Cypher 语句实战
Cypher 语句实战
下载和安装
Neo4j windows 桌面版- 环境设置
https://www.w3cschool.cn/neo4j/neo4j_exe_environment_setup.html
Neo4j - 解压版环境设置
https://www.w3cschool.cn/neo4j/neo4j_zip_environment_setup.html
Cypher语言的关键字不区分大小写,但是属性值,标签,关系类型和变量是区分大小写的。
Neo4j中不存在表的概念,只有标签(labels),节点(Node),关联(Relation),路径(path),标签里存的节点,节点和关联可以简单理解为图里面的点和边,路径是用节点和关联表示的如:(a)-[r]->(b),表示一条从节点a经关联r到节点b的路径。
在数据查询中,节点一般用小括号(),关联用中括号[]。
1.创建节点
创建Person 标签,刘德华等若干节点,各自有name,birthday ,born,englishname等属性
create (n:Person { name: '刘德华', birthday:'1961年9月27日',born: 1961 ,englishname:'Andy Lau'})
create (n:Person { name: '朱丽倩', birthday:'1966年4月6日',born: 1966 ,englishname:'Carol'}) ;
create (n:Person { name: '刘向蕙', birthday:'2012年5月9日',born: 2012 ,englishname:'Hanna'}) ;
create (n:Person { name: '任贤齐', birthday:'1966年6月23日',born: 1966 ,englishname:'Richie Jen'}) ;
create (n:Person { name: '金城武', birthday:'1973年10月11日',born: 1973,englishname:'Takeshi Kaneshiro'}) ;
create (n:Person { name: '林志玲', birthday:'1974年11月29日',born: 1974,englishname:'zhilin'}) ;
创建Movie 标签,彩云曲等若干节点,各自有title,released 等属性
create (n:Movie { title: '彩云曲',released: 1981})
create (n:Movie { title: '神雕侠侣',released: 1983})
create (n:Movie { title: '暗战',released: 2000})
create (n:Movie { title: '拆弹专家',released: 2017})
2.查询节点
2.1 查询整个图形数据库:
点击节点,查看节点的属性,如图,Neo4j自动为节点设置ID值
match(n) return n;

2.2 查询具有指定标签的节点
查询Movie标签下的节点
match(n:Movie) return n;
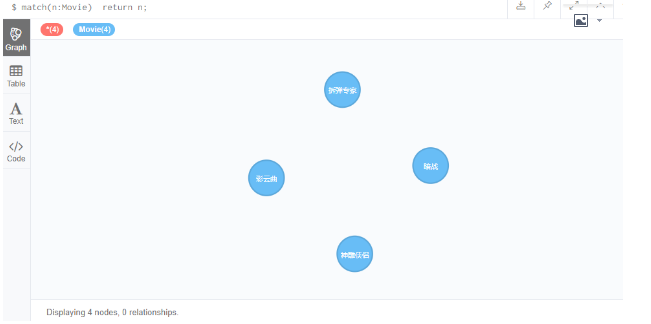
2.3 where 谓词查询
查询名称为林志玲的节点
match (n:Person) where n.name='林志玲' return n
(查询具有指定属性的节点)结果相同
match(n{name:'林志玲'}) return n;

查询born属性小于1967的节点
match(n) where n.born<1967 return n;
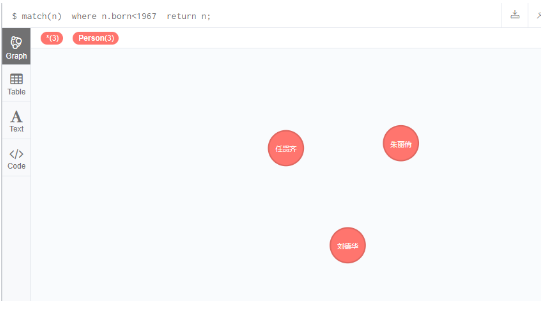
3.创建关系
