Redis 设计与实现 5:压缩列表
压缩列表是 ZSET、HASH和 LIST 类型的其中一种编码的底层实现,是由一系列特殊编码的连续内存块组成的顺序型数据结构,其目的是节省内存。
ziplist 的结构
外层结构
下图展示了压缩列表的组成:
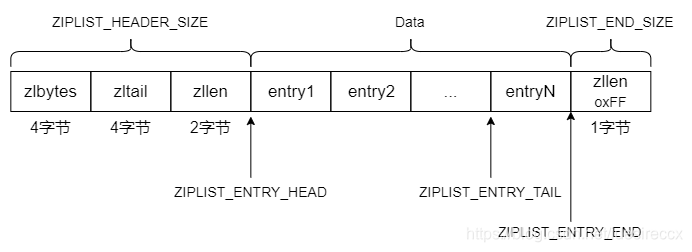
各个字段的含义如下:
zlbytes:是一个无符号 4 字节整数,保存着 ziplist 使用的内存数量。
通过zlbytes,程序可以直接对 ziplist 的内存大小进行调整,无须为了计算 ziplist 的内存大小而遍历整个列表。zltail:压缩列表 最后一个 entry 距离起始地址的偏移量,占 4 个字节。
这个偏移量使得对表尾的pop操作可以在无须遍历整个列表的情况下进行。zllen:压缩列表的节点entry数目,占 2 个字节。
当压缩列表的元素数目超过2^16 - 2的时候,zllen会设置为2^16-1,当程序查询到值为2^16-1,就需要遍历整个压缩列表才能获取到元素数目。所以zllen并不能替代zltail。entryX:压缩列表存储数据的节点,可以为字节数组或者整数。zlend:压缩列表的结尾,占一个字节,恒为0xFF。
实现的代码 ziplist.c 中,ziplist 定义成了宏属性。
// 相当于 zlbytes,ziplist 使用的内存字节数
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
// 相当于 zltail,最后一个 entry 距离 ziplist 起始位置的偏移量
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 相当于 zllen,entry 的数量
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
// zlbytes + zltail + zllen 的长度,也就是 4 + 4 + 2 = 10
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// zlend 的长度,1 字节
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
// 指向第一个 entry 起始位置的指针
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
// 指向最后一个 entry 起始位置的指针
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
// 相当于 zlend,指向 ziplist 最后一个字节
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
以下是重建新的空 ziplist 的代码实现,在 ziplist.c 中:
unsigned char *ziplistNew(void) {
// ziplist 头加上结尾标志字节数,就是 ziplist 使用内存的字节数了
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
// 因为没有 entry 列表,所以尾部偏移量是 ZIPLIST_HEADER_SIZE
