第三章 Java内存模型(上)
本章大致分为4部分:
- Java内存模型的基础:主要介绍内存模型相关的基本概念
- Java内存模型中的顺序一致性:主要介绍重排序和顺序一致性内存模型
- 同步原语:主要介绍3个同步原语(synchroized、volatile和final)的内存语义及重排序规则在处理器中的实现
- Java内存模型的设计:主要介绍Java内存模型的设计原理,及其与处理器内存模型和顺序一致性内存模型的关系
Java内存模型的基础
并发编程模型的两个关键问题
在并发编程中,需要处理两个关键问题:
- 线程之间如何通信:指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种(共享内存和消息传递)
- 在共享内存的并发模型里,线程之间共享程序的公共状态,通过写-读内存中的公共状态进行隐式通信
- 在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过发送消息来显式进行通信
- 线程之间如何同步:指程序中用于控制不同线程间操作发生相对顺序的机制
- 在共享内存并发模型里,同步是显式进行的,程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行
- 在消息传递的并发模型里,由于消息的发送必须在消息的接受之前,因此同步是隐式进行的
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。
Java内存模型的抽象结构
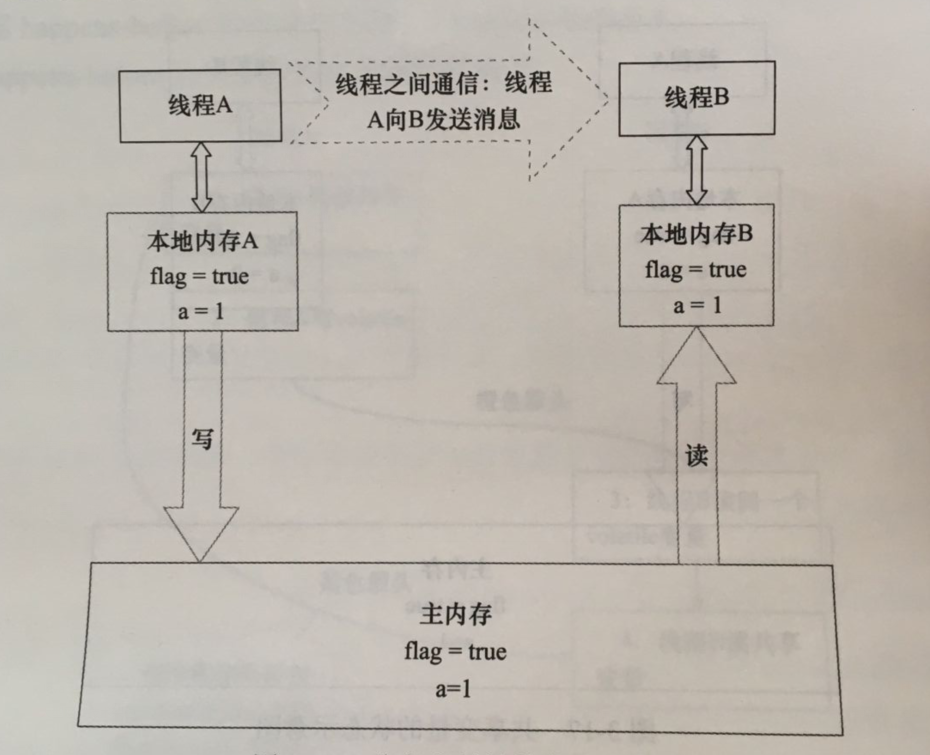
在Java中,所有实例域、静态域和数组元素都存储在堆内存中,堆内存在线程之间共享。局部变量、方法定义参数和异常处理器参数不会再线程之间共享,它们不会又内存可见性问题,也不会收内存模型的影响。
线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM(Java内存模型)的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
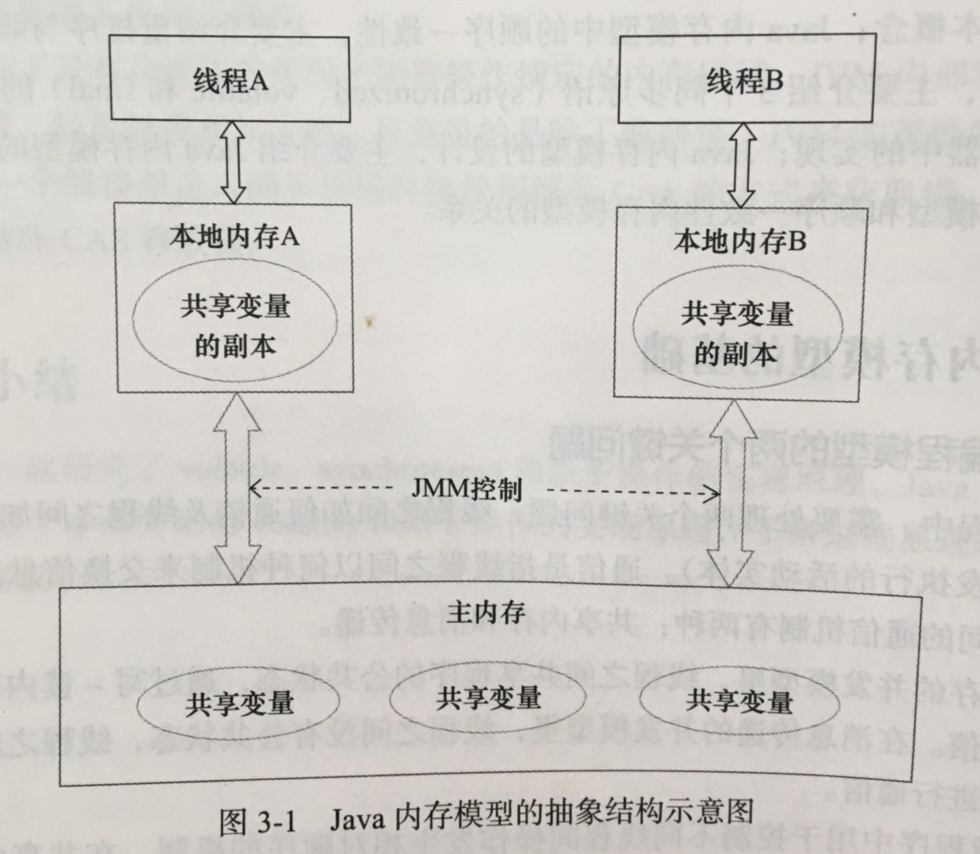
从上图来看,线程A与线程B之间要通信的话,必须要经历下面2个步骤:
(1)线程A把本地内存A中更新过的共享变量刷新到主内存中去
(2)线程B到主内存中去读取线程A之前已更新过的共享变量
