【VSA】One-shot video-based person re-identification with variance subsampling algorithm
导言
针对现有工作中存在的错误伪标签问题,文章通过优化样本间的相似性度量和伪标签置信度评估策略来改善这个问题,从而提供模型性能。具体地,文章提出了方差置信度的概念,并设计了方差二次采样算法将方差置信度和距离置信度结合起来作为采样准则,同时还提出了方差衰减策略来更好了优化选择出来的伪标签样本。最终,该方法将MARS数据集上的mAP和Rank1分别提高了 3.94%和4.55%。
引用
@article{DBLP:journals/jvca/ZhaoYYHYZ20,
author = {Jing Zhao and
Wenjing Yang and
Mingliang Yang and
Wanrong Huang and
Qiong Yang and
Hongguang Zhang},
title = {One-shot video-based person re-identification with variance subsampling
algorithm},
journal = {Comput. Animat. Virtual Worlds},
volume = {31},
number = {4-5},
year = {2020}
}
相关链接
原文链接:https://onlinelibrary.wiley.com/doi/10.1002/cav.1964
或者下方↓公众号后台回复“VSA”,即可获得论文电子资源。

解决了什么问题
Previous works propose the distance-based sampling for unlabeled datapoints to address the few-shot person re-identification task, however, many selected samples may be assigned with wrong labels due to poor feature quality in these works, which negatively affects the learning procedure.
主要贡献和创新点
- We propose the variance confidence to measure the credibility of pseudo-labels, which can be widely used as a general similarity measurement.
- We propose a novel VSA(variance subsampling algorithm) to improve the accuracy of pseudo-labels for selected samples. It combines distance confidence and variance confidence as the sampling criterion, and adopt a variance decay strategy as the sampling strategy.
创新点主要有三个:
- 一是提出了方差置信度(variance confidence)的概念
- 二是提出了VSA(方差二次采样算法)
- 三是提出了方差衰减策略(variance decay strategy)。
基本框架
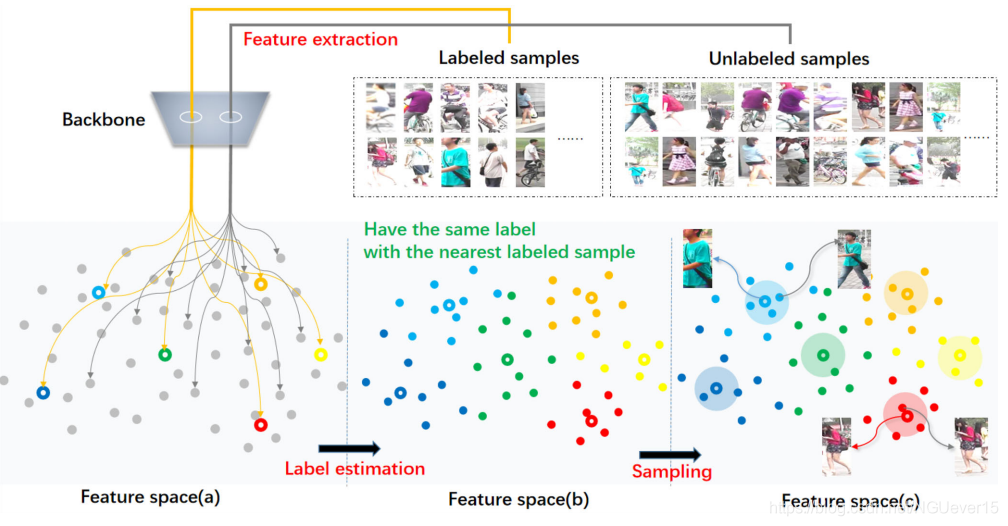
The dataset extension process. Both labeled and unlabeled samples are extracted into the feature space through the backbone network in step 1. As shown in feature space (a), the gray points indicate unlabeled samples, and the colored hollow points indicate labeled samples. Different