关系的构成:StartNode - [Variable:RelationshipType{Key1:Value1,Key2:Value2}] -> EndNode,在创建关系时,必须指定关系类型。
3.1 创建没有任何属性的关系
MATCH (a:Person),(b:Movie) WHERE a.name = '刘德华' AND b.title = '暗战' CREATE (a)-[r:DIRECTED]->(b) RETURN r;
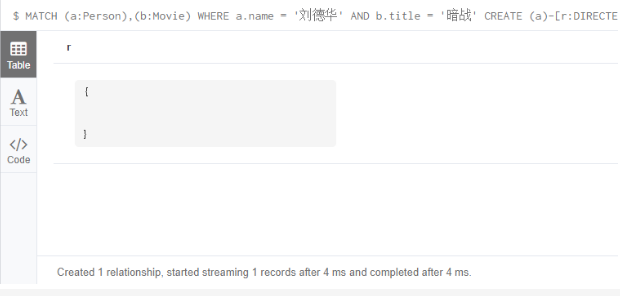
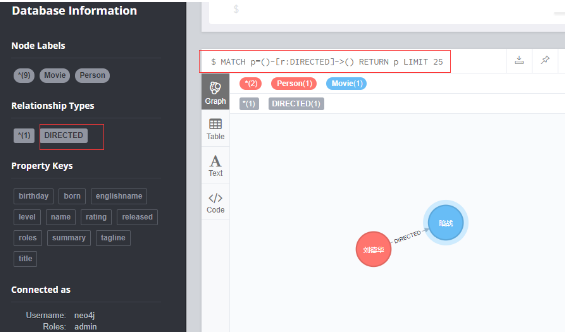
3.2 创建关系,并设置关系的属性
MATCH (a:Person),(b:Movie) WHERE a.name = '刘德华' AND b.title = '神雕侠侣' CREATE (a)-[r:出演 { roles:['杨过'] }]->(b) RETURN r;

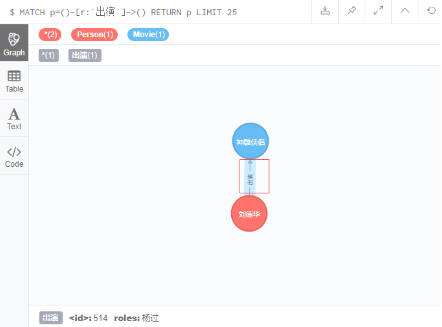
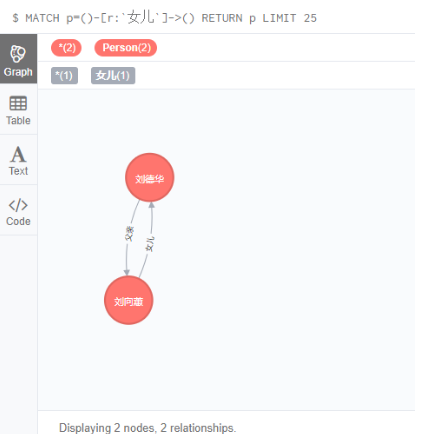
3.3 创建双向关系
刘德华的女是刘向蕙,刘向蕙的父亲是刘德华
MATCH (a:Person),(c:Person)
WHERE a.name = '刘德华' AND c.name = '刘向蕙'
CREATE (a)-[r:父亲 { nickname:'甜心' }]->(c),
(c)-[d:女儿 { nickname:'爹地' }]->(a)
RETURN r;
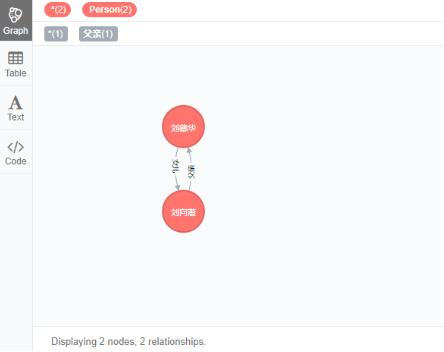
关系建错了 删除关系 (见5.2 )
重新创建
MATCH (a:Person),(c:Person)
WHERE a.name = '刘德华' AND c.name = '刘向蕙'
CREATE (a)-[d:女儿 { nickname:'甜心' }]->(c),
(c)-[r:父亲 { nickname:'爹地' }]->(a)
RETURN r;
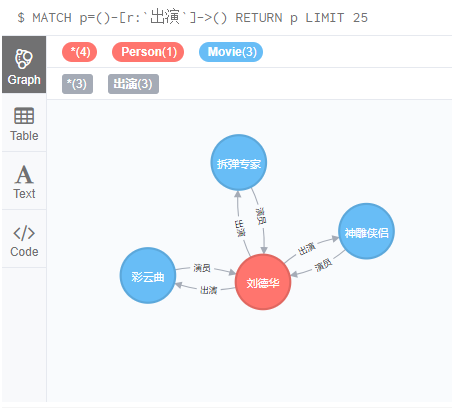
MATCH (a:Person),(c:Movie)
WHERE a.name = '刘德华' AND c.title = '彩云曲'
CREATE (a)-[r:出演 { partner:'张国荣' }]->(c),
(c)-[d:演员 { rolename:'阿华哥' }]->(a)
RETURN r;
MATCH (a:Person),(c:Movie)
WHERE a.name = '刘德华' AND c.title = '拆弹专家'
CREATE (a)-[r:出演 { partner:'赵薇,高圆圆' }]->(c),
(c)-[d:演员 { rolename:'华仔' }]->(a)
RETURN r;
MATCH (a:Person),(c:Movie)
WHERE a.name = '刘德华' AND c.title = '神雕侠侣'
CREATE (a)-[r:出演 { partner:'刘亦菲' }]->(c),
(c)-[d:演员 { rolename:'杨过' }]->(a)
RETURN r;
继续新增关系 刘德华和林志玲,金城武,任贤齐
MATCH (a:Person),(c:Person)
WHERE a.name = '刘德华' AND c.name = '任贤齐'
CREATE (a)-[d:朋友 { sex:'男' }]->(c)
RETURN d;
MATCH (a:Person),(c:Person)
WHERE a.name = '刘德华' AND c.name = '金城武'
CREATE (a)-[d:朋友 { sex:'男' }]->(c)
RETURN d;
这里没有给关系设置属性sex
MATCH (a:Person),(c:Person)
WHERE a.name = '刘德华' AND c.name = '林志玲'
