线上Redis高并发性能调优实践
项目背景
最近,做一个按优先级和时间先后排队的需求。用 Redis 的 sorted set 做排队队列。
主要使用的 Redis 命令有, zadd, zcount, zscore, zrange 等。
测试完毕后,发到线上,发现有大量接口请求返回超时熔断(超时时间为3s)。
Error日志打印的异常堆栈为:
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
Caused by: redis.clients.jedis.exceptions.JedisConnectionException: java.net.ConnectException: Connection timed out (Connection timed out)
Caused by: java.net.ConnectException: Connection timed out (Connection timed out)
且有一个怪异的现象,只有写库的逻辑报错,即 zadd 操作。像 zadd, zcount, zscore 这些操作全部能正常执行。
还有就是报错和正常执行交错持续。即假设每分钟有1000个 Redis 操作,其中900个正常,100个报错。而不是报错后,Redis 就不能正常使用了。
问题排查
1.连接池泄露?
从上面的现象基本可以排除连接池泄露的可能,如果连接未被释放,那么一旦开始报错,后面的 Redis 请求基本上都会失败。而不是有90%都可正常执行。
但 Jedis 客户端据说有高并发下连接池泄露的问题,所以为了排除一切可能,还是升级了 Jedis 版本,发布上线,发现没什么用。
2.硬件原因?
排查 Redis 客户端服务器性能指标,CPU利用率10%,内存利用率75%,磁盘利用率10%,网络I/O上行 1.12M/s,下行 2.07M/s。接口单实例QPS均值300左右,峰值600左右。
Redis 服务端连接总数徘徊在2000+,CPU利用率5.8%,内存使用率49%,QPS1500-2500。
硬件指标似乎也没什么问题。
3.Redis参数配置问题?
1 JedisPoolConfig config = new JedisPoolConfig();
2 config.setMaxTotal (200); // 最大连接数
3 config.setMinIdle (5); // 最小空闲连接数
4 config.setMaxIdle (50); // 最大空闲连接数
5 config.setMaxWaitMillis (1000 * 1); // 最长等待时间
6 config.setTestOnReturn (false);
7 config.setTestOnBorrow (false);
