MobiSys'2022 CoDL论文详解
算子切分
.png)
在了解算子切分前,先了解一下卷积的运算过程,作者将算子切分分为了两个维度的切分:OC维度和H维度,没有W维度可能与数据在内存中的存储方式有关。
OC维度切分
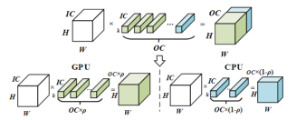
卷积就是OC数量个kernel_size×kernel_size×IC大小的卷积核与输入张量卷积计算后的输出叠加,因此从OC维度上切分,将OC×ρ个卷积核放在CPU上,OC×(1-ρ)个卷积核放在GPU上计算是容易理解的。
H维度切分
.png)
从H维度上切分,如果H * ρ = kerne_size + stride * n ,那切分与不切分的结果是可以等效的,负责就需要从切分位置进行填充,经过这一操作后,特征图也会增大。
不同维度划分对比
.png)
作者以YOLO中的卷积为例,测试了不同大小卷积通过两个维度切分后的加速效果对比,切分比例为0.5。文中给出的解释是:
The reason is that partitioning may reduce processor utilization compared to , depending on the operator shape. To utilize the inter-core and intra-core parallelism of a processor, the tensors of an operator need to be divided into blocks and scheduled to run on different cores. Take the GPU as an example shown in Fig. 11. A block named as a work group is scheduled to run on a GPU core. To efficiently utilize the many ALUs in a core, the basic execution unit named as a warp executes the same instruction for a number of threads (e.g., 64 or 128) simultaneously. Therefore, a work group should provide enough threads to fill up the warps. Or there will be idle ALUs.
作者提出与 OC 相比,H 分区可能会降低处理器利用率,计算任务分配给SM,每一个SM会有32个线程束,每一个线程数有64或者128线程,每一个线程在一个ALU上计算,线程较少,一些ALU会空闲。(这里建议看一下OPenCL后端怎么进行矩阵乘的)
Op_chain
Op
.png)
我们已经理解了算子切分,算子切分会带来一些开销,其中包括CPU和GPU的数据转化,数据的映射的开销。如果一个算子进行一次划分,那么数据映射带来的开销势必会非常大,因此将多个算子链接起来形成Op_chain,只在链头和链尾进行数据共享,如下图所示:
.png)
H维度的推理时延更快,但是需要进行填充,因此在过程中,chain越长,特征图越大,冗余计算也就越多。
.png)
随着链长的增加,由于填充带来的计算开销会覆盖掉链状结构带来的增益,因此链的长度抉择十分重要,在这里作者测试了最大链长度为8。
Op_chain搜索策略
.png)
上述算法在不断连接新的算子,直到不再获得收益。ParPlan是模型的算子集合(按照推理顺序排列),ParPlan[i]包括( , , , , , ), , ,其中( , , , , , ) 就是论文中的ophead,分别表示算子链的头,以及头的划分维度和划分比例。
对于每一条链的头,将当前的链收益Tgain和最大收益TmaxGain初始化为0,将划分比例[ρhead-δ, ρhead+δ] 内的大收益记录在TmaxGain 。对每一个划分比例ρ 进行以下操作:
初始化chaincur为头算子,划分维度和划分比例,Tchain初始化为头的预测时间。Tnochain为不添加该算子进入链,当前链与当前算子的时间相加,而Tchain则为将算子入链之后的链推理时长。Tgain是Tchain-Tnochain ,即将算子添加到当前链的收益,收益大于Tmaxgain就更新。
当上述过程结束后,从链尾后的第一个op开始初始化为新的ophead。
CoDL架构
.png)
CoDL分为两个阶段,离线估计阶段和在线阶段:
离线阶段,CoDL设计了一个轻量级但有效的延迟预测器来指导在线阶段的操作员分区。预测器既可以实现轻量级又有效,因为 1) 它考虑了所有数据共享开销,包括数据转换、映射和同步; 2)它解析地制定了平台特征引起的非线性延迟响应,只需要为每个内核实现学习一个极其轻量级的线性回归模型来学习基本执行单元的延迟。
在线阶段由两个模块组成,即算子分区器和算子协同执行器。算子分区器的作用是为输入 DL 模型找到最佳算子分区计划,它采用混合维度划分和算子链两种技术来完成这一作用。分区器首先找到最佳分区维度(高度或输出通道)和比率(例如 0.1、0.2) ,对于每个算子作为基础计划,通过混合维度分区技术。分区器的最终分区计划是找到的链的集合,每个链运算符和链设置,即分区比率和维度。使用计划,为 GPU 和 CPU 预先安排模型权重,以避免对每个推理调用进行重新转换。
延迟预测器
在前面的介绍已经知道算子切分的开销包括:映射,前同步,推理,后同步,解映射,论文提出,相取消映射和后同步的开销是微不足道的(~ 50s)。因此,运算符协同执行的总预测延迟is如下图,其中,,-和分别表示数据转换,映射,预同步和计算的延迟。
.png)
.png)
图14(a)所示,和与数据大小有明显的线性关系,使用以数据大小为特征的线性回归来学习预测器中和的延迟。对于预同步开销-,根据我们的测量,没有明显的模式,-主要依赖于厂商的驱动实现。因此,我们在预测器中使用测量的上界(1)作为- 。
CPU和GPU的时延预测
.png)
GEMM(General Matrix Multiplication,通用矩阵乘法)和Winograd算法都是用于加速卷积神经网络(CNN)中卷积操作的计算方法。
GEMM是一种基础线性代数运算,输入数据通常会通过im2col或类似的变换被重新排列成矩阵形式,然后与滤波器权重矩阵相乘,通过使用高度优化的BLAS库(如Intel MKL、cuBLAS等)。
Winograd算法则是一种专门针对小尺寸卷积核设计的快速卷积算法。它减少了标准直接卷积所需的乘法次数,以更多的加法代替部分乘法,从而降低了整体计算复杂度,对于常见的3x3卷积核大小,Winograd可以在某些情况下提供显著的速度提升,该算法特别适合于硬件资源有限的环境,例如移动设备或嵌入式系统,在这些环境中,减少乘法操作可以带来明显的性能改进和功耗降低。
在实践中,一些深度学习库(如cuDNN)可能会根据具体情况选择最合适的算法组合来达到最佳性能。例如,在处理小型卷积核时,可能会优先考虑使用Winograd算法;而对于其他情况,则可能回退到基于GEMM的标准卷积实现。
MobiSys'2022 CoDL论文详解的更多相关文章
- Attention is all you need 论文详解(转)
一.背景 自从Attention机制在提出之后,加入Attention的Seq2Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型.传统的基于R ...