CREATE (a)-[d:朋友]->(c)
RETURN d;
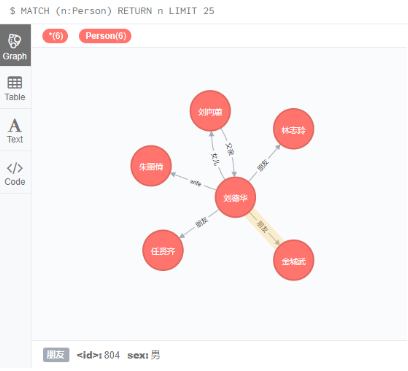
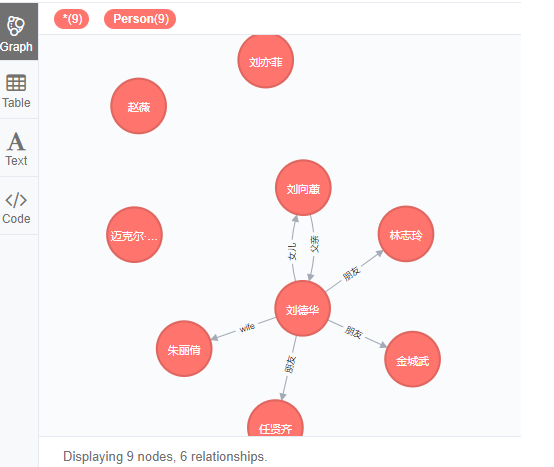
查询Person关系
MATCH (n:Person) RETURN n
4 查询关系
在Cypher中,关系分为三种:符号“--”,表示有关系,忽略关系的类型和方向;符号“-->”和“<--”,表示有方向的关系;
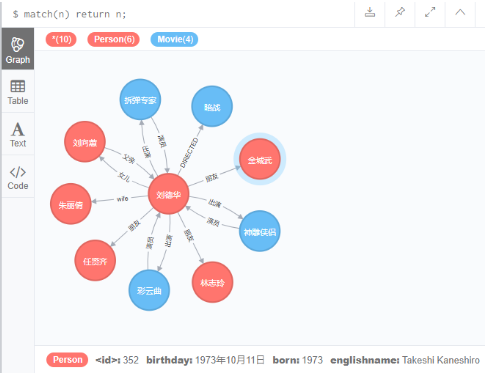
4.1 查询整个数据图形
match(n) return n;
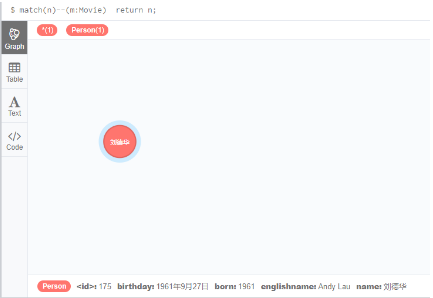
4.2 查询跟指定节点有关系的节点
查询跟Movie标签有关系的所有节点
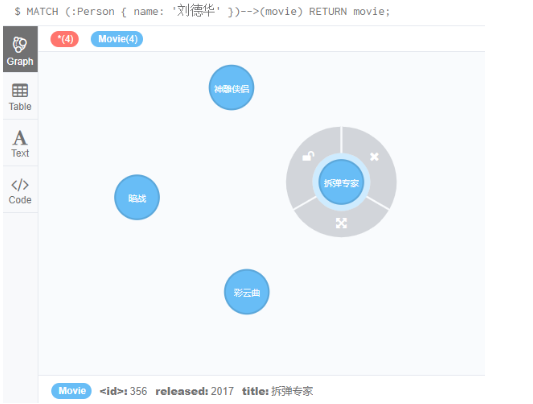
4.3,查询有向关系的节点
查询和刘德华有关系的电影
MATCH (:Person { name: '刘德华' })-->(movie)RETURN movie;
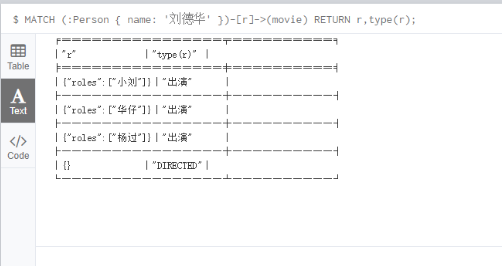
4.4 为关系命名
通过[r]为关系定义一个变量名,通过函数type获取关系的类型
MATCH (:Person { name: '刘德华' })-[r]->(movie) RETURN r,type(r);
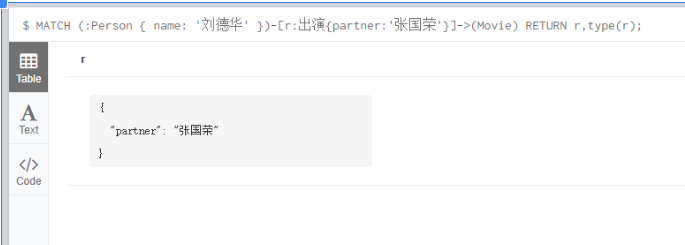
4.5 查询特定的关系类型
通过[Variable:RelationshipType{Key:Value}]指定关系的类型和属性
MATCH (:Person { name: '刘德华' })-[r:出演{partner:'张国荣'}]->(Movie) RETURN r,type(r);
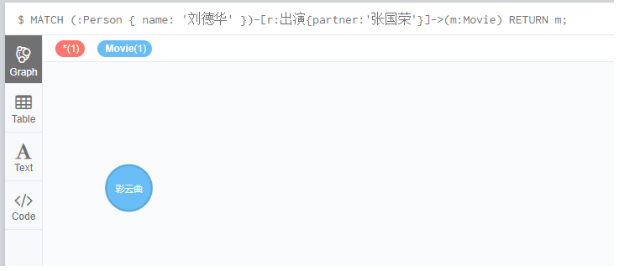
查询和刘德华和张国荣合作过的电影
MATCH (:Person { name: '刘德华' })-[r:出演{partner:'张国荣'}]->(m:Movie) RETURN m;
查询被刘德华称呼为甜心的女儿
MATCH (:Person { name: '刘德华' })-[r:女儿{nickname:'甜心'}]->(m:Person) return m
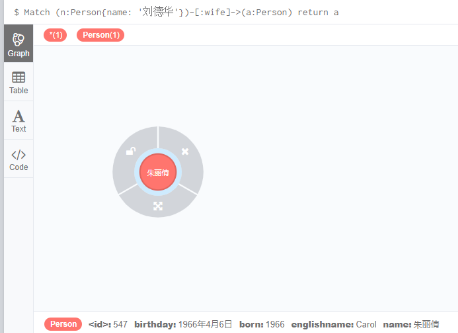
查询刘德华的老婆是谁
Match (n:Person{name: '刘德华'})-[:wife]->(a:Person) return a
刘德华出演过的电影
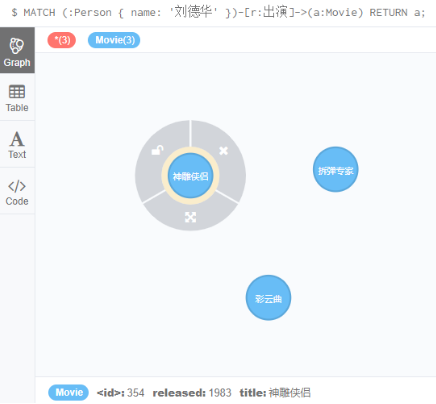
5 删除
5.1删除节点
create (n:City { name: '北京'})
Match (n:City{name:'北京'}) delete n
5.2 删除关系
Match (a:Person{name:'刘德华'})-[r:父亲]->(b:Person{name:'刘向蕙'}) delete r
Match (a:Person{name:'刘向蕙'})-[r:女儿]->(b:Person{name:'刘德华'}) delete r
6 常用查询关键词
6.1 count
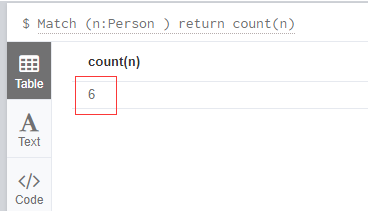
查询Person 一共有多少人
Match (n:Person ) return count(n)
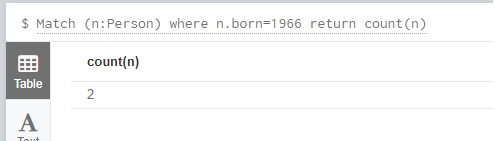
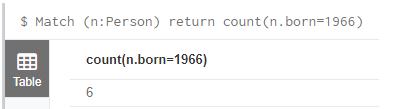
查询标签(Person)中born=1966的一共有多少节点(人):
三种写法(第三种不能用似乎):
