大白话详解大数据HBase核心知识点,老刘真的很用心(2)

前言:老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解!
01 HBase知识点
第6点:HRegionServer架构
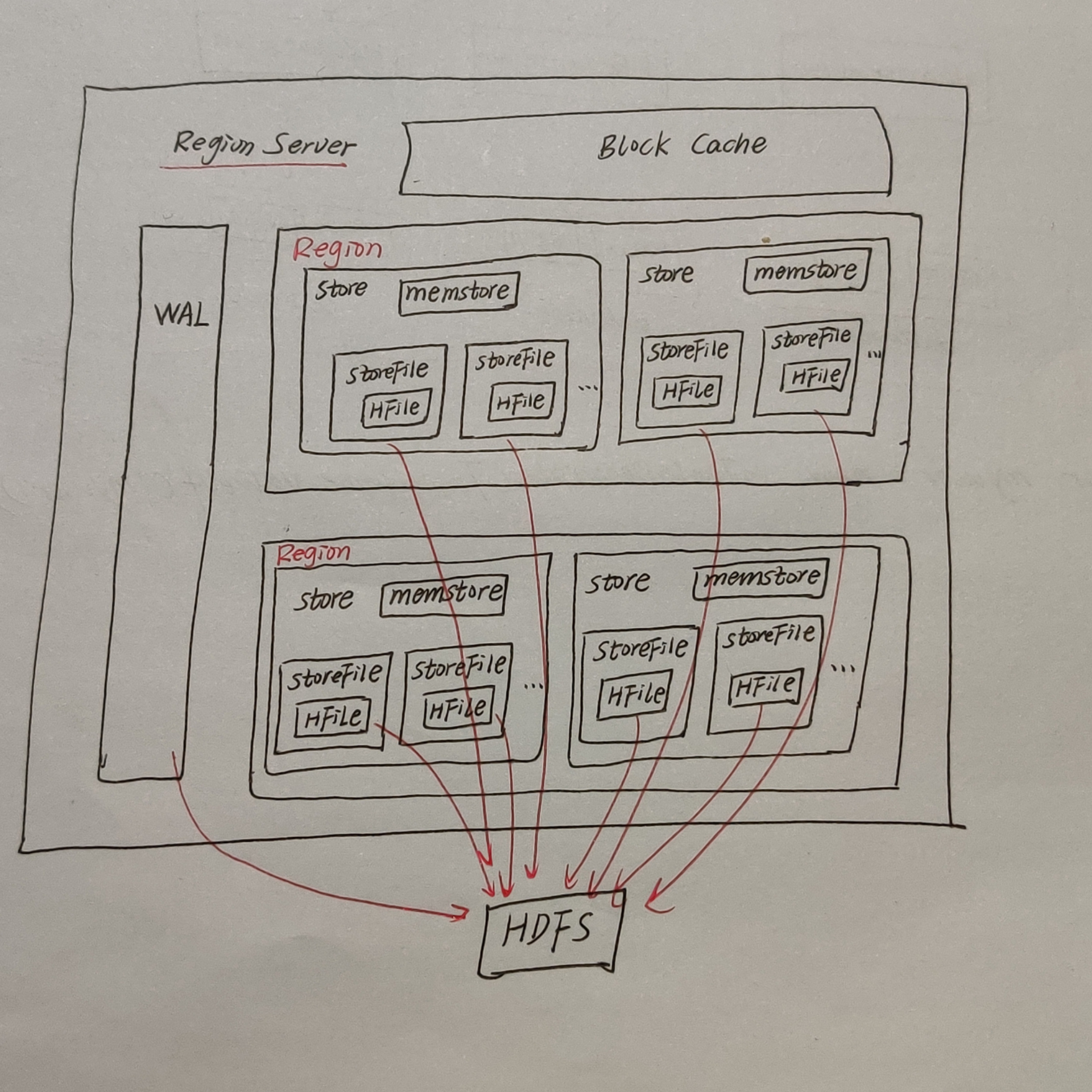
为什么要了解HRegionServer的架构呢?因为HBase集群中数据的存储和HRegionServer有着非常大的关系,只有搞清楚了它的架构,才能理清楚数据存储的逻辑。
那就让老刘好好介绍下HRegionServer架构。
StoreFile
在HRegionServer架构图中,StoreFile是保存实际数据的物理文件,StoreFile是以HFile的形式存储在HDFS上,每个Store会有一个或多个StoreFile,并且数据在每个StoreFile中都是有序的。为什么是有序的,会在MEMStore中介绍。
对于HFile是什么,老刘目前只能理解为它是StoreFile存在HDFS上的存储格式,也就是说StoreFile是以HFile这种形式存储在HDFS上。
MemStore
它是写缓存的意思。由于HFile是要求数据是有序的,要按照存储在HDFS上的数据需要按照rowkey排序,所以数据先存储在MemStore中,排好序后,达到阈值后才会flush到StoreFile中,每次flush生成一个新的StoreFIle。
那MemStore是如何将数据排序的呢?
