Qwen3接入评测,最强开源模型更懂Graph了吗?

今日凌晨,阿里开源Qwen3,推理成本大幅下降,性能全面超越 DeepSeek-R1、OpenAI-o1 等,问鼎全球最强开源模型。在代码、数学、通用能力各项性能指标中,Qwen3都名列前茅。与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比,表现出极具竞争力的结果。
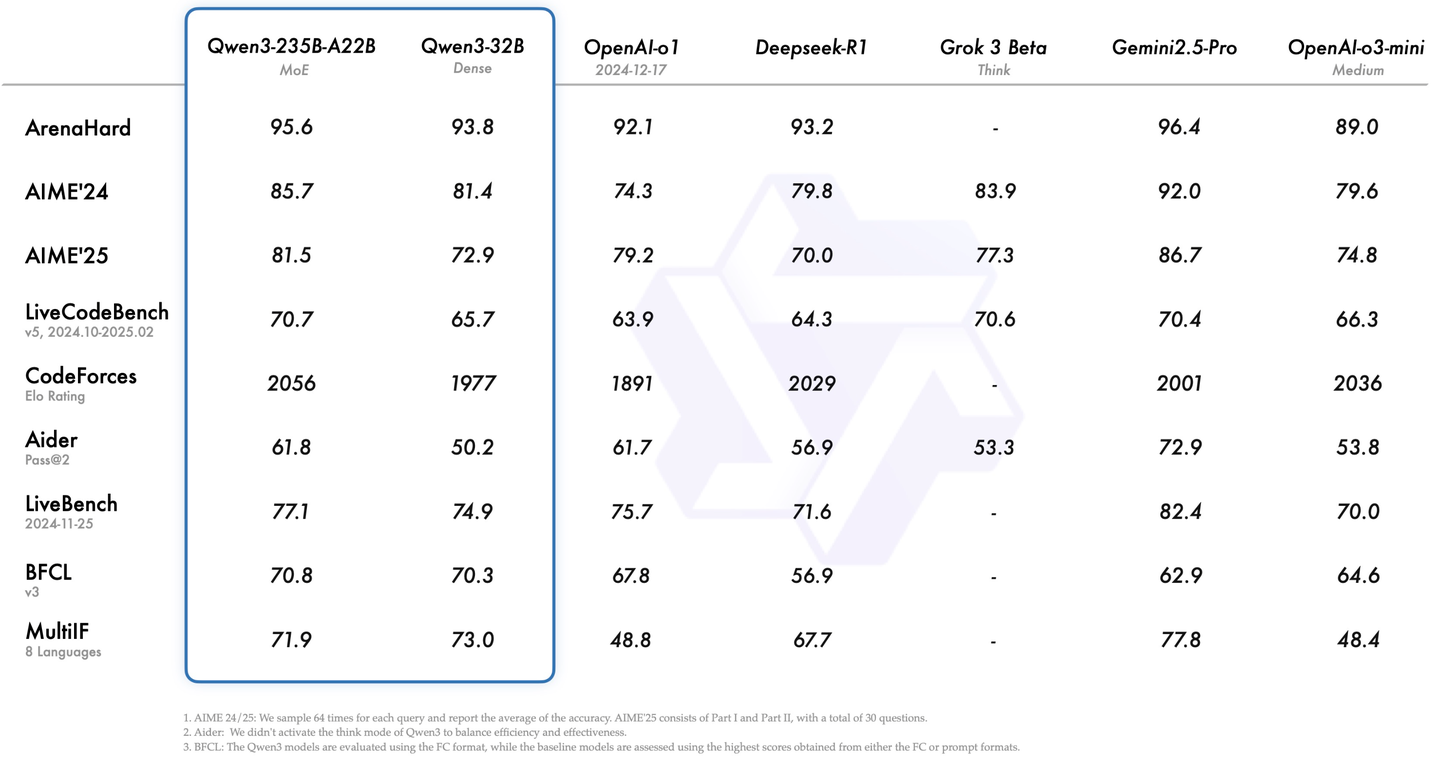
而就在 4 天前,我们刚发布了业内首个图原生智能体系统系统 Chat2Graph,旨在通过智能体技术高效解决用图问题,同时深度融合「Graph+AI」技术增强智能体的推理效果。开源项目链接:https://github.com/TuGraph-family/chat2graph。
Chat2Graph视频介绍:https://www.bilibili.com/video/BV15CjPztEgg
Chat2Graph 届时已将 Qwen3 接入作为基础模型服务,并在第一时间对其在图领域的任务上的表现进行了评测。
对比模型
综合性能、推理能力、价格三个因素,我们从挑选如下三个模型做对比分析:
- Qwen3:最强开源大模型,支持 thinking/no-thinking 两种模式。
- OpenAI o3-mini:o 系列闭源模型,mini 版本推理速度快、tokens 价格适中。
- Gemini 2.5 flash:最新的 Gemini 系列闭源模型,flash 版本推理速度极快,tokens 价格非常便宜。
图领域任务
我们使用了同一个问题在Chat2Graph上进行测试:
根据「罗密欧与朱丽叶」的故事构建图谱。然后,你还要查询图数据库,告诉我故事中出现了多少人物角色。然后进行深度分析,计算出最有影响力的节点。
实验结果
整体实验结果如下表所示。
| Qwen3 | OpenAI o3-mini | Gemini 2.5 flash | |
|---|---|---|---|
| 图谱规模 | 10 实体 11 关系 | 4 实体 3 关系 | 25 实体 30 关系 |
| 抽取人物数(共14位) | 8 位 | 2 位 | 13 位 |
| 调用图算法 | PageRank、BC | PageRank | PageRank |
