jvm系列二内存结构
二、内存结构
整体架构
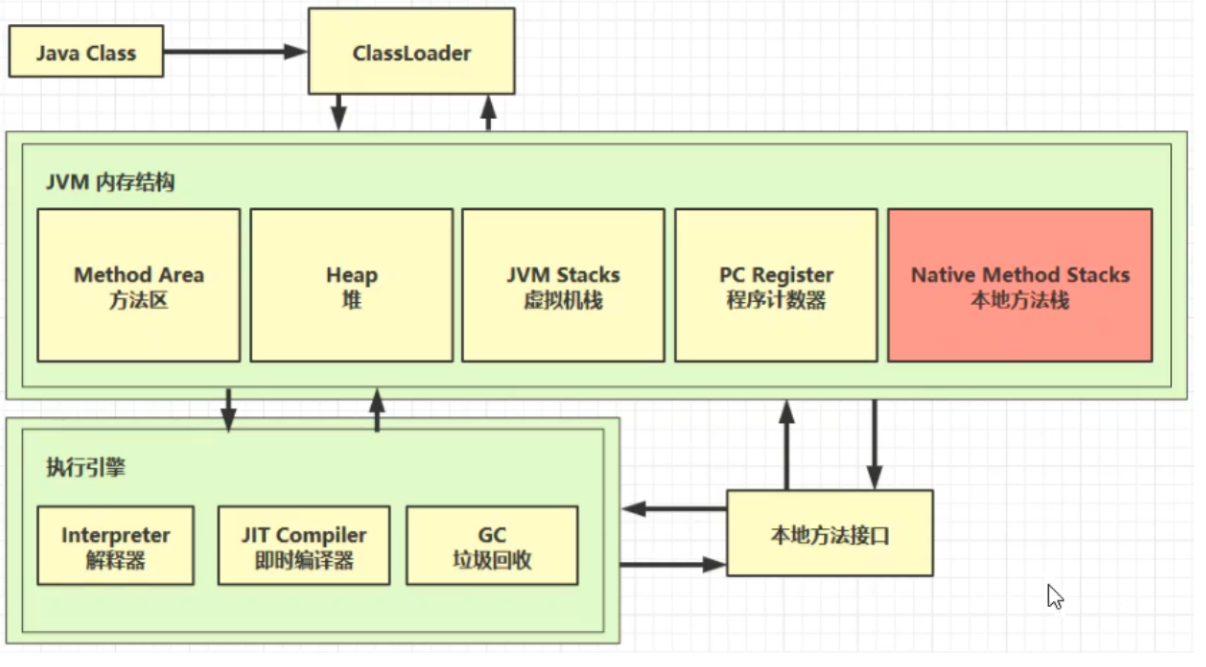
1、程序计数器
作用
用于保存JVM中下一条所要执行的指令的地址
特点
- 线程私有
- CPU会为每个线程分配时间片,当当前线程的时间片使用完以后,CPU就会去执行另一个线程中的代码
- 程序计数器是每个线程所私有的,当另一个线程的时间片用完,又返回来执行当前线程的代码时,通过程序计数器可以知道应该执行哪一句指令
- 不会存在内存溢出
2、虚拟机栈
定义
每个线程运行需要的内存空间,称为虚拟机栈
每个栈由多个栈帧组成,对应着每次调用方法时所占用的内存
每个线程只能有一个活动栈帧,对应着当前正在执行的方法
演示
代码
public class Main {
public static void main(String[] args) {
method1();
}
private static void method1() {
method2(1, 2);
}
private static int method2(int a, int b) {
int c = a + b;
return c;
}
}
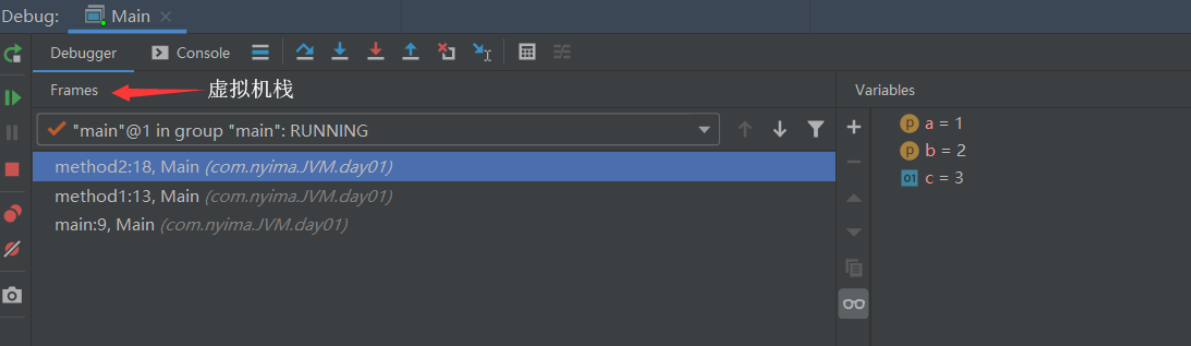
在控制台中可以看到,主类中的方法在进入虚拟机栈的时候,符合栈的特点
问题辨析
- 垃圾回收是否涉及栈内存?