很多机构的教学资料都没讲,老刘查了很多资料后,老刘只有一个相对较浅的理解,实现MemStore模型的数据结构是SkipList跳表,跳表它可以实现高效的查询、插入、删除操作。因为跳表本质上是由有序链表构成的,很多KV数据库都会使用跳表实现有序数据集合。所以呢,数据传入MemStore后,会利用跳表实现这些数据的有序。
WAL
WAL,全称是Write Ahead Log,预先写日志的意思。由于数据要经MemStore排序后才能刷写到HFile,但把数据保存在内存中会有很高的概率导致数据丢失的,所以为了解决这个问题,数据会先写在一个叫做Write Ahead Log的文件中,然后再写入MemStore中。所以当系统出现故障的时候,数据就可以通过这个日志文件重建,避免数据丢失。
BlockCache
它是读缓存的意思。每次查询出来的数据会先缓存在BlockCache中,方便下次查询数据。
第7点:HBase读数据流程
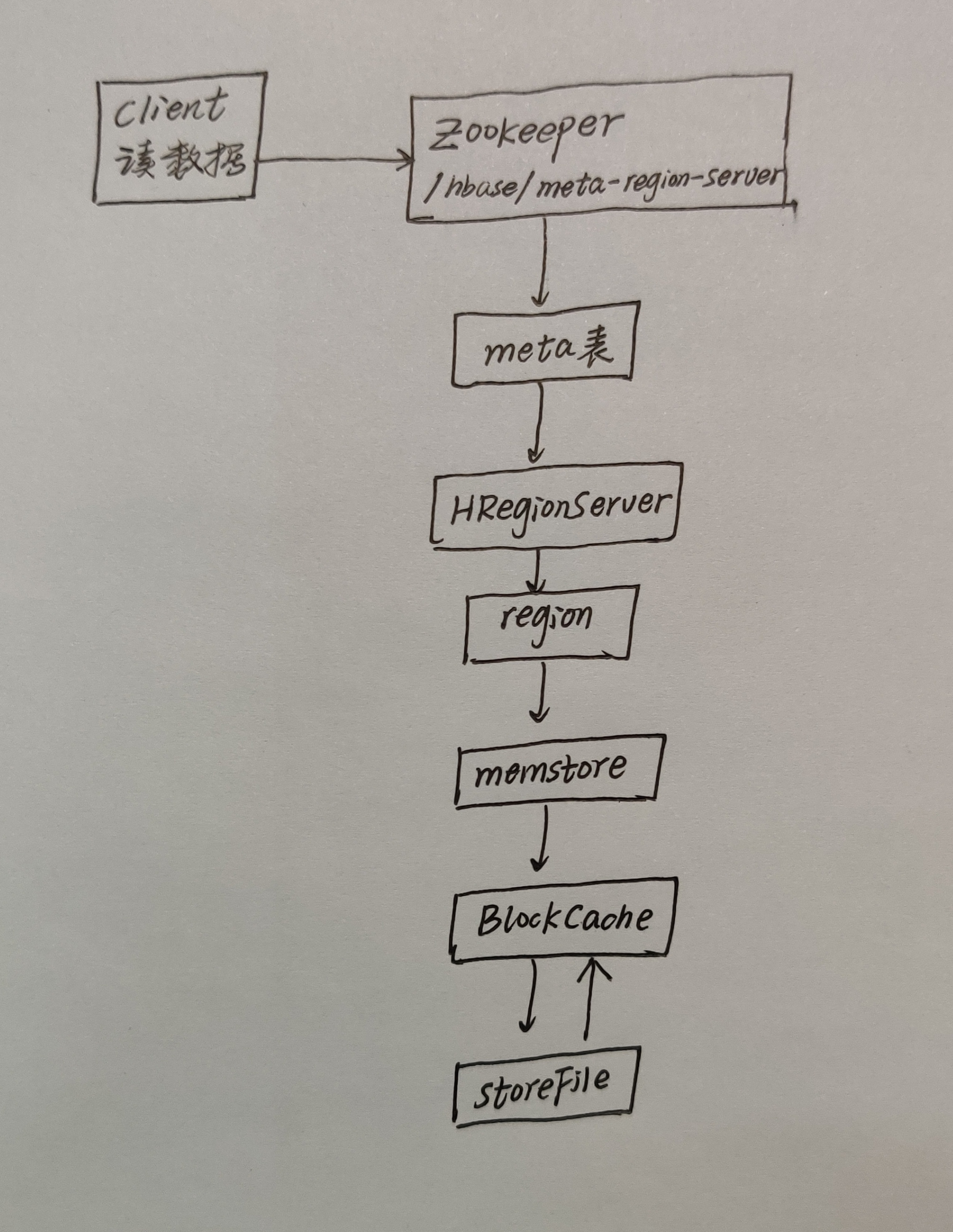
首先要说的是,在HBase中只有一张meta表(元数据表),此表只有一个region表,该region数据保存在一个HRegionServer上。
还记得HBase的第一篇文章说的ZooKeeper的作用吗,ZooKeeper里面保存了HBase的元数据meta。再想想我们要读取数据,是不是相当于去学校访问一个老师,是不是要先在校门口登记,搞清楚这个老师在学校哪个部门、哪个办公室之类的。
所以呢,HBase读数据流程如下:
1、HBase读取数据首先要与zk进行连接,从zk找到meta表的region位置,就是查找meta表存储在哪个HRegionServer,得到消息后,客户端就会立马与这个HRegionServer建立连接,然后读取meta表中的数据,这个meta表中的信息有:HBase集群有哪些表、每个表有哪些Region、都保存在哪些RegionServer上以及存储了所有用户表的Region信息。
