mysql一张表到底能存多少数据?
前言
程序员平时和mysql打交道一定不少,可以说每天都有接触到,但是mysql一张表到底能存多少数据呢?计算根据是什么呢?接下来咱们逐一探讨
知识准备
数据页
在操作系统中,我们知道为了跟磁盘交互,内存也是分页的,一页大小4KB。同样的在MySQL中为了提高吞吐率,数据也是分页的,不过MySQL的数据页大小是16KB。(确切的说是InnoDB数据页大小16KB)。详细学习可以参考官网
我们可以用如下命令查询到。
mysql> SHOW GLOBAL STATUS LIKE 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.00 sec)
今天咱们数据页的具体结构指针等不深究,知道它默认是16kb就行了,也就是说一个节点的数据大小是16kb
索引结构(innodb)
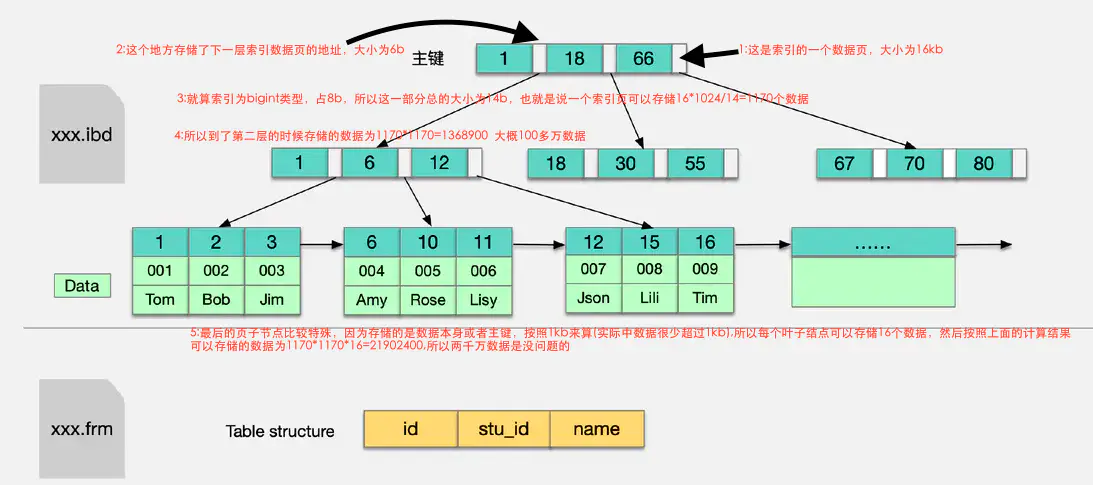
mysql的索引结构咱们应该都知道,是如下的b+树结构

通常b+树非叶子节点不存储数据,只有叶子节点(最下面一层)才存储数据,那么咱们说回节点,一个节点指的是(对于上图而言)

每个红框选中的部分称为一个节点,而不是说某个元素。
了解了节点的概念和每个节点的大小为16kb之后,咱们计算mysql能存储多少数据就容易很多了
具体计算方法
根节点计算
首先咱们只看根节点
比如我们设置的数据类型是bigint,大小为8b
在数据本身如今还有一小块空间,用来存储下一层索引数据页的地址,大小为6kb

