面向初学者的Python爬虫程序教程之动态网页抓取
目的是对所有注释进行爬网。
下面列出了已爬网链接。如果您使用AJAX加载动态网页,则有两种方式对其进行爬网。
分别介绍了两种方法:(如果对代码有任何疑问,请提出改进建议)
解析真实地址爬网
示例是参考链接中提供的URL,网站上评论的链接必须使用
beats进行爬网。如果单击“网络”以刷新网页,则注释数据将位于这些文件中。通常,这些数据以json文件格式提供。然后找到注释数据文件。参见下图。单击预览以查看数据。
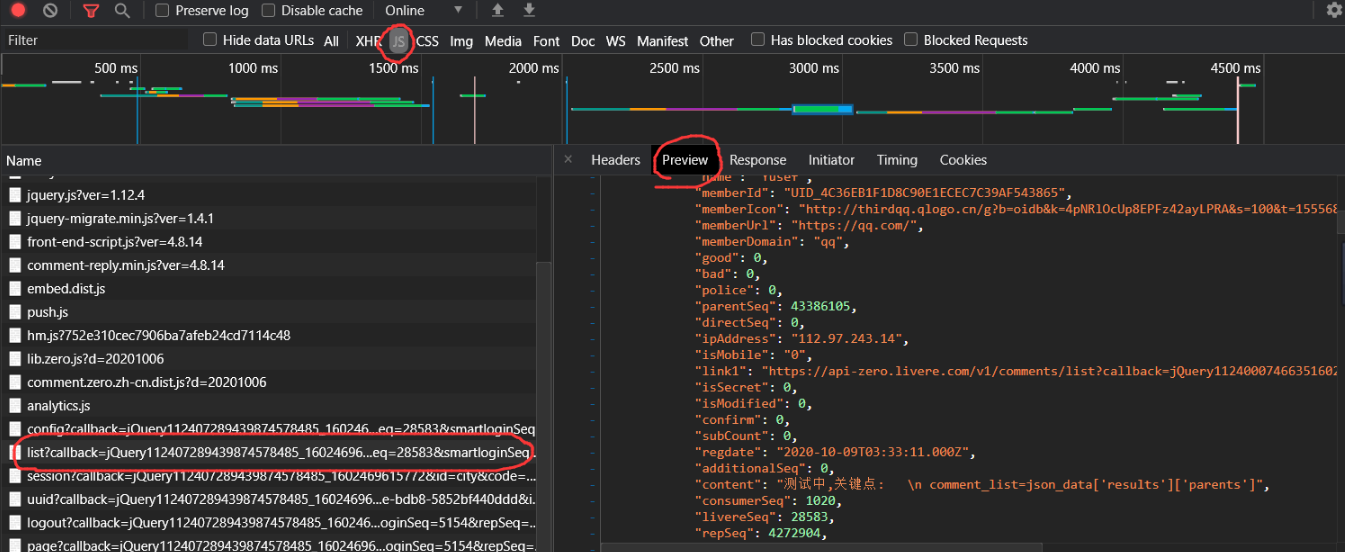
执行后,对数据进行爬取,添加注释并进行描述,并打印测试结果。

改进:仅将第一页上的注释爬到此处。所有评论都应被抓取。单击另一个页码以查找更多json文件:

如果单击这些Json文件并比较URL,则会看到参数存在差异。
此参数代表页数,offset = 1代表第一页。 (注意:第一次输入时,默认情况下,偏移量为1、并且可能没有偏移量参数,因此它不会出现在URL中)
使用selenium模拟浏览器爬网
在以前的方法中,某些网站会加密地址以避免这些爬网,因此第二种方法
seleniuminstallation和测试 您可以使用。
如果您使用的是Firefox,则下载地址为
。其他浏览器可以使用百度
进行测试。代码如下:

