Java集合--HashMap底层原理可视化,秒懂扩容、链化、树化
文章内容较长,带着疑问慢慢读。
哈希冲突问题如何高效解决?
1. 什么是冲突?
准确的说是解决哈希值映射冲突,而非解决哈希冲突。
哈希冲突指的是不同的key计算出来的哈希值相同而产生的冲突。
但这里是,不同的哈希值映射到相同的数组槽位置,而产生的存储位置冲突。
哈希表把 key 计算出哈希值后映射成整数 index,放到固定长度的数组槽(bucket)里。
当两个不同的 key 经过哈希函数后映射到相同的槽位,就发生了冲突。例如:
hash("abc") & (tableSize - 1) == 3
hash("xyz") & (tableSize - 1) == 3
这两个不同的key 计算出来的哈希值不同,但都会被放到索引 3 的桶里。
关于这个问题可查阅上一篇文章:HashMap如何快速定位数据存储在内存地址的位置?。
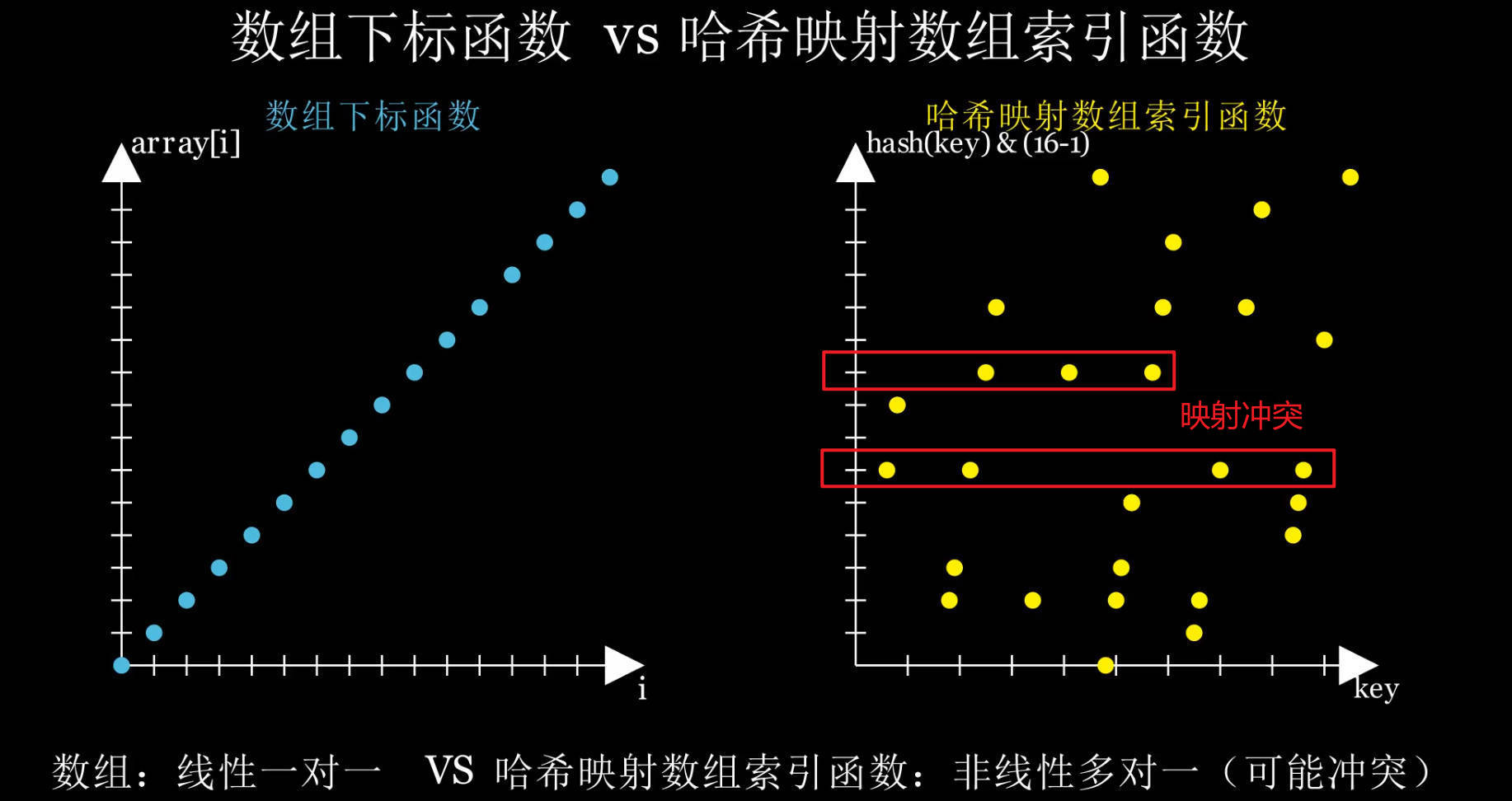
但很多人都会将其称为哈希冲突,为了“达成共识”,后面都会把映射冲突和哈希冲突都称为哈希冲突。
2. 如何解决哈希冲突?