所以我们是可以计算出来一个数据为(8b+6b=14b)的空间(以bigint为例)
我们刚刚说到一个数据页的大小是16kb,也就是(161024)b,那么根节点是可以存储(161024/(8+6))个数据的,结果大概是1170个数据
如果跟节点的计算方法计算出来了,那么接下来的就容易了。
其余层节点计算
第二层其实比较容易,因为每个节点数据结构和跟节点一样,而且在跟节点每个元素都会延伸出来一个节点,所以第二层的数据量是1170*1170=1368900,问题在于第三层,因为innodb的叶子节点,是直接包含整条mysql数据的,如果字段非常多的话数据所占空间是不小的,我们这里以1kb计算,所以在第三层,每个节点为16kb,那么每个节点是可以放16个数据的,所以最终mysql可以存储的总数据为
1170 * 1170 * 16 = 21902400 (千万级条)
其实计算结果与我们平时的工作经验也是相符的,一般mysql一张表的数据超过了千万也是得进行分表操作了。
总结
最后用一张图片总结一下今天讨论的内容,希望您能喜欢
mysql一张表到底能存多少数据?的更多相关文章
- [MyBatis]再次向MySql一张表插入一千万条数据 批量插入 用时5m24s
本例代码下载:https://files.cnblogs.com/files/xiandedanteng/InsertMillionComparison20191012.rar 环境依然和原来一样. ...
- mysql三张表关联查询
三张表,需要得到的数据是标红色部分的.sql如下: select a.uid,a.uname,a.upsw,a.urealname,a.utel,a.uremark, b.rid,b.rname,b. ...
- Mysql两张表的关联字段不一致
工作中遇到了一个问题,邮件系统群发失败,后来经过排查查找到了原因 原来是因为mysql中的两张表的关联字段竟然不一致, 表A mysql> desc rm_user_router;+------ ...
- 将MySQL一张表的数据迁移到MongoDB数据库的Java代码示例
Java代码: package com.zifeiy.snowflake.handle.etl.mongodb; import java.sql.Connection; import java.sql ...
- MySQL之三张表关联
创建三张表 1.学生表 mysql> create table students( sid int primary key auto_increment, sname ) not null, a ...
- 将mysql中的一张表中的一个字段数据根据条件导入另一张表中
添加字段:alter table matInformation add facid varchar(99) default ''; 导入数据:update matInformation m set ...
- MySQL 两张表关联更新(用一个表的数据更新另一个表的数据)
有两张表,info1, info2 . info1: info2: 现在,要用info2中的数据更新info1中对应的学生信息,sql语句如下: UPDATE info1 t1 JOIN info2 ...
- mysql获取某个表的所有属性名及其数据
MYSQL类实现从数据库相应的表中获取所有属性及其数据,数据为元组类型.返回结果存放在字典中 import pymysql class MYSQL: def __init__(self): pass ...
- 查询同一张表符合条件的某些数据的id拼接成一个字段返回
同一张表存在类似多级菜单的上下级关系的数据,查询出符合条件的某些数据的id拼接成一个字段返回: SELECT CONCAT(a.pid, ',', b.subid) AS studentIDS FRO ...
随机推荐
- (八)整合 Dubbo框架 ,实现RPC服务远程调用
整合 Dubbo框架 ,实现RPC服务远程调用 1.Dubbo框架简介 1.1 框架依赖 1.2 核心角色说明 2.SpringBoot整合Dubbo 2.1 核心依赖 2.2 项目结构说明 2.3 ...
- Grafana+Prometheus通过node_exporter监控Linux服务器信息
Grafana+Prometheus通过node_exporter监控Linux服务器信息 一.Grafana+Prometheus通过node_exporter监控Linux服务器信息 1.1nod ...
- HttpClient之基本使用
1.HttpClient简介 http协议可以说是现在Internet上面最重要,使用最多的协议之一了,越来越多的java应用需要使用http协议来访问网络资源,特别是现在rest api的流行,Ht ...
- Apache Cocoon XML注入 [CVE-2020-11991]
受影响版本: Apache Cocoon <= 2.1.x 程序使用了StreamGenerator这个方法时,解析从外部请求的xml数据包未做相关的限制,恶意用户就可以构造任意的xml表达式, ...
- 闲聊CAP、BASE与XA
CAP理论与BASE理论 首先要和大家说的就是大名鼎鼎的CAP理论与BASE理论了,这两个理论与解决分布式事务问题是密切相关的. 其实网上有很多关于CAP与BASE相关的文章,一写就写了一大堆,篇幅很 ...
- mysql创建和使用数据库
mysql连接和断开 mysql -h host -u user -p******** /*建议不要在命令行中输入密码,因为这样做会使其暴露给在您的计算机上登录的其他用户窥探*/ mysql -u u ...
- Codeforces Round #589 (Div. 2) D. Complete Tripartite(模拟)
题意:给你n个点 和 m条边 问是否可以分成三个集合 使得任意两个集合之间的任意两个点都有边 思路:对于其中一个集合v1 我们考虑其中的点1 假设点u和1无边 那么我们可以得到 u一定和点1在一个集合 ...
- Codeforces Round #696 (Div. 2) C. Array Destruction (贪心,multiset)
题意:有\(n\)个数,首先任选一个正整数\(x\),然后在数组中找到两个和为\(x\)的数,然后去掉这两个数,\(x\)更新为两个数中较大的那个.问你最后时候能把所有数都去掉,如果能,输出最初的\( ...
- 【noi 2.6_7627】鸡蛋的硬度(DP)
题意:其中n表示楼的高度,m表示你现在拥有的鸡蛋个数. 解法:f[i][j]表示 i 层楼有 j 个鸡蛋时,至少要扔多少次.3重循环,k为测试的楼层,分这时扔下去的鸡蛋碎和不碎的情况.要注意初始化. ...
- hdu5247 找连续数
Problem Description 小度熊拿到了一个无序的数组,对于这个数组,小度熊想知道是否能找到一个k 的区间,里面的 k 个数字排完序后是连续的. 现在小度熊增加题目难度,他不想知道是否有这 ...