8,HashMap子类-LinkedHashMap
在上一篇随笔中,分析了HashMap的源码,里面涉及到了3个钩子函数(afterNodeAccess(e),afterNodeInsertion(evict),afterNodeRemoval(node)),用来预设给子类——LinkedHashMap调用。
一,LinkedHashMap数据结构
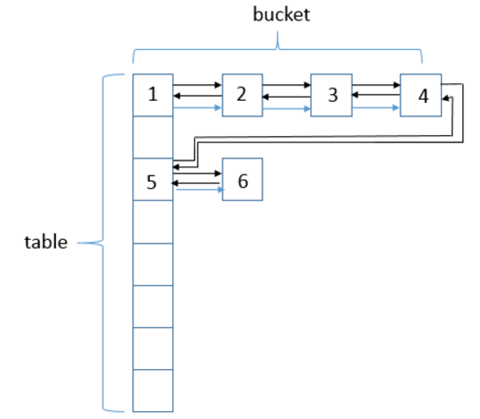
可以从上图中看到,LinkedHashMap数据结构相比较于HashMap来说,添加了双向指针,分别指向前一个节点——before和后一个节点——after,从而将所有的节点已链表的形式串联一起来。数据结构为(数组 + 单链表 + 红黑树 + 双链表),图中的标号是结点插入的顺序。
二,LinkedHashMap源码
1,LinkedHashMap结构
LinkedHashMap继承HashMap,所以HashMap中的非private方法和字段,都可以在LinkedHashMap直接中访问。
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
// 版本序列号
private static final long serialVersionUID = 3801124242820219131L;
// 链表头结点
transient LinkedHashMap.Entry<K,V> head;
// 链表尾结点
transient LinkedHashMap.Entry<K,V> tail;
/**
* 用来指定LinkedHashMap的迭代顺序,
* true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾
* false则表示按照插入顺序来
*/
final boolean accessOrder;
}
2,构造函数
LinkedHashMap提供了五种方式的构造器,所有构造函数的第一行都会调用父类构造函数,使用super关键字,如下
构造器一:
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
accessOrder默认为false,access为true表示之后访问顺序按照元素的访问顺序进行,即不按照之前的插入顺序了,access为false表示按照插入顺序访问。
构造器二:
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
构造器三:
public LinkedHashMap() {
super();
accessOrder = false;
}
构造器四:
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
}
putMapEntries是调用到父类HashMap的函数。
构造器五:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
通过指定accessOrder的值,从而控制访问顺序。
3,LinkedHashMap.Entry内部类
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
LinkedHashMap.Entry继承自HashMap.Node,在HashMap.Node基础上增加了前后两个指针域。
4,部分函数
4.1,get()函数
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
//accessOrder为true则表示按照基于访问的顺序来排列,意思就是最近使用的entry,放在链表的最末尾
//在取值后对参数accessOrder进行判断,如果为true,执行afterNodeAccess
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
//此函数执行的效果就是将最近使用的Node,放在链表的最末尾
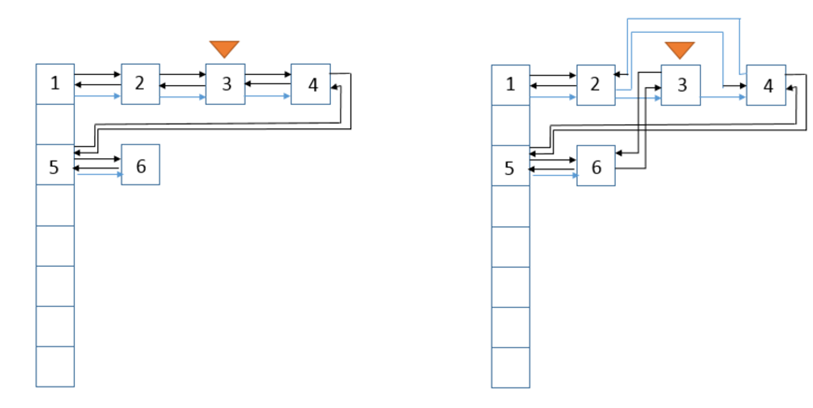
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
//仅当按照LRU原则且e不在最末尾,才执行修改链表,将e移到链表最末尾的操作
if (accessOrder && (last = tail) != e) {
//将e赋值临时节点p, b是e的前一个节点, a是e的后一个节点
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//设置p的后一个节点为null,因为执行后p在链表末尾,after肯定为null
p.after = null;
//情况一(p为头部):p前一个节点为null
if (b == null)
head = a;
else
b.after = a;
//情况二(p为尾部):p的后一个节点为null
if (a != null)
a.before = b;
else
last = b;
//情况三(p为链表里的第一个节点)
