weight decay 和正则化caffe
正则化是为了防止过拟合,因为正则化能降低权重
caffe默认L2正则化
代码讲解的地址:http://alanse7en.github.io/caffedai-ma-jie-xi-4/
重要的一个回答:https://stats.stackexchange.com/questions/29130/difference-between-neural-net-weight-decay-and-learning-rate
按照这个答主的说法,正则化损失函数,正则化之后的损失函数如下:

这个损失函数求偏导就变成了:加号前面是原始损失函数求偏导,加号后面就变成了 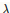 *w,这样梯度更新就变了下式:
*w,这样梯度更新就变了下式:
wi←wi−η∂E∂wi−ηλwi.
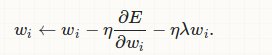
L2正则化的梯度更新公式,与没有加regulization正则化相比,每个参数更新的时候多剪了正则化的值,相当于让每个参数多剪了weight_decay*w原本的值
根据caffe中的代码也可以推断出L1正则化的公式:
把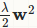 替换成
替换成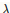 *w的绝对值
*w的绝对值
所以求偏导的时候就变成了,当w大于0为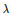 ,当w小于0为-
,当w小于0为-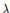
void SGDSolver<Dtype>::Regularize(int param_id) {
const vector<shared_ptr<Blob<Dtype> > >& net_params = this->net_->params();
const vector<float>& net_params_weight_decay =
this->net_->params_weight_decay();
Dtype weight_decay = this->param_.weight_decay();
string regularization_type = this->param_.regularization_type();
Dtype local_decay = weight_decay * net_params_weight_decay[param_id];
switch (Caffe::mode()) {
case Caffe::CPU: {
if (local_decay) {
if (regularization_type == "L2") {
// add weight decay
caffe_axpy(net_params[param_id]->count(),
local_decay,
net_params[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());
} else if (regularization_type == "L1") {
caffe_cpu_sign(net_params[param_id]->count(),
net_params[param_id]->cpu_data(),
temp_[param_id]->mutable_cpu_data());
caffe_axpy(net_params[param_id]->count(),
local_decay,
temp_[param_id]->cpu_data(),
net_params[param_id]->mutable_cpu_diff());
} else {
LOG(FATAL) << "Unknown regularization type: " << regularization_type;
}
}
break;
}
caffe_axpy的实现在util下的math_functions.cpp里,实现的功能是y = a*x + y,也就是相当于把梯度更新值和weight_decay*w加起来了
caffe_sign的实现在util下的math_functions.hpp里,通过一个宏定义生成了caffe_cpu_sign这个函数,函数实现的功能是当value>0返回1,<0返回-1
weight decay 和正则化caffe的更多相关文章
- PyTorch 中 weight decay 的设置
先介绍一下 Caffe 和 TensorFlow 中 weight decay 的设置: 在 Caffe 中, SolverParameter.weight_decay 可以作用于所有的可训练参数, ...
- dying relu 和weight decay
weight decay就是在原有loss后面,再加一个关于权重的正则化,类似与L2 正则,让权重变得稀疏: 参考:https://www.zhihu.com/question/24529483 dy ...
- 权重衰减(weight decay)与学习率衰减(learning rate decay)
本文链接:https://blog.csdn.net/program_developer/article/details/80867468“微信公众号” 1. 权重衰减(weight decay)L2 ...
- weight decay(权值衰减)、momentum(冲量)和normalization
一.weight decay(权值衰减)的使用既不是为了提高你所说的收敛精确度也不是为了提高收敛速度,其最终目的是防止过拟合.在损失函数中,weight decay是放在正则项(regularizat ...
- 在神经网络中weight decay
weight decay(权值衰减)的最终目的是防止过拟合.在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weigh ...
- 【tf.keras】AdamW: Adam with Weight decay
论文 Decoupled Weight Decay Regularization 中提到,Adam 在使用时,L2 与 weight decay 并不等价,并提出了 AdamW,在神经网络需要正则项时 ...
- weight decay (权值衰减)
http://blog.sina.com.cn/s/blog_890c6aa30100z7su.html 在机器学习或者模式识别中,会出现overfitting,而当网络逐渐overfitting时网 ...
- [转载]理解weight decay
http://blog.sina.com.cn/s/blog_a89e19440102x1el.html
- 【撸码caffe四】 solver.cpp&&sgd_solver.cpp
caffe中solver的作用就是交替低啊用前向(forward)算法和后向(backward)算法来更新参数,从而最小化loss,实际上就是一种迭代的优化算法. solver.cpp中的Solver ...
随机推荐
- vue.js入门环境搭建
1.node.js环境(npm包管理器) 2.vue-cli手脚架构建工具 3.cnpm npm的淘宝镜像 安装node.js 从node.js官网下载并安装node,安装过程一路“下一步”就可以 安 ...
- js 实现继承的几种方式
//js中实现继承的几种方式 //实现继承首先要有一个父类,先创造一个动物的父类 function Animal(name){ this.name = name; this.shoot = funct ...
- 18-----BBS论坛
BBS论坛(十八) 18.首页轮播图实现 (1)front/css/front_base.css .main-container{ width: 990px; margin: 0 auto; over ...
- web三大组件
1.Servlet Servlet是用来处理客户端请求的动态资源,也就是当我们在浏览器中键入一个地址回车跳转后,请求就会被发送到对应的Servlet上进行处理. Servlet的任务有: 接收请求数据 ...
- AVplayer搭建ftp共享PC端
1.安装FTP服务 2.关闭防火墙 3.添加FTP站点 设置ip时,需要查询本机的ip 本机测试 4.iphone安装AVPlayer,并设置
- Java-IO中的节点流和处理流
理解好Java-IO中的节点流和处理流是理解Java输入.输出的关键基础,因此,了解节点流和处理流相关的知识点尤为重要. 1.定义 (1)节点流:可以从或向一个特定的地方(节点)读写数据.如FileR ...
- Idea创建Maven项目没有src
第一次创建,下载非常慢,解决方法 1.配置环境变量 第二种:创建Maven项目时加上 archetypeCatalog=internal 参数 第三种:为自己的Maven配置国内镜像源 打开自己的 M ...
- ace+validate表单验证(两种方法)
//修改密码(直接在validate中验证提交) $("#changePassword").on(ace.click_event, function() { var html = ...
- [OpenStack] [Liberty] Neutron单网卡桥接模式访问外网
环境配置: * Exsi一台 * Exsi创建的单网卡虚拟机一台 * Ubuntu 14LTS 64位操作系统 * OpenStack Liberty版本 * 使用Neutron网络而非Nova网络 ...
- 利用DOS命令做伪装成图片的压缩包,看上去是图片其实是个压缩包用2条命令即搞定
在很多地方我们看到一张图片,然后把这张图片下载到本地,改后缀名为xx.rar,即变成了压缩包. 比如下面这个图片:(把以下图片保存到本地,后缀名xx.png 改为 xx.rar,解压试试) 怎么样,是 ...