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
// entry 节点数量是 0
ZIPLIST_LENGTH(zl) = 0;
// 设置尾标识。
// #define ZIP_END 255
zl[bytes-1] = ZIP_END;
return zl;
}
entry 节点的结构
布局
节点的结构一般是:<prevlen> <encoding> <entry-data>
prevlen:前一个entry的大小,用于反向遍历。encoding:编码,由于ziplist就是用来节省空间的,所以ziplist有多种编码,用来表示不同长度的字符串或整数。data:用于存储entry真实的数据;
prevlen
节点的 prevlen 属性以字节为单位,记录了压缩列表中前一个节点的长度。编码长度可以是 1 字节或者 5 字节。
- 当前面节点长度小于 254 的时候,长度为 1 个字节。
- 当前面节点长度大于 254 的时候,1 个字节不够存了。前面第一个字节就设置为 254,后面 4 个字节才是真正的前面节点的长度。
下图展示了 1 字节 和 5 字节 prevlen 的示意图(来源)
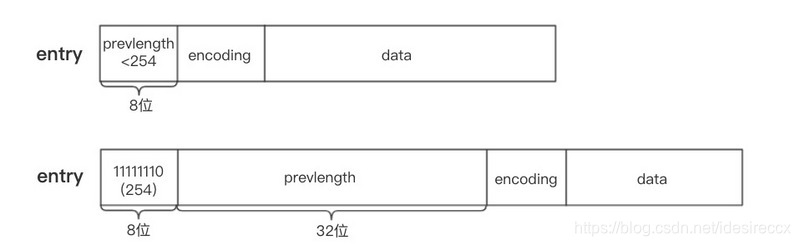
prevlen 属性主要的作用是反向遍历。通过 ziplist 的 zltail,我们可以得到最后一个节点的位置,接着可以获取到前一个节点的长度 len,指针向前移动 len,就是指向倒数第二个节点的位置了。以此类推,可以一直往前遍历。
encoding
encoding 记录了节点的 data 属性所保存数据的类型和长度。类型主要有两种:字符串和整数。
类型 1. 字符串
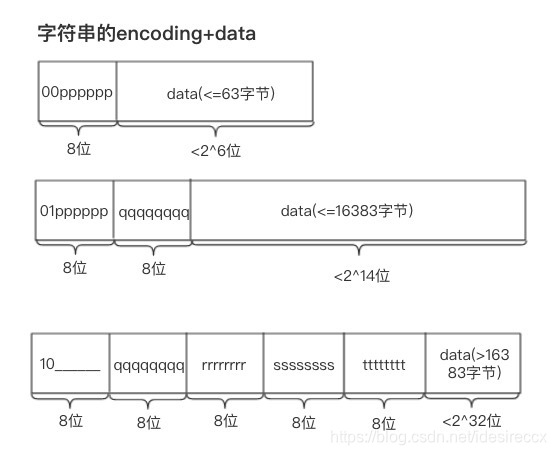
如果 encoding 以 00、01 或者 10 开头,就表示数据类型是字符串。
#define ZIP_STR_06B (0 << 6)
#define ZIP_STR_14B (1 << 6)
#define ZIP_STR_32B (2 << 6)
字符串有三种编码:
长度 < 2^6时,以00开头,后 6 位表示 data 的长度,。2^6 <= 长度 < 2^14时,以01开头,后续 6 位 + 下一个字节的 8 位 = 14 位表示 data 的长度。2^14 <= 长度 < 2^32字节时,以10开头,后续 6 位不用,从下一字节起连续 32 位表示 data 的长度。
下图为字符串三种长度结构的示意图(来源):
类型 2. 整数
如果 encoding 以 11 开头,就表示数据类型是整数。
#define ZIP_INT_16B (0xc0 | 0<<4)
#define ZIP_INT_32B (0xc0 | 1<<4)
#define ZIP_INT_64B (0xc0 | 2<<4)
#define ZIP_INT_24B (0xc0 | 3<<4)
#define ZIP_INT_8B 0xfe
#define ZIP_INT_IMM_MIN 0xf1 /* 11110001 */
#define ZIP_INT_IMM_MAX 0xfd /* 11111101 */
整数一共有 6 种编码,说起来麻烦,看图吧(来源)。
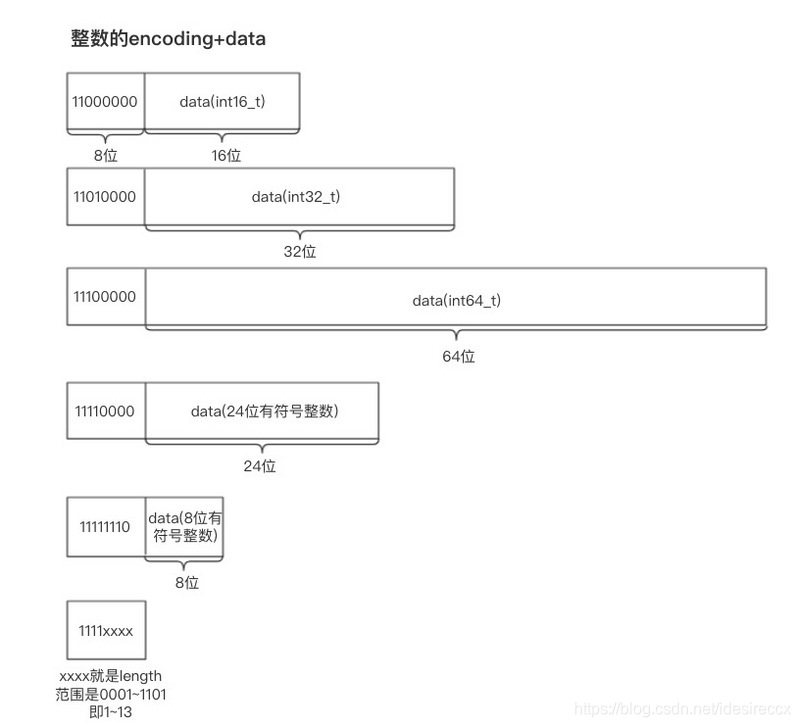
看了上图的最后一个类型,可能有小伙伴就有疑问:为啥没有 11111111 ?