- 不需要。因为虚拟机栈中是由一个个栈帧组成的,在方法执行完毕后,对应的栈帧就会被弹出栈。所以无需通过垃圾回收机制去回收内存。
- 栈内存的分配越大越好吗?
- 不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。
- 方法内的局部变量是否是线程安全的?
- 如果方法内局部变量没有逃离方法的作用范围,则是线程安全的
- 如果如果局部变量引用了对象,并逃离了方法的作用范围,则需要考虑线程安全问题
内存溢出
Java.lang.stackOverflowError 栈内存溢出
发生原因
- 虚拟机栈中,栈帧过多(无限递归)
- 每个栈帧所占用过大
线程运行诊断
CPU占用过高
- Linux环境下运行某些程序的时候,可能导致CPU的占用过高,这时需要定位占用CPU过高的线程
- top命令,查看是哪个进程占用CPU过高
- ps H -eo pid, tid(线程id), %cpu | grep 刚才通过top查到的进程号 通过ps命令进一步查看是哪个线程占用CPU过高
- jstack 进程id 通过查看进程中的线程的nid,刚才通过ps命令看到的tid来对比定位,注意jstack查找出的线程id是16进制的,需要转换
3、本地方法栈
一些带有native关键字的方法就是需要JAVA去调用本地的C或者C++方法,因为JAVA有时候没法直接和操作系统底层交互,所以需要用到本地方法
4、堆
定义
通过new关键字创建的对象都会被放在堆内存
特点
- 所有线程共享,堆内存中的对象都需要考虑线程安全问题
- 有垃圾回收机制
堆内存溢出
java.lang.OutofMemoryError :java heap space. 堆内存溢出
堆内存诊断
jps
jmap
jconsole
jvirsalvm
5、方法区
结构
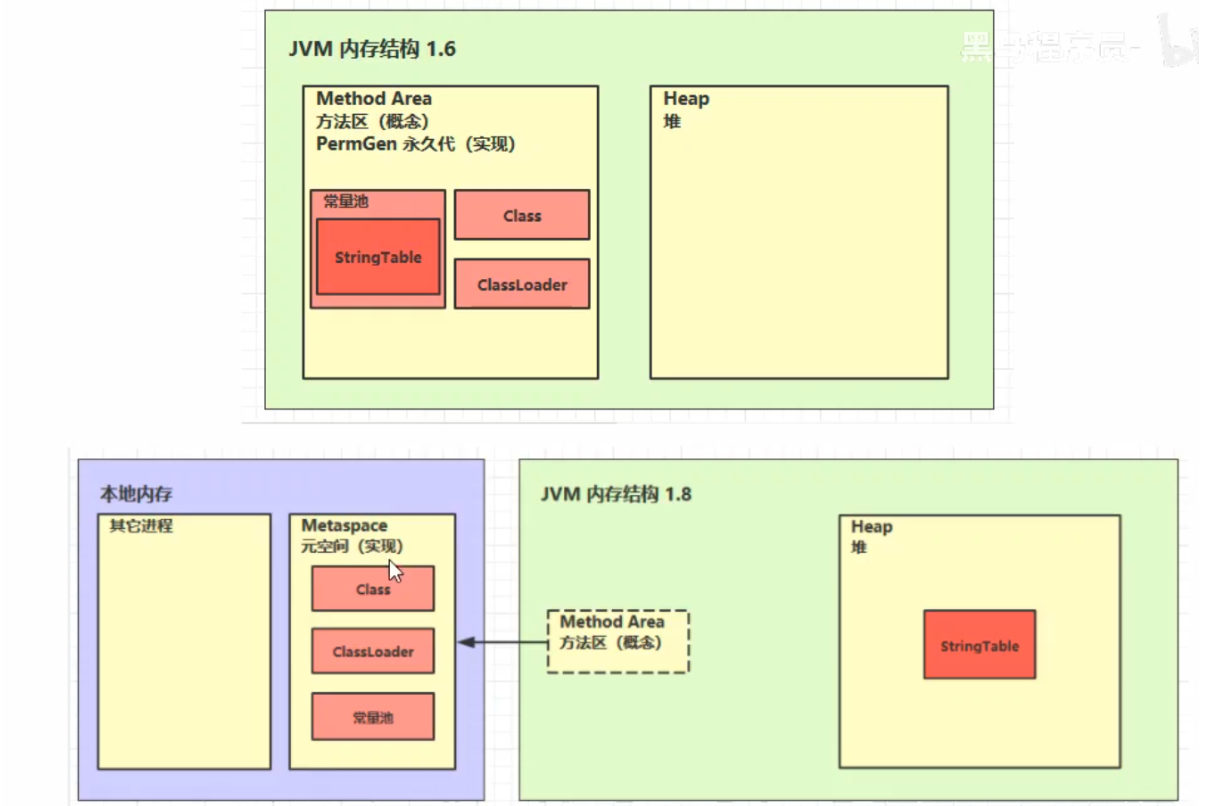
内存溢出
- 1.8以前会导致永久代内存溢出
- 1.8以后会导致元空间内存溢出
常量池
二进制字节码的组成:类的基本信息、常量池、类的方法定义(包含了虚拟机指令)
通过反编译来查看类的信息
获得对应类的.class文件
在JDK对应的bin目录下运行cmd,也可以在IDEA控制台输入

输入 javac 对应类的绝对路径
F:\JAVA\JDK8.0\bin>javac F:\Thread_study\src\com\nyima\JVM\day01\Main.java
输入完成后,对应的目录下就会出现类的.class文件
在控制台输入 javap -v 类的绝对路径
javap -v F:\Thread_study\src\com\nyima\JVM\day01\Main.class
然后能在控制台看到反编译以后类的信息了
类的基本信息