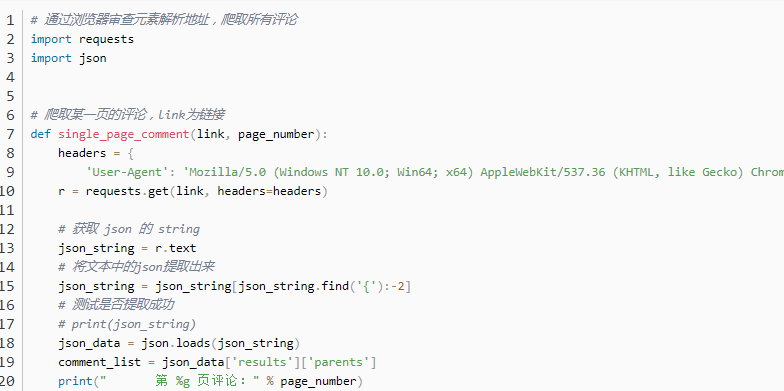
使用以下代码抓取数据。请注意,注释位于iframe框架下方,因此您需要先解析iframe。因此,首先使用switch_to转移焦点。
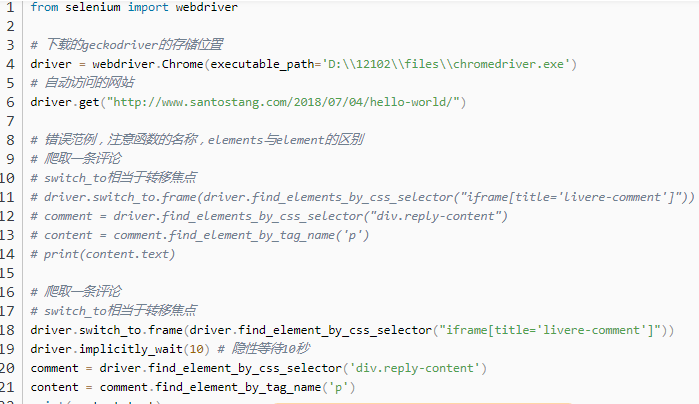
在此处添加了Driver.implicitly_wait(10)以隐式等待10秒。如果未添加此代码行,则iframe框架将花费很长时间加载,并且将报告错误,提示找不到div.reply-content。
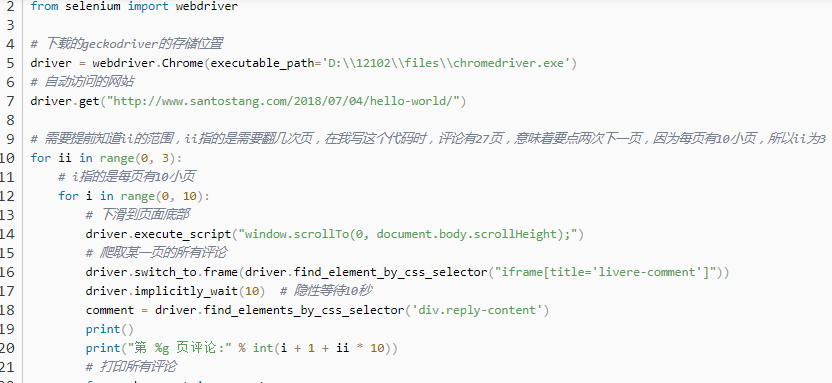
每页有10小页。浏览10页后,单击[下一页]共27页。一切都在嵌套的for循环中完成。外层代表1-10、11-20、21-27页,内层在每页上打印注释。在每页上打印评论的方法与抓取上一个评论的方法相同。参见下面的
代码,并有一个注释:
通常,Selenium趋向于减慢速度,因为它必须在开始抓取内容之前加载整个网页。但是,可以使用以下方法:禁用
图像,CSS和JS后,结果如下所示:

上面的代码使用fp = webdriver.FirefoxProfile()控制CSS的加载。要设置不加载CSS,请使用fp.set_preference(“ permissions.default.stylesheet ”,2)。然后使用webdriver.Firefox(firefox_profile = fp)来控制css不加载。运行上面的代码后,结果页面将显示在下面。