主要有 两大类方法:
开放寻址法(Open Addressing)
所有元素都直接存放在哈希表数组里,没有链表。
一旦发生冲突,就在数组里按一定探测规则继续找下一个空槽位。
常见策略:
| 方法 | 原理 |
|---|---|
| 线性探测(Linear Probing) | 下一个槽位是 (index + 1) % tableSize |
| 二次探测(Quadratic Probing) | 距离按平方增加,如 (index + i^2) % tableSize |
| 双重哈希(Double Hashing) | 用另一个哈希函数求探测步长 |
特点:适合占用率低时(负载因子 < 0.7);一旦负载高就容易产生聚集,效率下降。
链地址法(Separate Chaining)
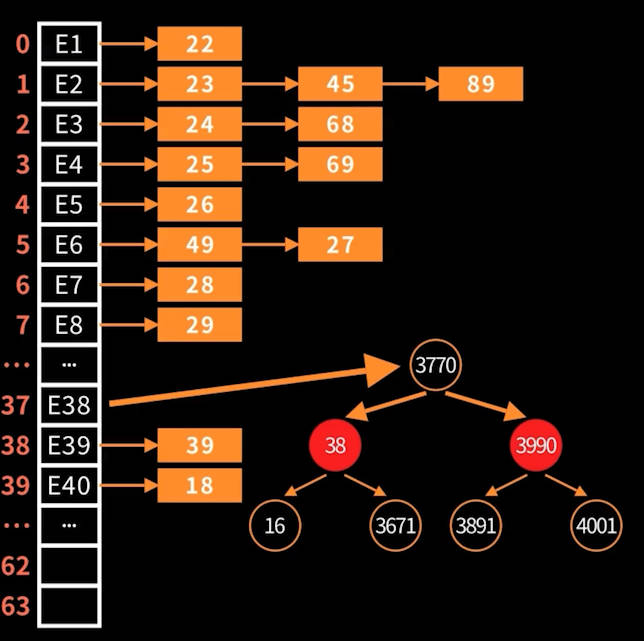
每个槽位维护一个 桶(链表或红黑树);冲突的元素插入到该槽位的桶结构里。
HashMap 就是这样做的:
早期 JDK:每个桶是一个链表
JDK 8+:当链表长度超过阈值 8,同时桶的大小>=64时,自动转成红黑树,提升查找效率
特点:实现简单,扩容后负载高也不怕冲突太多;空间换时间(每个桶需要额外引用);适合高负载且需要稳定性能的场景。
HashMap的数据结构:数组+链表/红黑树
3. 怎么提升效率?