if (last == null)
head = p;
else {
//正常情况,将p设置为尾节点的准备工作,p的前一个节点为原先的last,last的after为p
p.before = last;
last.after = p;
}
//将p设置为尾节点
tail = p;
// 修改计数器+1
++modCount;
}
}
概念:
LRU(Least Recently Used): 意思就是最近读取的数据放在最前面,最早读取的数据放在最后面,如果这个时候有新的数据进来,那么最后面存储的数据淘汰。
说明一下:
正常情况下:查询的p在链表中间,那么将p设置到末尾后,它原先的 前节点b 和 后节点a 就变成了前后节点。
情况一:p为头部,前一个节点b不存在,那么考虑到p要放到最后面,则设置p的后一个节点a为head。
情况二:p为尾部,后一个节点a不存在,那么考虑到统一操作,设置last为b。
情况三:p为链表里的第一个节点,head=p。
将最近使用的Node,放在链表的最末尾示意图:
4.2,put()方法
LinkedHashMap的put方法调用的还是HashMap里的put,不同的是重写了里面的部分方法。
LinkedHashMap将其中newNode方法以及之前设置下的钩子方法afterNodeAccess(该方法上面已说明)和afterNodeInsertion进行了重写,从而实现了加入链表的目的。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
//把新加的节点放在链表的最后面。
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
//将tail给临时变量last
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
//若没有last,说明p是第一个节点,head=p
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
//插入后把最老的Entry删除,不过removeEldestEntry总是返回false,所以不会删除,估计又是一个钩子方法给子类用的
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
4.3,remove()方法
在HashMap的remove方法中也有一个钩子方法afterNodeRemoval。
LinkedHashMap的remove方法调用的还是HashMap里的remove,不同的是重写了里面的部分方法。
void afterNodeRemoval(Node<K,V> e) {
//记录e的前后节点b,a
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//p已删除,前后指针都设置为null,便于GC回收
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
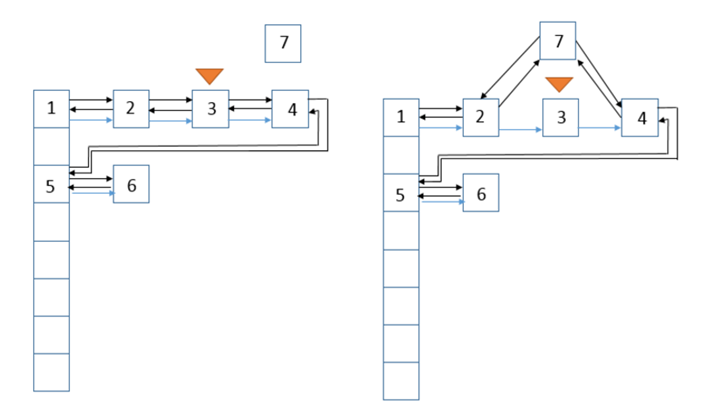
4.4,transferLinks()方法
//替换节点的方法,我们使用的replacementNode,replacementTreeNode等方法都是通过该方法实现的
private void transferLinks(LinkedHashMap.Entry<K,V> src,
LinkedHashMap.Entry<K,V> dst) {
LinkedHashMap.Entry<K,V> b = dst.before = src.before;
LinkedHashMap.Entry<K,V> a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
}
dst节点替换src节点示意图:
5,LinkedHashMap的迭代器
abstract class LinkedHashIterator {
//记录下一个Entry
LinkedHashMap.Entry<K,V> next;
//记录当前的Entry
LinkedHashMap.Entry<K,V> current;
//记录是否发生了迭代过程中的修改
int expectedModCount;
LinkedHashIterator() {
//初始化的时候把head给next
next = head;
expectedModCount = modCount;
current = null;
}
public final boolean hasNext() {
return next != null;
}
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
8,HashMap子类-LinkedHashMap的更多相关文章
- HashMap和LinkedHashMap的区别
参考:https://blog.csdn.net/a822631129/article/details/78520111 java为数据结构中的映射定义了一个接口java.util.Map;它有四个实 ...