2、我们根据要查询的namespace(命名空间,相当于关系型数据库的数据库名称)、表名和rowkey信息。找到写入数据对应的Region信息。
3、然后找到这个Region对应的RegionServer,然后发送请求。
4、现在就可以查找并定位到对应的Region了。
5、我们会先从MemStore中查找数据,如果没有,就会再从BlockCache上读取,如果BlockCache中也没有找到,那就会从最后的StoreFile中读取,从StoreFile中读取到数据之后,并不是直接把结果数据返回到客户端,而是把数据先写入到BlockCache中,目的是为了加快后续的查询;然后在返回结果给客户端。
第8点:HBase写数据流程
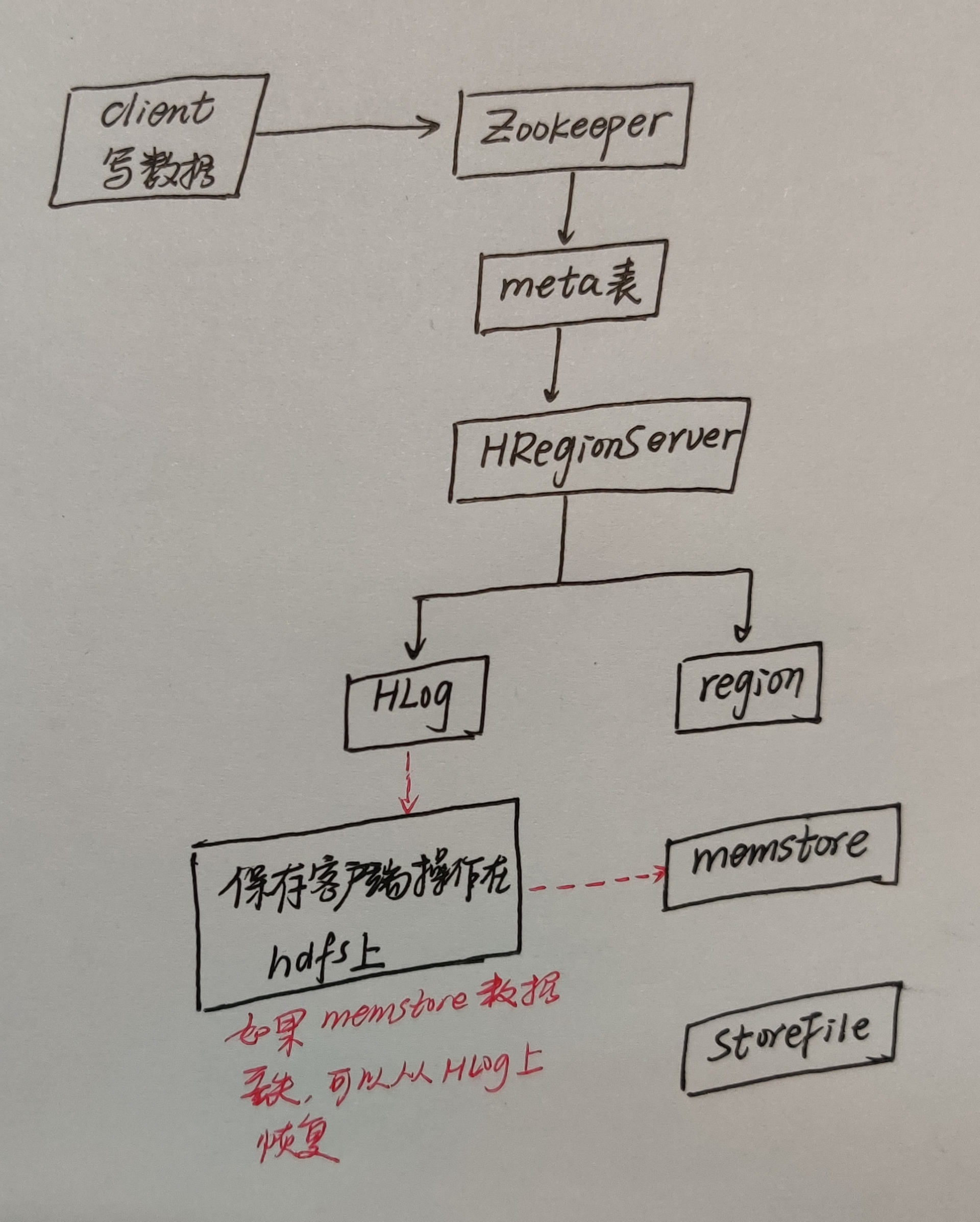
1、客户端首先会从zk找到meta表的region位置,然后读到meta表中的数据,meta表中存储了用户表的region信息。
2、根据我们根据要写入数据的namespace(命名空间,相当于关系型数据库的数据库名称)、表名和rowkey信息。找到写入数据对应的Region信息。
3、然后找到这个Region对应的RegionServer,然后发送请求。
4、现在就可以把数据顺序写入(追加)到WAL。
5、将数据写入对应的MemStore,数据会在MemStore进行排序。
6、达到MemStore的刷写时机后,将数据刷写到StoreHFile中。
但是大家好好想想,如果数据不停的写入,是不是会产生很多很多StoreFile?