面向初学者的Python爬虫程序教程之动态网页抓取的更多相关文章
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- Python开发爬虫之动态网页抓取篇:爬取博客评论数据——通过Selenium模拟浏览器抓取
区别于上篇动态网页抓取,这里介绍另一种方法,即使用浏览器渲染引擎.直接用浏览器在显示网页时解析 HTML.应用 CSS 样式并执行 JavaScript 的语句. 这个方法在爬虫过程中会打开一个浏览器 ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- Python爬虫工程师必学——App数据抓取实战 ✌✌
Python爬虫工程师必学——App数据抓取实战 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 爬虫分为几大方向,WEB网页数据抓取.APP数据抓取.软件系统 ...
- Python爬虫工程师必学APP数据抓取实战✍✍✍
Python爬虫工程师必学APP数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- Python爬虫工程师必学——App数据抓取实战
Python爬虫工程师必学 App数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- python网络爬虫-动态网页抓取(五)
动态抓取的实例 在开始爬虫之前,我们需要了解一下Ajax(异步请求).它的价值在于在与后台进行少量的数据交换就可以使网页实现异步更新. 如果使用Ajax加载的动态网页抓取,有两种方法: 通过浏览器审查 ...
- Python之HTML的解析(网页抓取一)
http://blog.csdn.net/my2010sam/article/details/14526223 --------------------- 对html的解析是网页抓取的基础,分析抓取的 ...
- Python爬虫入门教程: 27270图片爬取
今天继续爬取一个网站,http://www.27270.com/ent/meinvtupian/ 这个网站具备反爬,so我们下载的代码有些地方处理的也不是很到位,大家重点学习思路,有啥建议可以在评论的 ...
随机推荐
- 【题解】CF413C Jeopardy!
\(\color{blue}{Link}\) \(\text{Solution:}\) 首先,显然的策略是把一定不能翻倍的先加进来.继续考虑下一步操作. 考虑\(x,y\)两个可以翻倍的物品,且\(a ...
- Metasploit简单使用——后渗透阶段
在上文中我们复现了永恒之蓝漏洞,这里我们学习一下利用msf简单的后渗透阶段的知识/ 一.meterperter常用命令 sysinfo #查看目标主机系统信息 run scraper #查看目标主机详 ...
- 手把手教你安装TensorFlow2 GPU 版本
参考博客:https://blog.csdn.net/weixin_44170512/article/details/103990592 (本文中部分内容引自参考博客,请大家支持原作者!) 感谢大佬的 ...
- JVM性能调优(4) —— 性能调优工具
前序文章: JVM性能调优(1) -- JVM内存模型和类加载运行机制 JVM性能调优(2) -- 垃圾回收器和回收策略 JVM性能调优(3) -- 内存分配和垃圾回收调优 一.JDK工具 先来看看有 ...
- spring-security-结合JWT的简单demo
spring-security-demo 前言:本来是想尽量简单简单点的写一个demo的,但是spring-security实在是内容有点多,写着写着看起来就没那么简单了,想入门spring-secu ...
- 【Linux编译环境的搭建】Linux都没有,怎么学Linux编程?
本文准备从0开始,一步步搭建一套属于自己的多节点Linux系统环境,这将是后续学Linux.用Linux.Linux环境编程.应用和项目部署.工具实验等一系列学习和实践的基石,希望对小伙伴们有帮助. ...
- 50种编程语言,一句 “Hello, World”!展现编程语言七十年发展!
mod confinment { use std::os::raw::{c_char}; extern "C" { pub fn puts(txt: *const c_char); ...
- MSF权限维持
MSF权限维持 环境搭建 目标机:win7 ip:192.168.224.133 攻击机:kali linux ip:192.168.224.129 首先使用web_delivery模块的regsvr ...
- 请勿过度依赖Redis的过期监听!!
作者:迪壳 https://juejin.im/post/6844904158227595271 Redis 过期监听场景 业务中有类似等待一定时间之后执行某种行为的需求 , 比如 30 分钟之后关闭 ...
- docker部署nginx服务器
1,下载nginx镜像 docker pull nginx 2,启动 docker run --name runoob-nginx-test -p 8081:80 -d nginx 3,创建本地目录 ...