STATA数据统计软件学习记录
STATA是一个数据统计软件,正如它的名字一样,STATA=statistic+data。STATA软件的功能和matlab类似,也可以用代码实现数据的统计与可视化。但几乎只能进行整行整列的数据处理,且每次只能加载处理一个数据矩阵,灵活性和全面性比不过matlab。那我为什么要用STATA呢?这是因为我选修了这门课,水一下学分。当然,相比matlab,它在数据处理方面,也有一些方便之处。下面记录STATA的一些常用的处理、统计、可视化方法。
基本命令
STATA命令的语法大部分是这样的:命令(空格)待处理的数据名(逗号)可选的一些参数。
读取软件自带数据集 sysuse
首先读取STATA自带的样例数据:
sysuse auto, clear
其中sysuse是一个命令,auto是汽车数据集的名称,clear是在读取数据之前先清空内存中已读取的数据。之后可以在变量窗口看到读取的变量。实际上这里的变量就是excel列表中的列标,每个变量代表一个列标。然后每个列标都有它对应的属性,属性定义了每列数据的类型和一些信息等。如下图:
浏览数据集 br
用br命令(等同于browse,STATA要弄一个简写让你更方便一些,然而让初学者很烦,可读性很差,弄巧成拙)可以查看所读取的表格:
br
如下图所示:
获取数据基本统计信息 sum codebook tabstat
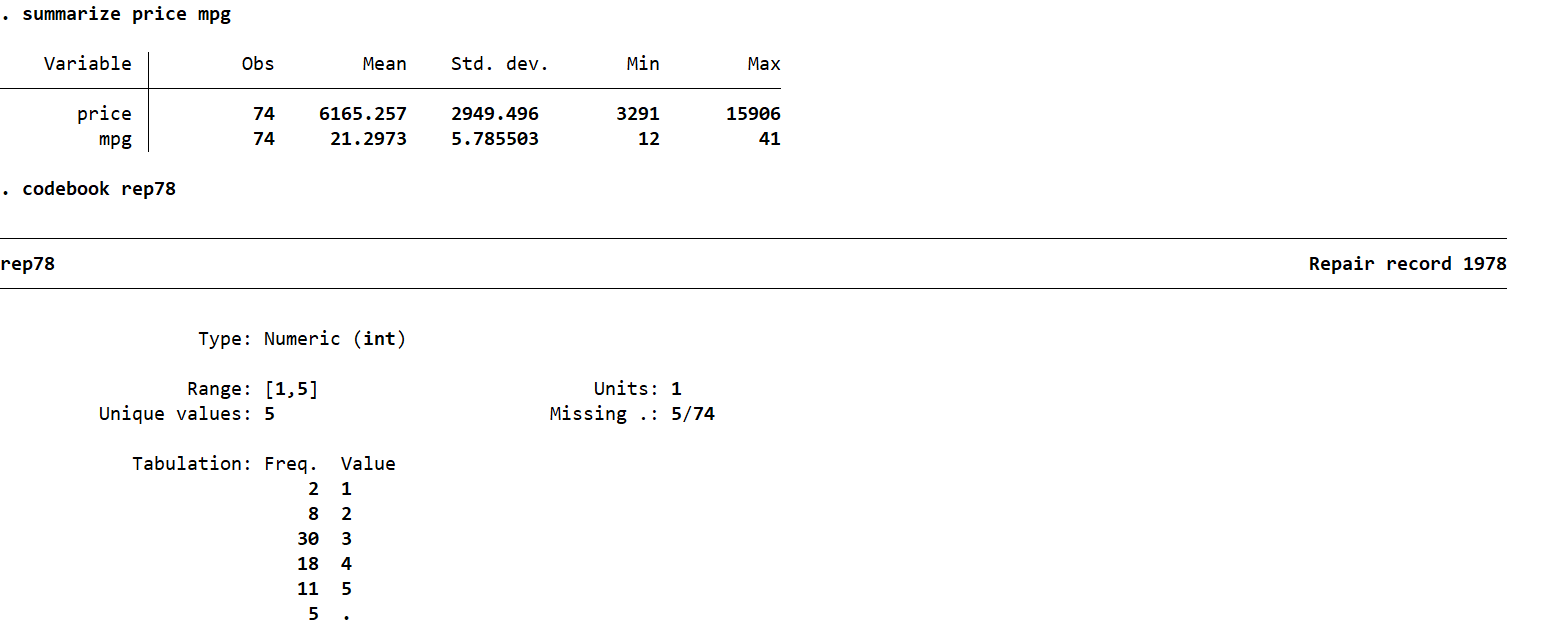
summarize可以看表格的一些统计信息、codebook则是对表格的各列进行统计。它们后面可以跟着列名,则只显示这几列的信息,否则显示所有列:
summarize price mpg
codebook rep78
如下图所示:
tabstat可计算某种统计值,统计值种类比sum和codebook多,当做print来用吧:
tabstat price, by(rep78) stat(std max min)
以上显示车价格,在rep78的各个条件下的标准差、最大值和最小值。想要其他统计值,用help查看简写方法╮(╯▽╰)╭。
变量生成与替换 gen egen
gen和egen用于生成变量,gen是一对一生成,egen是一对多生成(比如max()值会赋值到每一行上)。如:
gen test1 = 2*price
egen test2 = max(price)
replace用于变量的替换,如:
replace test1 = test2 in 1/10
将test1的前10行数据替换为test2。其中的in在很多其他对行进行操作的命令中也可以使用。
另外要注意的是,不像matlab,STATA中的操作不能直接使用,必须要进行赋值,也就是用gen等命令生成某列,否则会报错。
