.NET LINQ分析AWS ELB日志
前言
小明是个单纯的.NET开发,一天大哥叫住他,安排了一项任务:
“小明,分析一下我们超牛逼网站上个月的所有AWS ELB流量日志,这些日志保存在AWS S3上,你分析下,看哪个API的响应时间中位数最长。”
“对了,别用Excel,哥给你写好了一段Python脚本,可以自动解析统计一个AWS ELB文件的日志,你可以利用一下。”
“好的,大哥真厉害!”。
小明看了一下,然后傻眼了,在管理控制台中,九月份AWS ELB日志文件翻了好几页都没翻完,大概算算,大概有1000个文件不止。想想自己又不懂Python,又不是搞数据分析专业出身的,这个“看似简单”的工作完不成,这周怕是陪不了女朋友,搞不好还要996.ICU,小明几乎要流下了没有技术的泪水……
不怕!会.NET就行!
要完成这项工作,光老老实实将文件从管理控制台下载到本地,估计都够喝一壶。若小明稍机灵点,他可能会找到AWS S3的文件管理器,然后……发现只有付费版才有批量下载功能。
其实要完成这项工作,只需做好两项基本任务即可:
- 从
AWS S3下载9月份的所有ELB日志 - 聚合并分析这1000多个日志文件,然后按响应时间中位数倒排序
AWS资源
能在管理控制台上看到的AWS资源,AWS都提供了各语言的SDK可供操作(可在SDK上操作的东西,如批量下载,反倒不一定能在界面上看到)。SDK支持多种语言,其中(显然)也包括.NET。
对于AWS S3的访问,Amazon提供的NuGet包叫:AWSSDK.S3,在Visual Studio中下载并安装,即可运行本文的示例。
要使用AWSSDK.S3,首先需要实例化一个AmazonS3Client,并传入aws access key、aws secret key、AWS区域等参数:
var credentials = new BasicAWSCredentials(
Util.GetPassword("aws_live_access_key"),
Util.GetPassword("aws_live_secret_key"));
var s3 = new AmazonS3Client(credentials, RegionEndpoint.USEast1);
注意:本文的所有代码全部共享这一个
s3的实例。因为根据文档,AmazonS3Client实例是设计为线程安全的。
在下载AWS S3的文件(对象)之前,首先需要知道有哪些对象可供下载,可通过ListObjectsV2Async方法列出某个bucket的文件列表。注意该方法是分页的,经我的测试,无论MaxKeys参数设置多大,该接口最多一次性返回1000条数据,但这显然不够,因此需要循环分页去拿。
分页时该响应对象中包含了NextContinuationToken和IsTruncated属性,如果IsTruncated=true,则NextContinuationToken必定有值,此时下次调用ListObjectsV2Async时的请求参数传入NextContinuationToken即可实现分页获取S3文件列表的功能。
这个过程说起来有点绕,但感谢C#提供了yield关键字来实现协程-coroutine,代码写起来非常简单:
IEnumerable<List<S3Object>> Load201909SuperCoolData(AmazonS3Client s3)
{
ListObjectsV2Response response = null;
do
{
response = s3.ListObjectsV2Async(new ListObjectsV2Request
{
BucketName = "supercool-website",
Prefix = "AWSLogs/1383838438/elasticloadbalancing/us-east-1/2019/09",
ContinuationToken = response?.NextContinuationToken,
MaxKeys = 100,
}).Result;
yield return response.S3Objects;
} while (response.IsTruncated);
}
注意:
Prefix为前缀,AWS ELB日志都会按时间会有一个前缀模式,从文件列表中找到这一模式后填入该参数。
接下来就简单了,通过GetObjectAsync方法即可下载某个对象,要直接分析,最好先转换为字符串,拿到文件流stream后,最简单的方式是使用StreamReader将其转换为字符串:
IEnumerable<string> ReadS3Object(AmazonS3Client s3, S3Object x)
{