在HBase集群中,针对产生的很多很多StoreFile,它会把它们合并为一个大的StoreFile(这是一个小合并),最终所有的StoreFile会进行一个大合并。但是在数据不断写入过程中,Region中的数据会越来越大,此时Region就会进行拆分(一分为二),拆分过程比较耗性能,就有了预分区。老刘大致说了下HBase中为什么会有flush和compact机制、Region拆分合并以及预分区,下面就详细讲讲这些知识点。
第9点:HBase中的flush、compact机制
Flush机制
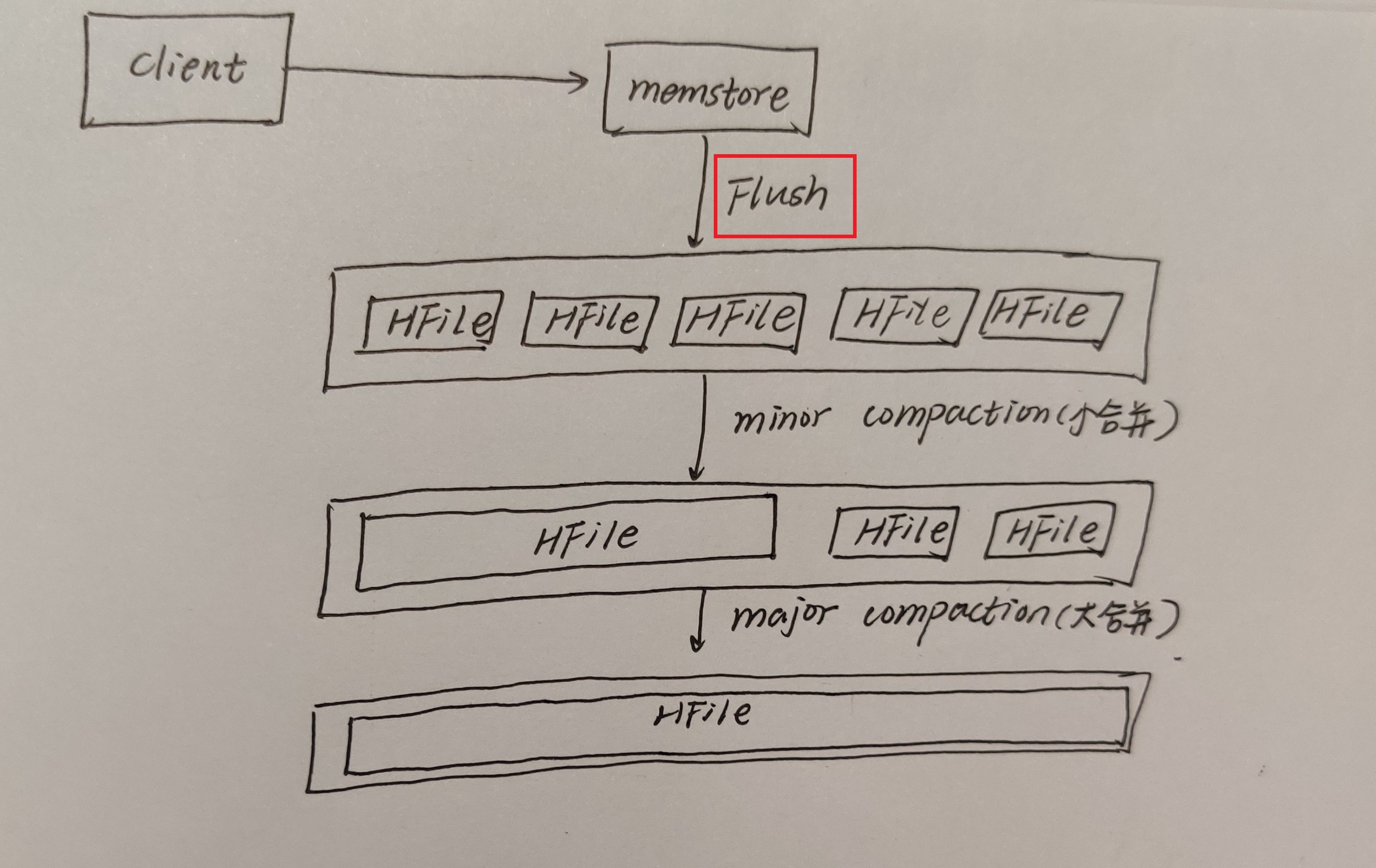
数据要刷写到磁盘,它是有很多刷写时机的,并不是想刷写就刷写的。
第一个是达到Memtore级别的限制,当Region中任意一个MemStore的大小达到了上限,默认是128M,就会触发MemStore刷新。这个上限的设置如下:
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
第二个是达到Region级别的限制,当Region中所有的MemStore的大小总和达到了上限,默认是2*128M=256M,会触发MemStore刷新。这个上限的设置如下:
<property>
<name>hbase.hregion.memstore.flush.size</name>
<value>134217728</value>
</property>
<property>
<name>hbase.hregion.memstore.block.multiplier</name>
<value>2</value>
</property>
第三个是达到RegionServer级别限制,当一个RegionServer中所有MemStore的大小总和超过低水位阈值,RegionServer开始强制Flush;先Flush MemStore最大的Region,再执行次大的,依次执行;
如果写入速度大于flush写出的速度,最后导致总MemStore大小超过高水位阈值(默认为JVM内存的40%),此时RegionServer会阻塞更新并强制执行flush,直到总MemStore大小低于低水位阈值。这些阈值的设置如下:
<property>
<name>hbase.regionserver.global.memstore.size.lower.limit</name>
<value>0.95</value>
</property>
<property>
<name>hbase.regionserver.global.memstore.size</name>
<value>0.4</value>
</property>
第四个是当WAL文件的数量超过hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下(该属性名已经废弃,现无需手动设置,最大值为32)。
第五个是定期刷新MemStore,默认周期为1小时,确保MemStroe不会长时间没有持久化。为避免所有的MemStore在同一时间都进行flush导致的问题,定期的flush操作会有20000左右的随机延时。
Compact合并机制
为什么有Compact合并机制?