1. Match (n:Person) where n.born=1966 return count(n)
2. Match (n:Person{born:1966}) return count(n) //特别注意类型,如果存的类似是数字类型,使用字符串就查不出来,如下:
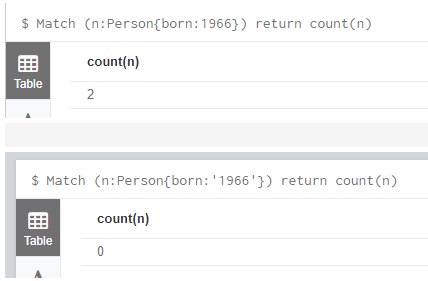
3. Match (n:Person) return count(n.born=1966) //貌似无效?
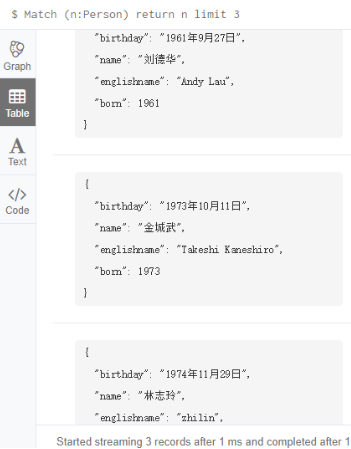
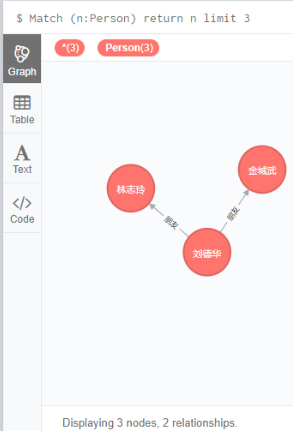
6.2 Limit
Match (n:Person) return n limit 3
6.3 Distinct
Match (n:Person) return distinct(n.born)

6.4 Order by
Match(n:Person) return n order by n.born (默认升序)
Match(n:Person) return n order by n.born asc (升序)
Match(n:Person) return n order by n.born desc (降序)



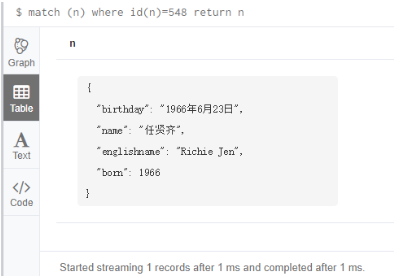
6.5 根据id查找
match (n) where id(n)=548 return n
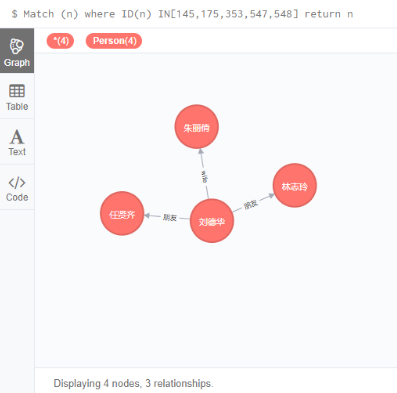
6.6 In的用法
Match (n) where ID(n) IN[353,145,547] return n
Match (n) where ID(n) IN[145,175,353,547,548] return n
//不明白为什么一直少一条记录
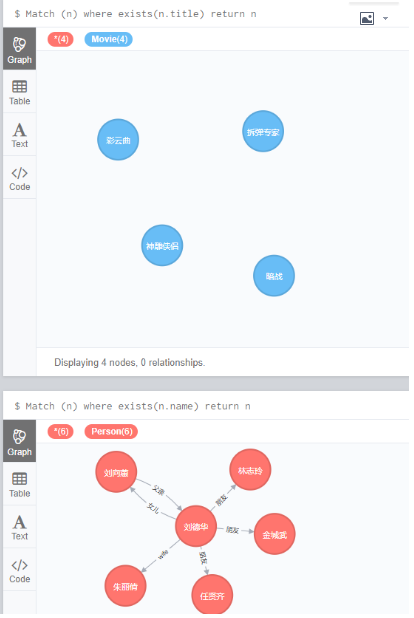
6.7 Exists
节点存在 name这个属性的记录:
Match (n) where exists(n.title) return n
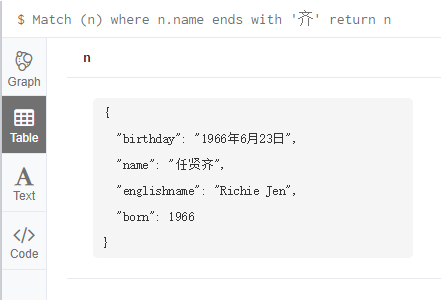
6.8 With
查询name以‘刘’开头的节点:
Match (n) where n.name starts with '刘' return n

查询name以‘明’结尾的节点:
Match (n) where n.name ends with '齐' return n
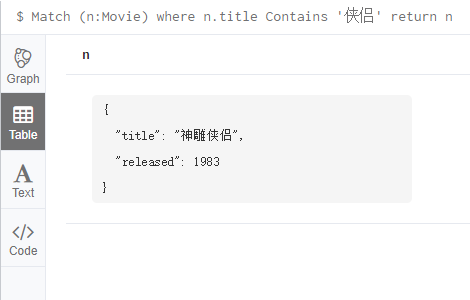
6.9 Contains
查询title中含有 ‘侠侣’的节点
Match (n:Movie) where n.title Contains '侠侣' return n
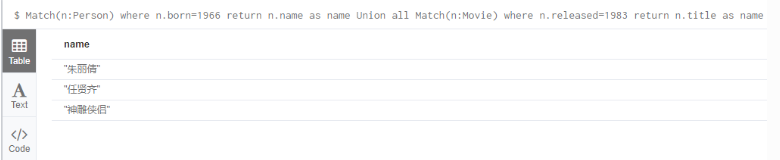
6.10 Union all (Union)
求并集,不去重(去重用Union, as 取别名):
Match(n:Person) where n.born=1966 return n.name as name
Union all
Match(n:Movie) where n.released=1983 return n.title as name
7. 更新
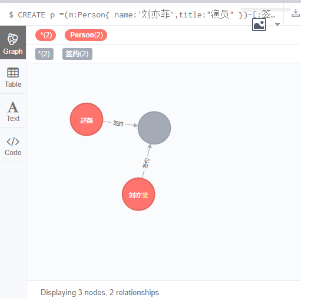
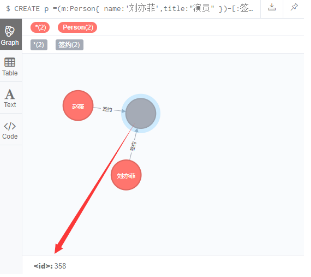
7.1 创建一个完整的Path
CREATE p =(m:Person{ name:'刘亦菲',title:"演员" })-[:签约]->(neo)<-[:签约]-(n:Person { name: '赵薇',title:"投资人" })
RETURN p
7.2 为节点增加一个属性
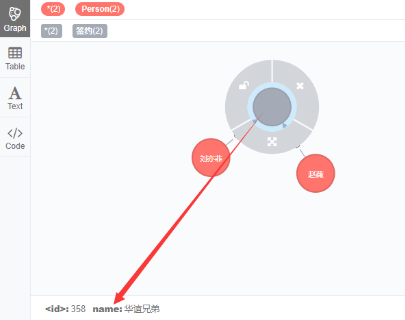