答:因为 11111111 表示 zlend (十进制的 255,十六进制的 oxff)
data
data 表示真实存的数据,可以是字符串或者整数,从编码可以得知类型和长度。知道长度,就知道 data 的起始位置了。
比较特殊的是,整数 1 ~ 13 (0001 ~ 1101),因为比较短,刚好可以塞在 encoding 字段里面,所以就没有 data。
连锁更新
通过上面的分析,我们知道:
- 前个节点的长度小于 254 的时候,用 1 个字节保存
prevlen - 前个字节的长度大于等于 254 的时候,用 5 个字节保存
prevlen
现在我们来考虑一种情况:假设一个压缩列表中,有多个长度 250 ~ 253 的节点,假设是 entry1 ~ entryN。
因为都是小于 254,所以都是用 1 个字节保存 prevlen。
如果此时,在压缩列表最前面,插入一个 254 长度的节点,此时它的长度需要 5 个字节。
也就是说 entry1.prevlen 会从 1 个字节变为 5 个字节,因为 prevlen 变长,entry1 的长度超过 254 了。
这下就糟糕了,entry2.prevlen 也会因为 entry1 而变长,entry2 长度也会超过 254 了。
然后接着 entry3 也会连锁更新。。。直到节点不超过 254, 噩梦终止。。。
这种由于一个节点的增删,后续节点变长而导致的连续重新分配内存的现象,就是连锁更新。最坏情况下,会导致整个压缩列表的所有节点都重新分配内存。
每次分配空间的最坏时间复杂度是 \(O(n)\),所以连锁更新的最坏时间复杂度高达 \(O(n^2)\) !
虽然说,连锁更新的时间复杂度高,但是它造成大的性能影响的概率很低,原因如下:
- 压缩列表中需要需要有连续多个长度刚好为 250 ~ 253 的节点,才有可能发生连锁更新。实际上,这种情况并不多见。
- 即使有连续多个长度刚好为 250 ~ 253 的节点,连续的个数也不多,不会对性能造成很大影响
因此,压缩列表插入操作,平均复杂度还是 \(O(n)\).
总结:
- 压缩列表是一种为节约内存而开发的顺序型数据结构,是 ZSET、HASH 和 LIST 的底层实现之一。
- 压缩列表有 3 种字符串类型编码、6 种整数类型编码
- 压缩列表的增删,可能会引发连锁更新操作,但这种操作出现的几率并不高。
本文的分析没有特殊说明都是基于 Redis 6.0 版本源码
redis 6.0 源码:https://github.com/redis/redis/tree/6.0
Redis 设计与实现 5:压缩列表的更多相关文章
- Redis数据结构—整数集合与压缩列表
目录 Redis数据结构-整数集合与压缩列表 整数集合的实现 整数集合的升级 整数集合不支持降级 压缩列表的构成 压缩列表节点的构成 小结 Redis数据结构-整数集合与压缩列表 大家好,我是白泽.今 ...
- Redis 的底层数据结构(压缩列表)
上一篇我们介绍了 redis 中的整数集合这种数据结构的实现,也谈到了,引入这种数据结构的一个很大的原因就是,在某些仅有少量整数元素的集合场景,通过整数集合既可以达到字典的效率,也能使用远少于字典的内 ...
- Redis 源码简洁剖析 05 - ziplist 压缩列表
ziplist 是什么 Redis 哪些数据结构使用了 ziplist? ziplist 特点 优点 缺点 ziplist 数据结构 ziplist 节点 pre_entry_length encod ...