using GetObjectResponse obj = s3.GetObjectAsync(x.BucketName, x.Key).Result;
using var reader = new StreamReader(obj.ResponseStream);
while (!reader.EndOfStream)
{
yield return reader.ReadLine();
}
}
注意:
GetObjectAsync方法返回的GetObjectResponse类实现了IDisposable接口,因为它的ResponseStream实际上是非托管资源,需要单独释放。因此需要使用using关键字来实现资源的正确释放。- 可以直接调用
StreamReader.ReadToEnd()方法直接获取全部字符串,然后再通过Split将字符串按行分隔,但这样会浪费大量内存,影响性能。
这时一般会将这个stream缓存到本地磁盘以供慢慢分析,但也可以一鼓作气直接将该stream转换为字符串直接分析。本文将采取后者做法。
分析1000多个文件
每个ELB日志文件的格式如下:
2019-08-31T23:08:36.637570Z SUPER-COOLELB 10.0.2.127:59737 10.0.3.142:86 0.000038 0.621249 0.000041 200 200 6359 291 "POST http://super-coolelb-10086.us-east-1.elb.amazonaws.com:80/api/Super/Cool HTTP/1.1" "-" - -
2019-08-31T23:28:36.264848Z SUPER-COOLELB 10.0.3.236:54141 10.0.3.249:86 0.00004 0.622208 0.000045 200 200 6359 291 "POST http://super-coolelb-10086.us-east-1.elb.amazonaws.com:80/api/Super/Cool HTTP/1.1" "-" - -
可见该日志有一定格式,Amazon提供了该日志的详细文档中文说明:https://docs.aws.amazon.com/zh_cn/elasticloadbalancing/latest/application/load-balancer-access-logs.html#access-log-entry-format
根据文档,这种日志可以通过按简单的空格分隔来解析,但后面的RequestInfo和UserAgent字段稍微麻烦点,这种可以使用正则表达式来实现比较精致的效果:
public static LogEntry Parse(string line)
{
MatchCollection s = Regex.Matches(line, @"[\""].+?[\""]|[^ ]+");
string[] requestInfo = s[11].Value.Replace("\"", "").Split(' ');
return new
{
Timestamp = DateTime.Parse(s[0].Value),
ElbName = s[1].Value,
ClientEndpoint = s[2].Value,
BackendEndpoint = s[3].Value,
RequestTime = decimal.Parse(s[4].Value),
BackendTime = decimal.Parse(s[5].Value),
ResponseTime = decimal.Parse(s[6].Value),
ElbStatusCode = int.Parse(s[7].Value),
BackendStatusCode = int.Parse(s[8].Value),
ReceivedBytes = long.Parse(s[9].Value),
SentBytes = long.Parse(s[10].Value),
Method = requestInfo[0],
Url = requestInfo[1],
Protocol = requestInfo[2],
UserAgent = s[12].Value.Replace("\"", ""),
SslCypher = s[13].Value,
SslProtocol = s[14].Value,
};
}
LINQ
数据下载好了,解析也成功了,这时即可通过强大的LINQ来进行分析。这里将用到以下的操作符:
SelectMany数据“打平”(和js数组的.flatMap方法类似)Select数据转换(和js数组的.map方法类似)GroupBy数据分组