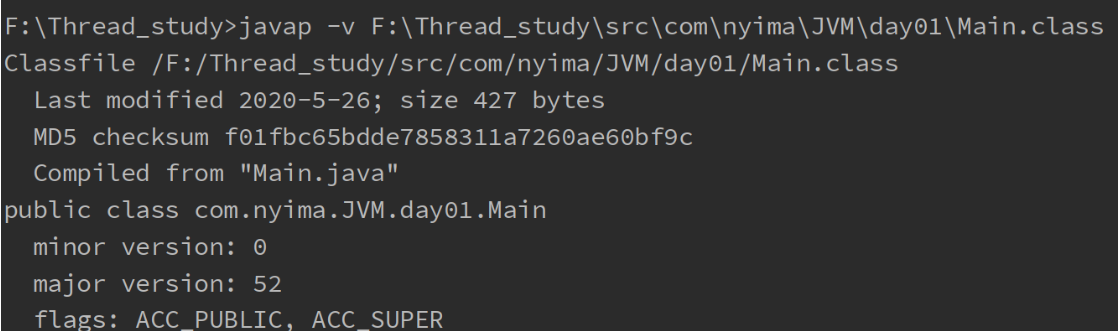
常量池
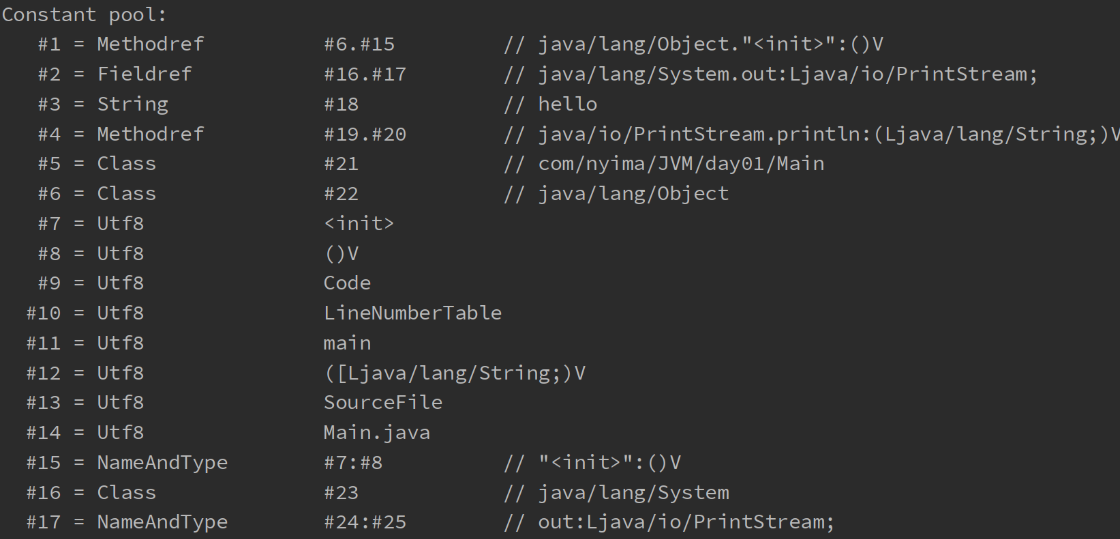
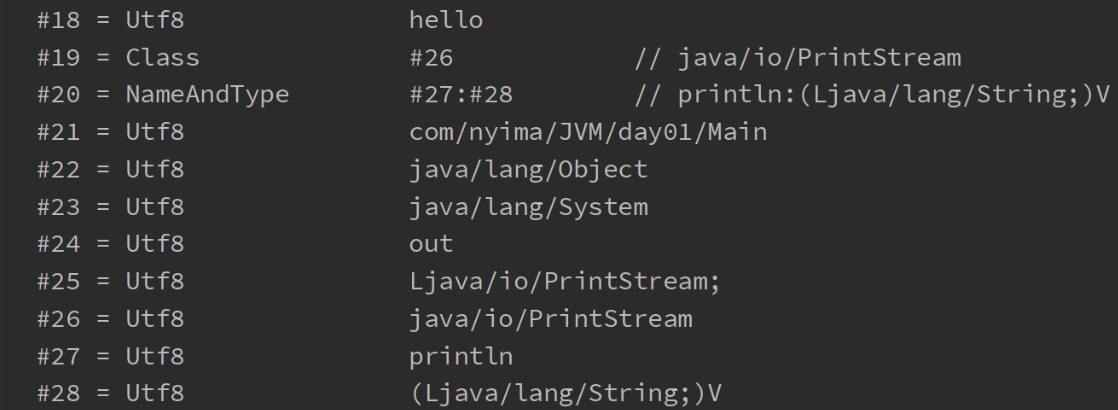
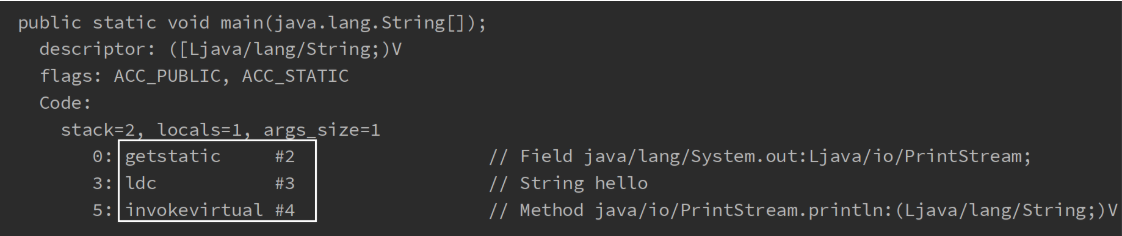
虚拟机中执行编译的方法(框内的是真正编译执行的内容,#号的内容需要在常量池中查找)
运行时常量池
- 常量池
- 就是一张表(如上图中的constant pool),虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量信息
- 运行时常量池
- 常量池是_.class文件中的,当该*_类被加载以后,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址**
常量池与串池的关系
串池StringTable
特征
- 常量池中的字符串仅是符号,只有在被用到时才会转化为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是StringBuilder
- 字符串常量拼接的原理是编译器优化
- 可以使用intern方法,主动将串池中还没有的字符串对象放入串池中
- 注意:无论是串池还是堆里面的字符串,都是对象
用来放字符串对象且里面的元素不重复
public class StringTableStudy {
public static void main(String[] args) {
String a = "a";
String b = "b";
String ab = "ab";
}
}
常量池中的信息,都会被加载到运行时常量池中,但这是a b ab 仅是常量池中的符号,还没有成为java字符串
0: ldc #2 // String a
2: astore_1
3: ldc #3 // String b
5: astore_2
6: ldc #4 // String ab
8: astore_3
9: return
当执行到 ldc #2 时,会把符号 a 变为 “a” 字符串对象,并放入串池中(hashtable结构 不可扩容)
当执行到 ldc #3 时,会把符号 b 变为 “b” 字符串对象,并放入串池中
当执行到 ldc #4 时,会把符号 ab 变为 “ab” 字符串对象,并放入串池中
最终StringTable [“a”, “b”, “ab”]
注意:字符串对象的创建都是懒惰的,只有当运行到那一行字符串且在串池中不存在的时候(如 ldc #2)时,该字符串才会被创建并放入串池中。
使用拼接字符串变量对象创建字符串的过程
public class StringTableStudy {
