机器学习:模型泛化(岭回归:Ridge Regression)
一、基础理解
模型正则化(Regularization)
# 有多种操作方差,岭回归只是其中一种方式;
- 功能:通过限制超参数大小,解决过拟合或者模型含有的巨大的方差误差的问题;
影响拟合曲线的两个因子
- 模型参数 θi (1 ≤ i ≤ n):决定拟合曲线上下抖动的幅度;
- 模型截距 θ0:决定整体拟合曲线上下位置的高低;
二、岭回归
- 岭回归(Ridge Regression):模型正则化的一种方式;

- 解决的问题:模型过拟合;
- 思路:拟合曲线上下抖动的幅度主要受模型参数的影响,限制参数的大小可以限制拟合曲线抖动的幅度;
1)原理及操作
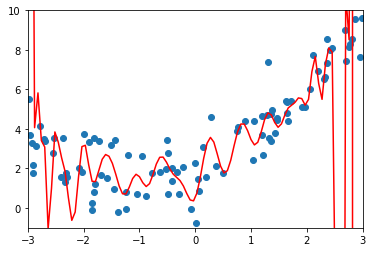
- 思路(以多项式回归为例):在原来的损失函数中加入一个含有所有变量的代数式,此时如果想让目标函数尽可能的小,也必须考虑让所有的参数 θi2 尽可能的小,进而可以降低拟合曲线上下的抖动幅度;
2)公式推导

- 加入的模型正则化:
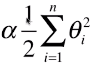 ;
;
- θi :决定拟合曲线的每一部分的抖动幅度,其中 i 取值范围 1 ~ n ,不包含 0,因为 θ0 表示模型的截距;
- θ0 :决定拟合曲线整体的上下位置的高低;
- 1/2 :方便计算,因为对式子求导后 θi2 变成 2θi ,产生的系数 2 刚好与 1/2 相乘为 1;但由于有 α 的存在,1/2 加与不加都没关系;
- α :引入的新的超参数,平衡新的损失函数中两部分的关系;是代数式的系数,代表在模型正则化下新的损失函数中,让每一个 θi 都尽可能的小,这个小的程度占整个优化损失函数程度的多少;
- 如果 α = 0:表示目标函数中没有加入模型正则化;
- 如果 α = +∞ :目标函数的另一部分 MSE 占整个目标函数的比重非常的小,主要的优化任务就是让每一个 θi 都尽可能的小;
三、实例查看岭回归对模型的影响
1)模拟数据集
import numpy as np
import matplotlib.pyplot as plt np.random.seed(42)
# np.random.uniform(-3, 3, size=100):在 [-3, 3] 之间等分取 100 个数;
x = np.random.uniform(-3.0, 3.0, size=100)
X = x.reshape(-1, 1)
y = 0.5 * x + 3. + np.random.normal(0, 1, size=100) plt.scatter(x, y)
plt.show()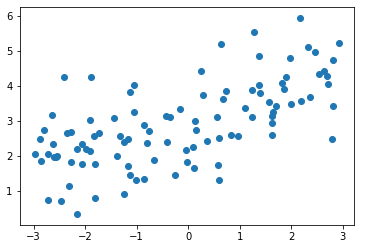
2)使用多形式回归过拟合数据
使用管道的方式使用多项式回归
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression # 使用多项式回归的管道方法
def PolynomialRegression(degree):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('lin_reg', LinearRegression())
]) from sklearn.model_selection import train_test_split np.random.seed(666)
X_train, X_test, y_train, y_test = train_test_split(X, y) from sklearn.metrics import mean_squared_error poly_reg = PolynomialRegression(degree=20)
poly_reg.fit(X_train, y_train) y_poly_predict = poly_reg.predict(X_test)
mean_squared_error(y_test, y_poly_predict)
# 输出:167.9401086729357# 均方误差:167.9401086729357
绘制模型曲线
# np.linspace(-3, 3, 100):在 [-3, 3] 之间等分取 100 个数,包含 -3 和 3;
X_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = poly_reg.predict(X_plot) plt.scatter(x, y)
plt.plot(X_plot[:, 0], poly_reg.predict(X_plot), color='r')
plt.axis([-3, 3, 0, 6])