| 工具调用次数 | 32 次 | 30 次(失败 1 次) | 50 次 |
| 总执行时间 | 30 分钟 | 13 分钟 | 15 分钟 |
| 输出格式丰富度 | 高 | 中 | 中 |
具体分析来看:
- Qwen3:
- 抽取:能力一般,主要弱点在于数据提取阶段,只识别了8/14的人物,构建的图谱规模相对较小,影响了后续任务的基础。
- 分析:能力突出,Qwen3 在图分析阶段表现最好,不仅调用了PageRank 算法,还调用了 BC 算法,并结合两者进行了深度分析,展现了较强的分析解释能力。输出格式也最丰富。
- 效率:一般,Qwen3 在三个模型中执行时间最长(30分钟)。但是在平均执行效率(执行时间/图谱规模)上和 OpenAI o3-mini 基本持平。
- 综合评定:★★★
- OpenAI o3-mini:
- 抽取:能力较差,仅提取了极少量的实体和关系(4实体,3关系),人物提取准确率最低(2/14)。构建的知识图谱过于稀疏,无法有效支持后续任务。
- 分析:能力一般,在 Schema 设计、复杂工具(多参数的 PageRank 算法)调用、图查询语句生成方面表现尚可,但整体效果因数据基础薄弱而大打折扣。输出格式丰富度一般。
- 效率:一般,o3-mini 虽然总时间最短,但其极低的图谱质量产出,导致效率指标并不理想。但这可能是牺牲了信息提取完整性的结果(被评价为学习了“偷懒”技能)。
- 综合评定:★★
- Gemini 2.5 flash:
- 抽取:能力最好,在此次测试中,Gemini 2.5 flash 表现最为出色。它成功构建了规模最大、最接近完整的知识图谱(25个实体,30条关系),并且在人物角色提取方面准确率最高(13/14,仅遗漏1位)。长文本幻觉率低,尽管逐步导入了相当规模的图谱,但没有出现节点重复导入的问题。
- 分析:能力一般,仅仅调用一个 PageRank 算法来找出最影响力的节点,不过作出了较为合理算法结果的解释,且结果符合基本常识。输出格式丰富度一般。
- 效率:最好,工具调用次数最多(50次),且执行时间仅为 15分钟,显示出较高的效率和彻底性。
- 综合评定:★★★★
最后补充一下部分关键测试效果。
任务规划
总体来看,三个模型在 Agent 任务规划能力上差异并不明显,基本上都能做到细致精确的子任务拆分。
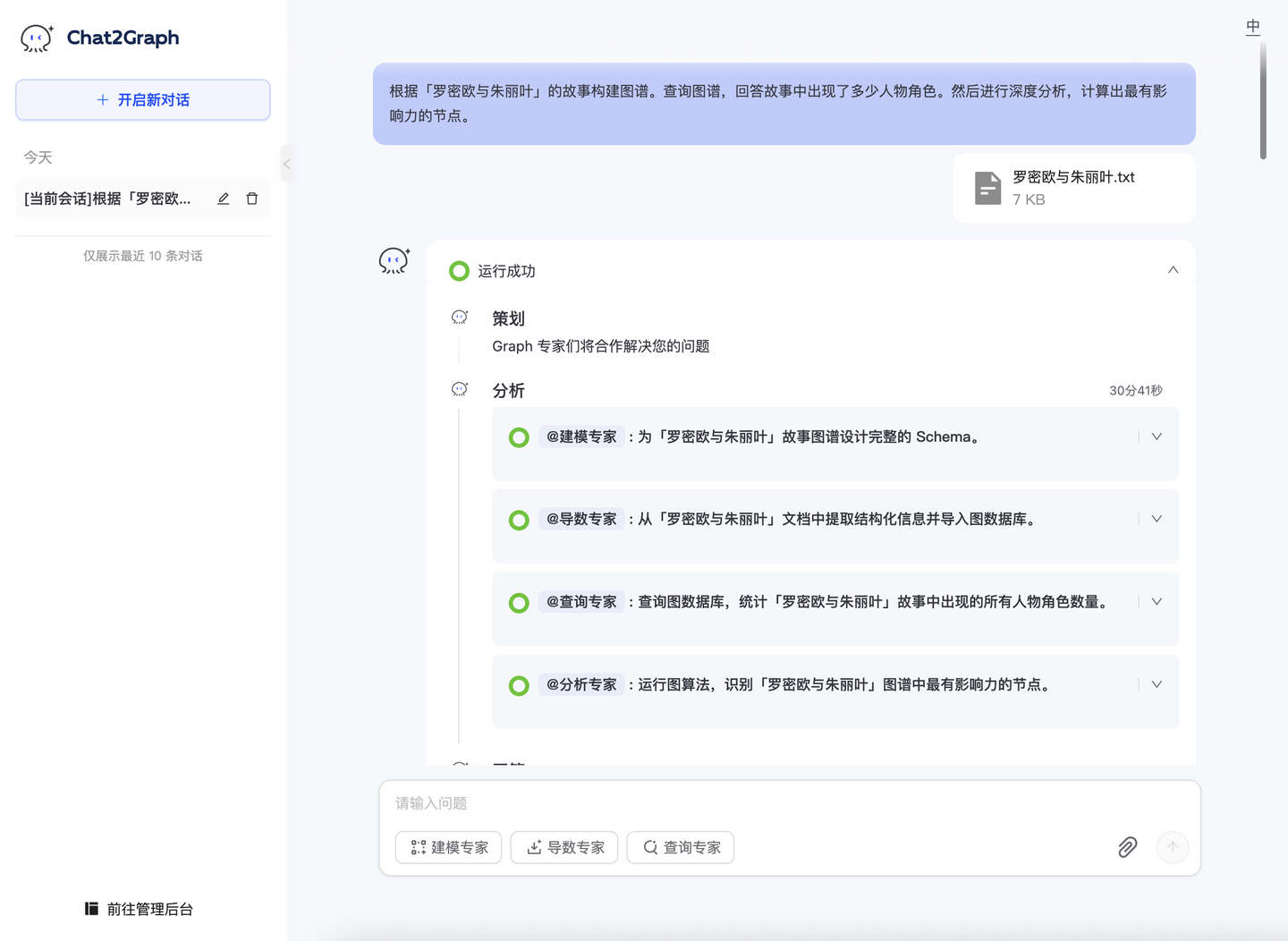