通过节点的ID获取节点,Neo4j推荐通过where子句和ID函数来实现。
match (n)
where id(n)=358
set n.name = '华谊兄弟'
return n;
7.3 为节点增加标签
match (n)
where id(n)=358
set n:公司
return n;
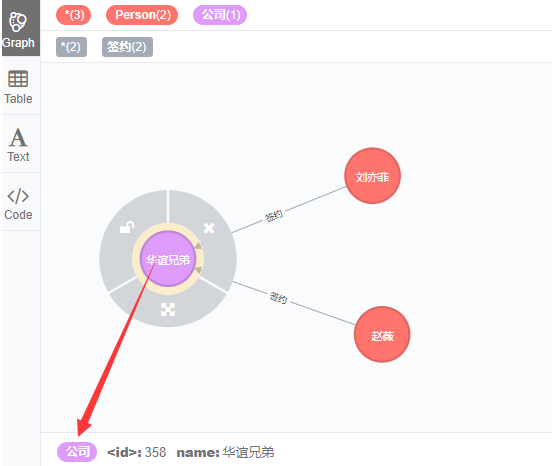
7.4 为关系增加属性
match (n)-[r]->(m)
where id(n)=357 and id(m)=358
set r.经纪人='程晨'
return n;
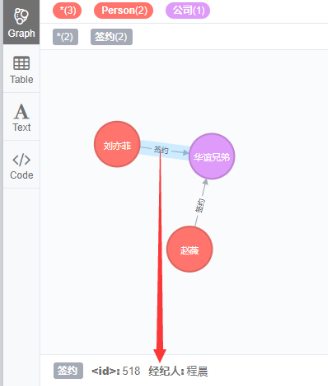
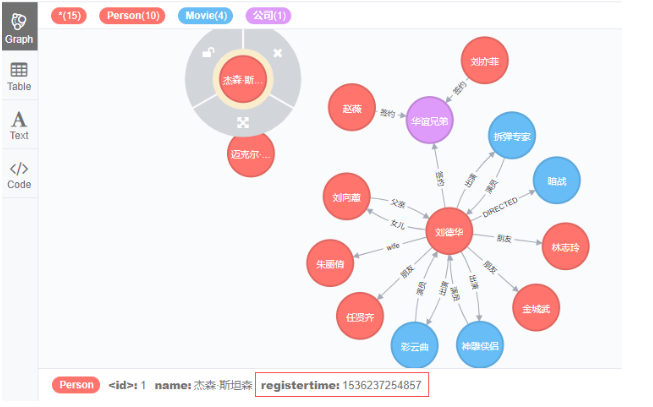
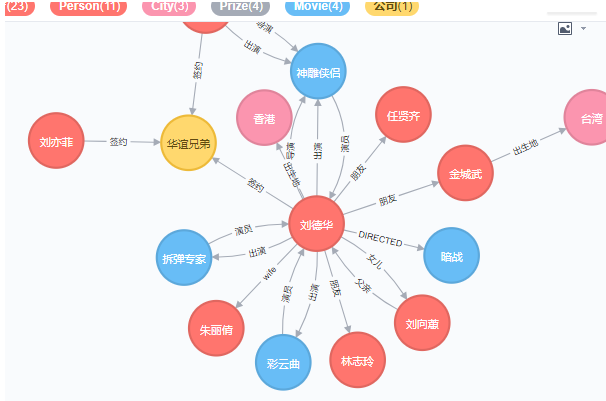
此时图谱效果
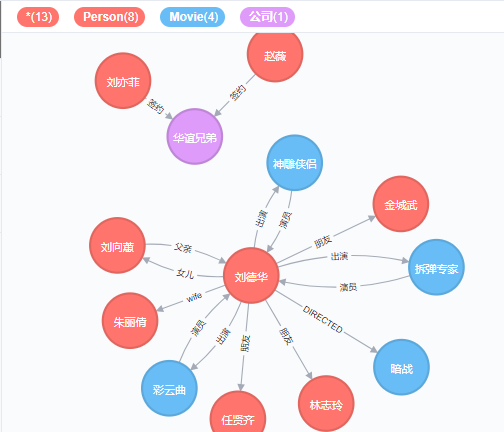
接着让刘德华也和华谊兄弟签约
MATCH (a:Person),(c:公司)
WHERE a.name = '刘德华' AND c.name = '华谊兄弟'
CREATE (a)-[d:签约 { 经纪人:'刘得得' }]->(c)
RETURN d;
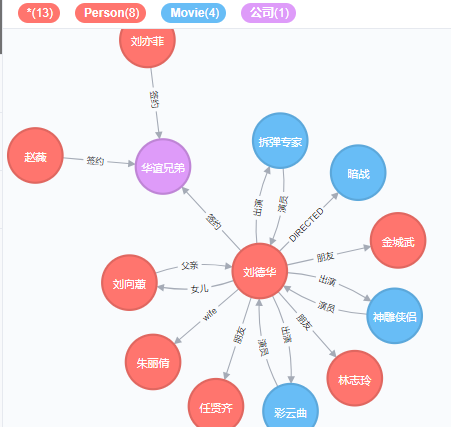
7.5 MERGE
Merge子句的作用有两个:当模式(Pattern)存在时,匹配该模式;当模式不存在时,创建新的模式,功能是match子句和create的组合。在merge子句之后,可以显式指定on creae和on match子句,用于修改绑定的节点或关系的属性。
通过merge子句,你可以指定图形中必须存在一个节点,该节点必须具有特定的标签,属性等,如果不存在,那么merge子句将创建相应的节点。
通过merge子句匹配搜索模式
匹配模式是:一个节点有Person标签,并且具有name属性;如果数据库不存在该模式,那么创建新的节点;如果存在该模式,那么绑定该节点;
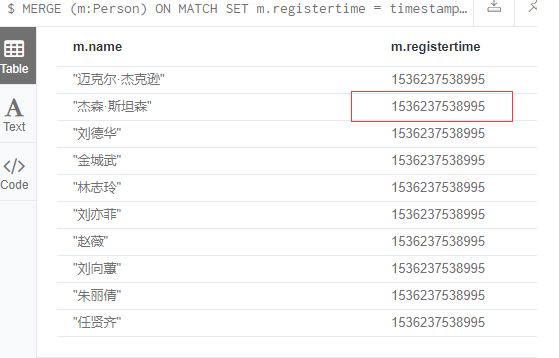
MERGE (m:Person { name: '迈克尔·杰克逊' })
RETURN m;
在merge子句中指定on create子句
如果需要创建节点,那么执行on create子句,修改节点的属性;
MERGE (m:Person { name: '杰森·斯坦森' })
ON CREATE SET m.registertime = timestamp()
RETURN m.name, m.registertime
在merge子句中指定on match子句
如果节点已经存在于数据库中,那么执行on match子句,修改节点的属性;节点属性不存在则新增
MERGE (m:Person)
ON MATCH SET m.registertime = timestamp()
RETURN m.name, m.registertime
在merge子句中同时指定on create 和 on match子句(没有对应属性则修改不成功,不会新增属性)
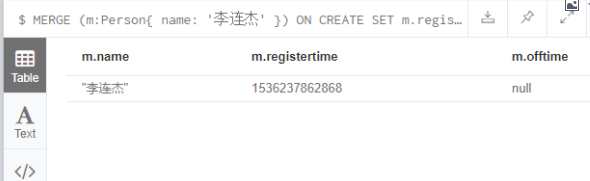
MERGE (m:Person{ name: '李连杰' })
ON CREATE SET m.registertime = timestamp()
ON MATCH SET m.offtime = timestamp()
RETURN m.name, m.registertime,m.offtime

merge子句用于match或create一个关系
MATCH (m:Person { name: '刘德华' }),(n:Movie { title: '神雕侠侣' })
MERGE (m)-[r:导演]->(n)
RETURN m.name, type(r), n.title

