Celery:小试牛刀
Celery是如何工作的?
Celery 由于 其分布式体系结构,在某种程度上可能难以理解。下图是典型Django-Celery设置的高级示意图(FROM O'REILLY):
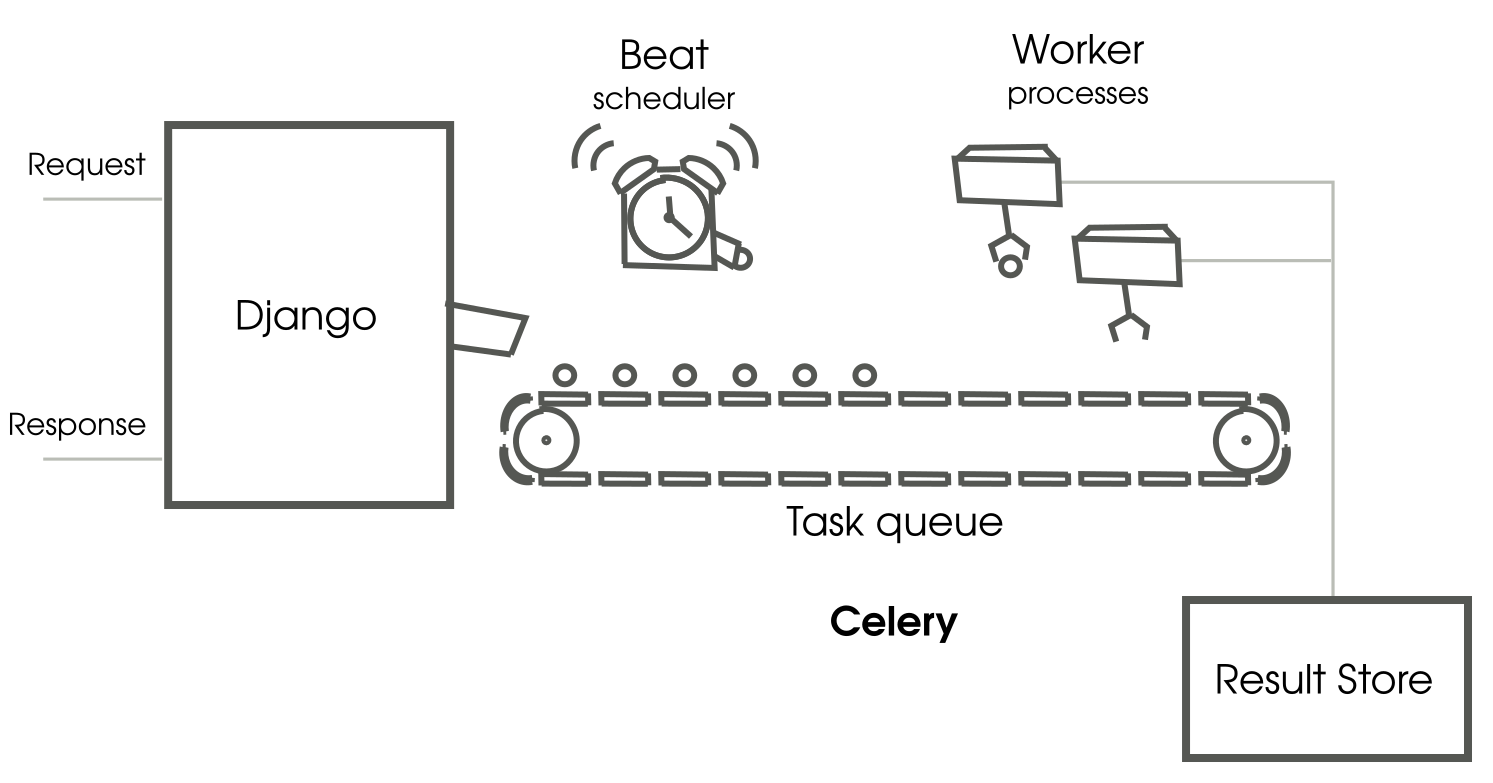
当请求到达时,您可以在处理它时调用Celery任务。调用任务的函数会立即返回,而不会阻塞当前进程。实际上,任务尚未完成执行,但是任务消息已进入任务队列(或许多可能的任务队列之一)。
workers 是独立的进程,用于监视任务队列中是否有新任务并实际执行它们,他们拿起任务消息、处理任务、存储结果。
一、安装一个broker
Celery需要一个发送和接收消息的解决方案,即一个消息代理(message broker)服务,常用的broker包括:

RabbitMQ功能齐全,稳定,耐用且易于安装,是生产环境的绝佳选择。
Ubuntu安装:
$ sudo apt-get install rabbitmq-server
Docker安装:
$ docker run -d -p 5672:5672 rabbitmq
关于RabbitMQ在Celery中的高级配置,见:使用RabbitMQ
其他系统安装RabbitMQ,见:下载并安装RabbitMQ

Redis
Redis也具有完整的功能,但是在突然终止或电源故障的情况下更容易丢失数据。
Ubuntu安装:
$ sudo apt install redis-server
Docker安装:
$ docker run -d -p 6379:6379 redis
关于Redis在Celery中的高级配置:使用Redis
关于Redis的安装:ubuntu 18.04安装Redis
二、安装Celery
$ pip install celery
三、编写Celery任务代码
首先导入Celery,创建一个Celery对象,这个对象将作为一个操作 Celery 的入口,如创建任务,管理workers等。
以下示例会把所有东西都写在一个模块中,但是对于大型项目,您需要创建一个专用模块。
# tasks.py
import time
from celery import Celery
app = Celery('tasks', ,broker='pyamqp://guest@localhost//')
@app.task
def add(x, y):