8 config.setTestWhileIdle (true);
9 config.setTimeBetweenEvictionRunsMillis (30 * 1000);
10 config.setNumTestsPerEvictionRun (50);
基本上大部分公司的配置包括网上博客提供的配置其实都和上面差不多,看不出有什么问题。
这里我尝试把最大连接数调整到500,发布到线上,并没什么卵用,报错数反而变多了。
4.连接数统计
在 Redis Master 库上执行命令:client list。打印出当前所有连接到服务器的客户端IP,并过滤出当前服务的IP地址的连接。
发现均未达到最大连接数,确实排除了连接泄露的可能。
5.最大连接数调优和压测
既然连接远未打满,说明不需要设置那么大的连接数。而 Redis 服务端又是单线程读写。客户端创建过多连接,只会耗费资源,反而拖累性能。
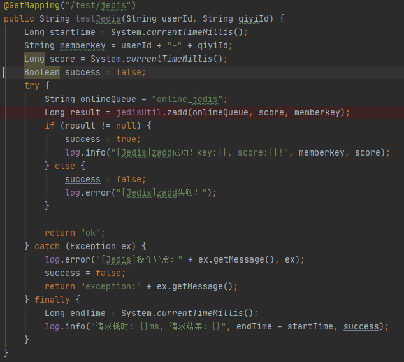
使用以上代码,在本机使用 JMeter 压测300个线程,连续请求30秒。
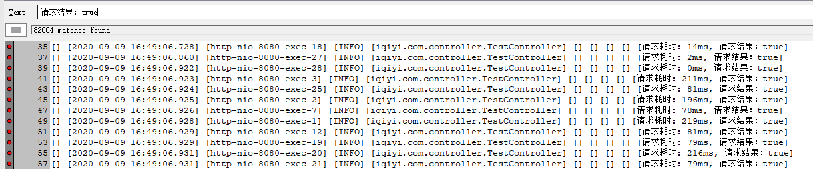
首先把最大连接数设为500,成功率:99.61%
请求成功:82004次,TP90耗时目测在50-80ms左右。
请求失败322次,全部为请求服务器超时:socket read timeout,耗时2s后,由 Jedis 自行熔断。
(这种情况造成数据不一致,实际上服务端已执行了命令,只是客户端读取返回结果超时)。

再把最大连接数设为20,成功率:98.62%(有一定几率100%成功)
请求成功:85788次,TP90耗时在10ms左右。
请求失败:1200次,全部为等待客户端连接超时:Caused by: java.util.NoSuchElementException: Timeout waiting for idle object,熔断时间为1秒。
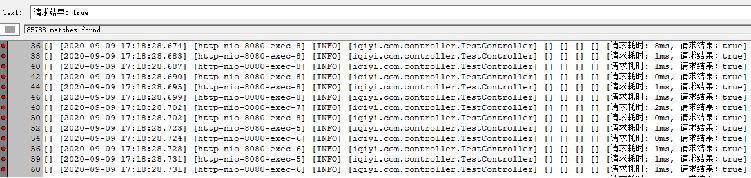
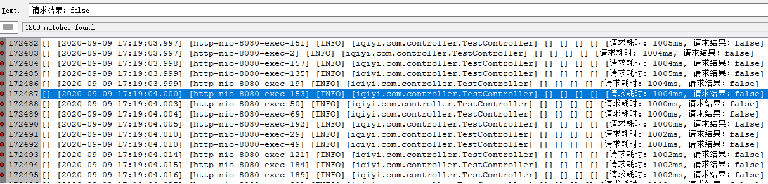
再将最大连接数调整为50,成功率:100%
请求成功:85788次, TP90耗时10ms。
请求失败:0次。
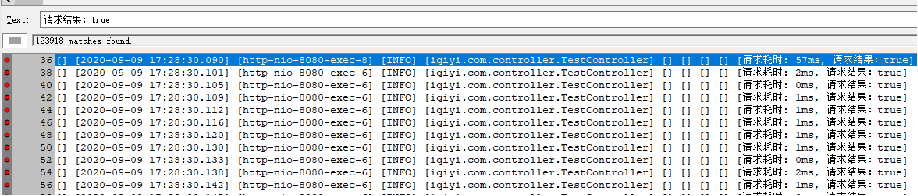
综上,Redis 服务端单线程读写,连接数太多并没卵用,反而会消耗更多资源。最大连接数配置太小,不能满足并发需求,线程会因为拿不到空闲连接而超时退出。
在满足并发的前提下,maxTotal连接数越小越好。在300线程并发下,最大连接数设为50,可以稳定运行。
基于以上结论,尝试调整 Redis 参数配置并发布上线,但以上实验只执行了 zadd 命令,仍未解决一个问题:为什么只有写库报错?