- 【Redis】ziplist压缩列表
压缩列表 压缩列表是列表和哈希表的底层实现之一: 如果一个列表只有少量数据,并且数据类型是整数或者比较短的字符串,redis底层就会使用压缩列表实现. 如果一个哈希表只有少量键值对,并且每个键值对的键 ...
- Redis压缩列表原理与应用分析
摘要 Redis是一款著名的key-value内存数据库软件,同时也是一款卓越的数据结构服务软件.它支持字符串.列表.哈希表.集合.有序集合五种数据结构类型,同时每种数据结构类型针对不同的应用场景又支 ...
- 【Redis源代码剖析】 - Redis内置数据结构之压缩字典zipmap
原创作品,转载请标明:http://blog.csdn.net/Xiejingfa/article/details/51111230 今天为大家带来Redis中zipmap数据结构的分析,该结构定义在 ...
- Redis压缩列表
此篇文章是主要介绍Redis在数据存储方面的其中一种方式,压缩列表.本文会介绍1. 压缩列表(ziplist)的使用场景 2.如何达到节约内存的效果?3.压缩列表的存储格式 4. 连锁更新的问题 5 ...
- redis 笔记01 简单动态字符串、链表、字典、跳跃表、整数集合、压缩列表
文中内容摘自<redis设计与实现> 简单动态字符串 1. Redis只会使用C字符串作为字面量,在大多数情况下,Redis使用SDS(Simple Dynamic String,简单动态 ...
- Redis 学习笔记(篇四):整数集合和压缩列表
整数集合 Redis 中当一个集合(set)中只包含整数,并且元素不多时,底层使用整数集合实现,否则使用字典实现. 那么: 为什么会出现整数集合呢?都使用字典存储不行吗? 整数集合在 Redis 中的 ...
随机推荐
- Java基础教程——Scanner类
Scanner属于java.util包. java.util包是Java内置的一个工具包,其中包含一系列常用的工具类,如处理日期.日历.集合类: 如果要使用到该包中的类,必须显式引入包名:import ...
- Java基础教程——继承
继承 一个类 可以 继承自 另一个类: 派生的类(子类)继承父类的方法和数据成员: 关键字:子类 extends 父类. public class 继承 { public static void ma ...
- java抽象类,多态1
1 package pet_2; 2 3 public abstract class Pet { 4 private String name; 5 6 public String getName() ...
- Python爬虫入门(二)之Requests库
Python爬虫入门(二)之Requests库 我是照着小白教程做的,所以该篇是更小白教程hhhhhhhh 一.Requests库的简介 Requests 唯一的一个非转基因的 Python HTTP ...
- 2、Spring Cloud和dubbo简介
1.Spring Cloud简介 (1).Spring Cloud简介 SpringCloud,基于SpringBoot提供了一套微服务解决方案,包括服务注册与发现,配置中心,全链路监控,服务网关,负 ...
- 浅尝 Elastic Stack (一) Elasticsearch、Kibana、Beats 安装
Elastic Stack 包括 Elasticsearch.Kibana.Beats 和 Logstash,也称为 ELK Stack.能够安全可靠地获取任何来源.任何格式的数据,然后实时地对数据进 ...
- PyQt(Python+Qt)学习随笔:QTabWidget选项卡部件的documentMode属性作用
老猿Python博文目录 专栏:使用PyQt开发图形界面Python应用 老猿Python博客地址 QTabWidget的documentMode属性用于控制是否以适合文档页的模式呈现选项卡部件.这与 ...
- PHP代码审计分段讲解(5)
11 sql闭合绕过 源代码为 <?php if($_POST[user] && $_POST[pass]) { $conn = mysql_connect("**** ...
- Python Flask后端异步处理(二)
在实际的应用场景中,如用户注册,用户输入了注册信息后,后端保存信息到数据库中,然后跳转至登录界面,这些操作用户需要等待的时间非常短,但是如果是有耗时任务,比如对输入的网址进行漏洞扫描,在后端处理就会花 ...
- BUUOJ 杂项MISC(1)
爱因斯坦 下载之后解压打开是一张爱因斯坦的图片,看来是图片隐写题 使用binwalk -e misc2.jpg 获得一个有flag.txt的压缩包,但是需要密码才能打开,猜想密码在图片里面,把图片丢进 ...