首先,通过AWSSDK的ListObjectsV2Async方法,获取的是文件列表,可以通过.SelectMany方法将多个下载批次“打平”:
Load201909SuperCoolData(s3)
.SelectMany(x => x)
然后通过Select,将单个文件Key下载并读为字符串:
Load201909SuperCoolData(s3)
.SelectMany(x => x)
.SelectMany(x => ReadS3Object(s3, x))
然后再通过Select,将文件每一行日志转换为一条.NET对象:
Load201909SuperCoolData(s3)
.SelectMany(x => x)
.SelectMany(x => ReadS3Object(s3, x))
.Select(LogEntry.Parse)
有了.NET对象,即可利用LINQ进行愉快地分析了,如小明需要求,只需加一个GroupBy和Select,即可求得根据Url分组的响应时间中位数,然后再通过OrderByDescending即按该数字排序,最后通过.Dump显示出来:
Load201909SuperCoolData(s3)
.SelectMany(x => x)
.SelectMany(x => ReadS3Object(s3, x))
.Select(LogEntry.Parse)
.GroupBy(x => x.Url)
.Select(x => new
{
Url = x.Key,
Median = x.OrderBy(x => x.BackendTime).ElementAt(x.Count() / 2)
})
.OrderByDescending(x => x.Median)
.Dump();
运行效果如下:

多线程下载
解析和分析都在内存中进行,因此本代码的瓶颈在于下载速度。
上文中的代码是串行、单线程下载,带宽利用率低,下载速度慢。可以改成并行、多线程下载,以提高带宽利用率。
传统的多线程需要非常大的功力,需要很好的技巧才能完成。但.NET 4.0发布了Parallel LINQ,只需极少的代码改动,即可享受到多线程的便利。在这里,只需将在第二个SelectMany后加上一个AsParallel(),即可瞬间获取多线程下载优势:
Load201909SuperCoolData(s3)
.SelectMany(x => x)
.AsParallel() // 重点
.SelectMany(x => ReadS3Object(s3, x))
.Select(LogEntry.Parse)
.GroupBy(x => x.Url)
.Select(x => new
{
Url = x.Key,
Median = x.OrderBy(x => x.BackendTime).ElementAt(x.Count() / 2)
})
.OrderByDescending(x => x.Median).Take(15)
.Dump();
注意:写
AsParallel()的位置有讲究,这取决于你对性能瓶颈的把控。总的来说:
- 太靠后了不行,因为
AsParallel之前的语句都是串行的;- 靠前了也不行,因为靠前的代码往往数据量还没扩大,并行没意义;
扩展
到了这一步,如果小明足够机灵,其实还能再扩展扩展,将平均值,总响应时间一并求出来,改动代码也不大,只需将下方那个Select改成如下即可:
.Select(x => new
{
Url = x.Key,
Median = x.OrderBy(x => x.BackendTime).ElementAt(x.Count() / 2),
Avg = x.Average(x => x.BackendTime),
Sum = x.Sum(x => x.BackendTime),
})
运行效果如下:
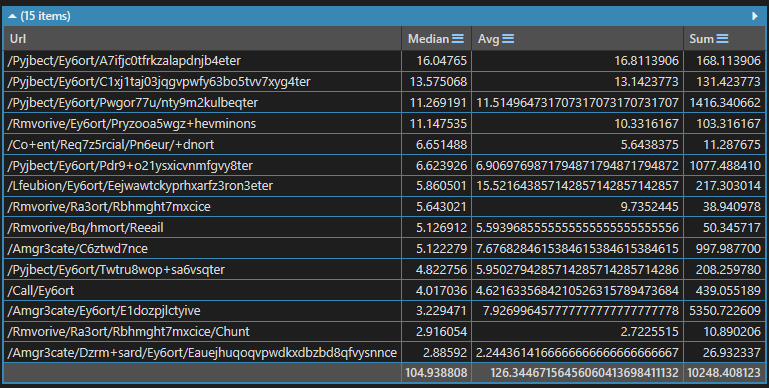
总结
看来并不需要python,有了.NET和LINQ两大法宝,看来小明周末又可以陪女朋友了
喜欢的请关注我的微信公众号:【DotNet骚操作】

.NET LINQ分析AWS ELB日志的更多相关文章
- .NET LINQ分析AWS ELB日志避免996
前言 小明是个单纯的.NET开发,一天大哥叫住他,安排了一项任务: "小明,分析一下我们超牛逼网站上个月的所有AWS ELB流量日志,这些日志保存在AWS S3上,你分析下,看哪个API的响 ...
- angular代码分析之异常日志设计
angular代码分析之异常日志设计 错误异常是面向对象开发中的记录提示程序执行问题的一种重要机制,在程序执行发生问题的条件下,异常会在中断程序执行,同时会沿着代码的执行路径一步一步的向上抛出异常,最 ...
