网络爬虫第一步:通用代码框架(python版)
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
if __name__=="__main__":
url="www.baidu.com"
print(getHTMLText(url))
运行的结果:
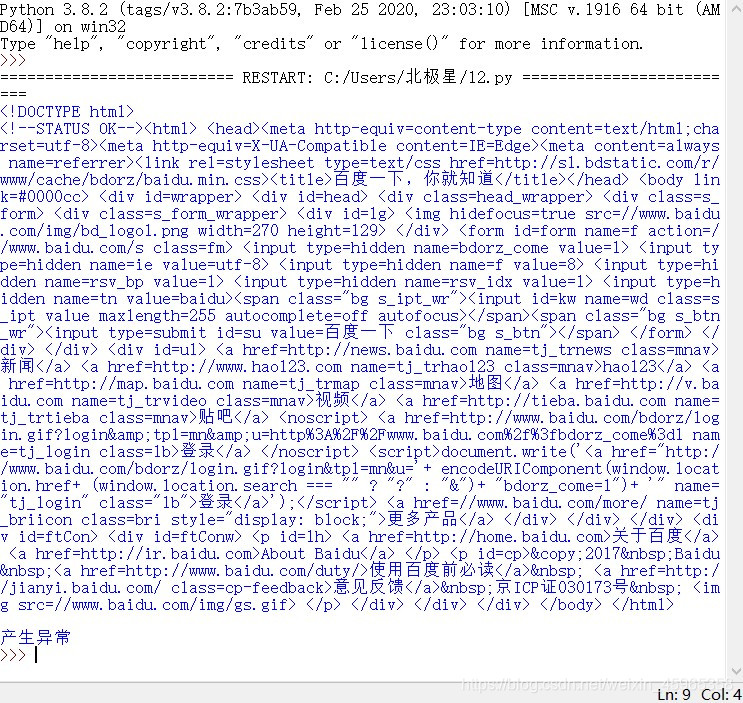
网络爬虫第一步:通用代码框架(python版)的更多相关文章
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- python网络爬虫(2)——scrapy框架的基础使用
这里写一下爬虫大概的步骤,主要是自己巩固一下知识,顺便复习一下. 一,网络爬虫的步骤 1,创建一个工程 scrapy startproject 工程名称 创建好工程后,目录结构大概如下: 其中: sc ...
- 03.Python网络爬虫第一弹《Python网络爬虫相关基础概念》
爬虫介绍 引入 之前在授课过程中,好多同学都问过我这样的一个问题:为什么要学习爬虫,学习爬虫能够为我们以后的发展带来那些好处?其实学习爬虫的原因和为我们以后发展带来的好处都是显而易见的,无论是从实际的 ...
- Python网络爬虫第一弹《Python网络爬虫相关基础概念》
爬虫介绍 引入 之前在授课过程中,好多同学都问过我这样的一个问题:为什么要学习爬虫,学习爬虫能够为我们以后的发展带来那些好处?其实学习爬虫的原因和为我们以后发展带来的好处都是显而易见的,无论是从实际的 ...
- 03,Python网络爬虫第一弹《Python网络爬虫相关基础概念》
爬虫介绍 引入 为什么要学习爬虫,学习爬虫能够为我们以后的发展带来那些好处?其实学习爬虫的原因和为我们以后发展带来的好处都是显而易见的,无论是从实际的应用还是从就业上. 我们都知道,当前我们所处的时代 ...
- Python爬虫第一步
这只是记录一下自己学习爬虫的过程,可能少了些章法.我使用过的是Python3.x版本,IDE为Pycharm. 这里贴出代码集合,这一份代码也是以防自己以后忘记了什么,方便查阅. import req ...
- 机器学习工作流程第一步:如何用Python做数据准备?
这篇的内容是一系列针对在Python中从零开始运用机器学习能力工作流的辅导第一部分,覆盖了从小组开始的算法编程和其他相关工具.最终会成为一套手工制成的机器语言工作包.这次的内容会首先从数据准备开始. ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 网络爬虫之网站图片爬取-python实现
版本1.5 本次简单添加了四路多线程(由于我电脑CPU是四核的),速度飙升.本想试试xPath,但发现反倒是多此一举,故暂不使用 #-*- coding:utf-8 -*- import re,url ...
随机推荐
- 性能测试基础——(MEN)
关于内存在一块其实我并不是很想拿出来说,一般情况下内存这一块都是可优化的,可以通过硬件资源或者调整一些系统或者应用系统的参数配置来进行优化. 很多同僚问到了"内存泄漏"和" ...
- 【老孟Flutter】41个酷炫的 Loading 组件库
老孟导读:目前 loading 库中包含41个动画组件,还会继续添加,同时也欢迎大家提交自己的 loading 动画组件或者直接微信发给我也可以. Github 地址:https://github.c ...
- 从 0 开始的min_max容斥证明
二项式反演 \[f_n=\sum\limits_{i=0}^nC^i_ng_i \Leftrightarrow g_n=\sum\limits_{i=0}^n{(-1)}^{n-i}f_i \] 证明 ...
- Acwing 403. 平面
以一个这个环为基准,剩下的边可以放在圈外,也可以放在圈内,两种状态. 如果两条线段出现了环上意义的交叉即冲突,即不能同时放在圈外/内. 这是典型的 2-SAT 问题,因为关系传递是无向的,即逆命题与原 ...
- Java-web-多个独立项目之间相互调用实践
本篇文章只涉及到应用层面,没有涉及到什么底层原理之类的,我目前的实力还没有达到那个级别.如果是大神级别的人看到这篇文章,请跳过. 项目框架也已经是搭建好了的,springboot版本为1.5,数据库操 ...
- 通过git-bash 批量管理VMware虚拟机
#先将vmrun .exe 加入环境变量 # 我这里是: ;C:\Program Files (x86)\VMware\VMware VIX; #cd E:/期中架构/#sh new\ 3.bash ...
- web前端常用js插件
第一款:截图插件html2Canvas.js html2是一款强大的截图插件,只需引入js文件,依照官方给定的截图方法,就能截取对应DOM区域的内容.对于有些截图出现模糊偏移的问题,网上也有一堆解决方 ...
- [GXYCTF2019]禁止套娃(无参RCE)
[GXYCTF2019]禁止套娃 1.扫描目录 扫描之后发现git泄漏 使用githack读取泄漏文件 <?php include "flag.php"; echo &quo ...
- Logistic 回归-原理及应用
公号:码农充电站pro 主页:https://codeshellme.github.io 上一篇文章介绍了线性回归模型,它用于处理回归问题. 这次来介绍一下 Logistic 回归,中文音译为逻辑回归 ...
- Git的使用以及命令
个人常用命令 git初始化操作 git init 把当前的目录变成git仓库,生成隐藏.git文件. git remote add origin url 把本地仓库的内容推送到GitHub仓库. gi ...