLS_FIELD = "img_url" # 对应item里面设定的字段,取到图片的url
IMAGES_STORE = 'E:/harrypotter'
ITEM_PIPELINES = {
'harry.pipelines.HarryDownLoadPipeline': 300,
}
5、最主要的爬虫组件hr.py
# -*- coding: utf-8 -*-
import scrapy
from harry.items import HarryItem
from scrapy import Request class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['www.ivsky.com']
sts=[]
st='http://www.ivsky.com/bizhi/harry_potter5_v3477/pic_1018'
for x in range(6,24):
if x<10:
sts.append(st+''+str(x)+'.html')
else:
sts.append(st+str(x)+'.html')
start_urls = sts def parse(self, response):
item=HarryItem()
urls=response.xpath('//div[@id="pic_con"]/div/img[@id="imgis"]/@src').extract()
names=response.xpath('//div[@id="pic_con"]/div/img[@id="imgis"]/@src').extract()[0].split('/')[-1]
item['img_name']=names
print ('links is :--','\n',urls)
item['img_url']=urls
yield item
6、执行爬虫
进入到工程路径,比如我的是harry这个路径中,执行 scrapy crawl hr #hr 是我设置的爬虫名称
7、总结
此次爬虫,有两方面的小收获。
收获①这个网站的网页设置很奇怪,用google浏览器F12打开看到图片链接结构是div/div/a/img/@src,但用 这个结构去爬取,发现链接都是空的(这也就是我的spiders中故意设置一 行print ('links is :--','\n',urls)的原因了,可以看到爬取过程的log,图片链接有没有正常爬取到)。所以直接邮件查看网页源代码,发现了猫腻,以下两张图片做对比可以发现实际只有div/div/img/@src这个结构才能真正获取到图片链接。怀疑是网站的程序猿将tag搞错<img> 和</a>配对了,在“查看网页源代码”可以看到是这样。
图片一:F12查看的结构
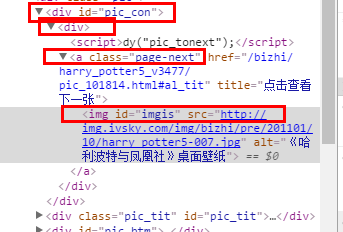
图片二、右键“查看网页源代码”

收获②
如果有些网页是类似下面数字翻页的,而且下一页中的链接不容易提取到的,那么可以用以下将要爬取的图片页面链接全部放置在start_urls这个list中
www.ivsky.com/bizhi/harry_potter5_v3477/pic_101808.html
www.ivsky.com/bizhi/harry_potter5_v3477/pic_101809.html
www.ivsky.com/bizhi/harry_potter5_v3477/pic_101811.html
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['www.ivsky.com']
sts=[]
st='http://www.ivsky.com/bizhi/harry_potter5_v3477/pic_1018'
for x in range(6,24):
if x<10:
sts.append(st+''+str(x)+'.html')
else:
sts.append(st+str(x)+'.html')
start_urls = sts
欢迎大家留言讨论,转载请注明出处。
scrapy图片-爬取哈利波特壁纸的更多相关文章
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- scrapy之360图片爬取
#今日目标 **scrapy之360图片爬取** 今天要爬取的是360美女图片,首先分析页面得知网页是动态加载,故需要先找到网页链接规律, 然后调用ImagesPipeline类实现图片爬取 *代码实 ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- [Python_scrapy图片爬取下载]
welcome to myblog Dome地址 爬取某个车站的图片 item.py 中 1.申明item 的fields class PhotoItem(scrapy.Item): # define ...
- scrapy版本爬取某网站,加入了ua池,ip池,不限速不封号,100个线程爬崩网站
目录 scrapy版本爬取妹子图 关键所在下载图片 前期准备 代理ip池 UserAgent池 middlewares中间件(破解反爬) settings配置 正题 爬虫 保存下载图片 scrapy版 ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- Python爬虫入门教程 26-100 知乎文章图片爬取器之二
1. 知乎文章图片爬取器之二博客背景 昨天写了知乎文章图片爬取器的一部分代码,针对知乎问题的答案json进行了数据抓取,博客中出现了部分写死的内容,今天把那部分信息调整完毕,并且将图片下载完善到代码中 ...
- 如何提高scrapy的爬取效率
提高scrapy的爬取效率 增加并发: 默认scrapy开启的并发线程为32个,可以适当进行增加.在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置 ...
- scrapy框架爬取笔趣阁完整版
继续上一篇,这一次的爬取了小说内容 pipelines.py import csv class ScrapytestPipeline(object): # 爬虫文件中提取数据的方法每yield一次it ...
随机推荐
- ELKB是什么?
ELKB是四个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana ,Beats. Elasticsearch是个开源分布式搜索引擎,提供搜集.分析.存储数据三大 ...
- Miller rabin
蛤蛤,终于基本上搞懂了 #include<iostream> #include<cstdio> using namespace std; long long num[10]={ ...
- AngularJS 控制器的方法
AngularJS 控制器也有方法(变量和函数) <!DOCTYPE html><html><head><meta http-equiv="Cont ...
- data-ng-init 指令
1.data-ng-init指令为AngularJS应用程序定义了一个初始值. 2.通常情况下,data-ng-init指令并不常用,将会使用控制器或模块来代替它.
- jquery 筛选元素 (2)
.add() 创建一个新的对象,元素添加到匹配的元素集合中. .add(selector) selector 一个字符串表示的选择器表达式.找到更多的元素添加到匹配的元素集合. $("p&q ...
- motto - Express 4.x Request对象获得参数方法
本文搜索关键字:motto express node js nodejs javascript request body request.body 1. req.param() 该方法获得参数最为方便 ...
- MySQL超大表如何提高count速度
经常用到count统计记录数,表又超级大,这时候sql执行很慢,就是走索引,也是很慢的,怎么办呢? 1.这个时候我们就要想为什么这么慢:根本原因是访问的数据量太大,就算只计算记录数也是很慢的. 2.如 ...
- js函数的默认参数
function f(flag, start, end, msg){ flag = flag == false ? flag : true; start = start || null; start ...
- python--随笔一
1.format函数--根据关键字和位置选择性插入数据 In [11]: '{mingzi}jintian{dongzuo}'.format(mingzi='duzi',dongzuo='i love ...
- TP5 webuploader 单页面多实例上传图片 案例
在使用 webuploader上传文件过程中,如果同一个页面存在多个上传区域,可以参考本示例代码. HTML 代码: <!DOCTYPE html> <html> <he ...