print('--------start---------')
for i in range(5):
print(f'第{i}秒')
print('--------over----------')
return x + y
第一个参数是当前模块的名称,这是唯一的必需参数。
第二个参数指定要使用的消息代理的URL。这里使用RabbitMQ(也是默认选项)。
若使用Redis:
app = Celery('tasks', broker='redis://localhost:6379/0')
四、启动 worker 进程
$ celery -A tasks worker --loglevel=INFO
在生产环境中,需要在后台将工作程序作为守护程序运行。为此,需要使用 平台提供的工具 或 类似supervisord的工具
五、调用任务
调用任务需要导入带有celery示例的模块,这里没有重新创建一个模块导入,而是使用命令行模式。要调用我们定义的任务,可以使用delay()(详情参阅 调用任务):
>>> from tasks import add
>>> add.delay(4, 4)
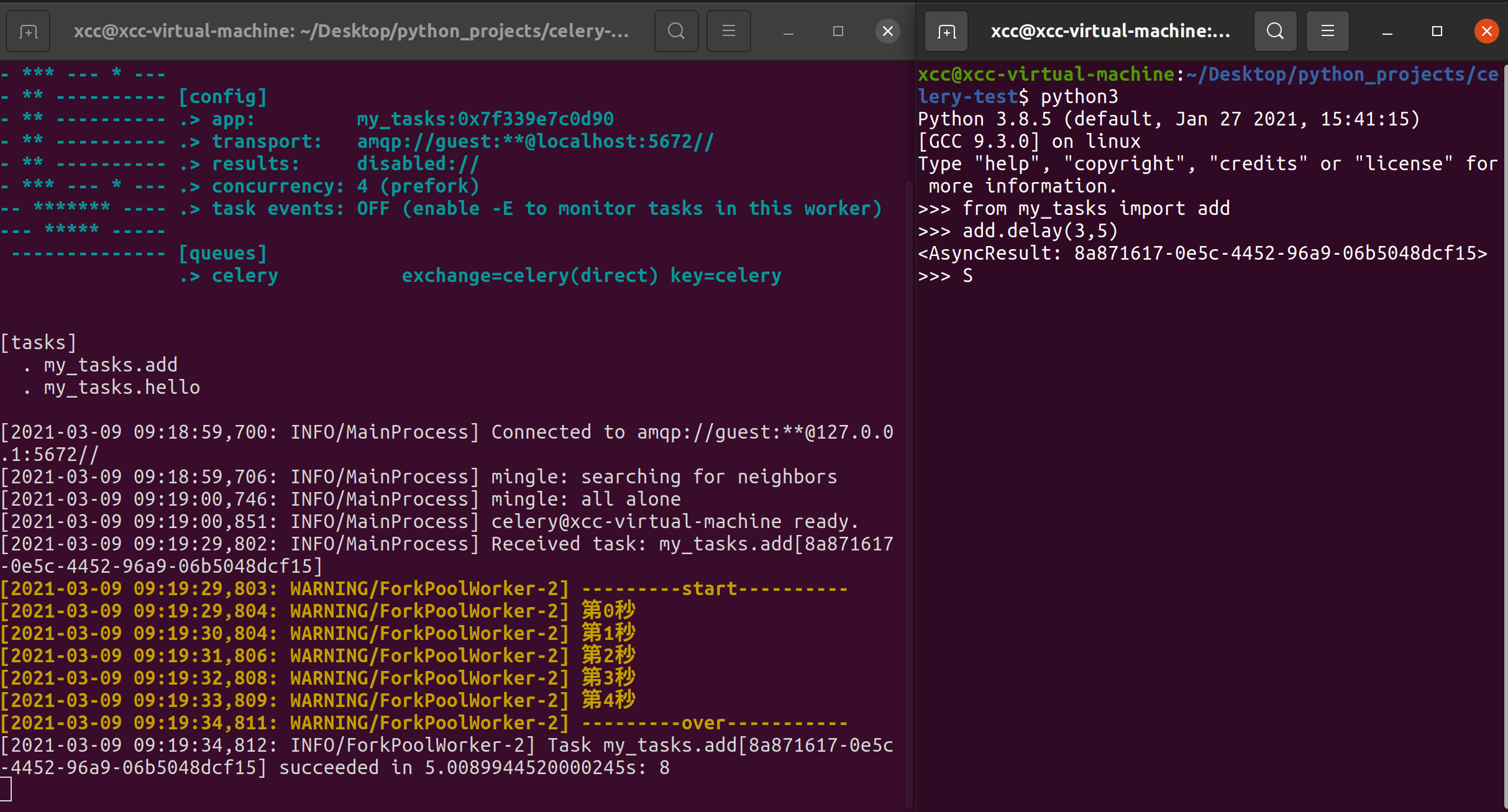
调用任务将返回一个AsyncResult实例,这可用于检查任务的状态,等待任务完成或获取其返回值(或者如果任务失败,则获取异常和回溯)
默认情况下执行任务不返回结果。为了执行远程过程调用或跟踪数据库中的任务结果,需要配置result backend。
六、获取运行结果
如果要跟踪任务的状态,Celery需要将状态存储或发送到某个地方。有多个result backend可供选择:SQLAlchemy / Django ORM, MongoDB,Memcached,Redis,RPC(RabbitMQ / AMQP)等。
下面使用 RPC 作为result backend,该后端将状态作为瞬态消息发送回去。使用backend参数配置Celery对象的result backend:
app = Celery('tasks', backend='rpc://', broker='pyamqp://')
或者,如果使用 Redis 作为result backend,但仍然使用 RabbitMQ 作为 broker(流行的组合):
app = Celery('tasks', backend='redis://localhost', broker='pyamqp://')
更多