hbase为了防止小文件过多,以保证查询效率,hbase需要在必要的时候将这些小的store file合并成相对较大的store file,这个过程就称之为compaction。
在hbase中主要存在两种类型的compaction合并:
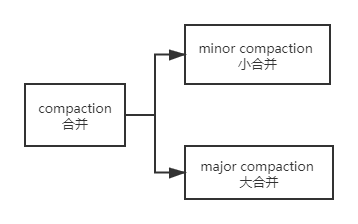
minor compaction 小合并
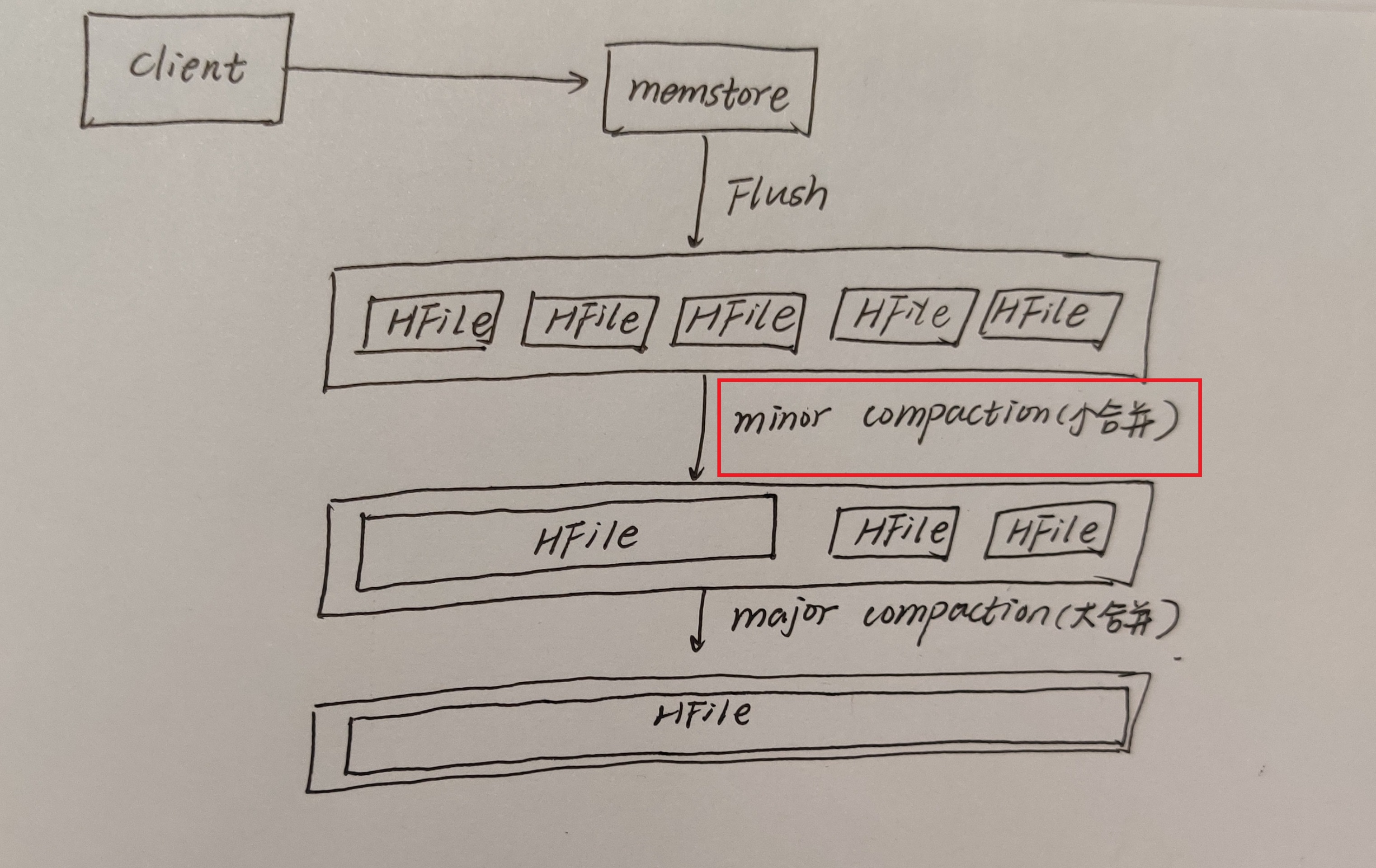
它会将Store中多个HFile合并为一个HFile。在这个过程中它会选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile。
对于超过了TTL(生存时间)的数据、更新的数据、删除的数据仅仅只是做了标记。并没有进行物理删除,进行一次Minor Compaction的结果是产生数量上更少并且内存上更大的StoreFile。这种合并的触发频率很高。
minor compaction触发条件由以下几个参数共同决定:
<!--表示至少需要三个满足条件的store file时,minor compaction才会启动-->
<property>
<name>hbase.hstore.compactionThreshold</name>
<value>3</value>
</property> <!--表示一次minor compaction中最多选取10个store file-->
<property>
<name>hbase.hstore.compaction.max</name>
<value>10</value>
</property> <!--默认值为128m,
表示文件大小小于该值的store file 一定会加入到minor compaction的store file中
-->
<property>
<name>hbase.hstore.compaction.min.size</name>
<value>134217728</value>
</property> <!--默认值为LONG.MAX_VALUE,
表示文件大小大于该值的store file 一定会被minor compaction排除-->
<property>
<name>hbase.hstore.compaction.max.size</name>
<value>9223372036854775807</value>
</property>
major compaction 大合并
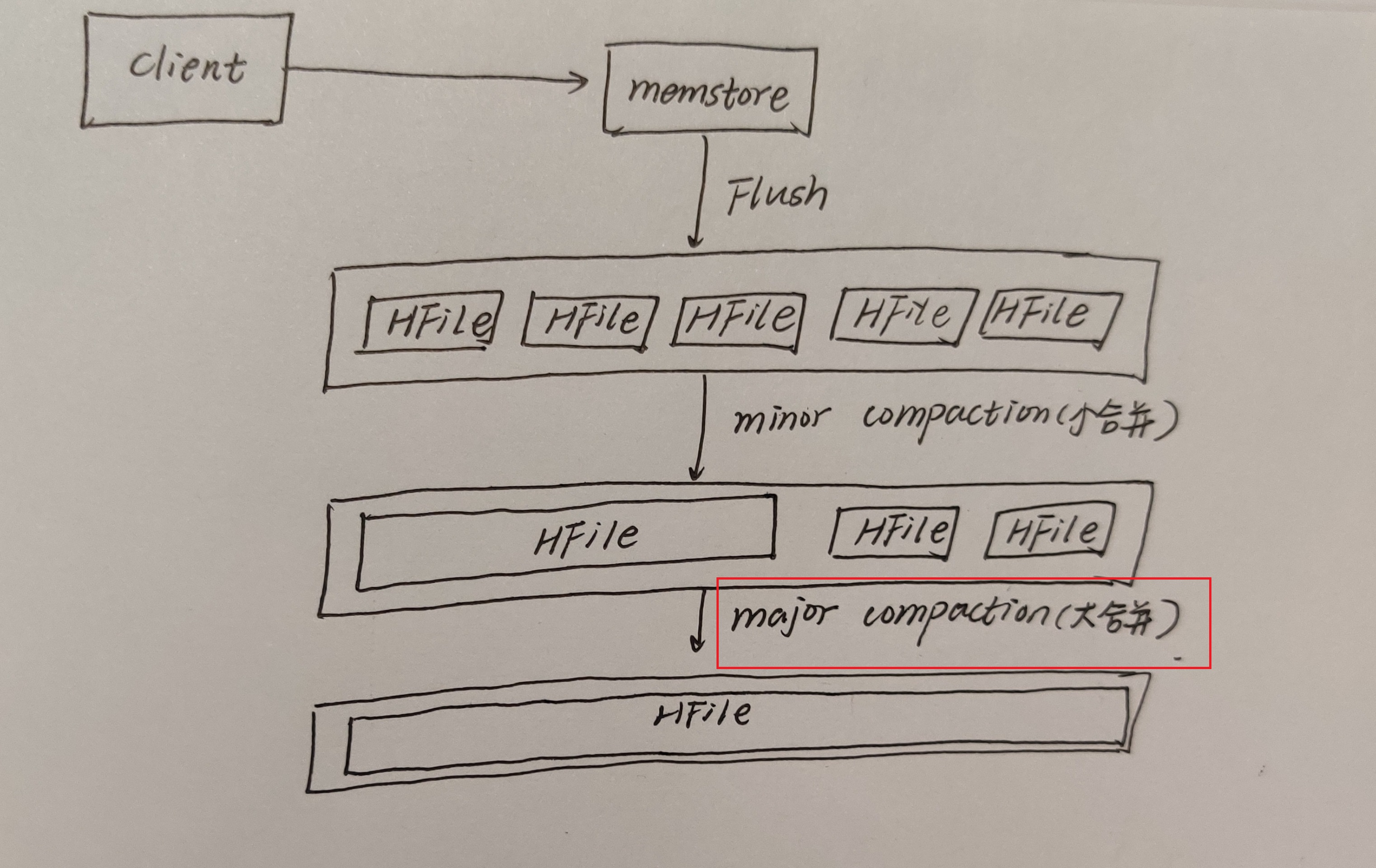
将所有的StoreFile合并成一个StoreFile,在这个过程中还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。它的合并频率比较低,默认7天执行一次,并且性能的消耗是非常大的,一般建议生产关闭,在应用空闲时间手动触发。一般可以是手动控制进行合并,这样可以防止出现在业务高峰期。