好的哈希函数:HashMap 会对 hashCode 做扰动(高位参与低位),保证桶索引分布更均匀。
链地址法:每个槽位维护一个 桶;冲突的元素插入到该槽位的桶结构里。
优秀桶结构:链表长度有阈值(8)控制,确保不会退化成O(n);自平衡二叉查找树--红黑树,确保查找效率为 O(log n)。并且有负载阈值触发动态扩容,不会让红黑树无限扩大。
动态扩容:当负载因子(元素数量 / 桶数量)超过阈值(默认 0.75),就会扩容(桶数量 * 2),扩容会重新计算所有元素的桶索引,让冲突的元素再次分散开来,从而减少冲突。
HashMap高效归纳为:好哈希函数 + 链地址法 + 优秀桶结构 + 动态扩容四件套组合,保证冲突多时依然高效。
4. 扩容
扩容,扩的都是数组的容量。
有三种情况会触发扩容
初次插入数据时的扩容,不管是否构造函数指定大小创建
HashMap都是插入才扩容;数组(桶)小于64,并且单链表 >8 时的扩容
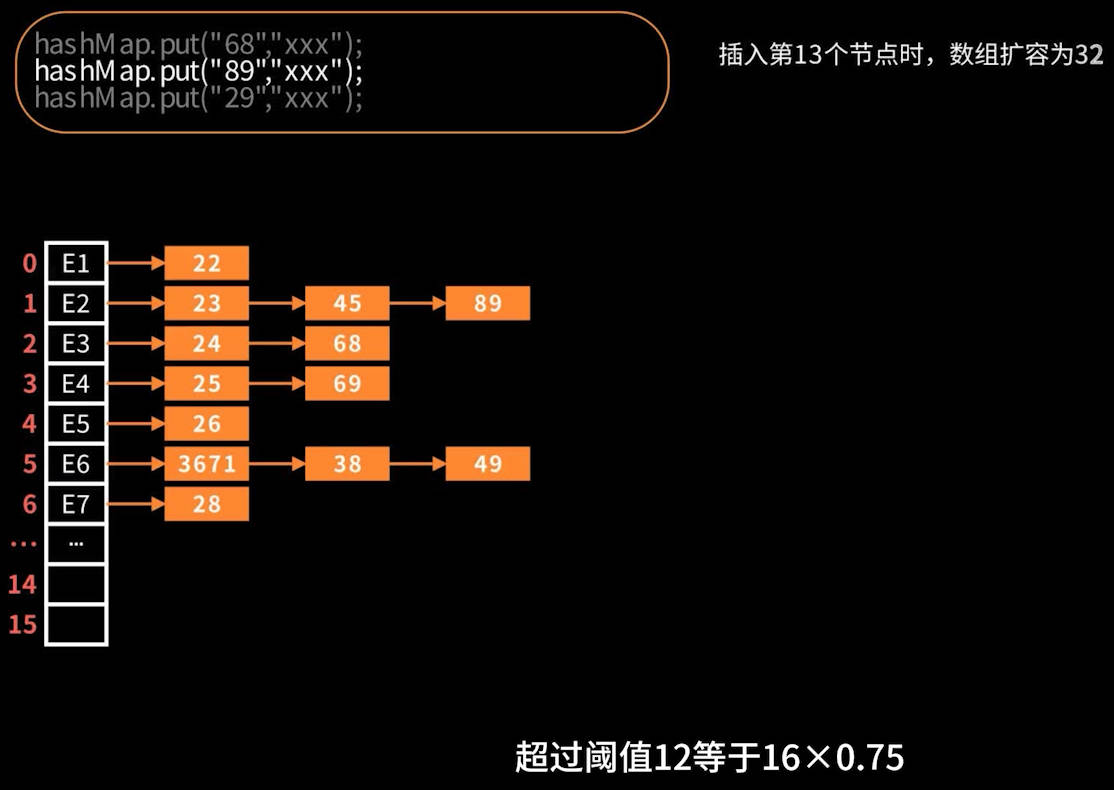
默认情况,使用容量 > 存储容量的loadFactor倍(存储容量的75%)
比如,大于阈值的扩容过程
触发条件满足:size > threshold = newCap × loadFactor
计算新容量:newCap = oldCap << 1(翻倍),最高 MAXIMUM_CAPACITY。
接着重设阈值:threshold = newCap × loadFactor。
最后迁移节点(再哈希):所有已有节点需重新按照新容量 newCap 计算索引,分布到新的桶数组中。链表可按 hash & oldCap 判定留在原地或移到 index + oldCap,减少再次哈希开销。
以下将从四次扩容来逐渐掌握整个HashMap的扩容机制。
5. 第一次扩容(首次扩容)
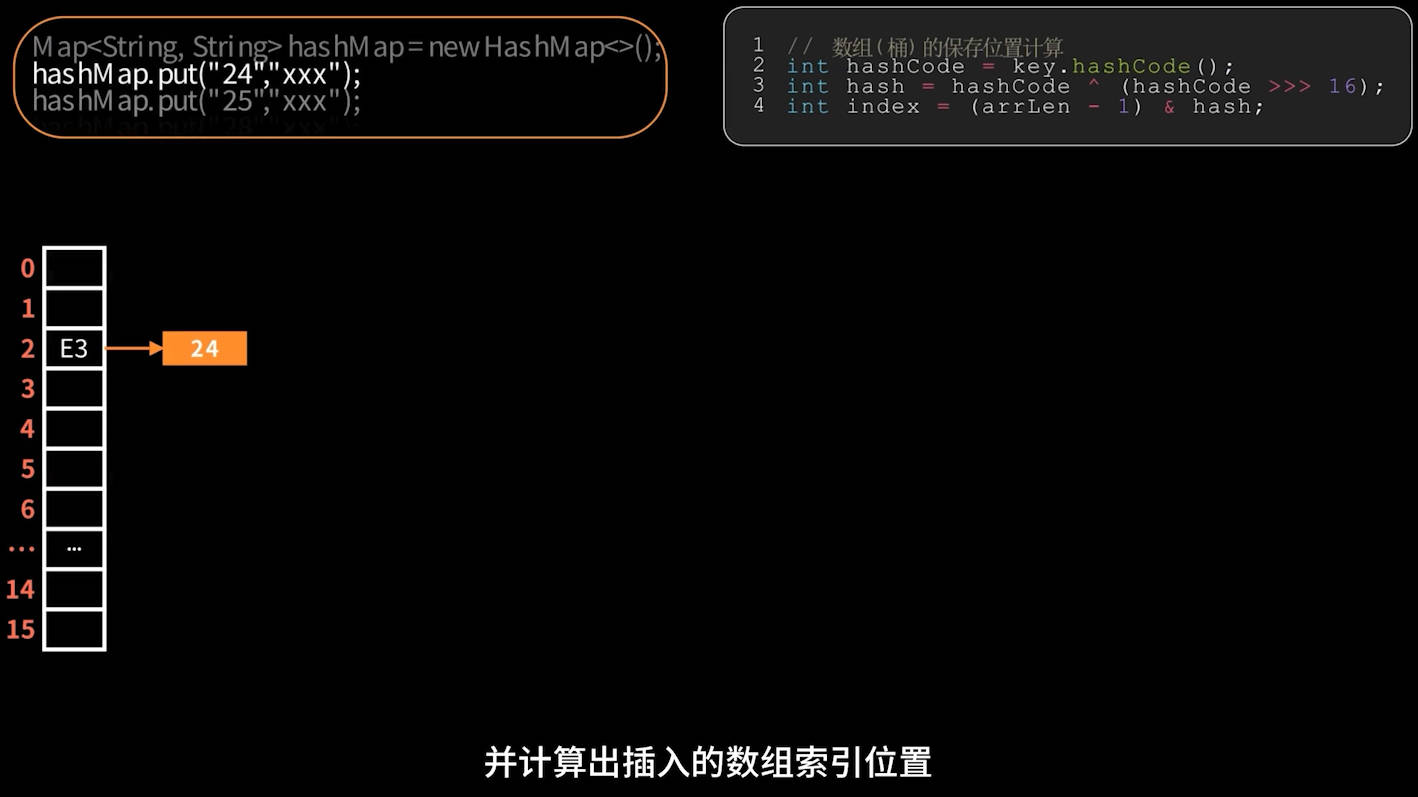
在首次插入元素时,先进行首次扩容,默认扩容为16。
链表挂载
插入元素时初次冲突:链表挂载,非首次冲突的需要遍历链表找相同 key 或添加到尾部,部分源码如下:
if (table[index] == null) {
table[index] = newNode(hash, key, value, null);
} else {
// 已有节点,遍历链表找相同 key 或添加到尾部
}
若 table[idx] 为空,则直接放入新节点。
否则沿链表遍历:
- 若遇
key.equals(oldKey),则替换旧值。 - 否则追加到链表尾。
tableSizeFor 方法的巧妙作用