plt.show()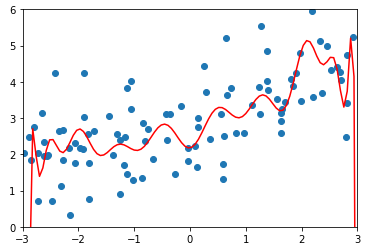
3)使用岭回归
- from sklearn.linear_model import Ridge
将绘图代码封装为一个函数
def plot_model(model):
X_plot = np.linspace(-3, 3, 100).reshape(100, 1)
y_plot = model.predict(X_plot) plt.scatter(x, y)
plt.plot(X_plot[:, 0], model.predict(X_plot), color='r')
plt.axis([-3, 3, 0, 6])
plt.show()使用管道的方式使用岭回归方法
from sklearn.linear_model import Ridge def RidgeRegression(degree, alpha):
return Pipeline([
('poly', PolynomialFeatures(degree=degree)),
('std_scaler', StandardScaler()),
('ridge_reg', Ridge(alpha=alpha))
])degree = 20、α = 0.0001
ridge1_reg = RidgeRegression(20, 0.0001)
ridge1_reg.fit(X_train, y_train) y1_predict = ridge1_reg.predict(X_test)
mean_squared_error(y_test, y1_predict)
# 输出:1.323349275406402(均方误差) plot_model(ridge1_reg)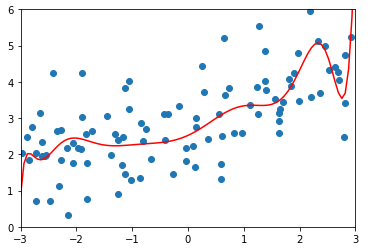
degree = 20、α = 1
ridge2_reg = RidgeRegression(20, 1)
ridge2_reg.fit(X_train, y_train) y2_predict = ridge2_reg.predict(X_test)
mean_squared_error(y_test, y2_predict)
# 输出:1.1888759304218448(均方误差) plot_model(ridge2_reg)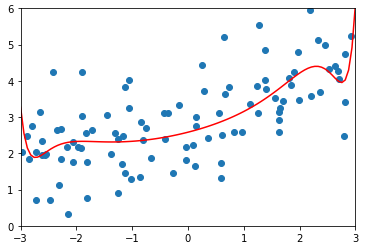
degree = 20、α = 100
ridge3_reg = RidgeRegression(20, 100)
ridge3_reg.fit(X_train, y_train) y3_predict = ridge3_reg.predict(X_test)
mean_squared_error(y_test, y3_predict)
# 输出:1.3196456113086197(均方误差) plot_model(ridge3_reg)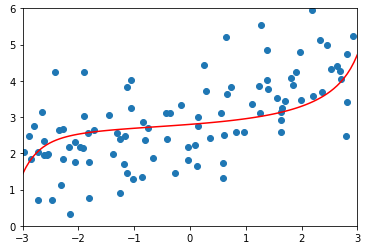
degree=20、alpha=1000000(相当于无穷大)
ridge4_reg = RidgeRegression(20, 1000000)
ridge4_reg.fit(X_train, y_train) y4_predict = ridge4_reg.predict(X_test)
mean_squared_error(y_test, y4_predict)
# 输出:1.8404103153255003 plot_model(ridge4_reg)
- 当 α = 1000000(相当于无穷大)时:拟合曲线几乎是一条水平的直线,因为当 α 非常大的时候,对目标函数的影响相当于只有添加的模型正则化在起作用;
机器学习:模型泛化(岭回归:Ridge Regression)的更多相关文章
- 岭回归(Ridge Regression)
一.一般线性回归遇到的问题 在处理复杂的数据的回归问题时,普通的线性回归会遇到一些问题,主要表现在: 预测精度:这里要处理好这样一对为题,即样本的数量和特征的数量 时,最小二乘回归会有较小的方差 时, ...
- 机器学习总结之逻辑回归Logistic Regression
机器学习总结之逻辑回归Logistic Regression 逻辑回归logistic regression,虽然名字是回归,但是实际上它是处理分类问题的算法.简单的说回归问题和分类问题如下: 回归问 ...
- 机器学习-正则化(岭回归、lasso)和前向逐步回归
机器学习-正则化(岭回归.lasso)和前向逐步回归 本文代码均来自于<机器学习实战> 这三种要处理的是同样的问题,也就是数据的特征数量大于样本数量的情况.这个时候会出现矩阵不可逆的情况, ...