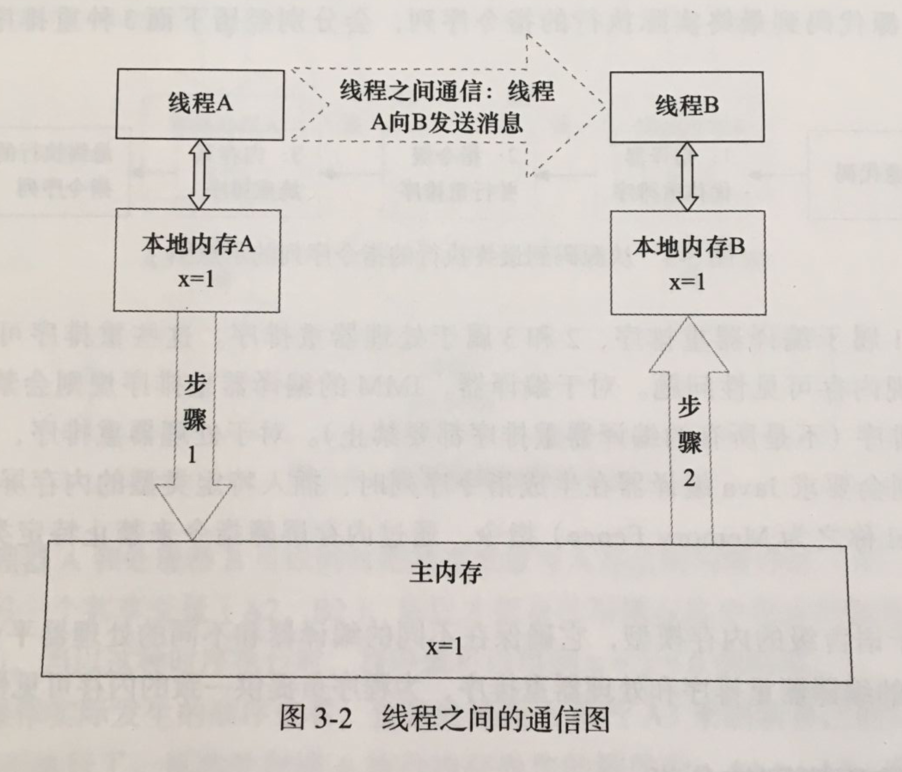
从整体来看,这两个步骤实质上是线程A在向线程B发送消息,而且这个通信过程必须要经过主内存。JMM通过控制主内存与每个线程的本地内存之间的交互,来为Java程序员提供内存可见性保证。
从源代码到指令序列的重排序
为了提高性能,编译器和处理器常常会对指令做重排序,重排序分3中类型
- 编译器优化的重排序:编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序
- 指令级并行的重排序:现代处理器采用了指令级并行技术(Instruction-Level Parallelism ,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序
- 内存系统的重排序:由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序
源代码 --> 1:编译器优化重排序 -->:2:指令级并行重排序 --> 3:内存系统重排序 --> 最终执行的指令序列
1属于编译器重排序,2和3属于处理器重排序。对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序;对于处理器重排序,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障指令,通过内存屏障指令来禁止特定类型的处理器重排序。
为了保证内存可见性,Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。JMM把内存屏障指令分为4类,如下图

Happens-before简介
从JDK 5开始,Java使用新的JSR-133内存模型(除非特别说明,本文针对的都是该模型)。JSR-133使用happens-before的概念来阐述操作之间的内存可见性。在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须要存在happens-before关系。这里提到的两个操作既可以是一个线程之内,也可以是不同线程之间。
happens-before规则如下:
程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作