- R-CNN论文详解(转载)
这几天在看<Rich feature hierarchies for accurate object detection and semantic segmentation >,觉得作者的 ...
- The Google File System——论文详解(转)
“Google文件存储系统(GFS)是构建在廉价服务器之上的大型分布式系统.它将服务器故障视为正常现象,通过软件方式自动容错,在保证系统可用性和可靠性同时,大大降低系统成本. GFS是Google整个 ...
- Faster R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks ...
- Fast R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Fast R-CNN &创新点 规避R-CNN中冗余的特征提取操作,只对整张图像全区域进行一次特征提取: 用RoI pooling层取代最后一层max ...
- R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Rich feature hierarchies for accurate object detection and semantic segmentatio ...
- 图像处理论文详解 | Deformable Convolutional Networks | CVPR | 2017
文章转自同一作者的微信公众号:[机器学习炼丹术] 论文名称:"Deformable Convolutional Networks" 论文链接:https://arxiv.org/a ...
- 《The Tail At Scale》论文详解
简介 用户体验与软件的流畅程度是呈正相关的,所以对于软件服务提供方来说,保持服务耗时在用户能接受的范围内就是一件必要的事情.但是在大型分布式系统上保持一个稳定的耗时又是一个很大的挑战,这篇文章解析的是 ...
- 轻量化卷积神经网络MobileNet论文详解(V1&V2)
本文是 Google 团队在 MobileNet 基础上提出的 MobileNetV2,其同样是一个轻量化卷积神经网络.目标主要是在提升现有算法的精度的同时也提升速度,以便加速深度网络在移动端的应用.
- 第三十一节,目标检测算法之 Faster R-CNN算法详解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal network ...
随机推荐
- 【Pandas】concat方法使用注意点
使用pandas库的concat做数据拼接需要注意,应该先对原始数据设置列名,如果没有设置列名,在拼接时只会保留第一个文件的第一行(以列名形式),由于剩下的文件在读取时会自动将第一行作为列名,这样就会 ...
- RabbitMQ 延迟任务(限时订单) 思路
一.场景 我们经常会碰见,一个需求就是,发送一条指令(消息),延迟一段时间执行,比如说常见的淘宝当下了一个订单后,订单支付时间为半个小时,如果半个小时没有支付,则关闭该订单.当然实现的方式有几种,今天 ...
- Linux C线程读写锁深度解读 | 从原理到实战(附实测数据)
Linux C线程读写锁深度解读 | 从原理到实战(附实测数据) 读写锁练习:主线程不断写数据,另外两个线程不断读,通过读写锁保证数据读取有效性. 代码实现如下: #include <stdio ...
- Unity il2cpp GC
截止2019版本,il2cpp使用的都是Boehm-Demers-Wiser
- vue2鼠标事件
1.单击 @click 2.按下 @mousedown 3.抬起 @mouseup 4.双击 @dblclick 5.移动 @mousemove 6.移除 @mouseout 7.离开 @mousel ...
- 【命令详解001】top
top命令可以用于实时监控cpu的状态,显示系统中各个进程的资源占用情况. 本次来详细看下top命令. 常用命令示例: top # 对,无参数的top命令是最长用的资源监控命令. [root@VM_0 ...
- coreJava笔记——1
一.数组 对于数组的操作: 1.System.arrayopy(旧数组,下表,新数组,下表,长度) 2.新对象 = Arrays.copyOf(旧数组,长度): \如果要删除数组中的一个元素,先用1. ...
- AdaBoost算法的原理及Python实现
一.概述 AdaBoost(Adaptive Boosting,自适应提升)是一种迭代式的集成学习算法,通过不断调整样本权重,提升弱学习器性能,最终集成为一个强学习器.它继承了 Boosting ...
- MIUI系统,APKMirror Installer安装apkm的时候提示app installation failed Installation aborted解决方案
场景 我的手机是MIUI系统,通过APKMirror Installer安装apkm的时候提示app installation failed Installation aborted. 本来不想装了, ...
- Excel 数据显示到网页
平时的, 数据分析过程, 会涉及很多表或者, 计算过程嘛, 有的时候, 需要将数据表啥的给同事查看和共享一下, 直接发送, 似乎不够优雅. 直接展示在网页往, 共小伙伴们查看和下载, 不就很香嘛. 其 ...