果然,发布上线后,接口超时次数有所减少,响应时间有所提升,但仍有报错,没能解决此问题。
6.插曲 - Redis锁
在优化此服务的同时,把同事使用的另一个 Redis 客户端一起优化了,结果同时的接口过了一天开始大面积报错,接口响应时间达到8个小时。
排查发现,同事的接口仅使用 Redis 作为分布式锁。而这个 RedisLock 类是从其他服务拿过来直接用的,自旋时间设置过长,这个接口又是超高并发。
最大连接数设为50后,锁资源竞争激烈,直接导致大部分线程自旋把连接池耗尽了。于是又紧急把最大连接池恢复到200,问题得以解决。
由此可见,在分布式锁的场景下,配置不能完全参考读写 Redis 操作的配置。
7.排查服务端持久化
在把客户端研究了好几遍之后,发现并没有什么可以优化的了,于是开始怀疑是服务端的问题。
持久化是一直没研究过的问题。在查阅了网上的一些博客,发现持久化确实有可能阻塞读写IO的。
“1) 对于没有持久化的方式,读写都在数据量达到800万的时候,性能下降几倍,此时正好是达到内存10G,Redis开始换出到磁盘的时候。并且从那以后再也没办法重新振作起来,性能比Mongodb还要差很多。
2) 对于AOF持久化的方式,总体性能并不会比不带持久化方式差太多,都是在到了千万数据量,内存占满之后读的性能只有几百。
3) 对于Dump持久化方式,读写性能波动都比较大,可能在那段时候正在Dump也有关系,并且在达到了1400万数据量之后,读写性能贴底了。在Dump的时候,不会进行换出,而且所有修改的数据还是创建的新页,内存占用比平时高不少,超过了15GB。而且Dump还会压缩,占用了大量的CPU。也就是说,在那个时候内存、磁盘和CPU的压力都接近极限,性能不差才怪。” ---- 引用自lovecindywang 的博客园博客
“内存越大,触发持久化的操作阻塞主线程的时间越长
Redis是单线程的内存数据库,在redis需要执行耗时的操作时,会fork一个新进程来做,比如bgsave,bgrewriteaof。 Fork新进程时,虽然可共享的数据内容不需要复制,但会复制之前进程空间的内存页表,这个复制是主线程来做的,会阻塞所有的读写操作,并且随着内存使用量越大耗时越长。例如:内存20G的redis,bgsave复制内存页表耗时约为750ms,redis主线程也会因为它阻塞750ms。” ---- 引用自CSDN博客
而我们的Redis实例总内存20G,内存使用了50%,keys数量达4000w。
主从集群,从库不做持久化,主库使用RDB持久化。rdb的save参数是默认值。(这也恰好能解释通为什么写库报错,读库正常)
且此 Redis 已使用了几年,里面可能存在大量的key已经不使用了,但未设置过期时间。
然而,像 Redis、MySQL 这种都是由数据中台负责,我们并无权查看服务端日志,这个事情也不好推动,中台会说客户端使用的有问题,建议调整参数。
所以最佳解决方案可能是,重新申请 Redis 实例,逐步把项目中使用的 Redis 迁移到新实例,并注意设置过期时间。迁移完成后,把老的 Redis 实例废弃回收。
小结
1)如果简单的在网上搜索,Could not get a resource from the pool , 基本都是些连接未释放的问题。
然而很多原因可能导致 Jedis 报这个错,这条信息并不是异常堆栈的最顶层。
2)Redis其实只适合作为缓存,而不是数据库或是存储。它的持久化方式适用于救救急啥的,不太适合当作一个普通功能来用。
3)还是建议任何数据都设置过期时间,哪怕设1年呢。不然老的项目可能已经都废弃了,残留在 Redis 里的 key,其他人也不敢删。
4)不要存放垃圾数据到 Redis 中,及时清理无用数据。业务下线了,就把相关数据清理掉。
线上Redis高并发性能调优实践的更多相关文章
- [转载]Java 应用性能调优实践
Java 应用性能调优实践 Java 应用性能优化是一个老生常谈的话题,笔者根据个人经验,将 Java 性能优化分为 4 个层级:应用层.数据库层.框架层.JVM 层.通过介绍 Java 性能诊断工具 ...
- JVM性能调优实践——JVM篇
前言 在遇到实际性能问题时,除了关注系统性能指标.还要结合应用程序的系统的日志.堆栈信息.GClog.threaddump等数据进行问题分析和定位.关于性能指标分析可以参考前一篇JVM性能调优实践-- ...
- elasticsearch5.3.0 bulk index 性能调优实践
elasticsearch5.3.0 bulk index 性能调优实践 通俗易懂
- Redis基础与性能调优
Redis是一个开源的,基于内存的结构化数据存储媒介,可以作为数据库.缓存服务或消息服务使用. Redis支持多种数据结构,包括字符串.哈希表.链表.集合.有序集合.位图.Hyperloglogs等. ...