major compaction触发时间条件(7天)
<!--默认值为7天进行一次大合并,-->
<property>
<name>hbase.hregion.majorcompaction</name>
<value>604800000</value>
</property>
手动触发
#使用major_compact命令
major_compact tableName
第10点:Region拆分
region中存储的是大量的rowkey数据,当region中的数据条数过多的时候,直接影响查询效率。当region过大的时候。hbase会拆分region,这也是Hbase的一个优点。
HBase的region split策略一共有以下几种,先说说3种。
1、ConstantSizeRegionSplitPolicy
它是0.94版本前默认切分策略。
当region的大小大于某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region会等分为2个region。但是这种切分策略却有相当大的弊端:切分策略对于大表和小表没有明显的区分。阈值设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1个,这对业务来说并不是什么好事。如果设置较小则对小表友好,但一个大表就会在整个集群产生大量的region,这对于集群的管理、资源使用、failover来说都不是一件好事。
2、IncreasingToUpperBoundRegionSplitPolicy
它是0.94版本~2.0版本默认切分策略。
切分策略稍微有点复杂,总体看和ConstantSizeRegionSplitPolicy思路相同,一个region大小大于设置阈值就会触发切分。但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系。
3、SteppingSplitPolicy
它是2.0版本默认切分策略
这种切分策略的切分阈值又发生了变化,就是一般刚设计出来都会存在一些不合理的地方,随着慢慢的发展,设计师们逐渐完善。
相比之前的IncreasingToUpperBoundRegionSplitPolicy,它会简单一些,依然和待分裂region所属表在当前regionserver上的region个数有关系,如果region个数等于1,切分阈值为flush size * 2,否则为MaxRegionFileSize。这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。
还有几个不讲了,老刘快记不住了。
第11点:Region合并
什么时候需要Region合并?