colors indicate different person identity. Then label estimation is performed according to the criterion that the unlabeled sample has the same label as the nearest labeled sample in step 2. We call the sample after label estimation a pseudo-label sample, which is the colored solid point in the feature space (b). Finally, the pseudo-label samples with higher confidence are preferred, which are closer to the labeled samples in feature space (c)
整体框架采用监督训练和数据扩展交叉迭代进行的模式。数据扩展的过程如上图所示,具体包括了特征提取、标签估计和伪标签样本采样三个环节。
提出的方法
01 variance confidence方差置信度
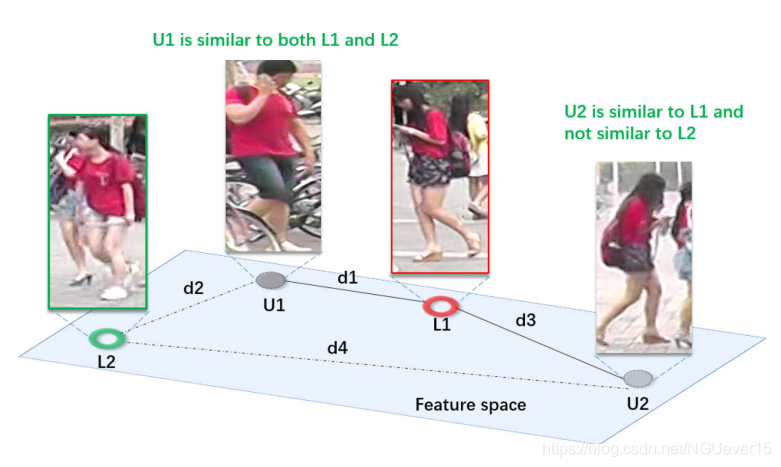
A distribution situation in the feature space. U1 and U2 represent two unlabeled samples, and L1 and L2 are the two labeled samples with the closest distance to both U1 and U2 in the feature space. di,i∈[1,4], represent the Euclidean distance between samples and satisfy Equation (7). The solid line represents the distance between the unlabeled sample and its nearest labeled sample. While U1 is similar to L1, it is also similar to L2 with the same extent. On the contrary, although U2 is slightly similar to L1, it is very different from L2. Therefore, it is more believable that U2 is more likely than U1 to fall into the same category as L1
作者举例了特征空间中的一种分布情况。 U1和U2是无标注样本,L1和L2是距离U1和U2最近的带标注样本。di表示样本之间的欧几里得距离,且满足\(d_1<d_2<d_3<d_4\)。 如果仅根据距离来度量样本标签的可靠性的话,那U1优于U2(因为d1<d3)。 但作者认为,当一个样本(U1)同时和两个不同的样本(L1和L2)相似的时候(d1和d2相差很小),那这个样本就谁都不像了。
作者用无标签样本与其距离最近的两个带标注样本的距离方差来表示方差置信度,且方差越大,置信度越高。
02 Variance Subsampling Algorithm 方差二次采样算法
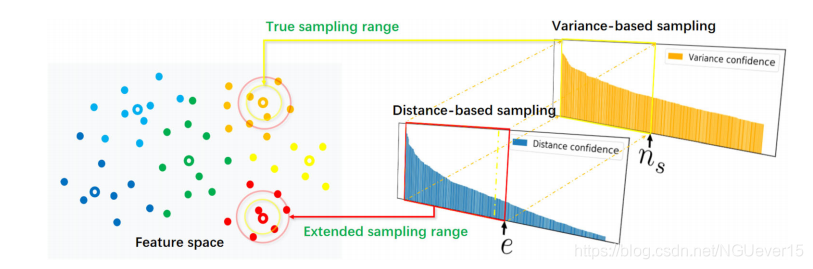
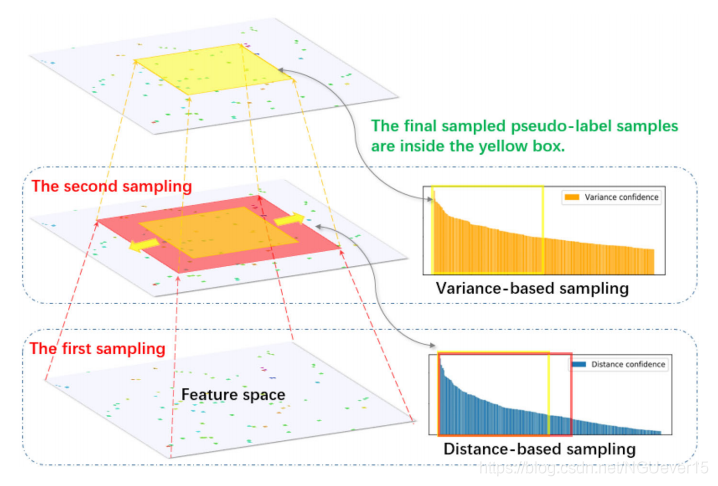
The sampling criterion of variance subsampling algorithm. Hollow points in the feature space represent labeled samples, and solid points represent pseudo-label samples. The first sampling is based on the distance confidence. The number of sampling is extended to e, corresponding to the range of the red squares and circles in the figure. The second sampling is based on the variance confidence, and the number of samples is restored to ns, which corresponds to the range of the yellow box and the circle in the figure.