- HashMap和LinkedHashMap区别
import java.util.HashMap; import java.util.Iterator; import java.util.LinkedHashMap; import java.uti ...
- HashMap和LinkedHashMap的比较使用
由于现在项目中用到了LinkedHashMap,并不是太熟悉就到网上搜了一下. import java.util.HashMap; import java.util.Iterator; impor ...
- Map,Hashmap,LinkedHashMap,Hashtable,TreeMap
java为数据结构中的映射定义了一个接口java.util.Map;它有四个实现类,分别是HashMap Hashtable LinkedHashMap 和TreeMap. Map主要用于存储健值对, ...
- 接口java.util.Map的四个实现类HashMap Hashtable LinkedHashMap TreeMap
java中HashMap,LinkedHashMap,TreeMap,HashTable的区别 :java为数据结构中的映射定义了一个接口java.util.Map;它有四个实现类,分别是HashMa ...
- TreeMap,HashMap,LinkedHashMap区别,很简单解释
TreeMap,HashMap,LinkedHashMap之间的区别和TreeSet,HashSet,LinkedHashSet之间的区别相似. TreeMap:内部排序. HashMap:无序. L ...
- TreeSet VS HashSet VS LinkedHashSet; TreeMap VS HashMap VS LinkedHashMap
From online resources Set HashSet is much faster than TreeSet (constant-time versus log-time for mos ...
- HashMap与LinkedHashMap的区别
/** * remark: * HashMap与LinkedHashMap的区别 * 这里必须使用LinkedHashMap: * 原因 ...
- LRU算法实现,HashMap与LinkedHashMap源码的部分总结
关于HashMap与LinkedHashMap源码的一些总结 JDK1.8之后的HashMap底层结构中,在数组(Node<K,V> table)长度大于64的时候且链表(依然是Node) ...
随机推荐
- golang error (slice of unaddressable value)
使用 Golang 将生成的 md5 转化为 string 的过程出现如下编译错误: 错误解析: 值得注意的一点是 func Sum(data []byte) [Size]byte 这个函数返回的 ...
- vue路由高级用法
五.路由设置高级用法alias 别名 {path:'/list',component:MyList,alias:'/lists'}redirect 重定向 {path:'/productList',r ...
- Java多线程学习——sleep和yield
Thread.sleep(); Thread.yield(); 相同点: 让线程暂停运行. 都是静态方法,可以直接调用. 不同点: sleep让线程从运行状态进入阻塞状态,但是不放开手中的资源. yi ...
- 数据库之DML
1.表的有关操作: 1.1.表的创建格式: CREATE TABLE IF NOT EXISTS 表名(属性1 类型,属性2 类型,....,属性n 类型):# 标记部分表示可以省略 1.2.表的修改 ...
- mysql 修改成utf8编码
参考文档 https://www.cnblogs.com/chenshuo/p/4743144.html
- Javascript原型介绍
原型及原型链 原型基础概念 function Person () { this.name = 'John'; } var person = new Person(); Person.prototype ...
- Linux环境部署Node.js
介绍 先前在阿里云ECS上部署Node.js,碰到不少坑,都是自己不仔细造成的,所以准备再部署一遍,并记录下来.我将我的服务器重置了,这次选择的是CentOS 7.4 64位,上次的是7.2的. 使用 ...
- JProfiler监控
原文: https://blog.csdn.net/jijilan/article/details/83022715
- Maven clean install 跳过单元测试
1.使用MVN命令 mvn clean install -DskipTests 或者 mvn clean install -Dmaven.test.skip=true 2.Eclipse中设置clea ...
- k3 cloud中如何把一个账套中的单据部署到另一个账套中
打开bos,依次点击->解决方案->部署包管理 填写部署包名称并点击下一步 选择需要部署的单据并点击下一步 确定后点击下一步: 点击完成 找到部署路径会成一个部署包: 部署:打开部署包安装 ...