public static void main(String[] args) {
String a = "a";
String b = "b";
String ab = "ab";
//拼接字符串对象来创建新的字符串
String ab2 = a+b;
}
}
反编译后的结果
Code:
stack=2, locals=5, args_size=1
0: ldc #2 // String a
2: astore_1
3: ldc #3 // String b
5: astore_2
6: ldc #4 // String ab
8: astore_3
9: new #5 // class java/lang/StringBuilder
12: dup
13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V
16: aload_1
17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String
;)Ljava/lang/StringBuilder;
20: aload_2
21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String
;)Ljava/lang/StringBuilder;
24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/Str
ing;
27: astore 4
29: return
通过拼接的方式来创建字符串的过程是:StringBuilder().append(“a”).append(“b”).toString()
最后的toString方法的返回值是一个新的字符串,但字符串的值和拼接的字符串一致,但是两个不同的字符串,一个存在于串池之中,一个存在于堆内存之中
String ab = "ab";
String ab2 = a+b;
//结果为false,因为ab是存在于串池之中,ab2是由StringBuffer的toString方法所返回的一个对象,存在于堆内存之中
System.out.println(ab == ab2);
使用拼接字符串常量对象的方法创建字符串
public class StringTableStudy {
public static void main(String[] args) {
String a = "a";
String b = "b";
String ab = "ab";
String ab2 = a+b;
//使用拼接字符串的方法创建字符串
String ab3 = "a" + "b";
}
}
反编译后的结果
Code:
stack=2, locals=6, args_size=1