- 机器学习入门11 - 逻辑回归 (Logistic Regression)
原文链接:https://developers.google.com/machine-learning/crash-course/logistic-regression/ 逻辑回归会生成一个介于 0 ...
- 机器学习入门线性回归 岭回归与Lasso回归(二)
一 线性回归(Linear Regression ) 1. 线性回归概述 回归的目的是预测数值型数据的目标值,最直接的方法就是根据输入写出一个求出目标值的计算公式,也就是所谓的回归方程,例如y = a ...
- 吴恩达机器学习笔记14-逻辑回归(Logistic Regression)
在分类问题中,你要预测的变量
- 机器学习系列-tensorflow-03-线性回归Linear Regression
利用tensorflow实现数据的线性回归 导入相关库 import tensorflow as tf import numpy import matplotlib.pyplot as plt rng ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- Jordan Lecture Note-4: Linear & Ridge Regression
Linear & Ridge Regression 对于$n$个数据$\{(x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n)\},x_i\in\mathbb{R}^d,y ...
- 在线场景感知:图像稀疏表示—ScSPM和LLC总结(以及lasso族、岭回归)
前言: 场景感知其实不分三维场景和二维场景,可以使用通用的方法,不同之处在于数据的形式,以及导致前期特征提取及后期在线场景分割过程.场景感知即是场景语义分析问题,即分析场景中物体的特征组合与相应场景的 ...
随机推荐
- 一个gpio 不受控制的bug
前几天调试一个flash灯的驱动程序,这可ic 有两个控制pin, 一个叫en1 一个叫en2, 根据spec的说明,不同的组合将产生不同的输出电流.但我发现,那个en1 这个pin 死活是拉不高的, ...
- Centos7 搭建DNS服务器与原理配置详解
在搭建我们自己DNS服务器之前,先必须了解下DNS服务器的作用和原理. DNS是在互联网上进行域名解析到对应IP地址的服务器,保存互联网上所有的IP与域名的对应信息,然后将我们对网址的访问,解析成IP ...
- java深入探究09-Filter,Listener,国际化
1.Filter过滤器 1)为是么有过滤器 开发项目中经常遇到直接登录主页面要判断用户是否合法,这类代码比较重复,可以通过过滤器来解决 2)过滤器原理生命周期 服务器创建过滤器对象->一个执行i ...
- 1.java实现——正规表达式判断
目标:这个代码仅局限于所展示的正规表达式判断,也就是这是一个较单一的正规表达式判断(简易版). 既然是简易版的,所以若要修改这个正规表达式也是非常容易的,只要将二维数组中的数组修改即可.数组数据依据, ...
- java学习小笔记(三.socket通信)【转】
三,socket通信1.http://blog.csdn.net/kongxx/article/details/7288896这个人写的关于socket通信不错,循序渐进式的讲解,用代码示例说明,运用 ...
- gulp的安装和配置
gulp的安装和使用方法 1先是有node为前提的, 2安装淘宝镜像 2.1因为很多npm包都是国外的,所以安装起来很慢,所以我们可以利用淘宝的镜像服务器来进行安装后续的包,速度和成功率会高很多. ...
- Pycharm更换pip源为国内
Python里的pip是官方自带的源,国内使用pip安装的时候十分缓慢,所以最好是更换成中国国内的源地址. 目前国内靠谱的 pip 镜像源有: 清华: https://pypi.tuna.tsingh ...
- VMware Workstation Pro v14.0
早些时候戴尔旗下的虚拟化软件 VMware Pro v14 版正式发布,本次更新主要是优化对创意者更新版的支持. 创意者更新版是目前微软 Windows 10 系统的最新版本,该版本亦会在十月份成为C ...
- swoole帮助文档
入门指引 [编辑本页] Swoole虽然是标准的PHP扩展,实际上与普通的扩展不同.普通的扩展只是提供一个库函数.而swoole扩展在运行后会接管PHP的控制权,进入事件循环.当IO事件发生后,swo ...
- Android项目的目录结构 初学者记录
Android项目的目录结构 Activity:应用被打开时显示的界面 src:项目代码 R.java:项目中所有资源文件的资源id Android.jar:Android的jar包,导入此包方可使用 ...