监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁
volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读
传递性:如果A happens-before B,且B happens-before C,那么A happens-before C
注意:两个操作之间具有happens-before关系,并不意味着前一个操作必须要在后一个操作之前执行!happens-before仅仅要求前一个操作(执行的结果)对后一个操作可见,切前一个操作按顺序排在第二个操作之前。
happens-before与JMM的关系如图
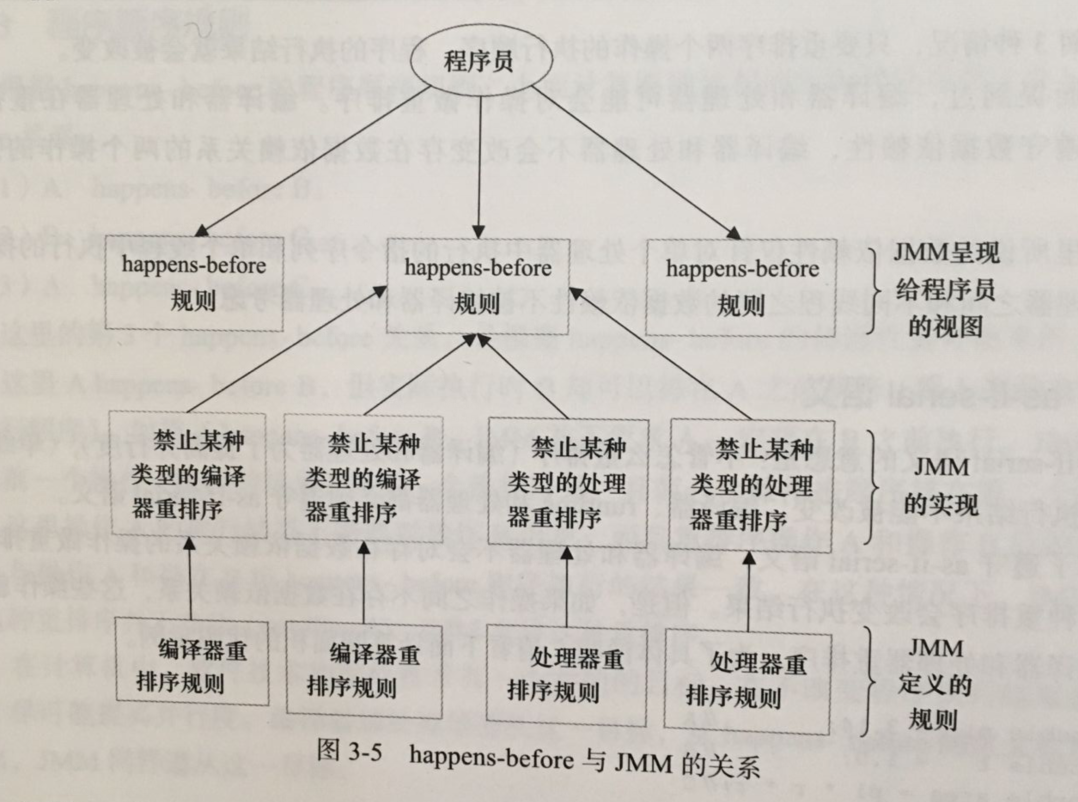
如上图,一个happens-before规则对应于一个或多个编译器和处理器重排序规则,对于Java程序员来说,happens-before规则简单易懂,它避免Java程序员为了理解JMM提供的内存可见性保证而去学习复杂的重排序规则以及这些贵的具体实现方法。
重排序
重排序是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。
数据依赖性
如果两个操作访问同一个变量,且这两个操作有一个为写操作,此时这两个操作之间就存在数据依赖性。数据依赖性分为3种类型
| 名称 | 代码示例 | 说明 |
| 写后读 |
a = 1; b = a; |
写一个变量之后,再读这个位置 |
| 写后写 |
a = 1; a = 2; |
写一个变量之后,再写这个变量 |
| 读后写 |
a = b; b = 1; |
读一个变量之后,再写这个变量 |
上面3中情况,只要重排序两个操作的执行顺序,程序的执行结果就会被改变。前面提到过,编译器和处理器可能会对操作作重排序,编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作执行顺序。这里所说的数据依赖性仅针对单个处理器中执行的指令序列和的那个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。
as-if-serial语义
as-if-serial语义的意思是:不管怎么重排序,(单线程)程序的执行结果不能被改变。编译器和处理器和runtime都必须遵守as-if-serial语义。
double pi = 3.14; //A