- elk收集分析nginx access日志
elk收集分析nginx access日志 首先elk的搭建按照这篇文章使用elk+redis搭建nginx日志分析平台说的,使用redis的push和pop做队列,然后有个logstash_inde ...
- [日志分析] Access Log 日志分析
0x00.前言: 如何知道自己所在的公司或单位是否被入侵了?是没人来“黑”,还是因自身感知能力不足,暂时还没发现?入侵检测是每个安全运维人员都要面临的严峻挑战.安全无小事,一旦入侵成功,后果不堪设想. ...
- 详细分析MySQL事务日志(redo log和undo log)
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- 【转】python模块分析之logging日志(四)
[转]python模块分析之logging日志(四) python的logging模块是用来写日志的,是python的标准模块. 系列文章 python模块分析之random(一) python模块分 ...
- 详细分析MySQL事务日志(redo log和undo log) 表明了为何mysql不会丢数据
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- python模块分析之logging日志(四)
前言 python的logging模块是用来设置日志的,是python的标准模块. 系列文章 python模块分析之random(一) python模块分析之hashlib加密(二) python模块 ...
- 日志分析工具、日志管理系统、syslog分析
日志分析工具.日志管理系统.syslog分析 系统日志(Syslog)管理是几乎所有企业的重要需求.系统管理员将syslog看作是解决网络上系统日志支持的系统和设备性能问题的关键资源.人们往往低估了对 ...
- Eventlog Analyzer日志管理系统、日志分析工具、日志服务器的功能及作用
Eventlog Analyzer日志管理系统.日志分析工具.日志服务器的功能及作用 Eventlog Analyzer是用来分析和审计系统及事件日志的管理软件,能够对全网范围内的主机.服务器.网络设 ...
随机推荐
- NYX靶机笔记
NYX靶机笔记 概述 VulnHub里的简单靶机 靶机地址:https://download.vulnhub.com/nyx/nyxvm.zip 1.nmap扫描 1)主机发现 # -sn 只做pin ...
- 万丈高楼平地起:UML类图
UML类图 UML类图 是一种静态的结构图,描述了系统的类的集合,类的属性和类之间的关系,可以简化了人们对系统的理解.UML类图 是系统分析和设计阶段的重要产物,是系统编码和测试的重要模型. 图示 类 ...
- SQL 求中位值
题目A median is defined as a number separating the higher half of a data set from the lower half. Quer ...
- 【笔记】node常用方法(持续更新)
1.path.basename(path[, ext]) path <string> ext <string> 可选的文件扩展名. 返回: <string> pat ...
- SQL Server – 基本操作 Table 和 Column
前言 日常都是用 EF Core 来管理 Database, 偶尔也用 Management Studio, 就是很少手写 Command. 虽然网上一拉就有很多, 但是每次写单侧都要到处找还是挺烦的 ...
- TypeScript – Work with JavaScript Library (using esbuild)
前言 JavaScript 早期是没有 Modular 和 Type (类型) 的. 随着这几年的普及, 几乎有维护的 Library 都有 Modular 和 Type 了. 但万一遇到没有 Mod ...
- win10安装linux的gcc
mysy2下载gcc 过程比较艰苦,2024年秋冬讲课,被linux毒打了3天 pacman -S mingw-w64-ucrt-x86_64-gcc 这个一次成功,不行继续接大招 实在不行安装 ...
- windows 下搭php环境
windows 下搭php环境(php7.2+mysql5.7+apache2.4) 1. 先下载需要的软件 1) 先去微软官网下载vc,我下载的是2017版中文简体的.网址为https://www. ...
- iOS本地化NSLocalizedString的使用小结
在iOS设备,包括iPhone和iPad是全球可用.显然,iOS用户都来自不同国家,说着不同的语言.为了提供出色的用户体验,你可能希望以多种语言提供您的应用程序.适应应用程序以支持特定语言的过程通常被 ...
- vue.config.js 常用的属性
// vue.config.js 文件是脚手架的配置文件 const { defineConfig } = require("@vue/cli-service"); module. ...