merge子句用于match或create多个关系
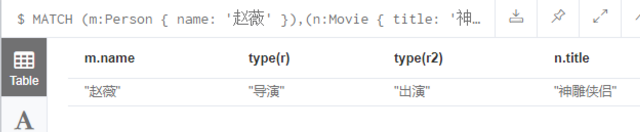
赵薇既是神雕侠侣的导演,也是神雕侠侣的演员
MATCH (m:Person { name: '赵薇' }),(n:Movie { title: '神雕侠侣' })
MERGE (m)-[r:导演]->(n)<-[r2:出演]-(m)
RETURN m.name, type(r),type(r2), n.title
merge子句用于子查询
先添加基础数据
创建城市节点
create (n:City { name: '北京',othername:'帝都'})
create (n:City { name: '香港',othername:'HongKong'})
create (n:City { name: '台湾',othername:'湾湾'})
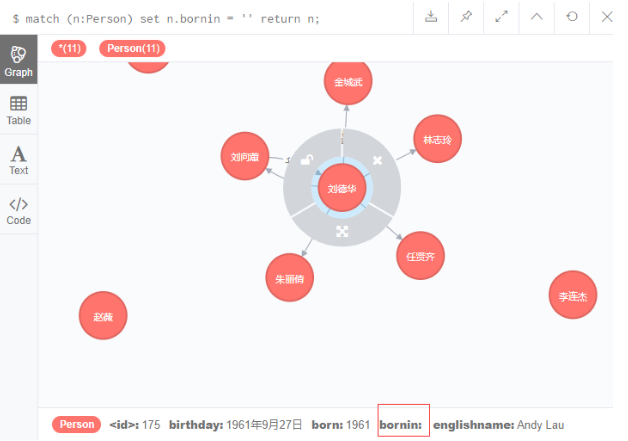
为Person标签的每个节点都增加一个属性 bornin
match (n:Person)
set n.bornin = ''
return n;
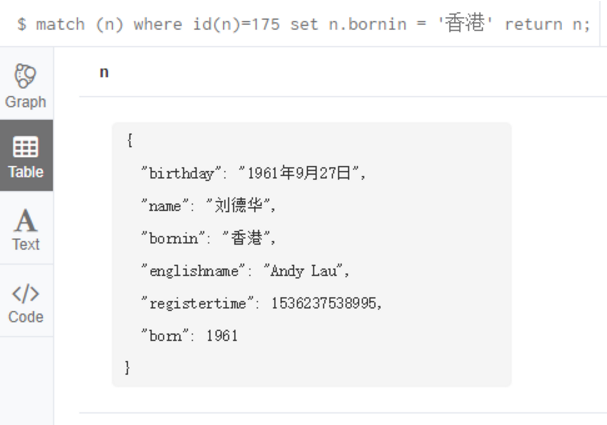
match (n)
where id(n)=175
set n.bornin = '香港'
return n;
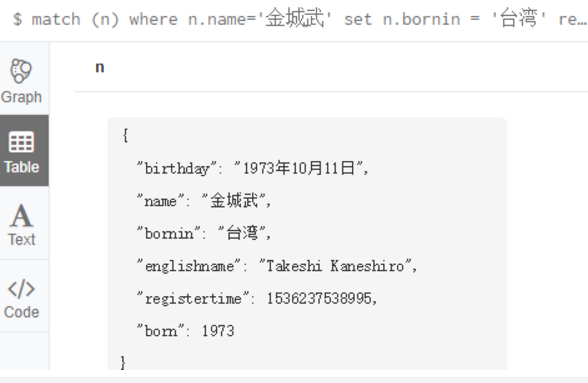
match (n)
where n.name='金城武'
set n.bornin = '台湾'
return n;
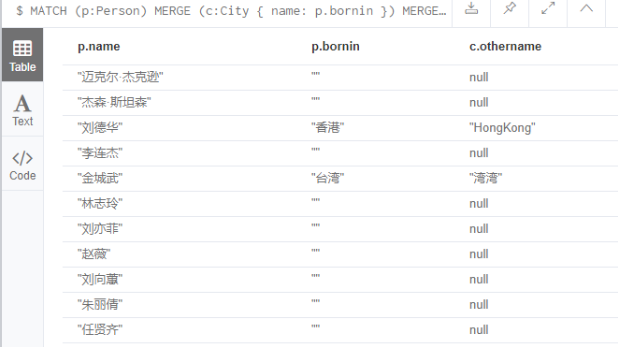
需求:查找刘德华和金城武的信息和所在地的othername(相当于mysql 连表查询)
MATCH (p:Person)
where p.name='刘德华' or p.name='金城武'
MERGE (c:City { name: p.bornin })
RETURN p.name,p.born,p.bornin , c.othername;

创建刘德华出生地是香港这条关系
MATCH (a:Person),(c:City)
WHERE a.name = '刘德华' AND c.name = '香港'
CREATE (a)-[r:出生地]->(c)
RETURN r;
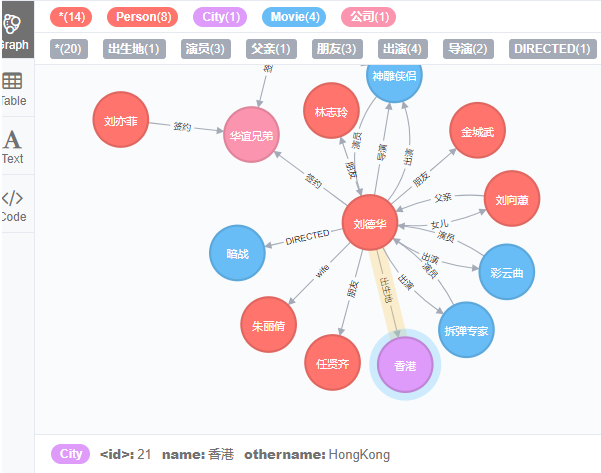
需求:给Person中每个节点都创建一个出生地的关系,没有则返回null
MATCH (p:Person)
MERGE (c:City { name: p.bornin })
MERGE (p)-[r:出生地]->(c)
RETURN p.name, p.bornin, c.othername;

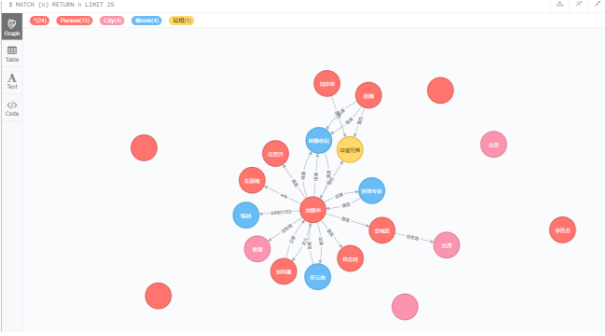
删除这些关系
Match (a:Person)-[r:出生地]->(c:City{name:''}) delete r
Match (a:City)-[r:出生地]->(c:Person) delete r
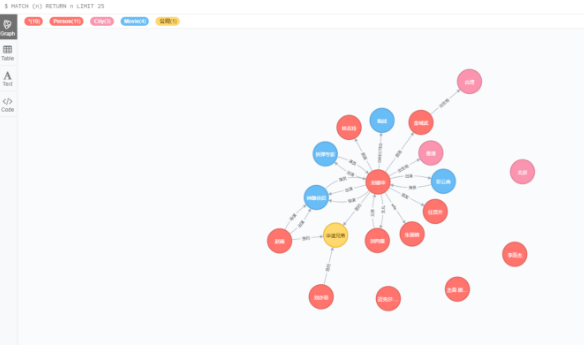
查询Person标签中不存在name属性的节点
Match (n:Person) where not exists(n.name) return n
Match (n:Person) where not exists(n.name) delete n
create (n:Prize { name: '金马奖'});
create (n:Prize { name: '奥斯卡金奖'});
create (n:Prize { name: '金鸡奖'});
create (n:Prize { name: '香港电影金像奖'});
7.6 跟实体相关的函数
通过id函数,返回节点或关系的ID