- Java 应用性能调优实践
Java 应用性能优化是一个老生常谈的话题,笔者根据个人经验,将 Java 性能优化分为 4 个层级:应用层.数据库层.框架层.JVM 层.通过介绍 Java 性能诊断工具和思路,给出搜狗商业平台的性 ...
- Java性能调优实践
1 导论 JVM主要有两类调优标志:布尔标志和附带参数标志 布尔标志:-XX:+FlagName表示开启,-XX:-FlagName表示关闭. 附带参数标志:-XX:FlagName=somethi ...
- Doris开发手记4:倍速性能提升,向量化导入的性能调优实践
最近居家中,对自己之前做的一些工作进行总结.正好有Doris社区的小伙伴吐槽向量化的导入性能表现并不是很理想,就借这个机会对之前开发的向量化导入的工作进行了性能调优,取得了不错的优化效果.借用本篇手记 ...
- Kafka跨集群迁移方案MirrorMaker原理、使用以及性能调优实践
序言Kakfa MirrorMaker是Kafka 官方提供的跨数据中心的流数据同步方案.其实现原理,其实就是通过从Source Cluster消费消息然后将消息生产到Target Cluster,即 ...
- MySQL面试必考知识点:揭秘亿级高并发数据库调优与最佳实践法则
做业务,要懂基本的SQL语句: 做性能优化,要懂索引,懂引擎: 做分库分表,要懂主从,懂读写分离... 数据库的使用,是开发人员的基本功,对它掌握越清晰越深入,你能做的事情就越多. 今天我们用10分钟 ...
随机推荐
- Docker学习笔记-Dockerfile文件详解
什么是Dockerfile? Docker中有个非常重要的概念叫做--镜像(Image).Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序.库.资源.配置等文件外,还包含了一些为运 ...
- [SCOI2013]摩托车交易 题解
思路分析 为了让交易额尽量大,显然我们需要尽量多地买入.对于每个城市,到达这个城市时携带的黄金受到几个条件的影响:之前卖出的黄金,之前能买入的最多的黄金,前一个城市到当前城市的路径上的最小边权.既然不 ...
- Spring_mybatis结合之1.1
Spring和mybatis结合,Spring管理容器,连接数据库等,mybatis负责管理sql语句,sql的入参和出参等 三种方法: 1.原始dao开发(不怎么用,好奇的宝宝可以自己搜搜.是dao ...
- 封装Vue Element的dialog弹窗组件
我本没有想着说要封装一个弹窗组件,但有同行的朋友在问我,而且弹窗组件也确实在项目开发中用的比较多.思前想后,又本着样式统一且修改起来方便的原则,还是再为大家分享一个我所封装的弹窗组件吧. 其实,并不是 ...
- 【Android】在开发项目的时候,利用AndroidStudio开发工具,突然一直报错。
作者:程序员小冰,CSDN博客:http://blog.csdn.net/qq_21376985, QQ986945193 公众号:程序员小冰 首先说明,虽然报错,但是并不影响开发使用.但是感觉很不爽 ...
- linux系统工程师修改打开文件数限制代码教程。服务器运维技术
提示linux文件打开错误,修改linux打开文件数参数. /etc/pam.d/login 添加 session required /lib/security/pam_limits.so 注意看这个 ...
- android studio 如何进行格式化代码 快捷键必备
在Eclipse中,我们一般使用Ctrl+Shift+F来格式化代码,Android Studio中需要换成: Reformat code CTRL + ALT + L (Win) OPTION + ...
- shell小技巧(4)AIX和Linux计算天前日期
Linux计算天前日期: date -d "- day" +%Y%m%d AIX计算5天前日期: perl -e "use POSIX qw(strftime); pri ...
- JSTL日期格式化用法
JSP Standard Tag LibrariesFormatting and InternationalizationTwo form input parameters, 'date' and ' ...
- jenkins iOS自动打包
1.Jenkins配置 采用命令行下载配置Jenkins,防止产生权限问题 1)先安装brew,打开命令行,输入:/usr/bin/ruby -e "$(curl -fsSL https:/ ...