如果指定大小的情况,会被方法int tableSizeFor(int cap)转为2的倍数大小。比如指定大小为5,那么得到的是大小为8;指定大小为16,那得到的大小为16。
tableSizeFor方法的作用:让哈希表内部桶数组的长度总是 2 的幂,保证hash & (length - 1)能高效工作。只要保存了hash值,就可以通过
hash & (length - 1)来获取到key的桶位置,这个运算在源码中会经常用到。
该方法的源码如下:
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
该方法是后续高效处理 key 的重要基础。
首次插入元素图示:
每次扩容都会:
重新计算新容量:
newCap = oldCap << 1(翻倍),重设阈值:
threshold = newCap × loadFactor。
当使用容量超过阈值threshold,便会触发下一次扩容,比如下图所示:
6. 第二次扩容(树化前扩容)
树化前的扩容规则都相对简单
只有一个节点的链表,直接计算
hash & (32 - 1)新位置插入即可;不止一个节点的链表,按照
hash & 16==0拆分成低位、高位两个链表,然后再插入。
重点在于理解:hash & oldCap ==0 为什么可以区分高低位?
hash & oldCap ==0的完全理解
oldCap是扩容前的容量,我们都知道扩容前数组(桶)的位置计算公式为hash&(oldCap-1),下面通过一个案例来完全理解并掌握它:

认真看完图中的案例,我们可以发现公式hash & 16 ==0的计算使用到的二进制位,正是扩容后公式hash&(32-1)使用的最高位二进制位,即案例中哈希值的第5位二进制位。
而哈希值的二进制只有0 和1,故,hash & oldCap 计算结果为0,说明扩容后,该节点保持原位不动;不为0,则必为原数组大小。
所以你会看到源代码会有这么一行代码:newTab[j + oldCap] = hiHead;
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
这个拆分规则成立的前提条件是:哈希表内部桶数组的长度总是 2 的幂,并且每次扩容都是翻倍。
为什么要拆分成高低位链表?
直接计算hash & (32 - 1)便可轻松实现扩容后的插入了,而且计算效率一致,为什么还要拆来拆去搞得那么复杂呢?
为了更高效
如果直接计算数组索引位置,那就需要遍历变量数组(桶)上的链表,找到最后一个节点才可以插入。而拆分高低位只需要插入最多两次数组(桶)即可,通过临时定义的尾部节点,计算完即可尾部插入形成链表,最后在插入到数组(桶),本质也是空间换时间。
7. 第三次扩容(树化前扩容)