double r = 1.0; //B
double area = pi * r * r //C
如上A和C,B和C都存在数据依赖关系,因此C不能排在A或者B之前;但是A和B之间没有数据依赖关系,编译器和处理器是可以重排序A与B之间执行顺序的
volatile的内存语义
volatile变量自身具有下列特性:
- 可见性:对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入
- 原子性:对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性
volatile写-读建立的happens-before关系
从JSR-133(JDK 1.5)开始,volatile变量的写-读可以实现线程之间的通信。从内存语义的角度来说,volatile的写-读与锁的释放-获取有相同的内存效果:volatile写和锁的释放有相同的内存定义;volatile的读与锁的获取有相同的内存语义
下面使用volatile变量的示例代码
public class VolatileExample {
int a = 0;
volatile boolean flag = false;
public void writer(){
a = 1; //
flag = ture; //
}
public void reader(){
if(flag){ //
int i = a; //
...
}
}
}
假设线程A执行writer()方法之后,线程B执行reader()方法。根据happens-before规则,这个过程建立的happens-before关系可以分为3类:
- 根据程序次序规则,1 happens-before 2, 3 happens-before 4
- 根据volatile规则,2 happens-before 3
- 根据happens-before传递性规则,1 happens-before 4
上述happens-before关系的图形化表示形式如下
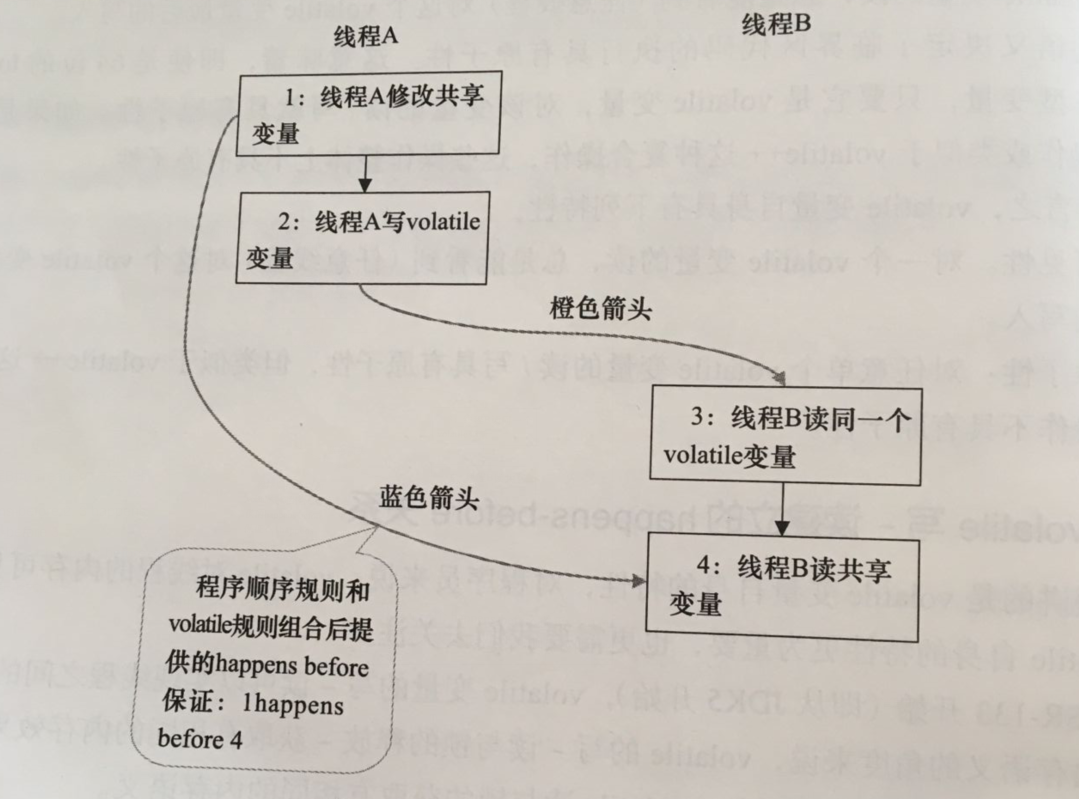
上图中,每一个箭头链接的两个节点,代表了一个happens-before关系。黑色箭头表示程序顺序规则,橙色箭头表示volatile规则,蓝色箭头表示组合这些规则后提供的happens-before保证。