基于某列取值下的分析 by
如果想在某列的各个不同的取值下,对其它列进行分析,可以用by,用法如下:
by foreign, sort: sum price
表示在foreign的各个取值下,获取price一些基本统计信息(sum就是summarize)。其中,如果by后面的变量没有排序,则必须要加sort,会先对其进行排序,否则会出错(默认排序不就行了?)。
如果想在某列特定取值下进行分析,可以用if:
sum price if foreign == 0
安装外部命令
STATA的命令是很分散的,不像python、matlab把相似的命令、处理方法都打包在一块儿。所以有些外部命令没得用,只能一个一个安装。用help查询相关命令,然后进行安装:
help graph3d
统计命令
下面的命令使用软件自带的auto数据集。
数量统计tabulate
统计某列或某两列中不同取值的数量,用法就是后面跟着一个或两个变量:
tabulate mpg
tabulate mpg rep78
两个以上变量会报错。
相关性分析correlate
correlate分析变量的相关性,可以输入多个变量,用法如下:
correlate mpg price rep78
运行结果: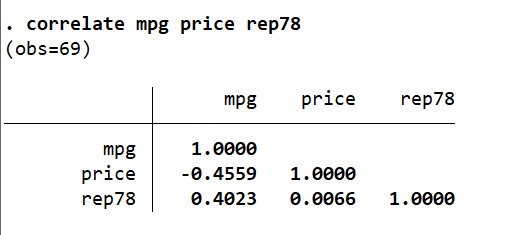
二维可视化twoway
twoway进行二维可视化,后面每个括号内都能画一个相应的可视化图。如下所示:
twoway (scatter length mpg) (lfit length mpg)
表示以length为y轴,mpg为x轴,绘制散点图和拟合一元一次方程。可视化结果如下:
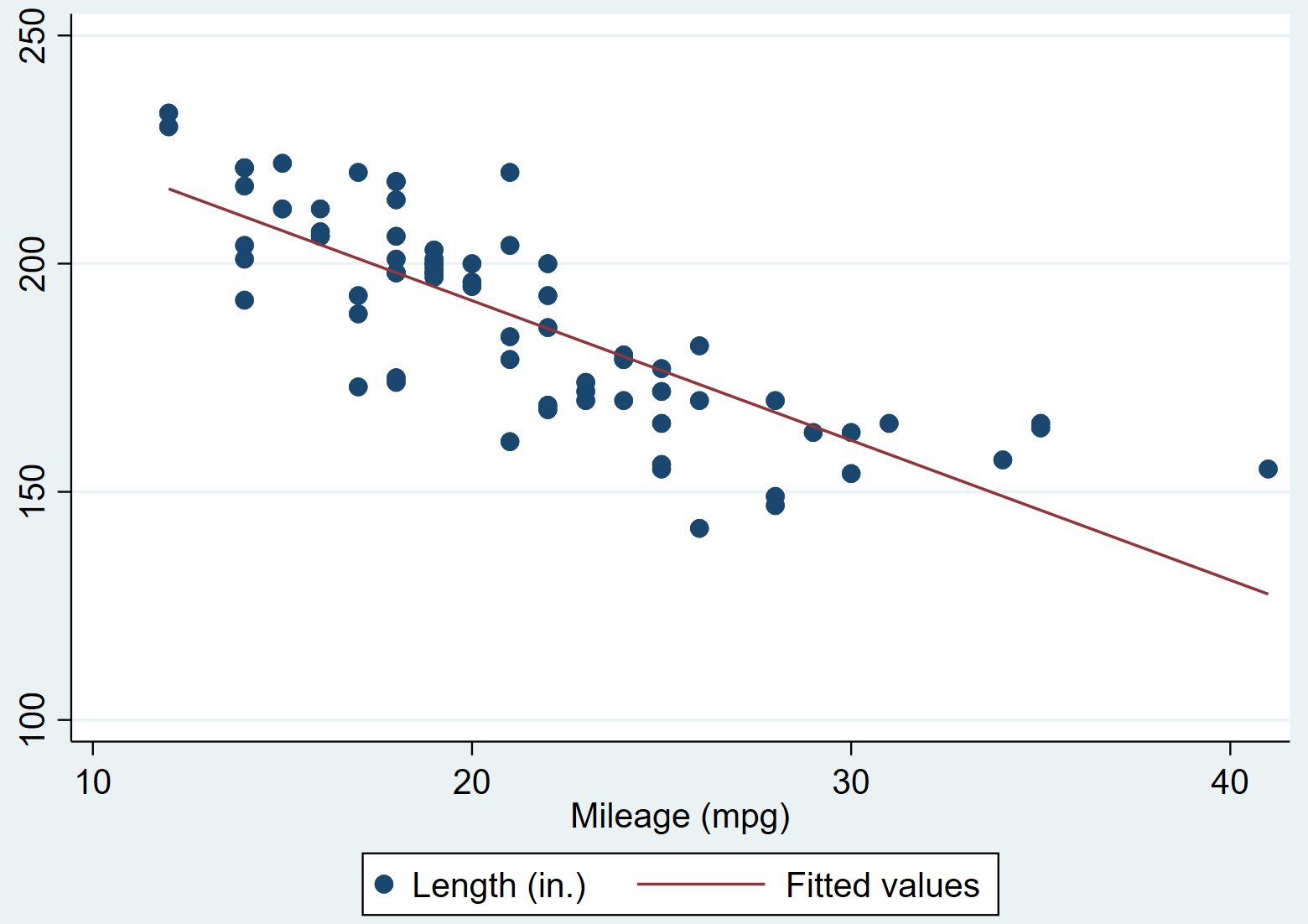
再加by可以在某个变量的各个取值下分别进行可视化:
twoway (scatter length weight) (lfit length weight), by(foreign)
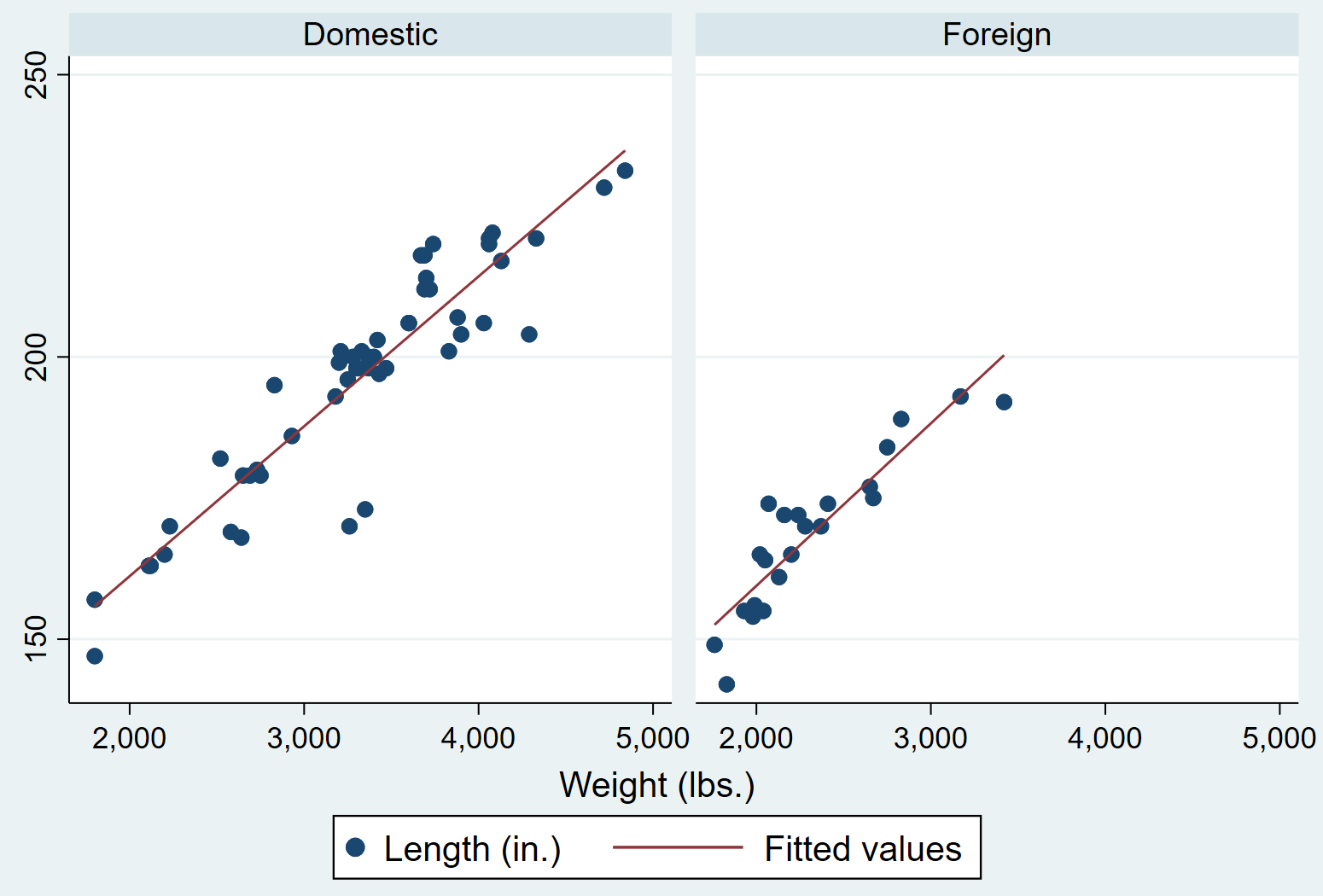
回归regress
基本用法
使用几列数据对某列数据进行线性回归。比如,使用mpg、rep78、length作为因变量,对price进行回归,用法如下:
regress price mpg rep78 length
结果:
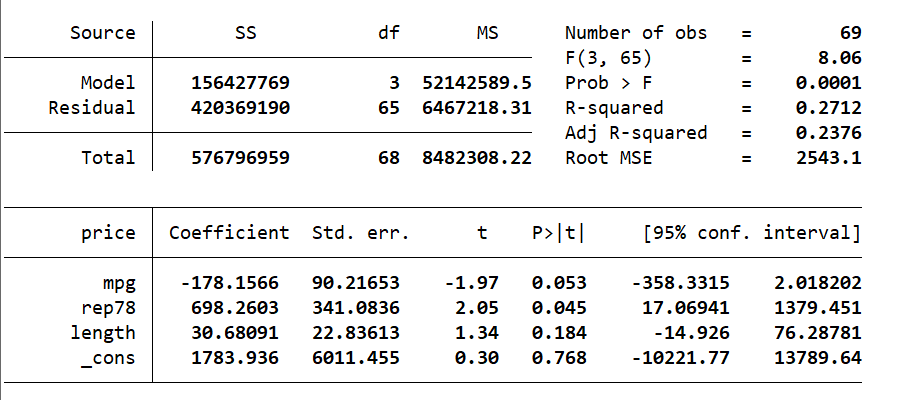
我们可以进行一个测试,创建test变量为price、mpg、weight的线性和,然后进行回归:
gen test = price*2+mpg*3+weight*456+789