0: ldc #2 // String a
2: astore_1
3: ldc #3 // String b
5: astore_2
6: ldc #4 // String ab
8: astore_3
9: new #5 // class java/lang/StringBuilder
12: dup
13: invokespecial #6 // Method java/lang/StringBuilder."<init>":()V
16: aload_1
17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String
;)Ljava/lang/StringBuilder;
20: aload_2
21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String
;)Ljava/lang/StringBuilder;
24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/Str
ing;
27: astore 4
//ab3初始化时直接从串池中获取字符串
29: ldc #4 // String ab
31: astore 5
33: return
- 使用拼接字符串常量的方法来创建新的字符串时,因为内容是常量,javac在编译期会进行优化,结果已在编译期确定为ab,而创建ab的时候已经在串池中放入了“ab”,所以ab3直接从串池中获取值,所以进行的操作和 ab = “ab” 一致。
- 使用拼接字符串变量的方法来创建新的字符串时,因为内容是变量,只能在运行期确定它的值,所以需要使用StringBuffer来创建
intern方法 1.8
调用字符串对象的intern方法,会将该字符串对象尝试放入到串池中
- 如果串池中没有该字符串对象,则放入成功
- 如果有该字符串对象,则放入失败
无论放入是否成功,都会返回串池中的字符串对象
注意:此时如果调用intern方法成功,堆内存与串池中的字符串对象是同一个对象;如果失败,则不是同一个对象
例1
public class Main {
public static void main(String[] args) {
//"a" "b" 被放入串池中,str则存在于堆内存之中
String str = new String("a") + new String("b");
//调用str的intern方法,这时串池中没有"ab",则会将该字符串对象放入到串池中,此时堆内存与串池中的"ab"是同一个对象
String st2 = str.intern();
//给str3赋值,因为此时串池中已有"ab",则直接将串池中的内容返回