A线程写了一个volatile变量后,B线程读同一个volatile变量。A线程在写volatile变量之前所有可见的共享变量,在B线程读同一个volatile变量后,将立即变得对B线程可见。
volatile写-读的内存语义
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值刷新到主内存
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量
结合上图总结为:
线程A写一个volatile变量,实质上是线程A向接下将要读这个volatile变量的某个线程发出了(其对共享变量所做修改的)消息
线程B读一个volatile变量,实质上是线程B接受了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息
线程A写一个volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息
volatile内存语义的实现
为了实现volatile内存语义,JMM会分别限制这两个类型的重排序类型,下表是JMM针对编译器制定的volatile重排序规则表
| 是否能重排序 | 第二个操作 | ||
| 第一个操作 | 普通的读/写 | volatile读 | volatile写 |
| 普通的读/写 | NO | ||
| volatile读 | NO | NO | NO |
| volatile写 | NO | NO | |
从上表可以看出:
当第二个操作时volatile写时,不管第一个操作时什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
当第一个操作时volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile之前。
当第一个操作时volatile写,第二个操作时volatile读时,不能重排序
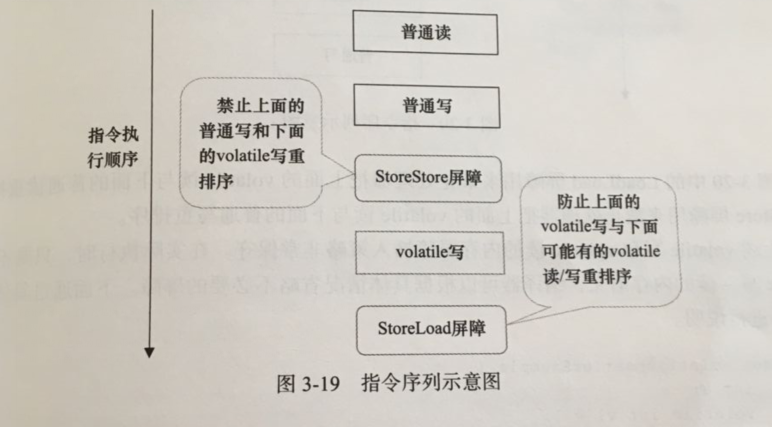
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能。为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略
在每个volatile写操作的前面插入一个StoreStore屏障
在每个volatile写操作的后面插入一个StoreLoad屏障