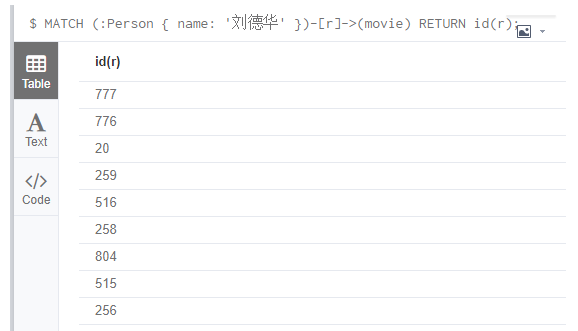
查询Person标签中和刘德华有关系的 id(节点和关系)
MATCH (:Person { name: '刘德华' })-[r]->(movie)
RETURN id(r);
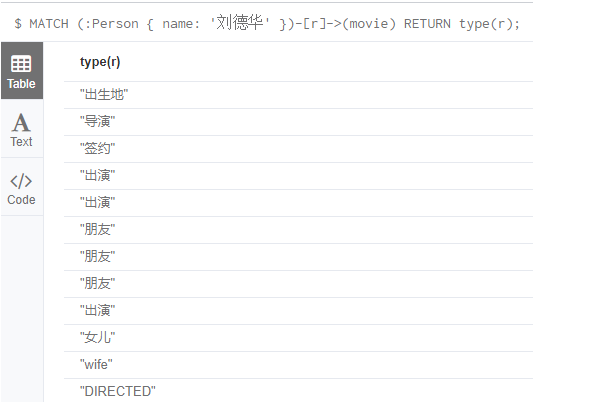
通过type函数,查询关系的类型
查询Person标签中和刘德华相关的关系(以下三种结果相同)
MATCH (:Person { name: '刘德华' })-[r]->(a)
MATCH (:Person { name: '刘德华' })-[r]->(b)
MATCH (:Person { name: '刘德华' })-[r]->()
RETURN type(r);
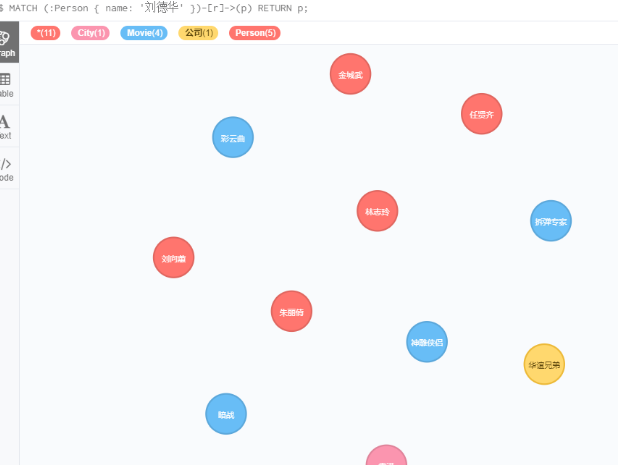
通过lables函数,查询节点的标签
查询和刘德华有关系的节点
MATCH (:Person { name: '刘德华' })-[r]->(p)
RETURN p;
查询和刘德华有关系的标签(去重)
MATCH (:Person { name: '刘德华' })-[r]->(p)
RETURN distinct(labels(p))

通过keys函数,查看节点或关系的属性键
MATCH (a)
WHERE a.name = '刘德华'
RETURN keys(a)

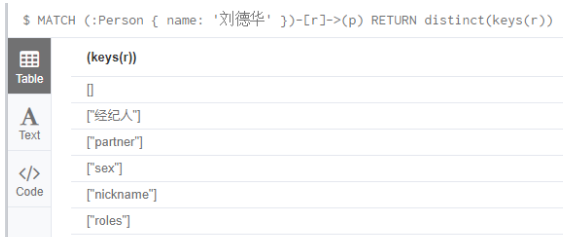
MATCH (:Person { name: '刘德华' })-[r]->(p) RETURN distinct(keys(r))
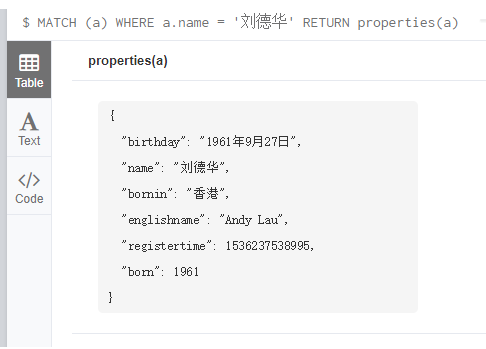
通过properties()函数,查看节点或关系的属性
MATCH (a)
WHERE a.name = '刘德华'
RETURN properties(a)
MATCH (:Person { name: '刘德华' })-[r]->(p) RETURN properties(r)
参考资料:
https://www.cnblogs.com/ljhdo/p/5516793.html
https://www.cnblogs.com/hwaggLee/p/5959716.html
原文地址:https://blog.csdn.net/poxiaomeng187/article/details/82496157
Cypher 语句实战的更多相关文章
- neo4j 基本概念和Cypher语句总结
下面是一个介绍基本概念的例子,参考链接Graph database concepts: (1) Nodes(节点) 图谱的基本单位主要是节点和关系,他们都可以包含属性,一个节点就是一行数据,一个关系也 ...
- neo4j中cypher语句多个模糊查询
总结一下经验: neo4j中,cypher语句的模糊查询,好像是个正则表达式结构. 对于一个属性的多个模糊查询,可以使用如下写法: 比如,查询N类型中,属性attr包含'a1'或者'a2'的所有节点. ...
- CYPHER 语句(Neo4j)
CYPHER 语句(Neo4j) 创建电影关系图 新增 查找 修改 删除 导入 格式转换 创建电影关系图 CREATE (TheMatrix:Movie {title:'The Matrix', re ...
- 50个Sql语句实战
/* 说明:以下五十个语句都按照测试数据进行过测试,最好每次只单独运行一个语句. 问题及描述:--1.学生表Student(S#,Sname,Sage,Ssex) --S# 学生编号,Sname 学生 ...
- If条件语句实战
1.If条件判断语句 通常以if开头,fi结尾.也可加入else或者elif进行多条件的判断,if表达式如下: if (表达式) 语句1 else 语句2 fi 2.If常见判断逻辑运算符详解: -f ...