regress test price mpg weight
结果:
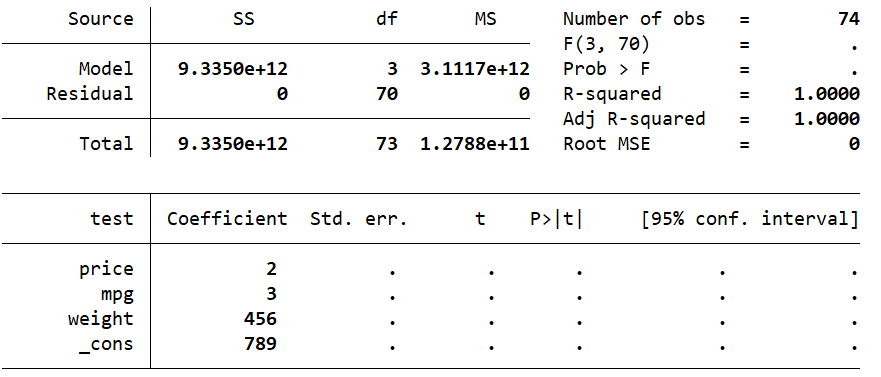
可以看出线性回归得到的系数与创建的一模一样。之后还可以使用predict创建回归值和回归偏差:
predict test_hat
predict test_res, res
结果如下:
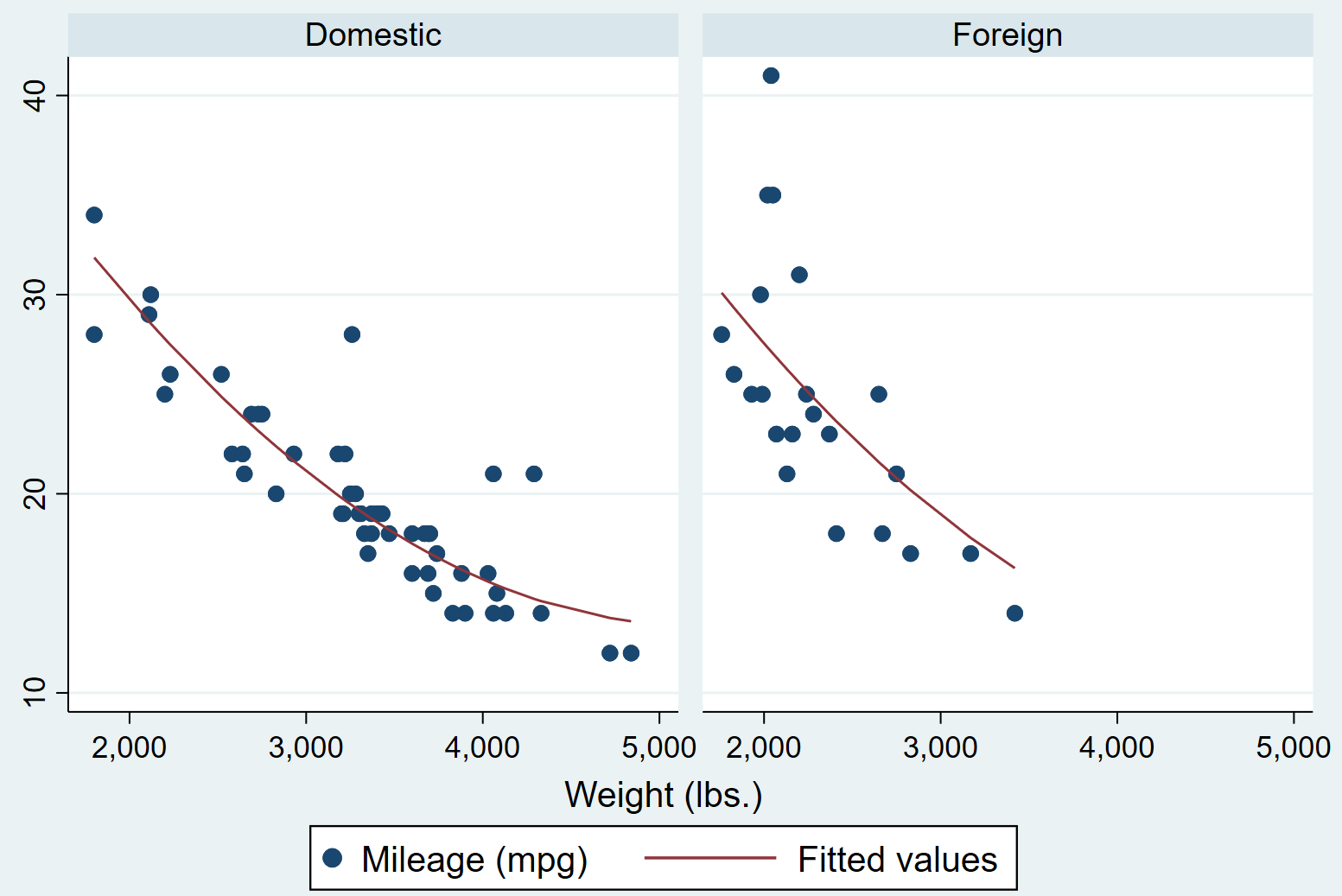
二次以上的回归方式
如果想进行二次回归,可以先创建因变量的平方,然后使用一次、二次变量作为因变量进行回归:
gen weight2 = weight^2
regress mpg weight weight2 foreign
predict mpg_hat
sort weight
twoway (scatter mpg weight) (line mpg_hat weight), by(foreign)
分别按国内外汽车进行了车重和油耗的二次关系的统计,结果如下:
STATA数据统计软件学习记录的更多相关文章
- 大数据kafka视频教程 学习记录【B站尚硅谷 】
视频地址: https://www.bilibili.com/video/av35354301/?p=1 2019/03/06 21:59 消息队列的内部实现: Kafka基础: ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- 大数据学习day33----spark13-----1.两种方式管理偏移量并将偏移量写入redis 2. MySQL事务的测试 3.利用MySQL事务实现数据统计的ExactlyOnce(sql语句中出现相同key时如何进行累加(此处时出现相同的单词))4 将数据写入kafka
1.两种方式管理偏移量并将偏移量写入redis (1)第一种:rdd的形式 一般是使用这种直连的方式,但其缺点是没法调用一些更加高级的api,如窗口操作.如果想更加精确的控制偏移量,就使用这种方式 代 ...
- 【分享】SAS统计分析软件学习教程电子书合集下载
SAS是著名的统计分析软件,全称为Statistics Analysis System,最早由北卡罗来纳大学的两位生物统计学研究生编制,并于1976年成立了SAS软件研究所,正式推出了SAS软件. 转 ...
- Thrift学习记录
Thrift学习记录 Thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发.它结合了功能强大的软件堆栈和代码生成引擎,以构建在C++,Java,Python,PHP,Ruby,Erlang, ...