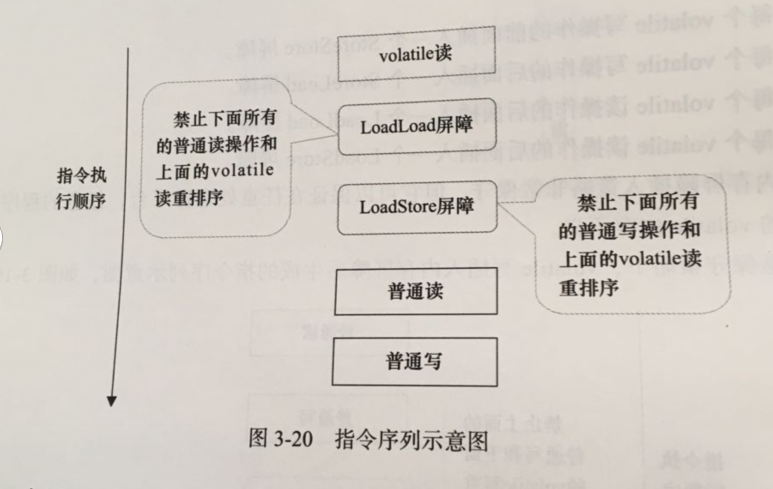
在每个volatile读操作的后面插入一个LoadLoad屏障
在每个volatile读操作的后面插入一个LoadStore屏障
下面是保守策略下,volatile写插入内存屏障后生产的指令序列示意图
下面是保守策略下,volatile读插入内存屏障后生产的指令序列示意图
上述的volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。
public class VolatileBarrierExample {
int a;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite(){
int i = v1; //第一个volatile读
int j = v2; //地二个volatile读
a = i + j; //普通写
v1 = i + 1; //第一个volatile写
v2 = j + 1; //第二个volatile写
}
... //其他方法
}
针对readAndWrite()方法,编译器在生成字节码可以做如下的优化
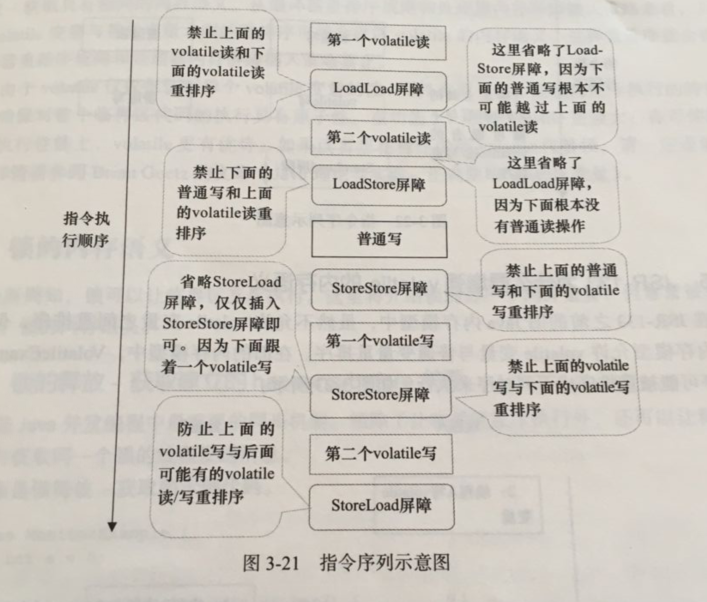
注意:最后的StoreLoad屏障不能省略。因为第一个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器通常会在这里插入一个StoreLoad屏障。
JSR-133为什么要增强volatile的内存语义?
在JSR-133之前的旧Java内存模型中,虽然不允许volatile变量之间重排序,但旧的Java内存模型允许volatile变量与普通变量重排序。volatile的写-读没有锁的释放-获取所具有的内存语义。为了提供一种比锁更轻量级的线程之间通信的机制,JSR-133专家组决定增强volatile的内存语义,严格限制编译器和处理器对volatile变量与普通变量的重排序,确保volatile的写-读和锁的释放-获取具有相同的内存语义。
第三章 Java内存模型(上)的更多相关文章
- (第三章)Java内存模型(上)
一.java内存模型的基础 1.1 并发编程模型的两个关键问题 在并发编程中,需要处理两个关键问题:线程之间如何通信及线程之间如何同步(这里的线程是指并发执行的活动实体).通信是指线程之间以何种机制来 ...