输出格式
从执行结果的输出格式来看,Qwen3 的输出格式相对丰富,可读性更加友好。

评测结论
整体来看,Gemini 2.5 flash 综合表现最佳,在执行效率和图抽取能力上优势明显;Qwen3 凭借对图领域工具的熟练运用展现了突出的深度分析能力,但在数据抽取和执行效率上表现一般;相比之下,o3-mini 整体表现最差。
因此,虽然 Qwen3 在各项开源测试榜单上表现出色,但经过对实际图任务的测试,与当下的领先的闭源模型能力仍有一定的差距。所以,通过特定的图领域知识和工具,基于通用大模型构建图原生智能体系统仍旧十分必要,这也是 Chat2Graph 一直以来要解决的问题。
技术展望
Qwen3的混合推理模型,无缝支持了thinking&no-thinking模式,为上层应用提供了灵活控制思考成本的能力。在Chat2Graph中可以尝试通过打开“thinking”模式来增强 Leader 的规划能力 / Thinker 的推理效果。同时也可以通过关闭“thinking”模式,降低 Expert/Actor 执行开销和时延。
此外 Qwen3 对 MCP 的支持,让我们看到大模型正在逐步过渡到以 Agent 为中心的训练,这更督促 Agent 的开发者需要深度反思大模型能力界限之外的 Agent 的工程设计策略,进一步挖掘在工程层面协助大模型改进智能应用端到端体验的创新与方案。
Qwen3接入评测,最强开源模型更懂Graph了吗?的更多相关文章
- 从开源模型、框架到自研,声网 Web 端虚拟背景算法正式发布
根据研究发现,在平均 38 分钟的视频会议里面,大概会有 13 分钟左右的时间用于处理和干扰相关的事情.同时研究也表明在参加在线会议的时候,人们更加倾向于语音会议,其中一个关键原因就是大家不希望个人隐 ...
- Wolsey“强整数规划模型”经典案例之一单源固定费用网络流问题
Wolsey“强整数规划模型”经典案例之一单源固定费用网络流问题 阅读本文可以理解什么是“强”整数规划模型. 单源固定费用网络流问题见文献[1]第13.4.1节(p229-231),是"强整 ...
- 最强NLP模型-BERT
简介: BERT,全称Bidirectional Encoder Representations from Transformers,是一个预训练的语言模型,可以通过它得到文本表示,然后用于下游任务, ...