比如有一张表在拆分后,一分为二,但是在使用过程中,对这两个表进行了数据的删除,数据量变小了,为了方便管理之类的,可以把他们合并。
又比如删除了大量的数据 ,这个时候每个Region都变得很小 ,存储多个Region就浪费了 ,这个时候可以把Region合并起来,进而可以减少一些Region服务器节点 。
总之,Region合并不是为了性能,而是为了方便维护管理。
第12点:HBase表的预分区
当一个table表刚被创建的时候,HBase会默认的分配一个region给这个table。这就相当于说,在这个时候,所有的读写请求都会访问到同一个regionServer的同一个region中,这个时候就达不到负载均衡的效果了,因为集群中的其他regionServer就可能会处于比较空闲的状态。出现了一人干活,其他人看戏的现象。
解决这个问题可以用预分区,在创建table表的时候就配置好,生成多个region。
预分区原理
每一个region都维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,就会把该数据交给这个region维护。如何手动指定预分区
方式一:
create 'person','info1','info2',SPLITS => ['1000','2000','3000','4000']
就会有如下这种效果:
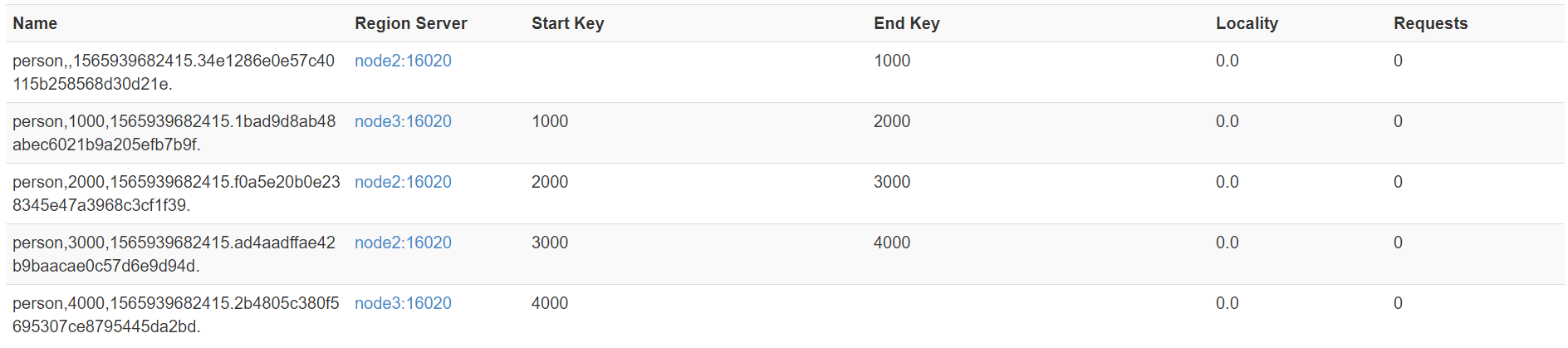
方式二:
把分区规则创建于文件中
cd /kkb/install vim split.txt
在里面添加这样的内容:
aaa
bbb
ccc
ddd
在执行这样的命令:
create 'student','info',SPLITS_FILE => '/kkb/install/split.txt'
就会得到这样的效果:
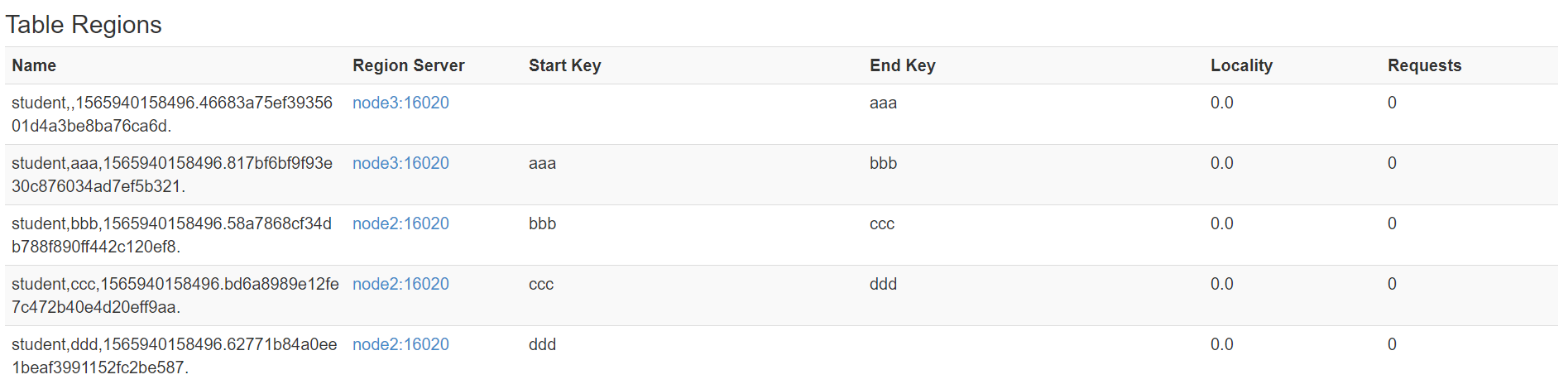
02 总结
好啦,大数据HBase的第二部分知识点就总结的差不多了,内容比较多,大家需要仔细理解,争取做到用自己的话把这些知识点讲述出来。
最后,如果觉得有哪里写的不好或者有错误的地方,可以联系公众号:努力的老刘,进行交流哦!希望能够对大数据开发感兴趣的同学有帮助,希望能够得到同学们的指导。
大白话详解大数据HBase核心知识点,老刘真的很用心(2)的更多相关文章
- 大白话详解大数据HBase核心知识点,老刘真的很用心(3)
老刘目前为明年校招而努力,写文章主要是想用大白话把自己复习的大数据知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的理解! 01 HBase知识点(3) 第13点:HBase表的热点问题 什么是热 ...