- 我的Spring学习记录(五)
在我的Spring学习记录(四)中使用了注解的方式对前面三篇做了总结.而这次,使用了用户登录及注册来对于本人前面四篇做一个应用案例,希望通过这个来对于我们的Spring的使用有一定的了解. 1. 程序 ...
- 学会C sharp计算机编程语言 轻松开发财务、统计软件
就像人们用同一种语言才可以顺畅交流一样,语言是计算机编程的根本,是IT世界交流的工具.运用这些计算机语言,人们可以创造出一个美妙的世界.你点击某个网页或是安装一个应用程序软件,这简简单单动作的背后,就 ...
- 韩天峰博客 php基础知识学习记录
http://rango.swoole.com 写好PHP代码真的不容易,给大家几个建议: 慎用全局变量,全局变量不好管理的,会导致你的代码依赖于全局变量,而耦合度太高. 一定不要复制粘贴代码,可重用 ...
- Ganlia采样、统计及RRD记录周期(频次、间隔)的配置和更改
Ganglia & RRD Ganglia是伯克利开发的一个集群监控软件.可以监视和显示集群中的节点的各种状态信息,比如如:cpu .mem.硬盘利用率, I/O负载.网络流量情况等,同时可以 ...
随机推荐
- 【Burp Suite】Mac之破解明文密码
一.安装CA证书 安装证书是为了代理的时候可以继续访问地址,否则的话会提示网络异常 参考文章:<Mac系统Burp Suite的安装>,文章中是火狐浏览器的操作 1.谷歌浏览器 选择导出的 ...
- WebShell流量特征检测_蚁剑篇
80后用菜刀,90后用蚁剑,95后用冰蝎和哥斯拉,以phpshell连接为例,本文主要是对这四款经典的webshell管理工具进行流量分析和检测. 什么是一句话木马? 1.定义 顾名思义就是执行恶意指 ...
- 【转】如何在ASP.NET Core自定义中间件中读取Request.Body和Response.Body的内容?
文章名称: 如何在ASP.NET Core自定义中间件读取Request.Body和Response.Body的内容?作者: Lamond Lu地址: https://www.cnblogs.com/ ...
- Coursera, Big Data 5, Graph Analytics for Big Data, Week 3
Graph Analytics 有哪些类型 node type (labels) node schema: attributes 组成了schema. 同样的, Edge也有 Edge Type 和E ...
- 爬虫案例1-爬取图片的三种方式之一:selenium篇(2)
@ 目录 前言 selenium简介 实战 共勉 ps 博客 前言 继使用requests库爬取图片后,本文使用python第三方库selenium来进行图片的爬取,后续也会使用同样是自动化测试工具D ...
- 合合信息亮相新加坡科技周——Big Data & AI World Expo展示AI驱动文档数字化的前沿能力
合合信息亮相新加坡科技周--Big Data & AI World Expo展示AI驱动文档数字化的前沿能力 展会规模背景: 2023年10月11日-12日,合合信息在TECH WEEK ...
- Nuxt Kit 中的上下文处理
title: Nuxt Kit 中的上下文处理 date: 2024/9/16 updated: 2024/9/16 author: cmdragon excerpt: Nuxt Kit 提供的上下文 ...
- JavaScript习题之判断题
1. JavaScript是Java语言的脚本形式.( ) 2. JavaScript中的方法名不区分大小写.( ) 3. JavaScript语句结束时的分号可以省略.( ) 4. 通过外链式引入J ...
- 80篇国产数据库实操文档汇总(含TiDB、达梦、openGauss等)
国产数据库发展得如火如荼,数据库的国产化替代也正在进行中.最近,有越来越多的朋友都加入了学习国产数据库的队伍中,本文便选取了墨天轮技术社区的国产数据库流行度排行榜上排名靠前的几个数据库,整理了相关的实 ...
- electron 菜单选项 - 隐藏,设置菜单
隐藏菜单 const { app, Menu, session } = require('electron'); /*隐藏electron的菜单栏*/ Menu.setApplicationMenu( ...