作者通过二次采样的形式,将距离置信度和方差置信度结合了起来,作为采样准则。
03 Variance decay strategy 方差衰减策略
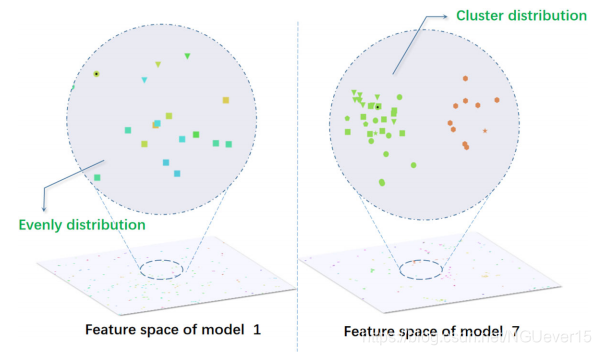
The partial distribution of the real feature space. Colors is used to distinguish different people identity, and shapes is used to distinguish the camera. Black dots in the center of the sample indicate that this is the original labeled sample. The distribution in the first iteration is relatively uniform, while the distribution after the seventh iteration has shown a clustering distribution。
作者在实验过程中可视化了特征空间的真实分布情况。 发现模型训练到中后期时,提取出的特征空间已经呈现出了聚类分布。
Obviously, in the case of the feature distribution of model 7 in Figure 5, the situation described in Figure 3 will hardly occur. This shows that the situation described in Figure 3 is gradually reduced during the iteration process. Therefore, a variance decay strategy is proposed as the sampling strategy. A stopping factor
【VSA】One-shot video-based person re-identification with variance subsampling algorithm的更多相关文章
- 【Egret】里使用video标签
egret里使用Html5的Video标签 egret里使用Html5的Video标签的demo: 链接:http://pan.baidu.com/s/1nuNyqRR 密码:x58i //----- ...
- 【转】视频H5 video最佳实践
原文地址:https://github.com/gnipbao/iblog/issues/11 随着 4G 的普遍以及 WiFi 的广泛使用,手机上的网速已经足够稳定和高速,以视频为主的 HTML5 ...
- 【转】如何修改 video 样式
我们这里说的“修改 video 样式”并不是要自己实现一套 controls,而是尝试修改 video 的默认样式 隐藏全屏按钮 这个很容易查到 video::-webkit-media-contro ...
- 【HTML5】HTML5中video元素事件详解(实时监测当前播放时间)
html 代码..video后边几个元素,可处理ios 系统的兼容性 <video id="myVideo" controls="controls" po ...
- 【转载】HTML5 Audio/Video 标签,属性,方法,事件汇总
<audio> 标签属性: src:音乐的URL preload:预加载 autoplay:自动播放 loop:循环播放 controls:浏览器自带的控制条 Html代码 <au ...