这次让单个链表插入第9个节点,从而触发扩容。注:插入超过容量阈值也可以触发扩容,这里为了展示
树化前的扩容规则都相对简单,和第二次扩容规则完全一样,只是触发扩容的条件不同而已。
只有一个节点的链表,直接计算
hash & (64 - 1)新位置插入即可;不止一个节点的链表,按照
hash & 32==0拆分成低位、高位两个链表,然后再插入。
拆分低位、高位的大概过程动画如下:

链表树化(Treeify)
这次扩容重点在于链表树化的学习。
树化的条件:TREEIFY_THRESHOLD为链表长度阈值
- 当前桶链表长度 >
TREEIFY_THRESHOLD(8) - 整个表容量 ≥
MIN_TREEIFY_CAPACITY(64)
如果条件符合,将该桶的链表转换为红黑树,节点类型由链表节点 Node<K,V> 被替换为 TreeNode<K,V>,查找、插入、删除最坏 O(log n)。若容量 < 64,则优先扩容而非树化。
触发链表树化的主要源码:
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
触发链表树化的条件if (binCount >= TREEIFY_THRESHOLD - 1) ,binCount=7的时候就会触发树化,因为binCount是p.next的次数,并且binCount从0开始的,也就是说循环了8次,在这里别搞混了。
还有一点就是,链表是插入第9个节点时才进行的树化,可看源码,是先插入节点后进行判断的;故此树化前的链表长度已变成9了,所以链表树化前的链表长度为9。
链表树化分两步
通过treeifyBin(tab,hash)方法完成链表树化操作。主要分为两步:
先将链表的Node节点,转化成TreeNode节点,关键源码:
TreeNode<K,V> p = replacementTreeNode(e, null);再进行真正树化,关键源码:
hd.treeify(tab)。
通过案例感受下:
将单个链表插入第9个节点,使其超过单链表长度阈值,此时数组大小为64,条件满足触发链表树化,可视化过程如图:

红黑树节点插入、染色、平衡的过程,不在这里展开,可单独学习红黑树数据结构。如果想要看HashMap红黑树数据结构的可视化视频的,可以在评论区留言,我抽时间把源代码完全还原出来。
红黑树插入、删除和树化完成都会调用这个方法moveRootToFront(tab, root),因为这些操作都有可能导致根节点发生变化,该方法的作用是确保数组(桶)始终指向红黑树的根节点。
8. 第四次扩容(树化后扩容)
然后插入满75%的容量,触发第四次扩容。扩容规则如下:
1.只有一个节点的链表直接计算位置插入;