- 大白话详解大数据hive知识点,老刘真的很用心(2)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 1. hive知识点(2) 第12点:hive分桶表 hive知识点主要偏实践, ...
- 大白话详解大数据hive知识点,老刘真的很用心(3)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的内容详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 1. hive知识点(3) 从这篇文章开始决定进行一些改变,老刘在博客上主要分享 ...
- 大白话详解大数据hive知识点,老刘真的很用心(1)
前言:老刘不敢说写的有多好,但敢保证尽量用大白话把自己复习的知识点详细解释出来,拒绝资料上的生搬硬套,做到有自己的了解! 01 hive知识点(1) 第1点:数据仓库的概念 由于hive它是基于had ...
- 用大白话讲大数据HBase,老刘真的很用心(1)
老刘今天复习HBase知识发现很多资料都没有把概念说清楚,有很多专业名词一笔带过没有解释.比如这个框架高性能.高可用,那什么是高性能高可用?怎么实现的高性能高可用?没说! 如果面试官听了你说的,会有什 ...
- 保证看完就会!大数据YRAN核心知识点来袭!
01 我们一起学大数据 大家好,今天分享的是大数据YRAN的核心知识点,老刘尽量用通俗易懂的话来讲述YARN知识点,争取做到大家看完后能够用口语化的形式将它们表达出来,做到真正的看完就会!(如果觉得老 ...
- AI时代,还不了解大数据?
如果要问最近几年,IT行业哪个技术方向最火?一定属于ABC,即AI + Big Data + Cloud,也就是人工智能.大数据和云计算. 这几年,随着互联网大潮走向低谷,同时传统企业纷纷进行数字化转 ...
- RocketMQ详解(四)核心设计原理
专题目录 RocketMQ详解(一)原理概览 RocketMQ详解(二)安装使用详解 RocketMQ详解(三)启动运行原理 RocketMQ详解(四)核心设计原理 RocketMQ详解(五)总结提高 ...
- 第五章:大数据 の HBase 进阶
本课主题 HBase 读写数据的流程 HBase 性能优化和最住实践 HBase 管理和集群操作 HBase 备份和复制 引言 前一篇 HBase 基础 (HBase 基础) 简单介绍了NoSQL是什 ...
随机推荐
- JS常用事件的总结
JS常用事件的总结 outsbumit 表单提交事件 onload 页面加载事件 onclick 鼠标单击某个对象事件 ondblclick 鼠标双击某个对象事件 on ...
- freopen ()函数
1.格式 FILE * freopen ( const char * filename, const char * mode, FILE * stream ); 2.参数说明 filename: 要打 ...
- 841. Keys and Rooms —— weekly contest 86
题目链接:https://leetcode.com/problems/keys-and-rooms/description/ 简单DFS time:9ms 1 class Solution { 2 p ...
- 力扣 - 445. 两数相加 II
目录 题目 思路 代码实现 题目 给你两个 非空 链表来代表两个非负整数.数字最高位位于链表开始位置.它们的每个节点只存储一位数字.将这两数相加会返回一个新的链表. 你可以假设除了数字 0 之外,这两 ...
- 解决windows下Chrome78以上跨域失效问题
1. 为什么需要解决chrome浏览器跨域的问题? 基于Hybird App的H5部分,可以直接打包进apk或者ipa包中,在开发过程中也不需要放置到临时搭建的服务器上,直接在本地打开html静态页面 ...
- JSP系列记录
JSP就是可以实现在html中写Java代码 例: hello.jsp <%@page contentType="text/html; charset=UTF-8" page ...
- linux c语言 哲学家进餐---信号量PV方法一
1.实验原理 由Dijkstra提出并解决的哲学家进餐问题(The Dinning Philosophers Problem)是典型的同步问题.该问题是描述有五个哲学家共用一张圆桌,分别坐在周围的 ...
- 一看就懂的MySQL的FreeList机制
Hi,大家好!我是白日梦! 今天我要跟你分享的MySQL话题是:"了解InnoDB的FreeList吗?谈谈看!" 本文是MySQL专题的第 7 篇,共110篇. 一.回顾 前面几 ...
- 四、c++总结------linux多线程服务端编程
- backfill和recovery的最优值
ceph在增加osd的时候会触发backfill,让数据得到平均,触发数据的迁移 ceph在移除osd的时候需要在节点上进行数据的恢复,也有数据的迁移和生成 只要是集群里面有数据的变动就会有网卡流量, ...