深入研究浏览器对HTML解析过程
HTML
HTML解析
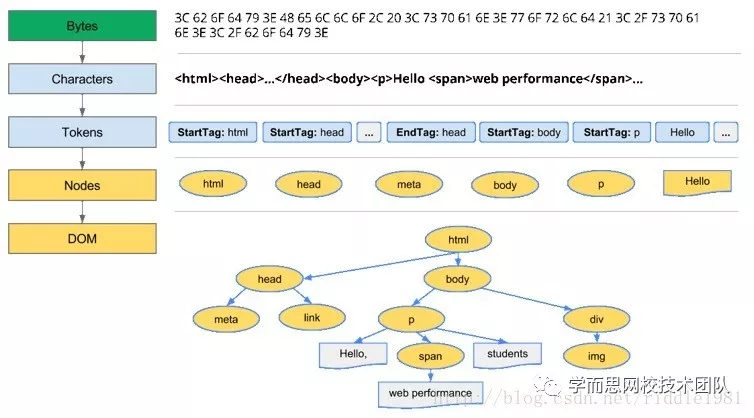
HTML解析是一个将字节转化为字符,字符解析为标记,标记生成节点,节点构建树的过程。
标记化算法
是词法分析过程,将输入内容解析成多个标记。HTML标记包括起始标记、结束标记、属性名称和属性值。标记生成器识别标记,传递给树构造器,然后接受下一个字符以识别下一个标记;如此反复直到输入的结束。
该算法的输出结果是 HTML 标记。该算法使用状态机来表示。每一个状态接收来自输入信息流的一个或多个字符,并根据这些字符更新下一个状态。当前的标记化状态和树结构状态会影响进入下一状态的决定
树构建算法
在树构建阶段,以 Document 为根节点的 DOM 树也会不断进行修改,向其中添加各种元素。
标记生成器发送的每个节点都会由树构建器进行处理。规范中定义了每个标记所对应的 DOM 元素,这些元素会在接收到相应的标记时创建。这些元素不仅会添加到 DOM 树中,还会添加到开放元素的堆栈中。此堆栈用于纠正嵌套错误和处理未关闭的标记。其算法也可以用状态机来描述。这些状态称为“插入模式”。
<html>
<body>hello</body>
</html>
标记化
初始状态是数据状态。
遇到字符 < 时,状态更改为
“标记打开状态”。接收一个 a-z字符会创建“起始标记”,状态更改为“标记名称状态”。这个状态会一直保持到接收> 字符。在此期间接收的每个字符都会附加到新的标记名称上。在本例中,我们创建的标记是 html 标记。遇到 > 标记时,会发送当前的标记,状态改回
“数据状态”。 标记也会进行同样的处理。目前 html 和 body 标记均已发出。现在我们回到“数据状态”。接收到 Hello world 中的 H 字符时,将创建并发送字符标记,直到接收</body> 中的<。我们将为 Hello world 中的每个字符都发送一个字符标记。接收</body> 中的<,现在我们回到
“标记打开状态”。接收下一个输入字符 / 时,会创建 end tag token 并改为“标记名称状态”。我们会再次保持这个状态,直到接收 >。然后将发送新的标记,并回到“数据状态”。 输入也会进行同样的处理。
树构建
树构建阶段的输入是一个来自标记化阶段的
标记序列第一个模式是“
initial mode”。接收 HTML 标记后转为“
before html”模式,并在这个模式下重新处理此标记。这样会创建一个 HTMLHtmlElement 元素,并将其附加到 Document 根对象上。然后状态将改为“
before head”。此时我们接收“head”标记。即使我们的示例中没有“head”标记,系统也会隐式创建一个 HTMLHeadElement,并将其添加到树中。现在我们进入了“
in head”模式,然后转入“
after head”模式。系统对 body 标记进行重新处理,创建并插入 HTMLBodyElement,同时模式转变为“
body”。现在,接收由“Hello world”字符串生成的一系列字符标记。接收第一个字符时会创建并插入“Text”节点,而其他字符也将附加到该节点接收 body 结束标记会触发“
after body"模式。现在我们将接收 HTML 结束标记,然后进入“
after after body”模式。接收到文件结束标记后,解析过程就此结束。解析结束后的操作当HTML解析完成后,浏览器会将文档标注为交互状态,并开始解析那些处于“deferred”模式的脚本,也就是那些应在文档解析完成后才执行的脚本。然后,文档状态将设置为“完成”,一个“加载”事件将随之触发。
完整解析过程
参考https://mp.weixin.qq.com/s/WtRxcyBbZQRcfFhfVJLBQA
深入研究浏览器对HTML解析过程的更多相关文章
- 浏览器与DNS解析过程
浏览器解析 1.地址栏输入地址后,浏览器检查自身DNS缓存 地址栏输入chrome://net-internals/#dns 查看. 2.浏览器缓存中未找到,那么Chrome会搜索操作系统自身的DNS ...