2.如果是红黑树,按照hash&64==0?分低位、高位拆分成两个链表,\n判断双链表的长度,节点数<=6 时,树转链表;节点数>6时,正常树化",再插入;
3.不止一个节点的链表,按照hash&64==0?分低位、高位拆分成两个链表,再插入
链表的调整前面已经讲过,重点关注红黑树在扩容期间如何操作的。
扩容期间,如果数组(桶)指向的是红黑树节点,那么就会调用split方法完成处理。
处理过程分为三步:
使用红黑树的双链结构TreeNode的next节点进行遍历;
根据
(hash & bit) == 0拆分成低位和高位两条TreeNode节点的双链结构;判断低位和高位双链表长度是否 <= 链化阈值
UNTREEIFY_THRESHOLD,阈值默认为6;长度<=6的,先链化,再放入数组(桶);反之,先放入数组(桶),再树化,树化逻辑和前面的一样。
红黑树链化(untreeify)
链化操作其实很简单,只要将TreeNode节点转化为Node节点即可,关键源码Node<K,V> p = map.replacementNode(q, null)。
看一个可视化案例就明白了:

9. 总结
HashMap做一个全面梳理,涵盖:冲突处理(链地址法)、扩容流程、链表–红黑树(树化/链化)转换的处理。通过四次扩容,渐进式的对 HashMap 扩容及相关操作有一个基本而完整的理解。

查看往期设计模式文章的:设计模式
原创不易,觉得还不错的,三连支持:点赞、分享、推荐↓
Java集合--HashMap底层原理可视化,秒懂扩容、链化、树化的更多相关文章
- 1.Java集合-HashMap实现原理及源码分析
哈希表(Hash Table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常 ...
- Java 集合 HashMap & HashSet 拾遗
Java 集合 HashMap & HashSet 拾遗 @author ixenos 摘要:HashMap内部结构分析 Java HashMap采用的是冲突链表方式 从上图容易看出,如果选择 ...
- 最简单的HashMap底层原理介绍
HashMap 底层原理 1.HashMap底层概述 2.JDK1.7实现方式 3.JDK1.8实现方式 4.关键名词 5.相关问题 1.HashMap底层概述 在JDK1.7中HashMap采用的 ...
- HashMap底层原理分析(put、get方法)
1.HashMap底层原理分析(put.get方法) HashMap底层是通过数组加链表的结构来实现的.HashMap通过计算key的hashCode来计算hash值,只要hashCode一样,那ha ...