String str3 = "ab";
//因为堆内存与串池中的"ab"是同一个对象,所以以下两条语句打印的都为true
System.out.println(str == st2);
System.out.println(str == str3);
}
}
例2
public class Main {
public static void main(String[] args) {
//此处创建字符串对象"ab",因为串池中还没有"ab",所以将其放入串池中
String str3 = "ab";
//"a" "b" 被放入串池中,str则存在于堆内存之中
String str = new String("a") + new String("b");
//此时因为在创建str3时,"ab"已存在与串池中,所以放入失败,但是会返回串池中的"ab"
String str2 = str.intern();
//false
System.out.println(str == str2);
//false
System.out.println(str == str3);
//true
System.out.println(str2 == str3);
}
}
intern方法 1.6
调用字符串对象的intern方法,会将该字符串对象尝试放入到串池中
- 如果串池中没有该字符串对象,会将该字符串对象复制一份,再放入到串池中
- 如果有该字符串对象,则放入失败
无论放入是否成功,都会返回串池中的字符串对象
注意:此时无论调用intern方法成功与否,串池中的字符串对象和堆内存中的字符串对象都不是同一个对象
StringTable 垃圾回收
StringTable在内存紧张时,会发生垃圾回收
StringTable调优
因为StringTable是由HashTable实现的,所以可以适当增加HashTable桶的个数,来减少字符串放入串池所需要的时间
-XX:StringTableSize=xxxx
考虑是否需要将字符串对象入池
可以通过intern方法减少重复入池
6、直接内存
- 属于操作系统,常见于NIO操作时,用于数据缓冲区
- 分配回收成本较高,但读写性能高
- 不受JVM内存回收管理
文件读写流程
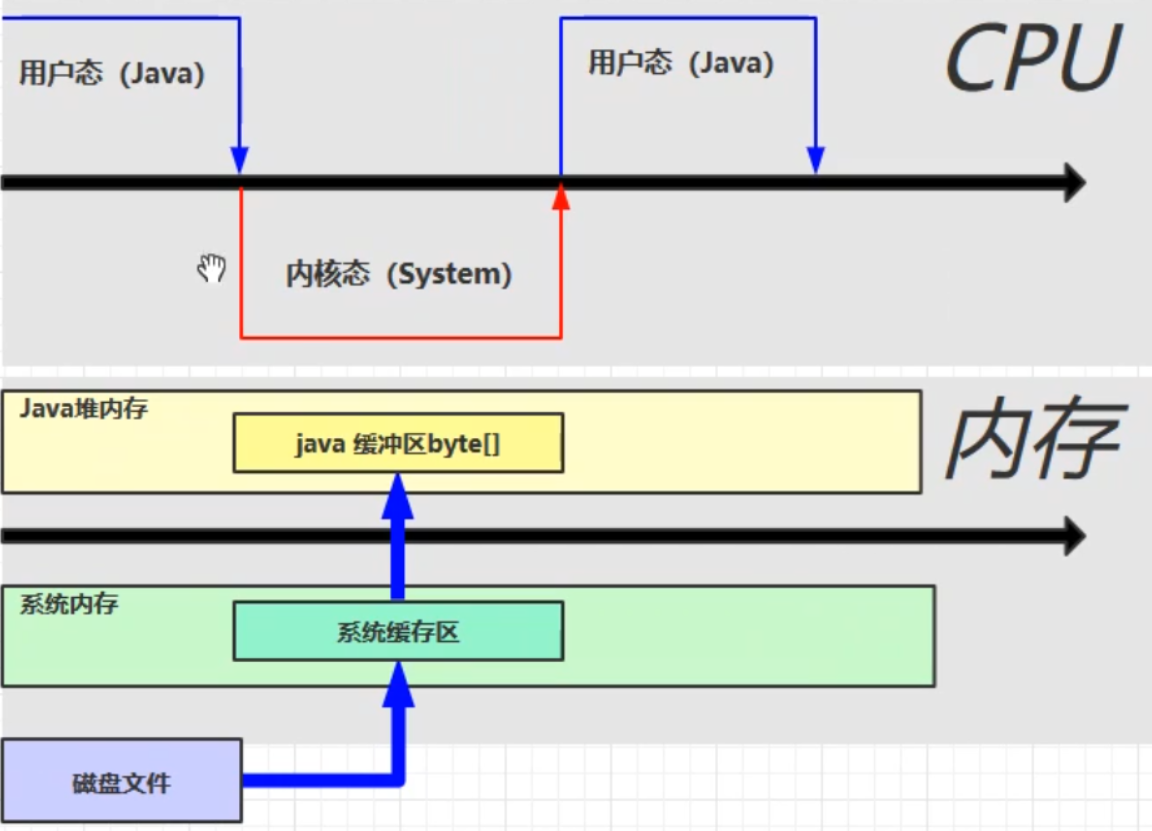
使用了DirectBuffer
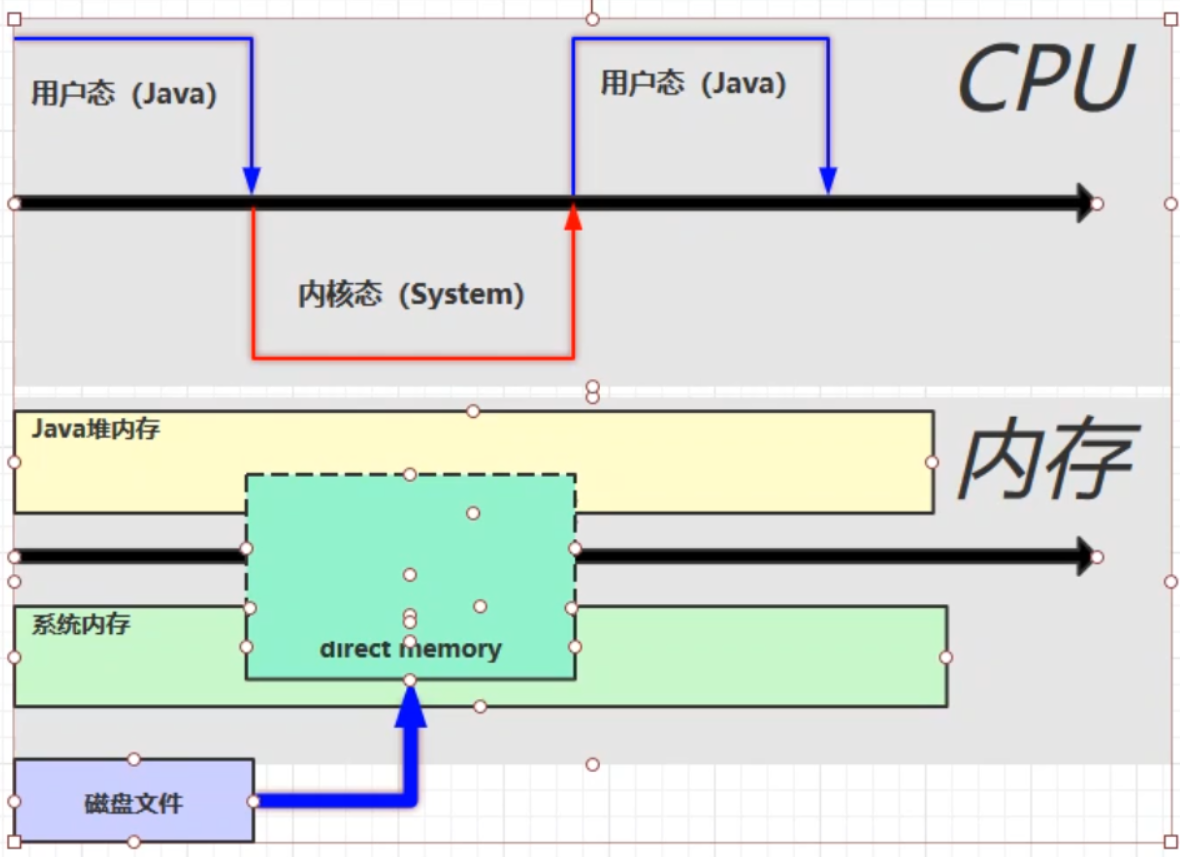
直接内存是操作系统和Java代码都可以访问的一块区域,无需将代码从系统内存复制到Java堆内存,从而提高了效率
释放原理
直接内存的回收不是通过JVM的垃圾回收来释放的,而是通过unsafe.freeMemory来手动释放
通过
//通过ByteBuffer申请1M的直接内存