- 输入URL到浏览器显示页面的过程,搜集各方面资料总结一下
面试中经常会被问到这个问题吧,唉,我最开始被问到的时候也就能大概说一些流程.被问得多了,自己就想去找找这个问题的全面回答,于是乎搜了很多资料和网上的文章,根据那些文章写一个总结. 写得不好,或者有意见 ...
- DNS原理及其解析过程 精彩剖析
本文章转自下面:http://369369.blog.51cto.com/319630/812889 DNS原理及其解析过程 精彩剖析 网络通讯大部分是基于TCP/IP的,而TCP/IP是基于IP地址 ...
- DNS解析过程详解
先说一下DNS的几个基本概念: 一. 根域 就是所谓的“.”,其实我们的网址www.baidu.com在配置当中应该是www.baidu.com.(最后有一点),一般我们在浏览器里输入时会省略后面的点 ...
- 解读JSP的解析过程
解读JSP的解析过程 互联网上,这方面的资料实在太少了,故把自己研究的一些结果公布出来. 首先,问大家几个问题,看大家能不能回答出来,或者在网上能不能找到答案: 1.page.include.tagl ...
- DNS原理及其解析过程【精彩剖析】(转)
2012-03-21 17:23:10 标签:dig wireshark bind nslookup dns 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否 ...
- 1.Google Chrome浏览器 控制台全解析
Google Chrome浏览器 控制台全解析 在Google Chrome浏览器出来之前,我一直使用FireFox,因为FireFox的插件非常丰富,更因为FireFox有强大的Firebug,对于 ...
- 转载:DNS解析过程详解
2015-09-20 此好文是转载,如有侵权联系我,立马删掉 DNS的几个基本概念: 一. 根域 就是所谓的“.”,其实我们的网址www.baidu.com在配置当中应该是www.baidu.com. ...
- 经典面试题:浏览器是怎样解析CSS的?
摘要: 理解浏览器原理. 解析 一旦 CSS 被浏览器下载,CSS 解析器就会被打开来处理它遇到的任何 CSS.这可以是单个文档内的 CSS.<style>标记内的 CSS,也可以是 DO ...
随机推荐
- 创建一个java项目并部署到weblogic服务器
转自:https://blog.csdn.net/krystal_sl/article/details/52847953 新建一个项目的步骤 打开eclipse,右键点击new–>java pr ...
- 数据库_PXC群集与存储引擎
1. PXC介绍与群集搭建; 2.数据存储引擎. 一, PXC介绍 1.介绍 PXC(Percona XtraDB Cluster)基于Galara的一台开源软件,应用于解决mysql的高可用集群问题 ...
- MySQL --12 备份的分类
目录 物理备份(Xtrabackup) 1.全量备份 2.增量备份及恢复 3.差异备份及恢复 4.实战:企业级增量恢复实战 物理备份(Xtrabackup) Xtrabackup安装 #下载epel源 ...
- django项目中账号注册登陆使用JWT的记录
需求分析 1. 注册用JWT做状态保持 1.1 安装jwt pip install djangorestframework-jwt 1.2 去settings里面配置jwt ...
- Sass函数:unit()函数
unit() 函数主要是用来获取一个值所使用的单位,碰到复杂的计算时,其能根据运算得到一个“多单位组合”的值,不过只充许乘.除运算: >> unit(100) "" & ...
- Go 使用 append 向切片增加元素
1.// 创建一个整型切片 // 其长度和容量都是 5 个元素 slice := []int{10, 20, 30, 40, 50} // 创建一个新切片 // 其长度为 2 个元素,容量为 4 个元 ...
- springboot+jsp项目实例(第二弹)(成功)
1.创建spring boot项目,使用idea自带的spring initializr创建Spring boot的maven项目(我是先创建了一个空的项目). 开始创建Spring boot项目,点 ...
- Servlet 第一天
package com.servlet; import java.io.IOException; import javax.servlet.Servlet; import javax.servlet. ...
- C# 私有字段前缀 _ 的设置(VS2019, .editorconfig)
常量和静态只读字段大写 私有字段前缀 _ #### Naming styles #### # Naming rules dotnet_naming_rule.const_should_be_all_u ...
- JS中常见的几种报错类型
1.SyntaxError(语法错误) 解析代码时发生的语法错误 var 1a; //Uncaught SyntaxError: Invalid or unexpected token 变量名错误 c ...