- [转]java 的HashMap底层数据结构
java 的HashMap底层数据结构 HashMap也是我们使用非常多的Collection,它是基于哈希表的 Map 接口的实现,以key-value的形式存在.在HashMap中,key-v ...
- Java集合---HashMap源码剖析
一.HashMap概述二.HashMap的数据结构三.HashMap源码分析 1.关键属性 2.构造方法 3.存储数据 4.调整大小 5.数据读取 ...
- [转载] Java集合---HashMap源码剖析
转载自http://www.cnblogs.com/ITtangtang/p/3948406.html 一.HashMap概述 HashMap基于哈希表的 Map 接口的实现.此实现提供所有可选的映射 ...
- Java集合 HashSet的原理及常用方法
目录 一. HashSet概述 二. HashSet构造 三. add方法 四. remove方法 五. 遍历 六. 合计合计 先看一下LinkedHashSet 在看一下TreeSet 七. 总结 ...
- Java面试& HashMap实现原理分析
1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二分查找时间复杂度小,为O( ...
- Java集合--HashMap分析
HashMap在Java开发中有着非常重要的角色地位,每一个Java程序员都应该了解HashMap. 本文主要从源码角度来解析HashMap的设计思路,并且详细地阐述HashMap中的几个概念,并深入 ...
随机推荐
- Lambda表达式的省略规则、Lambda和匿名内部类的区别--java进阶day03
1.省略规则 2.流程讲解 主方法中调用useStringhandler,该方法的形参是接口,所以我们要给实现类对象,这里我们使用匿名内部类 use...方法进栈,形参也是变量,接收到匿名内部类(如下 ...
- while循环、dowhile循环、三种循环的区别
1.while循环 案例:使用while循环,打印出水仙花数 while执行流程: 1.先执行初始化语句 2.执行判断条件 结果为true,则执行第3步 结果为false,循环结束 3.执行循环体语句 ...
- 【QT】解决生成的exe文件出现“无法定位程序入口”或“找不到xxx.dll”的问题
[QT]解决生成的exe文件出现"无法定位程序入口"或"找不到xxx.dll"的问题 零.问题 使用QT编译好项目后,想直接在文件资源管理器中运行exe程序或想 ...
- javascript 字符串截取
<script> //字符截取(需要的字符长度) function cut_str(need_str_length){ var bag_set = document.getElem ...
- ubuntu 22.04安装harbor
一.概述 Harbor 是一个企业级的云原生容器镜像仓库,由 VMware 开发并贡献给 Cloud Native Computing Foundation (CNCF).它在传统的 Docker R ...
- 使用Python建立双缝干涉模型
引言 双缝干涉实验是物理学中经典的实验之一,它展示了光的波动性以及量子力学的奇异性.实验结果表明,当光或粒子通过两条狭缝时,它们会产生干涉现象,形成明暗相间的条纹图案.这种现象不仅说明了光的波动性,还 ...
- v-bind,v-if,v-for,v-on,v-model基本用法
总结: 1.v-bind绑定数据:标签属性v-bind:title='xxx',简写:title='xxx', 标签内容{{xxx}} <span :title='message'>{{m ...
- SVN统计时间段内代码修改行数
1.本地安装svn客户端(方法自行百度) 注:安装时记得勾选命令行工具 若原安装未勾选,可再次启动安装文件: 选中Next即可: 环境变量记得配置svn路径(bin)(方法自行百度) cmd运行命令 ...
- @Accessors lombok注解用法
最近学习代码看到很多有趣的注解:慢慢整理下: @Accessors注解 @Accessors注解官方给出的解释是:面向getter和setter的更流畅的API.用于生成和查找getter和sette ...
- Selenium反屏蔽处理
Selenium自动化过程,在浏览器内会显示如下字样 当出现此内容时,有些网站就会判定是机器在进行操作,然后网站会加载防机器操作程序,如下图滑块验证 触发反机器操作的原理大概如下 解决方法 具体代码, ...