- Mysql 常用语句实战(3)
前置 sql 语句 用来创建表.插入数据 ; DROP TABLE IF EXISTS dept_;-- 部门表 DROP TABLE IF EXISTS emp_;-- 部门表 ; SELECT @ ...
- cypher语句摘要
match(n) return n 返回所有的节点和关系,只要有就返回,对节点和关系的查找不做条件限制. match(n:Student) return n 返回所有的Student节点 创建节点:c ...
- Mysql 常用语句实战(2)
前置 sql 语句 用来创建表.插入数据 SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- ...
- Mysql 常用语句实战(1)
前置 sql 语句 用来创建表.插入数据 DROP TABLE IF EXISTS `emp`; CREATE TABLE `emp` ( `id` int(11) NOT NULL COMMENT ...
随机推荐
- C++ - 操作运算符
一.操作运算符 操作运算符:在C++中,编译器有能力将数据.对象和操作符共同组成表达式,解释为对全局或成员函数的调用 该全局或成员函数被称为操作符函数,程序员可以通过重定义函数操作符函数,来达到自己想 ...
- 2018山东省赛 G Game ( Nim博弈 && DP )
题目链接 题意 : 给出 N 堆石子,每次可以选择一堆石子拿走任意颗石子,最后没有石子拿的人为败者.现在后手 Bob 可以在游戏开始前拿掉不超过 d 堆的整堆石子,现在问你有几种取走的组合使得 Bob ...
- Codeforces Round #345 (Div. 2) E. Table Compression 并查集+智商题
E. Table Compression time limit per test 4 seconds memory limit per test 256 megabytes input standar ...
- floor函数用法
floor(x),也写做Floor(x),其功能是“向下取整”,或者说“向下舍入”,即取不大于x的最大整数(与“四舍五入”不同,下取整是直接取按照数轴上最接近要求值的左边值,即不大于要求值的最大的那个 ...
- luogu P1083 借教室 x
P1083 借教室 题目描述 在大学期间,经常需要租借教室.大到院系举办活动,小到学习小组自习讨论,都需要向学校申请借教室.教室的大小功能不同,借教室人的身份不同,借教室的手续也不一样. 面对海量租借 ...
- 手写ORM
利用ORM把mysql中的数据封装成对象,通过对象点语法来获取mysql中的数据,所以自己手写一个ORM,方便我们操作数据 一.ORM:对象关系映射 类 >>> 数据库的一张表 对象 ...
- 用JQuery获取事件源怎么写
$(".btn").click(function(e){ // e 就是事件对象 e.target; // 事件的目标 dom e.currentTarget; // 事件处理程序 ...
- 项目三、文件上传器v1.1
/** * 自定义文件上传工具 v1.1 * @param url 路径 */ function fileUploader(url) { var _date = new Date(); //日期 th ...
- PADS LAYOUT的一般流程
1.概述 本文档的目的在于说明使用PADS的印制板设计软件PowerPCB进行印制板设计的流程和一些注意事项,为一个工作组的设计人员提供设计规 范,方便设计人员之间进行交流和相互检查. 2.设计 ...
- ES6数组的拓展
扩展运算符 扩展运算符(spread)是三个点(...).它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列. console.log(...[1, 2, 3]) // 1 2 3 c ...