- 【转】Android HTML5 Video视频标签自动播放与自动全屏问题解决
为了解决 HTML5Video视频标签自动播放与全屏问题,在网上找了很多相关资料,网上也很多关于此问题解决方法,但几乎都不能解决问题,特别对各大视频网站传回来的html5网页视频自动播放与全屏问题,我 ...
- 【sqli-labs】 less53 GET -Blind based -Order By Clause -String -Stacked injection(GET型基于盲注的字符型Order By从句堆叠注入)
http://192.168.136.128/sqli-labs-master/Less-53/?sort=1';insert into users(id,username,password) val ...
- 【sqli-labs】 less52 GET -Blind based -Order By Clause -numeric -Stacked injection(GET型基于盲注的整型Order By从句堆叠注入)
出错被关闭了 http://192.168.136.128/sqli-labs-master/Less-52/?sort=1' http://192.168.136.128/sqli-labs-mas ...
- 【sqli-labs】 less51 GET -Error based -Order By Clause -String -Stacked injection(GET型基于错误的字符型Order By从句堆叠注入)
less50的字符型版本,闭合好引号就行 http://192.168.136.128/sqli-labs-master/Less-51/?sort=1';insert into users(id,u ...
随机推荐
- [Luogu P3338] [ZJOI2014]力 (数论 FFT 卷积)
题面 传送门: 洛咕 BZOJ Solution 写到脑壳疼,我好菜啊 我们来颓柿子吧 \(F_j=\sum_{i<j}\frac{q_i*q_j}{(i-j)^2}-\sum_{i>j} ...
- solr 文档一
[在此处输入文章标题] 参考博客: http://blog.csdn.net/matthewei6/article/details/50620600 基础环境搭建 solr版本5.5.5: 一.sol ...
- 懒得写文档,swagger文档导出来不香吗
导航 前言 离线文档 1 保存为html 2 导出成pdf文档 3 导出成Word文档 参考 前言 早前笔者曾经写过一篇文章<研发团队,请管好你的API文档>.团队协作中,开发文档的重 ...
- Java每日一考202011.4
1.JDK,JRE,JVM三者之间的关系 JDK包含JRE,JRE包含JVM JDK=JRE+JAVA的开发工具 JRE=JVM+JAVA核心类库 2.为什么要配置环境变量? 希望在任何路径下都能执行 ...
- Spider_基础总结4_bs.find_all()与正则及lambda表达式
# beautifulsoup的 find()及find_all()方法,也会经常和正则表达式以及 Lambda表达式结合在一起使用: # 1-bs.find_all()与正则表达式的应用: # 语法 ...
- Linux下如何创建loop device
在Linux中,有一种特殊的块设备叫loop device,这种loop device设备是通过映射操作系统上的正常的文件而形成的虚拟块设备 因为这种设备的存在,就为我们提供了一种创建一个存在于其他文 ...
- WPF控件库总结
前言 在使用WPF项目的时候, 一般首要的就是对UI部分的选型, 而WPF相关的UI控件和样式库在Githu也是非常多. 关于UI的部分,可以分为二种: 对控件本身没有很大的需求, 只需要在原有的基础 ...
- 基于RBAC实现权限管理
基于RBAC实现权限管理 技术栈:SpringBoot.SpringMVC RBAC RBAC数据库表 主体 编号 账号 密码 001 admin 123456 资源 编号 资源名称 访问路径 001 ...
- RTSP服务端开发概述
一 概述 RTSP(Real Time Streaming Protocol),RFC2326,实时音视频流传输协议,是TCP/IP协议体系中的一个应用层协议.该协议定义了一对多应用程序如何有效地通过 ...
- MySQL数据库 | MySQL调优|MySQL底层原理|MySQL零基础新手教程
MySQL数据库安装 一.Windows 环境下安装 A.下载 MySQL Select Operating System: Microsoft Windows 快捷下载:mysql-8.0.22-w ...