result backend配置参阅“result backend。
我们再次调用该任务:
>>> result = add.delay(4, 4)
>>> result.ready() # 检查是否完成任务,返回布尔值
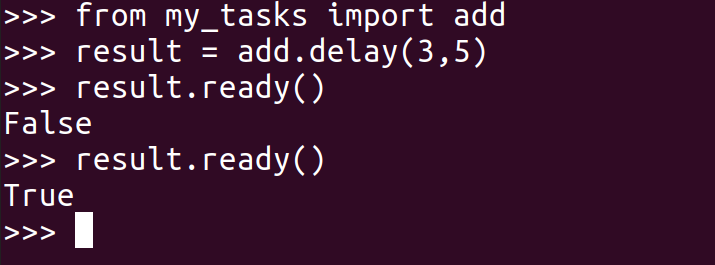
详情见有关
celery.result对象的完整参考
七、配置Celery
对于大多数使用情况,默认配置就够了,但是可以配置更多选项使Celery根据需要工作。详细配置见“配置和默认值”。
可以直接在应用程序上设置配置,也可以使用专用的配置模块设置配置。例如配置用于序列化任务负载的默认序列化器:
# 配置一个设置:
app.conf.task_serializer = 'json'
# 一次配置许多设置,则可以使用update
app.conf.update(
task_serializer='json',
accept_content=['json'], # Ignore other content
result_serializer='json',
timezone='Europe/Oslo',
enable_utc=True,
)
对于较大的项目,建议使用专用的配置模块。
app.config_from_object('celeryconfig')
celeryconfig.py必须可用于从当前目录或Python路径中加载
celeryconfig.py
broker_url = 'pyamqp://'
result_backend = 'rpc://'
task_serializer = 'json'
result_serializer = 'json'
accept_content = ['json']
timezone = 'Europe/Oslo'
enable_utc = True
参考
- First Steps with Celery
- How Celery works
- How To Use Celery with RabbitMQ to Queue Tasks on an Ubuntu VPS
Celery:小试牛刀的更多相关文章
- Celery 基本使用
1. 认识 Celery Celery 是一个 基于 Python 开发的分布式异步消息任务队列,可以实现任务异步处理,制定定时任务等. 异步消息队列:执行异步任务时,会返回一个任务 ID 给你,过一 ...