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1M);
申请直接内存,但JVM并不能回收直接内存中的内容,它是如何实现回收的呢?
allocateDirect的实现
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
DirectByteBuffer类
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size); //申请内存
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); //通过虚引用,来实现直接内存的释放,this为虚引用的实际对象
att = null;
}
这里调用了一个Cleaner的create方法,且后台线程还会对虚引用的对象监测,如果虚引用的实际对象(这里是DirectByteBuffer)被回收以后,就会调用Cleaner的clean方法,来清除直接内存中占用的内存
public void clean() {
if (remove(this)) {
try {
this.thunk.run(); //调用run方法
} catch (final Throwable var2) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (System.err != null) {
(new Error("Cleaner terminated abnormally", var2)).printStackTrace();
}
System.exit(1);
return null;
}
});
}
对应对象的run方法
public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address); //释放直接内存中占用的内存
address = 0;
Bits.unreserveMemory(size, capacity);
}
直接内存的回收机制总结
- 使用了Unsafe类来完成直接内存的分配回收,回收需要主动调用freeMemory方法
- ByteBuffer的实现内部使用了Cleaner(虚引用)来检测ByteBuffer。一旦ByteBuffer被垃圾回收,那么会由ReferenceHandler来调用Cleaner的clean方法调用freeMemory来释放内存
jvm系列二内存结构的更多相关文章
- jvm系列(二):JVM内存结构
JVM内存结构 所有的Java开发人员可能会遇到这样的困惑?我该为堆内存设置多大空间呢?OutOfMemoryError的异常到底涉及到运行时数据的哪块区域?该怎么解决呢?其实如果你经常解决服务器性能 ...