- R_针对churn数据用id3、cart、C4.5和C5.0创建决策树模型进行判断哪种模型更合适
data(churn)导入自带的训练集churnTrain和测试集churnTest 用id3.cart.C4.5和C5.0创建决策树模型,并用交叉矩阵评估模型,针对churn数据,哪种模型更合适 决 ...
- 什么?让每一个开源项目更安全?啊?还有IDE工具?难道是它?
背景 入编程界6年来,大大小小的安全漏洞是真滴听了不少,xxx通过日志入侵了,xxxx通过请求入侵了,等等等等. 近期fastJson又报安全漏洞,敢巧自己又"被"跳槽到了新公司, ...
- 技术范儿的 Keep 发力AI赛道,为什么“虚拟教练”会更懂你?
http://www.tmtpost.com/3363367.html 摘要: 虚拟教练技术会整合到一些业务场景和硬件产品中收费,但是收费的具体情况彭跃辉还暂未透露. 图片来源于Unsplash 自去 ...
- 阿里云更懂你的数据库,免费提供DBA服务
阿里云更懂你的数据库,免费提供DBA服务 阿里云云数据库(RDS)管理控制台近期将全面升级为云数据库管家.云数据库管家的使命是提供便捷的操作.贴心的服务.专业的处理建议,帮助用户管理好云数据库. ...
- Awareness Kit让你的音乐APP脱颖而出,更懂用户,也更动人心
让你的音乐APP脱颖而出,更懂用户,也更动人心. 场景 情景感知服务能带来什么? 作为音乐发烧友,闲下来的时候总想打开App,享受沉浸在音乐中的放松.然而,App推荐的歌单经常没法满足我的需要,如 ...
- TCP协议的性能评测工具 — Tcpdive开源啦
Github地址:https://github.com/fastos/tcpdive 为什么要开发Tcpdive 在过去的几年里,随着移动互联网的飞速发展,整个基础网络已经发生了翻天覆地的变化. 用户 ...
- 5 分钟入门 Google 最强NLP模型:BERT
BERT (Bidirectional Encoder Representations from Transformers) 10月11日,Google AI Language 发布了论文 BERT: ...
随机推荐
- 探索sqlmap在WebSocket安全测试中的应用
探索sqlmap在WebSocket安全测试中的应用 WebSocket与HTTP的区别 WebSocket,对于初次接触的人来说,往往会引发一个疑问:既然我们已经有了广泛使用的HTTP协议,为何还需 ...
- Recent 做题记录(重写)
重构. 2023.9 CF922D 考虑交换法即可.Livshits-Kladov 定理. CF1528C 第一棵树上是一条链:第二棵树上使用数据结构维护贪心(小的区间比大的更优:树上具有包含/无交性 ...
- Codeforces 11D A Simple Task 题解 [ 蓝 ] [ 状压 dp ]
思路不难想,细节比较多. 思路 观察到 \(n \le 19\) ,首先想到状压 dp . 于是自然地定义 \(dp[j][i]\) 为:抵达点的状态为 \(i\) ,且此时在点 \(j\) 时,简单 ...
- 利用纯JS导出到EXCEL
var tableToExcel = (function () { var uri = 'data:application/vnd.ms-excel;base64,', template = '< ...
- C# 心跳检测实现
原文链接: https://blog.csdn.net/yupu56/article/details/72356700 TCP网络长连接 手机能够使用联网功能是因为手机底层实现了TCP/IP协议,可以 ...
- 探秘Transformer系列之(5)--- 训练&推理
探秘Transformer系列之(5)--- 训练&推理 0x00 概述 Transformer训练的目的是通过对输入源序列和模型输出序列的学习,来拟合真正的目标序列.推理的目的则是仅通过输入 ...
- 有关C++程序设计基础的各种考题解答参考汇总
早先年考研的主考科目正是[算法与数据结构],复习得还算可以.也在当时[百度知道]上回答了许多相关问题,现把他们一起汇总整理一下,供读者参考. [1] 原题目地址:https://zhidao.baid ...
- 错误模块名称:vrfcore.dll
记录一下. 应用程序莫名报这个错,其它电脑上正常. 可能是Application Verifier这个工具影响到了. 进入注册表:win+R->regedit->HKEY_LOCAL_MA ...
- 使用selenium下载文件--设置下载文件自动保存文件夹
selenium自动下载文件到指定目录 本文参考:https://www.cnblogs.com/huxiaofeng1029/p/17383726.html 有时候,我们需要在网页中点击某些按钮,将 ...
- 7. Nginx 工作机制&参数设置(详细讲解说明)
7. Nginx 工作机制&参数设置(详细讲解说明) @ 目录 7. Nginx 工作机制&参数设置(详细讲解说明) 1. Nginx 当中的 master-worker 机制原理 2 ...