- (第三章)Java内存模型(下)
一.happens-before happens-before是JMM最核心的概念.对于Java程序员来说,理解happens-before是理解JMM的关键. 1.1 JMM的设计 从JMM设计者的 ...
- (第三章)Java内存模型(中)
一.volatile的内存语义 1.1 volatile的特性 理解volatile特性的一个好办法是把对volatile变量的单个读/写,看成是使用同一个锁对这些单个读/写操作做了同步.下面通过具体 ...
- 第三章 Java内存模型(下)
锁的内存语义 中所周知,锁可以让临界区互斥执行.这里将介绍锁的另一个同样重要但常常被忽视的功能:锁的内存语义 锁的释放-获取建立的happens-before关系 锁是Java并发编程中最重要的同步机 ...
- 深入理解java虚拟机-第12章Java内存模型与线程
第12章 Java内存模型与线程 Java内存模型 主内存与工作内存: java内存模型规定了所有的变量都在主内存中,每条线程还有自己的工作内存. 工作内存中保存了该线程使用的主内存副本拷贝,线程对 ...
- 《Java并发编程实战》第十六章 Java内存模型 读书笔记
Java内存模型是保障多线程安全的根基,这里不过认识型的理解总结并未深入研究. 一.什么是内存模型,为什么须要它 Java内存模型(Java Memory Model)并发相关的安全公布,同步策略的规 ...
- java并发编程实战:第十六章----Java内存模型
一.什么是内存模型,为什么要使用它 如果缺少同步,那么将会有许多因素使得线程无法立即甚至永远看到一个线程的操作结果 编译器把变量保存在本地寄存器而不是内存中 编译器中生成的指令顺序,可以与源代码中的顺 ...
- 并发之初章Java内存模型
>>>>>>博客地址<<<<<< >>>>>>首发博客<<<<< ...
- 《深入理解Java虚拟机》-----第12章 Java内存模型与线程
概述 多任务处理在现代计算机操作系统中几乎已是一项必备的功能了.在许多情况下,让计算机同时去做几件事情,不仅是因为计算机的运算能力强大了,还有一个很重要的原因是计算机的运算速度与它的存储和通信子系统速 ...
随机推荐
- 怎样在WIN7系统下安装IIS和配置ASP
一:Windows7系统 (IIS是WIN7自带的,版本7.0),首先是安装IIS.打开控制面板,找到“程序与功能”,点进去,点击左侧“打开或关闭Windows功能”,找到“Internet 信息服务 ...
- org.apache.flume.ChannelException: Take list for MemoryTransaction, capacity 100 full, consider committing more frequently, increasing capacity, or increasing thread count
flume在抽取MySQL数据到kafka时报错,如下 [SinkRunner-PollingRunner-DefaultSinkProcessor] ERROR org.apache.flume.s ...
- js的值类型和引用类型
(1)值类型:String.Boolean.Number.null.undefined.(原始值) var a = 2; var b = a; b=3; a ==>2; b ==>3 原 ...
- ssh学习(1)
雇员薪资管理系统(crud) ①先搞定spring ②引入spring包 ③编写applicationContext.xml文件(或者beans.xml),我们把该文件放在src目录下 ④测试一下sp ...
- hdu 5241 Friends(找规律?)
Friends Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total S ...
- 浅谈Vue个性化dashBoard 布局
dashBoard布局在管理系统使用比较多:使用自己喜欢的方式进行自定义布局 使用npm 安装 npm install vue-grid-layout 全局使用 import vueGridLayou ...
- 201621123014《Java程序设计》第十一周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多线程相关内容. 2. 书面作业 本次PTA作业题集多线程 1. 源代码阅读:多线程程序BounceThread 1.1 BallR ...
- freemarker实现第一个HelloWorld
第一步:引入freemarker jar包 第二步:创建templates下的test01.ftl 第三步:在web.xml下 第四步:编写后台代码 package com.wisezone.test ...
- LeetCode Reshape the Matrix
原题链接在这里:https://leetcode.com/problems/reshape-the-matrix/#/description 题目: In MATLAB, there is a ver ...
- 如何开启MySQL远程访问权限 允许远程连接
1.改表法. 可能是你的帐号不允许从远程登陆,只能在localhost.这个时候只要在localhost的那台电脑,登入mysql后,更改 "mysql" 数据库里的 " ...