- jvm系列二、JVM内存结构
原文链接:http://www.cnblogs.com/ityouknow/p/5610232.html 所有的Java开发人员可能会遇到这样的困惑?我该为堆内存设置多大空间呢?OutOfMemory ...
- jvm系列 (二) ---垃圾收集器与内存分配策略
垃圾收集器与内存分配策略 前言:本文基于<深入java虚拟机>再加上个人的理解以及其他相关资料,对内容进行整理浓缩总结.本文中的图来自网络,感谢图的作者.如果有不正确的地方,欢迎指出. 目 ...
- JVM系列(二):JVM的内存模型
深入理解JVM内存模型 Java虚拟机在执行Java程序的过程中,把它所管理里的内存划分了不同的数据类型区域,作为一名开发者,我们需要了解jvm的内存分配机制以及这些不同的数据区域各自的作用. ...
- [转]oracle学习入门系列之五内存结构、数据库结构、进程
原文地址:http://www.2cto.com/database/201505/399285.html 1 Oracle数据库结构 关于这个话题,网上一搜绝对一大把,更别提书籍上出现的了,还有很多大 ...
- JVM原理及内存结构
JVM是按照运行时数据的存储结构来划分内存结构的,JVM在运行java程序时,将它们划分成几种不同格式的数据,分别存储在不同的区域,这些数据统一称为运行时数据.运行时数据包括java程序本身的数据信息 ...
- jvm(1):内存结构
JVM内存结构 JVM内存的运行时数据区: 线程私有(在线程启动时创建) 程序计数器Program Counter Register 一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器, ...
- JVM学习之 内存结构
目录 一.引言 1.什么是JVM? 2.学习JVM有什么用 3.常见的JVM 4.学习路线 二.内存结构 1. 程序计数器 1.1 定义 1.2作用 2. 虚拟机栈 2.1定义 2.2栈内存溢出 2. ...
- JVM之--Java内存结构(第一篇)
最近在和同事朋友聊天的时候,发现一个很让人思考的问题,很多人总觉得JVM将java和操作系统隔离开来,导致很多人不用熟悉操作系统,甚至不用了解JVM本身即可完全掌握Java这一门技术,其实个人的观点是 ...
随机推荐
- 2.1 关系型数据的收集--Sqoop
Sqoop应用场景: 1.数据迁移,将关系型数据库中的数据导入Hadoop存储系统 2.可视化分析结果,将Hadoop处理之后产生的结果导入关系型数据库,以便进行可视化展示 3.数据增量导入:减少ha ...
- node使用xlsx导入导出excel
1.安装和引入xlsx 安装 npm install xlsx 引入:let xlsx = require('xlsx');2.读取excel数据function readFile(file) { ...
- Docker进行MySQL主从复制操作
Docker的相关操作 与 Docker下MySQL容器的安装 https://www.cnblogs.com/yumq/p/14253360.html 本次实验我是在单机状态下进行mysql的主从复 ...
- k8s之API Server认证
集群安全性 在生产环境中,必须保障集群用户的角色以及权限问题,不能给所有用户都赋予管理员权限. 1.集群的安全性必须考虑如下几个目标 (1)保证容器与其所在宿主机的隔离 (2)限制容器给基础设置或其他 ...
- M43 第一阶段考试
一.解答题 1.统计当前主机的TCP协议网络各种连接状态出现的次数 netstat -an | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a ...
- Vue 组件内滚动条 滚到到底部
因为在vue中,某个组件内 使用scrollTop赋值 滚动条没有变化 使用scrollTo 也不行(window.scorllTo 或者dom.scrollTo) 所以可以考虑使用投机取巧的办法: ...
- qmake奇淫技巧之字符串宏定义
阅读本文大概需要3.3分钟 我们平时在软件开发过程中需要定义一些宏,以便在代码中调用,这样每次不需要修改代码,只需要修改外部编译命令就可以得到想要的参数,非常方便 比如我们想在软件介绍中显示软件版本, ...
- os.walk() 遍历目录下的文件夹和文件
os.walk(top, topdown=True, onerror=None, followlinks=False) top:顶级目录 os.walk()返回一个三元tupple(dirpath, ...
- 在recover database时,如何决定该从哪一个SCN开始恢复
使用备份恢复的方法搭建DG库,还原数据文件后,打开数据库时报错 SQL> ALTER DATABASE OPEN READ ONLY; ALTER DATABASE OPEN READ ONLY ...
- perl打开本地/服务器图片
index.html <html> <body> <h2> perl read img </h2> <img src = "displa ...