- 分布式框架Celery(转)
一.简介 Celery是一个异步任务的调度工具. Celery 是 Distributed Task Queue,分布式任务队列,分布式决定了可以有多个 worker 的存在,队列表示其是异步操作,即 ...
- 异步任务队列Celery在Django中的使用
前段时间在Django Web平台开发中,碰到一些请求执行的任务时间较长(几分钟),为了加快用户的响应时间,因此决定采用异步任务的方式在后台执行这些任务.在同事的指引下接触了Celery这个异步任务队 ...
- Xamarin+Prism小试牛刀:定制跨平台Outlook邮箱应用(后续)
在[Xamarin+Prism小试牛刀:定制跨平台Outlook邮箱应用]里面提到了Microsoft 身份认证,其实这也是一大块需要注意的地方,特作为后续补充这些知识点.上章是使用了Microsof ...
- celery使用的一些小坑和技巧(非从无到有的过程)
纯粹是记录一下自己在刚开始使用的时候遇到的一些坑,以及自己是怎样通过配合redis来解决问题的.文章分为三个部分,一是怎样跑起来,并且怎样监控相关的队列和任务:二是遇到的几个坑:三是给一些自己配合re ...
- tornado+sqlalchemy+celery,数据库连接消耗在哪里
随着公司业务的发展,网站的日活数也逐渐增多,以前只需要考虑将所需要的功能实现就行了,当日活越来越大的时候,就需要考虑对服务器的资源使用消耗情况有一个清楚的认知. 最近老是发现数据库的连接数如果 ...
- celery 框架
转自:http://www.cnblogs.com/forward-wang/p/5970806.html 生产者消费者模式 在实际的软件开发过程中,经常会碰到如下场景:某个模块负责产生数据,这些数据 ...
- celery使用方法
1.celery4.0以上不支持windows,用pip安装celery 2.启动redis-server.exe服务 3.编辑运行celery_blog2.py !/usr/bin/python c ...
- Celery的实践指南
http://www.cnblogs.com/ToDoToTry/p/5453149.html Celery的实践指南 Celery的实践指南 celery原理: celery实际上是实现了一个典 ...
随机推荐
- Vitya and Strange Lesson CodeForces - 842D 字典树+交换节点
题意: Today at the lesson Vitya learned a very interesting function - mex. Mex of a sequence of number ...
- Java 在Word中添加多行图片水印
Word中设置水印效果时,不论是文本水印或者是图片水印都只能添加单个文字或者图片到Word页面,效果比较单一,本文通过Java代码示例介绍如何在页面中添加多行图片水印效果,即水印效果以多个图片平铺到页 ...
- Python——控制鼠标键盘
一.安装包 pip install pynput 二.引用包 from pynput import mouse,keyboard 三.控制鼠标 from pynput.mouse import But ...
- java中string,stringBuffer和StringBuider
最近学习到StringBuffer,心中有好些疑问,搜索了一些关于String,StringBuffer,StringBuilder的东西,现在整理一下. 关于这三个类在字符串处理中的位置不言而喻,那 ...
- codeforces 903D
D. Almost Difference time limit per test 2 seconds memory limit per test 256 megabytes input standar ...
- C++中关于输入cin的一些总结
(1)cin 在理解cin功能时,不得不提标准输入缓冲区.当我们从键盘输入字符串的时候需要敲一下回车键才能够将这个字符串送入到缓冲区中,那么敲入的这个回车键(\r)会被转换为一个换行符\n,这个换行符 ...
- Verilog基础语法总结
去年小学期写的,push到博客上好了 Verilog 的基本声明类型 wire w1; // 线路类型 reg [-3:4] r1; // 八位寄存器 integer mem[0:2047]; // ...
- 痞子衡嵌入式:我的博文总量终于追平了jicheng0622
自打2016年10月选定清爽又复古的博客园平台作为痞子衡的个人博客主战场之后,痞子衡就一直坚持在博客园首发原创技术文章,然后再同步到其他平台(CSDN,知乎,微信公众号...),在坚持更文近四年半(2 ...
- Android vs iOS vs Web
Android vs iOS vs Web UI view Android ViewGroup ImageView TextView iOS UIView ImageView TextView Web ...
- vscode & ignore .idea
vscode & ignore .idea settings.json .vscode & ignore .idea // 将设置放入此文件中以覆盖默认设置 { "files ...